 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$γ$-Models: Generative Temporal Difference Learning for Infinite-Horizon Prediction
Oct 27, 2020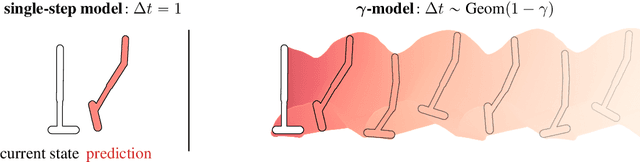

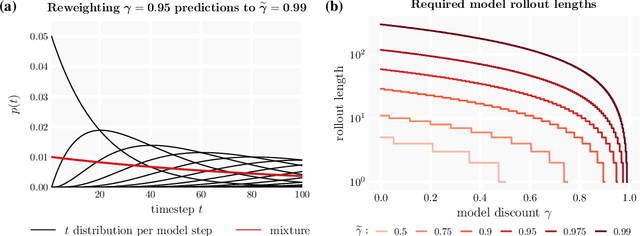

We introduce the $\gamma$-model, a predictive model of environment dynamics with an infinite probabilistic horizon. Replacing standard single-step models with $\gamma$-models leads to generalizations of the procedures that form the foundation of model-based control, including the model rollout and model-based value estimation. The $\gamma$-model, trained with a generative reinterpretation of temporal difference learning, is a natural continuous analogue of the successor representation and a hybrid between model-free and model-based mechanisms. Like a value function, it contains information about the long-term future; like a standard predictive model, it is independent of task reward. We instantiate the $\gamma$-model as both a generative adversarial network and normalizing flow, discuss how its training reflects an inescapable tradeoff between training-time and testing-time compounding errors, and empirically investigate its utility for prediction and control.
One Policy to Control Them All: Shared Modular Policies for Agent-Agnostic Control
Jul 09, 2020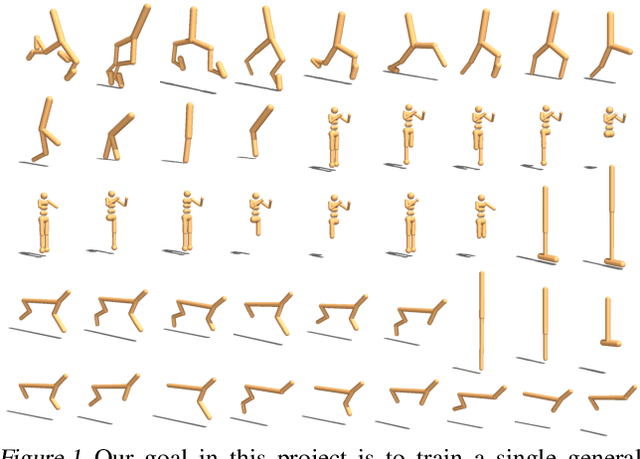
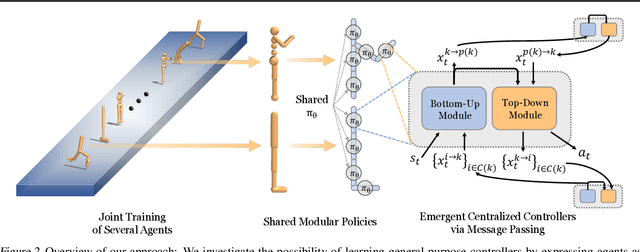
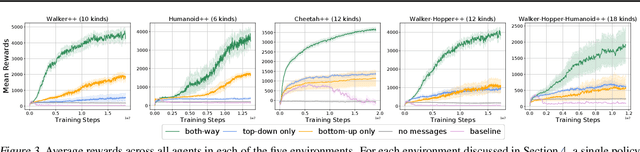
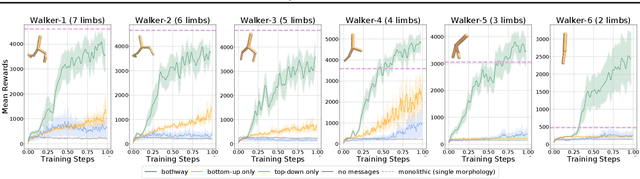
Reinforcement learning is typically concerned with learning control policies tailored to a particular agent. We investigate whether there exists a single global policy that can generalize to control a wide variety of agent morphologies -- ones in which even dimensionality of state and action spaces changes. We propose to express this global policy as a collection of identical modular neural networks, dubbed as Shared Modular Policies (SMP), that correspond to each of the agent's actuators. Every module is only responsible for controlling its corresponding actuator and receives information from only its local sensors. In addition, messages are passed between modules, propagating information between distant modules. We show that a single modular policy can successfully generate locomotion behaviors for several planar agents with different skeletal structures such as monopod hoppers, quadrupeds, bipeds, and generalize to variants not seen during training -- a process that would normally require training and manual hyperparameter tuning for each morphology. We observe that a wide variety of drastically diverse locomotion styles across morphologies as well as centralized coordination emerges via message passing between decentralized modules purely from the reinforcement learning objective. Videos and code at https://huangwl18.github.io/modular-rl/
A Game Theoretic Framework for Model Based Reinforcement Learning
Apr 16, 2020

