 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefense Against the Dark Arts: An overview of adversarial example security research and future research directions
Jun 11, 2018



This article presents a summary of a keynote lecture at the Deep Learning Security workshop at IEEE Security and Privacy 2018. This lecture summarizes the state of the art in defenses against adversarial examples and provides recommendations for future research directions on this topic.
Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
May 22, 2018
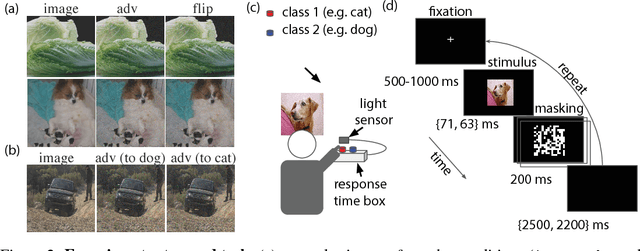
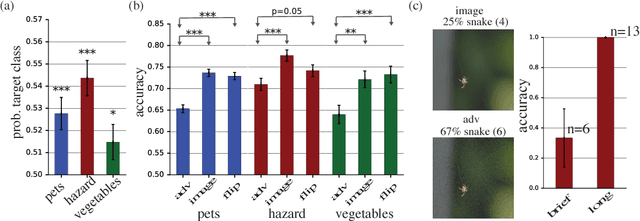
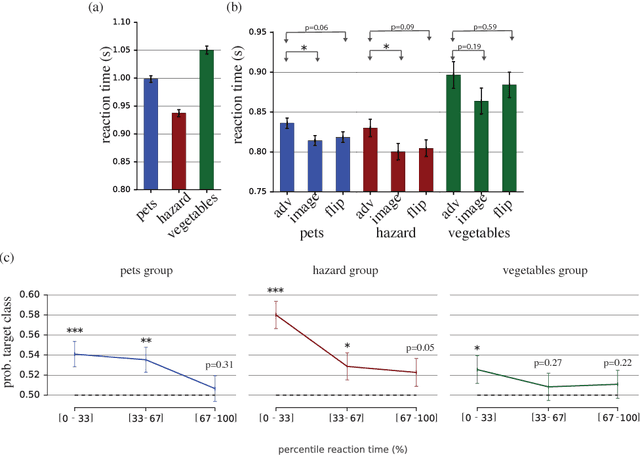
Machine learning models are vulnerable to adversarial examples: small changes to images can cause computer vision models to make mistakes such as identifying a school bus as an ostrich. However, it is still an open question whether humans are prone to similar mistakes. Here, we address this question by leveraging recent techniques that transfer adversarial examples from computer vision models with known parameters and architecture to other models with unknown parameters and architecture, and by matching the initial processing of the human visual system. We find that adversarial examples that strongly transfer across computer vision models influence the classifications made by time-limited human observers.
Self-Attention Generative Adversarial Networks
May 21, 2018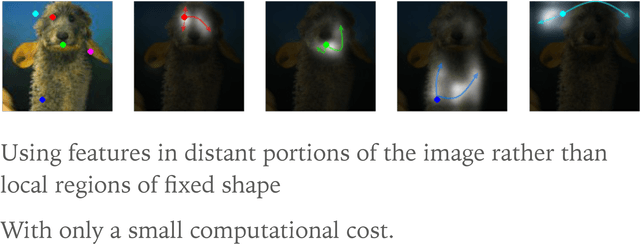
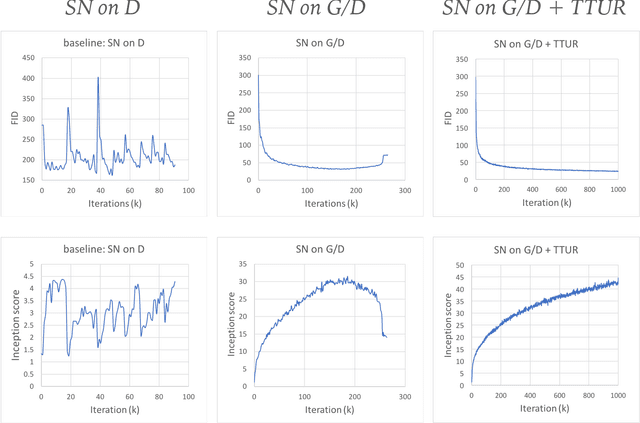

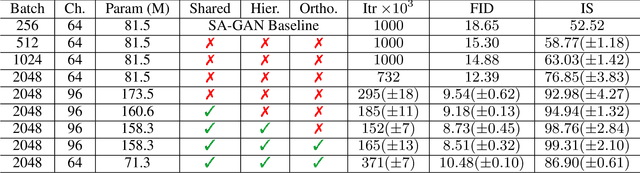
In this paper, we propose the Self-Attention Generative Adversarial Network (SAGAN) which allows attention-driven, long-range dependency modeling for image generation tasks. Traditional convolutional GANs generate high-resolution details as a function of only spatially local points in lower-resolution feature maps. In SAGAN, details can be generated using cues