 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforce to Learn, Elect to Reason: A Dual Paradigm for Video Reasoning
Apr 06, 2026Video reasoning has advanced with large multimodal models (LMMs), yet their inference is often a single pass that returns an answer without verifying whether the reasoning is evidence-aligned. We introduce Reinforce to Learn, Elect to Reason (RLER), a dual paradigm that decouples learning to produce evidence from obtaining a reliable answer. In RLER-Training, we optimize the policy with group-relative reinforcement learning (RL) and 3 novel task-driven rewards: Frame-sensitive reward grounds reasoning on explicit key frames, Think-transparency reward shapes readable and parsable reasoning traces, and Anti-repetition reward boosts information density. These signals teach the model to emit structured, machine-checkable evidence and potentiate reasoning capabilities. In RLER-Inference, we apply a train-free orchestrator that generates a small set of diverse candidates, parses their answers and cited frames, scores them by evidence consistency, confidence, transparency, and non-redundancy, and then performs a robust evidence-weighted election. This closes the loop between producing and using evidence, improving reliability and interpretability without enlarging the model. We comprehensively evaluate RLER against various open-source and RL-based LMMs on 8 representative benchmarks. RLER achieves state of the art across all benchmarks and delivers an average improvement of 6.3\% over base models, while using on average 3.1 candidates per question, indicating a favorable balance between compute and quality. The results support a simple thesis: making evidence explicit during learning and electing by evidence during inference is a robust path to trustworthy video reasoning.
Graph-to-Frame RAG: Visual-Space Knowledge Fusion for Training-Free and Auditable Video Reasoning
Apr 06, 2026When video reasoning requires external knowledge, many systems with large multimodal models (LMMs) adopt retrieval augmentation to supply the missing context. Appending textual or multi-clip evidence, however, forces heterogeneous signals into a single attention space. We observe diluted attention and higher cognitive load even on non-long videos. The bottleneck is not only what to retrieve but how to represent and fuse external knowledge with the video backbone.We present Graph-to-Frame RAG (G2F-RAG), a training free and auditable paradigm that delivers knowledge in the visual space. On the offline stage, an agent builds a problem-agnostic video knowledge graph that integrates entities, events, spatial relations, and linked world knowledge. On the online stage, a hierarchical multi-agent controller decides whether external knowledge is needed, retrieves a minimal sufficient subgraph, and renders it as a single reasoning frame appended to the video. LMMs then perform joint reasoning in a unified visual domain. This design reduces cognitive load and leaves an explicit, inspectable evidence trail.G2F-RAG is plug-and-play across backbones and scales. It yields consistent gains on diverse public benchmarks, with larger improvements in knowledge-intensive settings. Ablations further confirm that knowledge representation and delivery matter. G2F-RAG reframes retrieval as visual space knowledge fusion for robust and interpretable video reasoning.
BeyondFacial: Identity-Preserving Personalized Generation Beyond Facial Close-ups
Nov 15, 2025



Identity-Preserving Personalized Generation (IPPG) has advanced film production and artistic creation, yet existing approaches overemphasize facial regions, resulting in outputs dominated by facial close-ups.These methods suffer from weak visual narrativity and poor semantic consistency under complex text prompts, with the core limitation rooted in identity (ID) feature embeddings undermining the semantic expressiveness of generative models. To address these issues, this paper presents an IPPG method that breaks the constraint of facial close-ups, achieving synergistic optimization of identity fidelity and scene semantic creation. Specifically, we design a Dual-Line Inference (DLI) pipeline with identity-semantic separation, resolving the representation conflict between ID and semantics inherent in traditional single-path architectures. Further, we propose an Identity Adaptive Fusion (IdAF) strategy that defers ID-semantic fusion to the noise prediction stage, integrating adaptive attention fusion and noise decision masking to avoid ID embedding interference on semantics without manual masking. Finally, an Identity Aggregation Prepending (IdAP) module is introduced to aggregate ID information and replace random initializations, further enhancing identity preservation. Experimental results validate that our method achieves stable and effective performance in IPPG tasks beyond facial close-ups, enabling efficient generation without manual masking or fine-tuning. As a plug-and-play component, it can be rapidly deployed in existing IPPG frameworks, addressing the over-reliance on facial close-ups, facilitating film-level character-scene creation, and providing richer personalized generation capabilities for related domains.