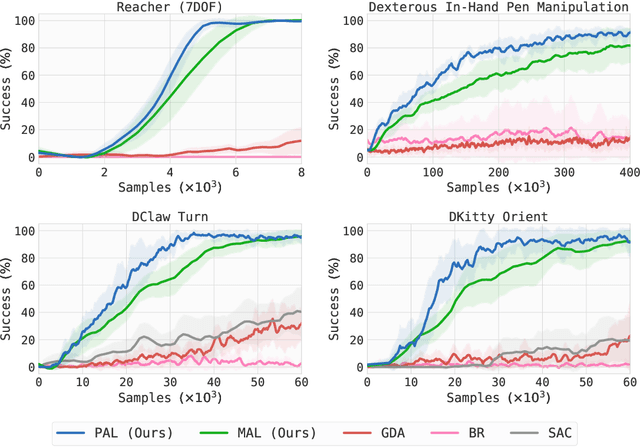
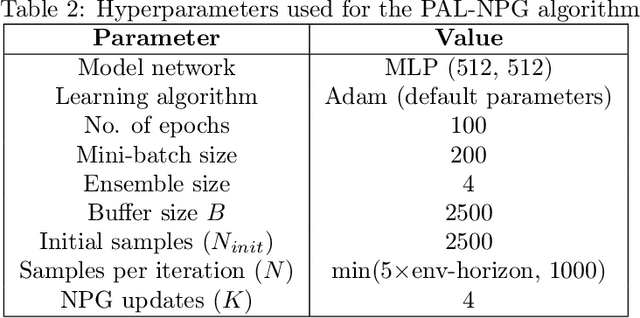
Model-based reinforcement learning (MBRL) has recently gained immense interest due to its potential for sample efficiency and ability to incorporate off-policy data. However, designing stable and efficient MBRL algorithms using rich function approximators have remained challenging. To help expose the practical challenges in MBRL and simplify algorithm design from the lens of abstraction, we develop a new framework that casts MBRL as a game between: (1) a policy player, which attempts to maximize rewards under the learned model; (2) a model player, which attempts to fit the real-world data collected by the policy player. For algorithm development, we construct a Stackelberg game between the two players, and show that it can be solved with approximate bi-level optimization. This gives rise to two natural families of algorithms for MBRL based on which player is chosen as the leader in the Stackelberg game. Together, they encapsulate, unify, and generalize many previous MBRL algorithms. Furthermore, our framework is consistent with and provides a clear basis for heuristics known to be important in practice from prior works. Finally, through experiments we validate that our proposed algorithms are highly sample efficient, match the asymptotic performance of model-free policy gradient, and scale gracefully to high-dimensional tasks like dexterous hand manipulation.