from all feature locations. Moreover, the discriminator can check that highly detailed features in distant portions of the image are consistent with each other. Furthermore, recent work has shown that generator conditioning affects GAN performance. Leveraging this insight, we apply spectral normalization to the GAN generator and find that this improves training dynamics. The proposed SAGAN achieves the state-of-the-art results, boosting the best published Inception score from 36.8 to 52.52 and reducing Frechet Inception distance from 27.62 to 18.65 on the challenging ImageNet dataset. Visualization of the attention layers shows that the generator leverages neighborhoods that correspond to object shapes rather than local regions of fixed shape.
Gradient Masking Causes CLEVER to Overestimate Adversarial Perturbation Size
Apr 21, 2018
A key problem in research on adversarial examples is that vulnerability to adversarial examples is usually measured by running attack algorithms. Because the attack algorithms are not optimal, the attack algorithms are prone to overestimating the size of perturbation needed to fool the target model. In other words, the attack-based methodology provides an upper-bound on the size of a perturbation that will fool the model, but security guarantees require a lower bound. CLEVER is a proposed scoring method to estimate a lower bound. Unfortunately, an estimate of a bound is not a bound. In this report, we show that gradient masking, a common problem that causes attack methodologies to provide only a very loose upper bound, causes CLEVER to overestimate the size of perturbation needed to fool the model. In other words, CLEVER does not resolve the key problem with the attack-based methodology, because it fails to provide a lower bound.
Adversarial Attacks and Defences Competition
Mar 31, 2018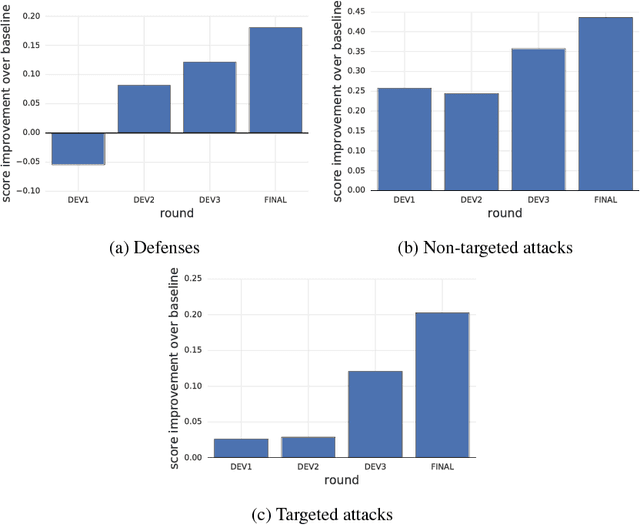
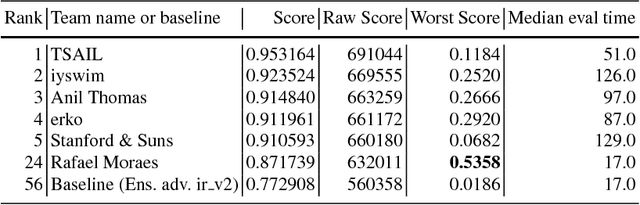