Impact of Light and Shadow on Robustness of Deep Neural Networks
May 23, 2023Deep neural networks (DNNs) have made remarkable strides in various computer vision tasks, including image classification, segmentation, and object detection. However, recent research has revealed a vulnerability in advanced DNNs when faced with deliberate manipulations of input data, known as adversarial attacks. Moreover, the accuracy of DNNs is heavily influenced by the distribution of the training dataset. Distortions or perturbations in the color space of input images can introduce out-of-distribution data, resulting in misclassification. In this work, we propose a brightness-variation dataset, which incorporates 24 distinct brightness levels for each image within a subset of ImageNet. This dataset enables us to simulate the effects of light and shadow on the images, so as is to investigate the impact of light and shadow on the performance of DNNs. In our study, we conduct experiments using several state-of-the-art DNN architectures on the aforementioned dataset. Through our analysis, we discover a noteworthy positive correlation between the brightness levels and the loss of accuracy in DNNs. Furthermore, we assess the effectiveness of recently proposed robust training techniques and strategies, including AugMix, Revisit, and Free Normalizer, using the ResNet50 architecture on our brightness-variation dataset. Our experimental results demonstrate that these techniques can enhance the robustness of DNNs against brightness variation, leading to improved performance when dealing with images exhibiting varying brightness levels.
Mini-data-driven Deep Arbitrary Polynomial Chaos Expansion for Uncertainty Quantification
Jul 22, 2021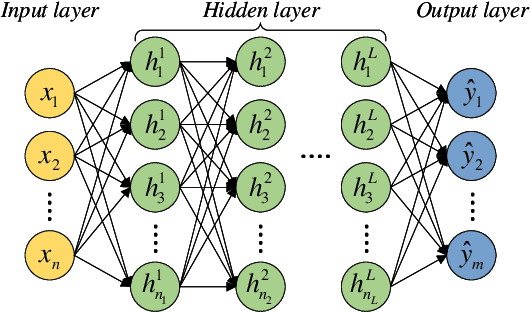
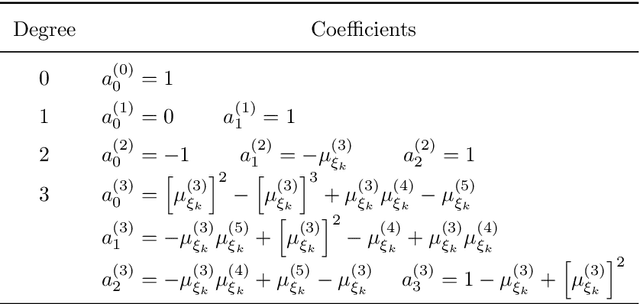
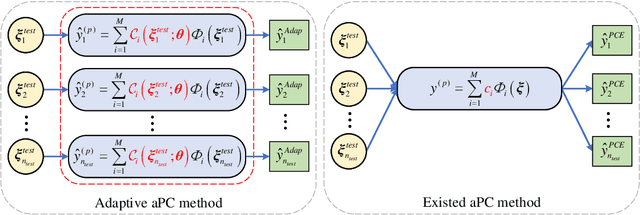
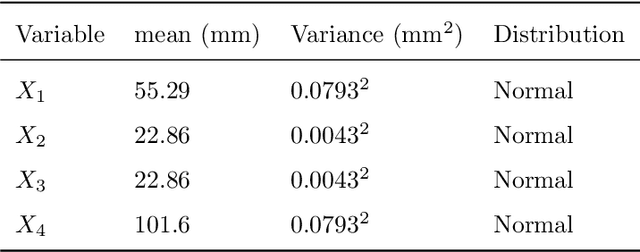
The surrogate model-based uncertainty quantification method has drawn a lot of attention in recent years. Both the polynomial chaos expansion (PCE) and the deep learning (DL) are powerful methods for building a surrogate model. However, the PCE needs to increase the expansion order to improve the accuracy of the surrogate model, which causes more labeled data to solve the expansion coefficients, and the DL also needs a lot of labeled data to train the neural network model. This paper proposes a deep arbitrary polynomial chaos expansion (Deep aPCE) method to improve the balance between surrogate model accuracy and training data cost. On the one hand, the multilayer perceptron (MLP) model is used to solve the adaptive expansion coefficients of arbitrary polynomial chaos expansion, which can improve the Deep aPCE model accuracy with lower expansion order. On the other hand, the adaptive arbitrary polynomial chaos expansion's properties are used to construct the MLP training cost function based on only a small amount of labeled data and a large scale of non-labeled data, which can significantly reduce the training data cost. Four numerical examples and an actual engineering problem are used to verify the effectiveness of the Deep aPCE method.