Compositional Visual Generation and Inference with Energy Based Models
Apr 13, 2020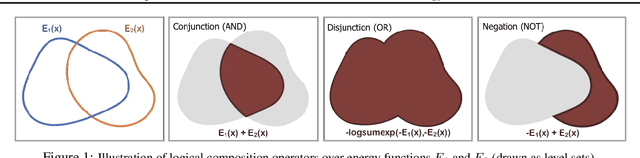
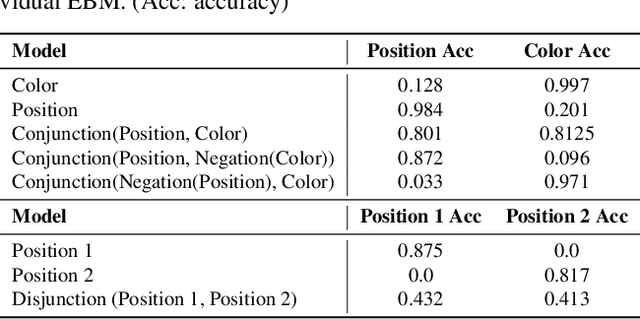
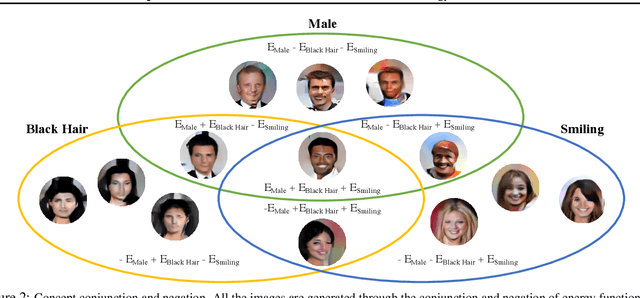
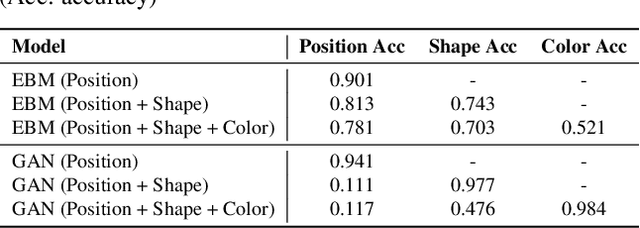
A vital aspect of human intelligence is the ability to compose increasingly complex concepts out of simpler ideas, enabling both rapid learning and adaptation of knowledge. In this paper we show that energy-based models can exhibit this ability by directly combining probability distributions. Samples from the combined distribution correspond to compositions of concepts. For example, given a distribution for smiling faces, and another for male faces, we can combine them to generate smiling male faces. This allows us to generate natural images that simultaneously satisfy conjunctions, disjunctions, and negations of concepts. We evaluate compositional generation abilities of our model on the CelebA dataset of natural faces and synthetic 3D scene images. We also demonstrate other unique advantages of our model, such as the ability to continually learn and incorporate new concepts, or infer compositions of concept properties underlying an image.
Adaptive Online Planning for Continual Lifelong Learning
Dec 03, 2019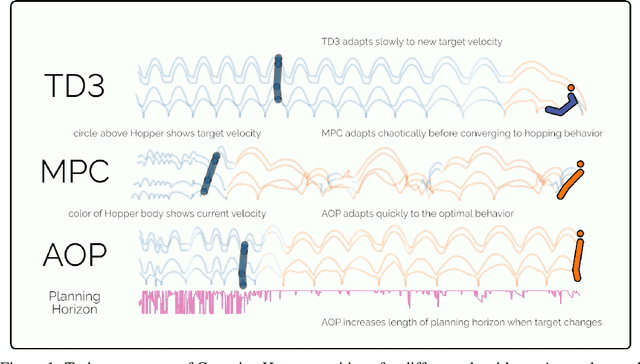
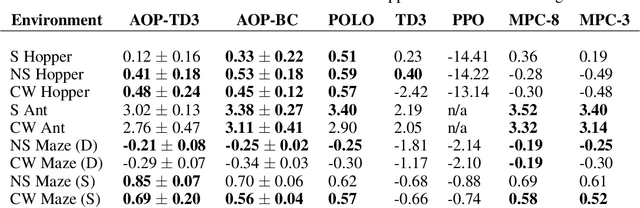
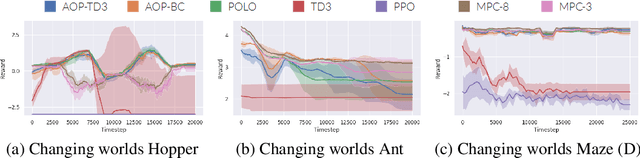