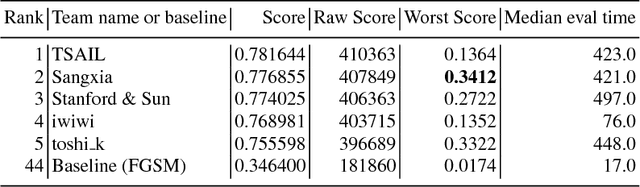
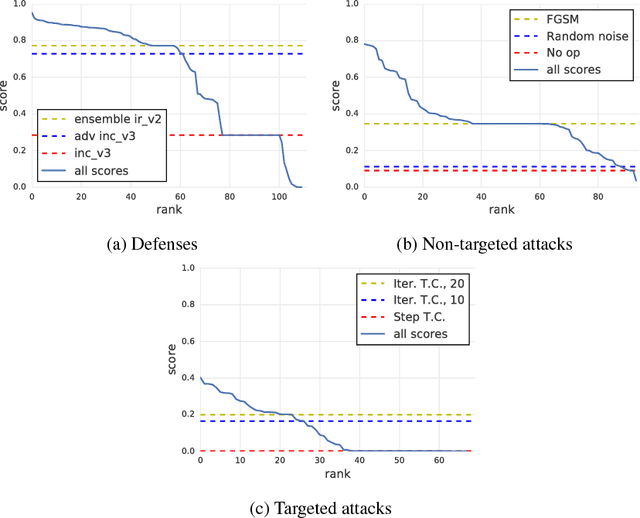
To accelerate research on adversarial examples and robustness of machine learning classifiers, Google Brain organized a NIPS 2017 competition that encouraged researchers to develop new methods to generate adversarial examples as well as to develop new ways to defend against them. In this chapter, we describe the structure and organization of the competition and the solutions developed by several of the top-placing teams.
Adversarial Logit Pairing
Mar 16, 2018
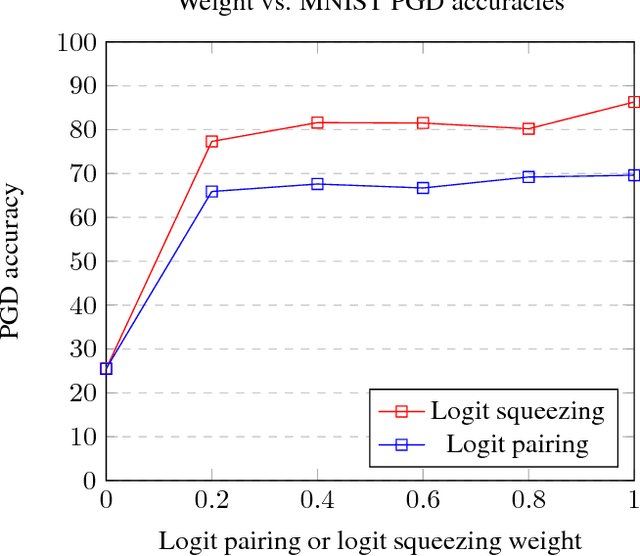

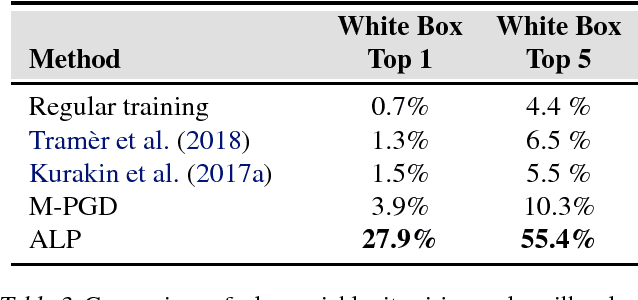
In this paper, we develop improved techniques for defending against adversarial examples at scale. First, we implement the state of the art version of adversarial training at unprecedented scale on ImageNet and investigate whether it remains effective in this setting - an important open scientific question (Athalye et al., 2018). Next, we introduce enhanced defenses using a technique we call logit pairing, a method that encourages logits for pairs of examples to be similar. When applied to clean examples and their adversarial counterparts, logit pairing improves accuracy on adversarial examples over vanilla adversarial training; we also find that logit pairing on clean examples only is competitive with adversarial training in terms of accuracy on two datasets. Finally, we show that adversarial logit pairing achieves the state of the art defense on ImageNet against PGD white box attacks, with an accuracy improvement from 1.5% to 27.9%. Adversarial logit pairing also successfully damages the current state of the art defense against black box attacks on ImageNet (Tramer et al., 2018), dropping its accuracy from 66.6% to 47.1%. With this new accuracy drop, adversarial logit pairing ties with Tramer et al.(2018) for the state of the art on black box attacks on ImageNet.
