 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalized Source Tracing for Codec-Based Deepfake Speech
Jun 08, 2025Recent attempts at source tracing for codec-based deepfake speech (CodecFake), generated by neural audio codec-based speech generation (CoSG) models, have exhibited suboptimal performance. However, how to train source tracing models using simulated CoSG data while maintaining strong performance on real CoSG-generated audio remains an open challenge. In this paper, we show that models trained solely on codec-resynthesized data tend to overfit to non-speech regions and struggle to generalize to unseen content. To mitigate these challenges, we introduce the Semantic-Acoustic Source Tracing Network (SASTNet), which jointly leverages Whisper for semantic feature encoding and Wav2vec2 with AudioMAE for acoustic feature encoding. Our proposed SASTNet achieves state-of-the-art performance on the CoSG test set of the CodecFake+ dataset, demonstrating its effectiveness for reliable source tracing.
Multi-Distillation from Speech and Music Representation Models
Jun 08, 2025



Real-world audio often mixes speech and music, yet models typically handle only one domain. This paper introduces a multi-teacher distillation framework that unifies speech and music models into a single one while significantly reducing model size. Our approach leverages the strengths of domain-specific teacher models, such as HuBERT for speech and MERT for music, and explores various strategies to balance both domains. Experiments across diverse tasks demonstrate that our model matches the performance of domain-specific models, showing the effectiveness of cross-domain distillation. Additionally, we conduct few-shot learning experiments, highlighting the need for general models in real-world scenarios where labeled data is limited. Our results show that our model not only performs on par with specialized models but also outperforms them in few-shot scenarios, proving that a cross-domain approach is essential and effective for diverse tasks with limited data.
Reducing Object Hallucination in Large Audio-Language Models via Audio-Aware Decoding
Jun 08, 2025Large Audio-Language Models (LALMs) can take audio and text as the inputs and answer questions about the audio. While prior LALMs have shown strong performance on standard benchmarks, there has been alarming evidence that LALMs can hallucinate what is presented in the audio. To mitigate the hallucination of LALMs, we introduce Audio-Aware Decoding (AAD), a lightweight inference-time strategy that uses contrastive decoding to compare the token prediction logits with and without the audio context. By contrastive decoding, AAD promotes the tokens whose probability increases when the audio is present. We conduct our experiment on object hallucination datasets with three LALMs and show that AAD improves the F1 score by 0.046 to 0.428. We also show that AAD can improve the accuracy on general audio QA datasets like Clotho-AQA by 5.4% to 10.3%. We conduct thorough ablation studies to understand the effectiveness of each component in AAD.
CO-VADA: A Confidence-Oriented Voice Augmentation Debiasing Approach for Fair Speech Emotion Recognition
Jun 06, 2025Bias in speech emotion recognition (SER) systems often stems from spurious correlations between speaker characteristics and emotional labels, leading to unfair predictions across demographic groups. Many existing debiasing methods require model-specific changes or demographic annotations, limiting their practical use. We present CO-VADA, a Confidence-Oriented Voice Augmentation Debiasing Approach that mitigates bias without modifying model architecture or relying on demographic information. CO-VADA identifies training samples that reflect bias patterns present in the training data and then applies voice conversion to alter irrelevant attributes and generate samples. These augmented samples introduce speaker variations that differ from dominant patterns in the data, guiding the model to focus more on emotion-relevant features. Our framework is compatible with various SER models and voice conversion tools, making it a scalable and practical solution for improving fairness in SER systems.
Audio-Aware Large Language Models as Judges for Speaking Styles
Jun 06, 2025Audio-aware large language models (ALLMs) can understand the textual and non-textual information in the audio input. In this paper, we explore using ALLMs as an automatic judge to assess the speaking styles of speeches. We use ALLM judges to evaluate the speeches generated by SLMs on two tasks: voice style instruction following and role-playing. The speaking style we consider includes emotion, volume, speaking pace, word emphasis, pitch control, and non-verbal elements. We use four spoken language models (SLMs) to complete the two tasks and use humans and ALLMs to judge the SLMs' responses. We compare two ALLM judges, GPT-4o-audio and Gemini-2.5-pro, with human evaluation results and show that the agreement between Gemini and human judges is comparable to the agreement between human evaluators. These promising results show that ALLMs can be used as a judge to evaluate SLMs. Our results also reveal that current SLMs, even GPT-4o-audio, still have room for improvement in controlling the speaking style and generating natural dialogues.