We study learning control in an online lifelong learning scenario, where mistakes can compound catastrophically into the future and the underlying dynamics of the environment may change. Traditional model-free policy learning methods have achieved successes in difficult tasks due to their broad flexibility, and capably condense broad experiences into compact networks, but struggle in this setting, as they can activate failure modes early in their lifetimes which are difficult to recover from and face performance degradation as dynamics change. On the other hand, model-based planning methods learn and adapt quickly, but require prohibitive levels of computational resources. Under constrained computation limits, the agent must allocate its resources wisely, which requires the agent to understand both its own performance and the current state of the environment: knowing that its mastery over control in the current dynamics is poor, the agent should dedicate more time to planning. We present a new algorithm, Adaptive Online Planning (AOP), that achieves strong performance in this setting by combining model-based planning with model-free learning. By measuring the performance of the planner and the uncertainty of the model-free components, AOP is able to call upon more extensive planning only when necessary, leading to reduced computation times. We show that AOP gracefully deals with novel situations, adapting behaviors and policies effectively in the face of unpredictable changes in the world -- challenges that a continual learning agent naturally faces over an extended lifetime -- even when traditional reinforcement learning methods fail.
Emergent Tool Use From Multi-Agent Autocurricula
Sep 17, 2019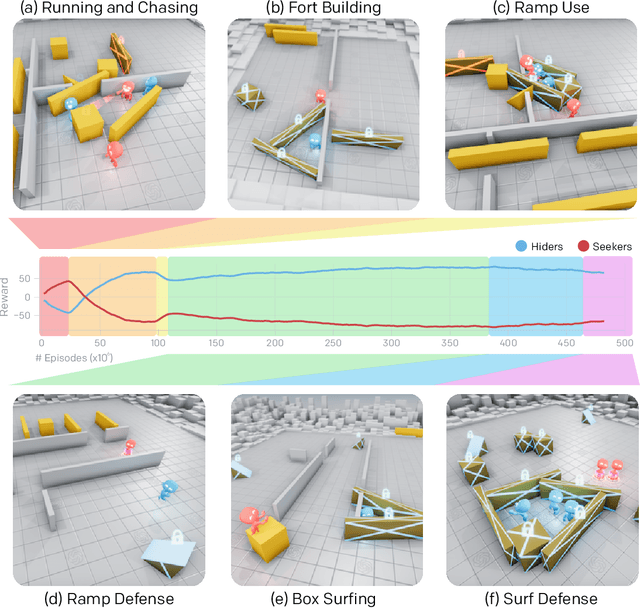
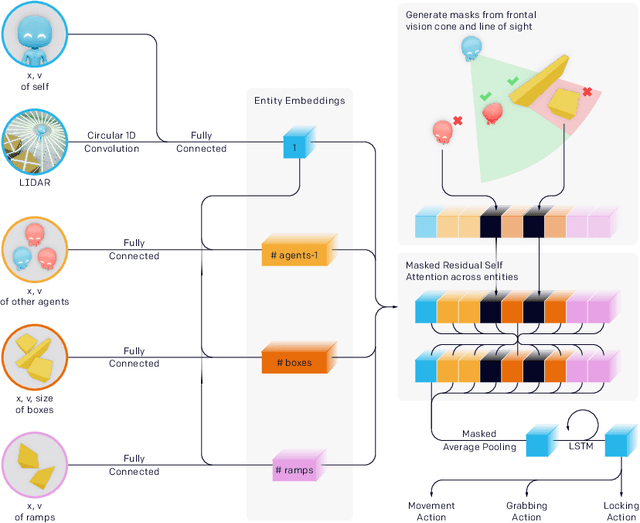
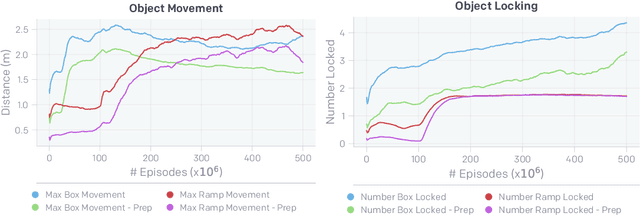
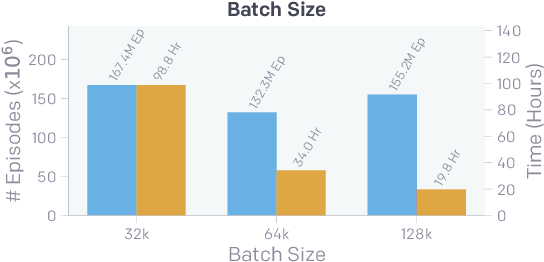
Through multi-agent competition, the simple objective of hide-and-seek, and standard reinforcement learning algorithms at scale, we find that agents create a self-supervised autocurriculum inducing multiple distinct rounds of emergent strategy, many of which require sophisticated tool use and coordination. We find clear evidence of six emergent phases in agent strategy in our environment, each of which creates a new pressure for the opposing team to adapt; for instance, agents learn to build multi-object shelters using moveable boxes which in turn leads to agents discovering that they can overcome obstacles using ramps. We further provide evidence that multi-agent competition may scale better with increasing environment complexity and leads to behavior that centers around far more human-relevant skills than other self-supervised reinforcement learning methods such as intrinsic motivation. Finally, we propose transfer and fine-tuning as a way to quantitatively evaluate targeted capabilities, and we compare hide-and-seek agents to both intrinsic motivation and random initialization baselines in a suite of domain-specific intelligence tests.
Model Based Planning with Energy Based Models
Sep 15, 2019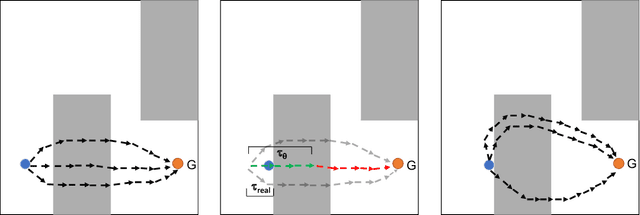