MaskGAN: Better Text Generation via Filling in the______
Mar 01, 2018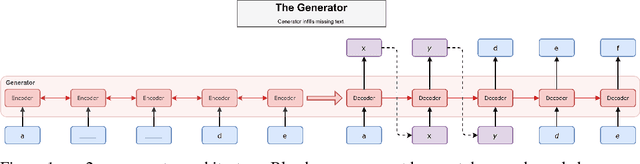


Neural text generation models are often autoregressive language models or seq2seq models. These models generate text by sampling words sequentially, with each word conditioned on the previous word, and are state-of-the-art for several machine translation and summarization benchmarks. These benchmarks are often defined by validation perplexity even though this is not a direct measure of the quality of the generated text. Additionally, these models are typically trained via maxi- mum likelihood and teacher forcing. These methods are well-suited to optimizing perplexity but can result in poor sample quality since generating text requires conditioning on sequences of words that may have never been observed at training time. We propose to improve sample quality using Generative Adversarial Networks (GANs), which explicitly train the generator to produce high quality samples and have shown a lot of success in image generation. GANs were originally designed to output differentiable values, so discrete language generation is challenging for them. We claim that validation perplexity alone is not indicative of the quality of text generated by a model. We introduce an actor-critic conditional GAN that fills in missing text conditioned on the surrounding context. We show qualitatively and quantitatively, evidence that this produces more realistic conditional and unconditional text samples compared to a maximum likelihood trained model.
Many Paths to Equilibrium: GANs Do Not Need to Decrease a Divergence At Every Step
Feb 20, 2018
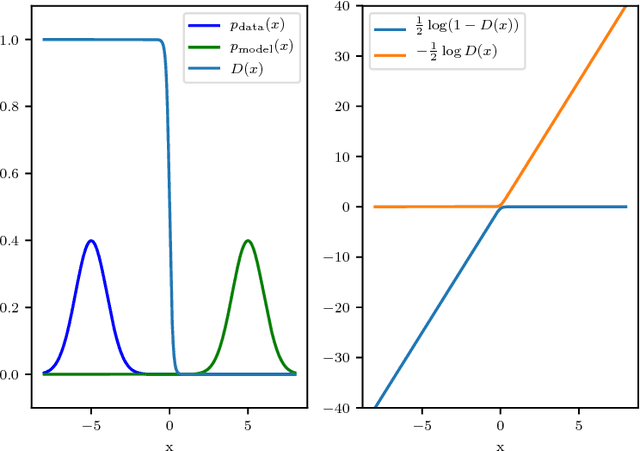
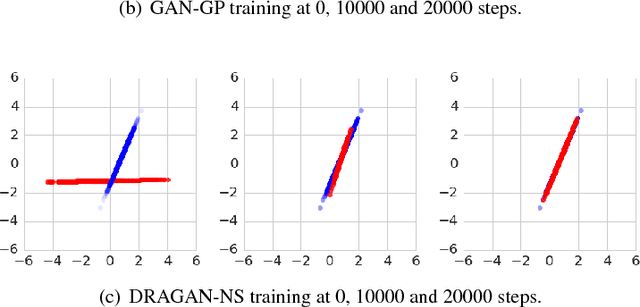
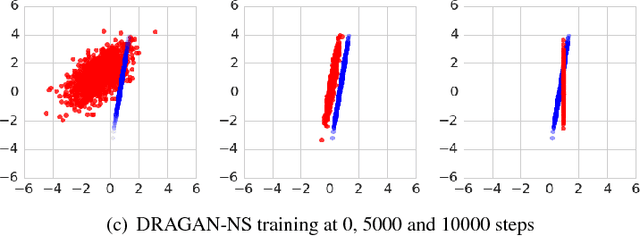
Generative adversarial networks (GANs) are a family of generative models that do not minimize a single training criterion. Unlike other generative models, the data distribution is learned via a game between a generator (the generative model) and a discriminator (a teacher providing training signal) that each minimize their own cost. GANs are designed to reach a Nash equilibrium at which each player cannot reduce their cost without changing the other players' parameters. One useful approach for the theory of GANs is to show that a divergence between the training distribution and the model distribution obtains its minimum value at equilibrium. Several recent research directions have been motivated by the idea that this divergence is the primary guide for the learning process and that every step of learning should decrease the divergence. We show that this view is overly restrictive. During GAN training, the discriminator provides learning signal in situations where the gradients of the divergences between distributions would not be useful. We provide empirical counterexamples to the view of GAN training as divergence minimization. Specifically, we demonstrate that GANs are able to learn distributions in situations where the divergence minimization point of view predicts they would fail. We also show that gradient penalties motivated from the divergence minimization perspective are equally helpful when applied in other contexts in which the divergence minimization perspective does not predict they would be helpful. This contributes to a growing body of evidence that GAN training may be more usefully viewed as approaching Nash equilibria via trajectories that do not necessarily minimize a specific divergence at each step.