EMO-Debias: Benchmarking Gender Debiasing Techniques in Multi-Label Speech Emotion Recognition
Jun 05, 2025Speech emotion recognition (SER) systems often exhibit gender bias. However, the effectiveness and robustness of existing debiasing methods in such multi-label scenarios remain underexplored. To address this gap, we present EMO-Debias, a large-scale comparison of 13 debiasing methods applied to multi-label SER. Our study encompasses techniques from pre-processing, regularization, adversarial learning, biased learners, and distributionally robust optimization. Experiments conducted on acted and naturalistic emotion datasets, using WavLM and XLSR representations, evaluate each method under conditions of gender imbalance. Our analysis quantifies the trade-offs between fairness and accuracy, identifying which approaches consistently reduce gender performance gaps without compromising overall model performance. The findings provide actionable insights for selecting effective debiasing strategies and highlight the impact of dataset distributions.
AudioLens: A Closer Look at Auditory Attribute Perception of Large Audio-Language Models
Jun 05, 2025Understanding the internal mechanisms of large audio-language models (LALMs) is crucial for interpreting their behavior and improving performance. This work presents the first in-depth analysis of how LALMs internally perceive and recognize auditory attributes. By applying vocabulary projection on three state-of-the-art LALMs, we track how attribute information evolves across layers and token positions. We find that attribute information generally decreases with layer depth when recognition fails, and that resolving attributes at earlier layers correlates with better accuracy. Moreover, LALMs heavily rely on querying auditory inputs for predicting attributes instead of aggregating necessary information in hidden states at attribute-mentioning positions. Based on our findings, we demonstrate a method to enhance LALMs. Our results offer insights into auditory attribute processing, paving the way for future improvements.
Creativity in LLM-based Multi-Agent Systems: A Survey
May 27, 2025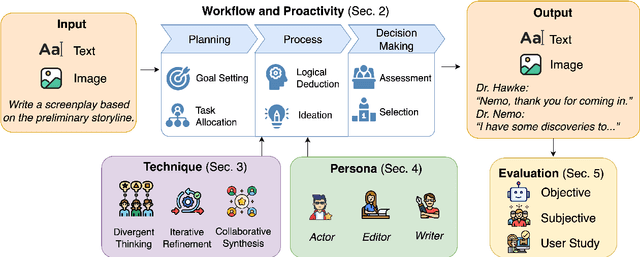
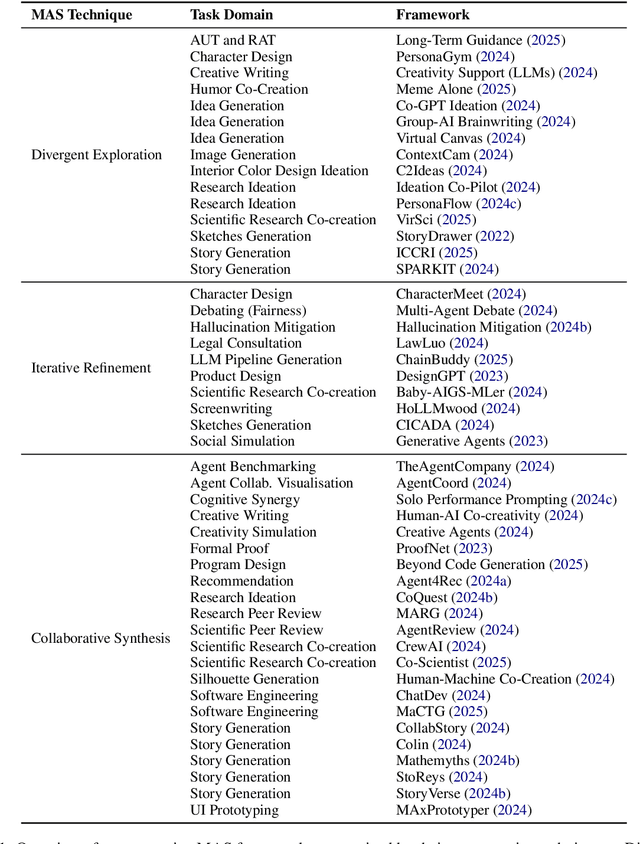
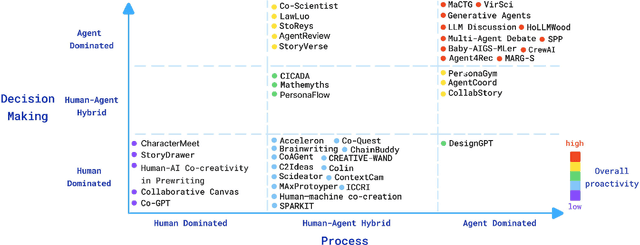
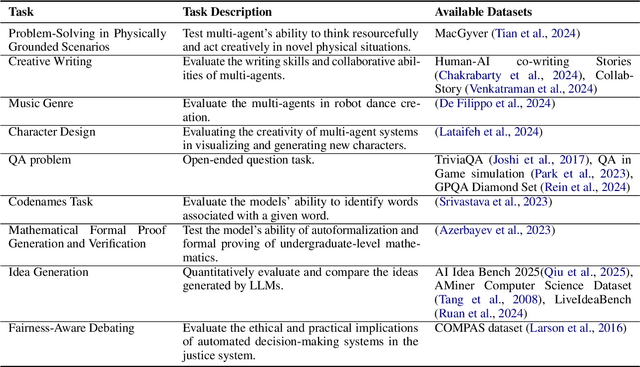
Large language model (LLM)-driven multi-agent systems (MAS) are transforming how humans and AIs collaboratively generate ideas and artifacts. While existing surveys provide comprehensive overviews of MAS infrastructures, they largely overlook the dimension of \emph{creativity}, including how novel outputs are generated and evaluated, how creativity informs agent personas, and how creative workflows are coordinated. This is the first survey dedicated to creativity in MAS. We focus on text and image generation tasks, and present: (1) a taxonomy of agent proactivity and persona design; (2) an overview of generation techniques, including divergent exploration, iterative refinement, and collaborative synthesis, as well as relevant datasets and evaluation metrics; and (3) a discussion of key challenges, such as inconsistent evaluation standards, insufficient bias mitigation, coordination conflicts, and the lack of unified benchmarks. This survey offers a structured framework and roadmap for advancing the development, evaluation, and standardization of creative MAS.