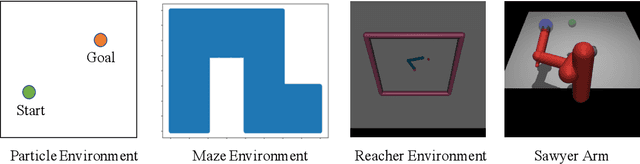

Model-based planning holds great promise for improving both sample efficiency and generalization in reinforcement learning (RL). We show that energy-based models (EBMs) are a promising class of models to use for model-based planning. EBMs naturally support inference of intermediate states given start and goal state distributions. We provide an online algorithm to train EBMs while interacting with the environment, and show that EBMs allow for significantly better online learning than corresponding feed-forward networks. We further show that EBMs support maximum entropy state inference and are able to generate diverse state space plans. We show that inference purely in state space - without planning actions - allows for better generalization to previously unseen obstacles in the environment and prevents the planner from exploiting the dynamics model by applying uncharacteristic action sequences. Finally, we show that online EBM training naturally leads to intentionally planned state exploration which performs significantly better than random exploration.
Implicit Generation and Generalization in Energy-Based Models
Mar 20, 2019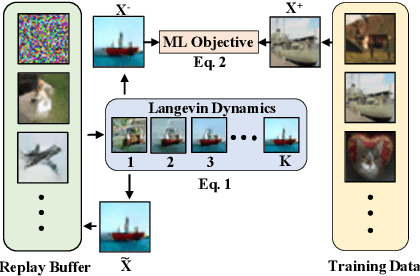