On the Protection of Private Information in Machine Learning Systems: Two Recent Approaches
Aug 26, 2017The recent, remarkable growth of machine learning has led to intense interest in the privacy of the data on which machine learning relies, and to new techniques for preserving privacy. However, older ideas about privacy may well remain valid and useful. This note reviews two recent works on privacy in the light of the wisdom of some of the early literature, in particular the principles distilled by Saltzer and Schroeder in the 1970s.
The Space of Transferable Adversarial Examples
May 23, 2017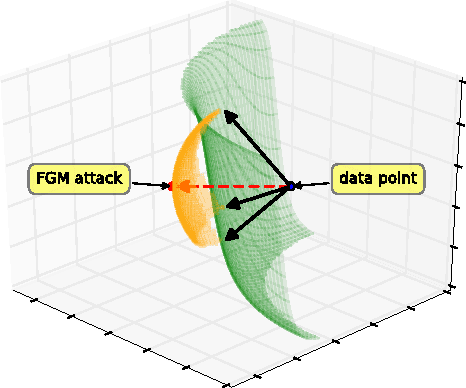

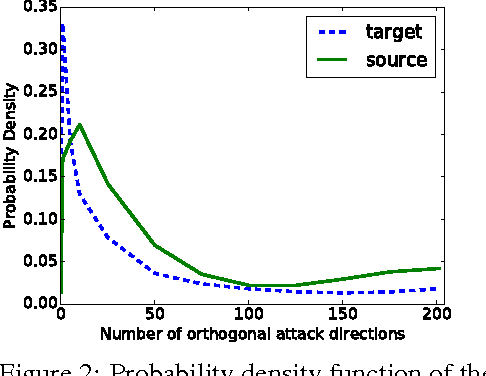
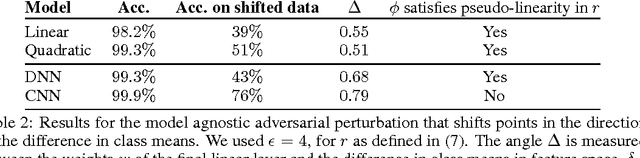
Adversarial examples are maliciously perturbed inputs designed to mislead machine learning (ML) models at test-time. They often transfer: the same adversarial example fools more than one model. In this work, we propose novel methods for estimating the previously unknown dimensionality of the space of adversarial inputs. We find that adversarial examples span a contiguous subspace of large (~25) dimensionality. Adversarial subspaces with higher dimensionality are more likely to intersect. We find that for two different models, a significant fraction of their subspaces is shared, thus enabling transferability. In the first quantitative analysis of the similarity of different models' decision boundaries, we show that these boundaries are actually close in arbitrary directions, whether adversarial or benign. We conclude by formally studying the limits of transferability. We derive (1) sufficient conditions on the data distribution that imply transferability for simple model classes and (2) examples of scenarios in which transfer does not occur. These findings indicate that it may be possible to design defenses against transfer-based attacks, even for models that are vulnerable to direct attacks.