From Alignment to Advancement: Bootstrapping Audio-Language Alignment with Synthetic Data
May 26, 2025Audio-aware large language models (ALLMs) have recently made great strides in understanding and processing audio inputs. These models are typically adapted from text-based large language models (LLMs) through additional training on audio-related tasks. However, this adaptation process presents two major limitations. First, ALLMs often suffer from catastrophic forgetting, where important textual capabilities such as instruction-following are lost after training on audio data. In some cases, models may even hallucinate sounds that are not present in the input audio, raising concerns about their reliability. Second, achieving cross-modal alignment between audio and language typically relies on large collections of task-specific question-answer pairs for instruction tuning, making the process resource-intensive. To address these issues, we leverage the backbone LLMs from ALLMs to synthesize general-purpose caption-style alignment data. We refer to this process as bootstrapping audio-language alignment via synthetic data generation from backbone LLMs (BALSa). Building on BALSa, we introduce LISTEN (Learning to Identify Sounds Through Extended Negative Samples), a contrastive-like training method designed to improve ALLMs' ability to distinguish between present and absent sounds. We further extend BALSa to multi-audio scenarios, where the model either explains the differences between audio inputs or produces a unified caption that describes them all, thereby enhancing audio-language alignment. Experimental results indicate that our method effectively mitigates audio hallucinations while reliably maintaining strong performance in audio understanding, reasoning, and instruction-following skills. Moreover, incorporating multi-audio training further enhances the model's comprehension and reasoning capabilities. Overall, BALSa offers an efficient and scalable approach to the development of ALLMs.
Speech-IFEval: Evaluating Instruction-Following and Quantifying Catastrophic Forgetting in Speech-Aware Language Models
May 25, 2025We introduce Speech-IFeval, an evaluation framework designed to assess instruction-following capabilities and quantify catastrophic forgetting in speech-aware language models (SLMs). Recent SLMs integrate speech perception with large language models (LLMs), often degrading textual capabilities due to speech-centric training. Existing benchmarks conflate speech perception with instruction-following, hindering evaluation of these distinct skills. To address this gap, we provide a benchmark for diagnosing the instruction-following abilities of SLMs. Our findings show that most SLMs struggle with even basic instructions, performing far worse than text-based LLMs. Additionally, these models are highly sensitive to prompt variations, often yielding inconsistent and unreliable outputs. We highlight core challenges and provide insights to guide future research, emphasizing the need for evaluation beyond task-level metrics.