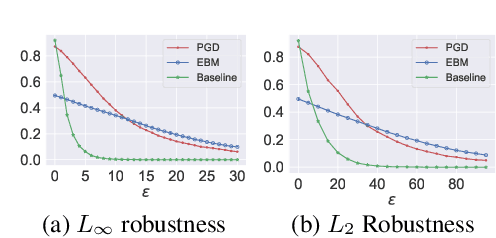

Energy based models (EBMs) are appealing due to their generality and simplicity in likelihood modeling, but have been traditionally difficult to train. We present techniques to scale MCMC based EBM training, on continuous neural networks, and show its success on the high-dimensional data domains of ImageNet32x32, ImageNet128x128, CIFAR-10, and robotic hand trajectories, achieving significantly better samples than other likelihood models and on par with contemporary GAN approaches, while covering all modes of the data. We highlight unique capabilities of implicit generation, such as energy compositionality and corrupt image reconstruction and completion. Finally, we show that EBMs generalize well and are able to achieve state-of-the-art out-of-distribution classification, exhibit adversarially robust classification, coherent long term predicted trajectory roll-outs, and generate zero-shot compositions of models.
Neural MMO: A Massively Multiagent Game Environment for Training and Evaluating Intelligent Agents
Mar 02, 2019



The emergence of complex life on Earth is often attributed to the arms race that ensued from a huge number of organisms all competing for finite resources. We present an artificial intelligence research environment, inspired by the human game genre of MMORPGs (Massively Multiplayer Online Role-Playing Games, a.k.a. MMOs), that aims to simulate this setting in microcosm. As with MMORPGs and the real world alike, our environment is persistent and supports a large and variable number of agents. Our environment is well suited to the study of large-scale multiagent interaction: it requires that agents learn robust combat and navigation policies in the presence of large populations attempting to do the same. Baseline experiments reveal that population size magnifies and incentivizes the development of skillful behaviors and results in agents that outcompete agents trained in smaller populations. We further show that the policies of agents with unshared weights naturally diverge to fill different niches in order to avoid competition.
Multi Agent Reinforcement Learning with Multi-Step Generative Models
Jan 29, 2019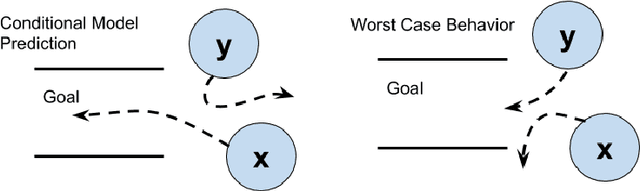

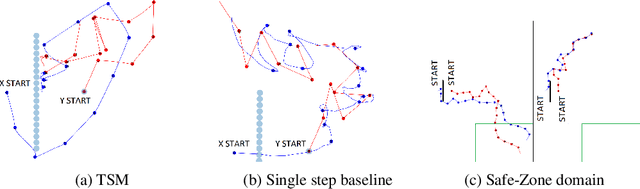

The dynamics between agents and the environment are an important component of multi-agent Reinforcement Learning (RL), and learning them provides a basis for decision making. However, a major challenge in optimizing a learned dynamics model is the accumulation of error when predicting multiple steps into the future. Recent advances in variational inference provide model based solutions that predict complete trajectory segments, and optimize over a latent representation of trajectories. For single-agent scenarios, several recent studies have explored this idea, and showed its benefits over conventional methods. In this work, we extend this approach to the multi-agent case, and effectively optimize over a latent space that encodes multi-agent strategies. We discuss the challenges in optimizing over a latent variable model for multiple agents, both in the optimization algorithm and in the model representation, and propose a method for both cooperative and competitive settings based on risk-sensitive optimization. We evaluate our method on tasks in the multi-agent particle environment and on a simulated RoboCup domain.