 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuartet Logic: A Four-Step Reasoning framework for advancing Short Text Classification
Jan 06, 2024



Short Text Classification (STC) is crucial for processing and comprehending the brief but substantial content prevalent on contemporary digital platforms. The STC encounters difficulties in grasping semantic and syntactic intricacies, an issue that is apparent in traditional pre-trained language models. Although Graph Convolutional Networks enhance performance by integrating external knowledge bases, these methods are limited by the quality and extent of the knowledge applied. Recently, the emergence of Large Language Models (LLMs) and Chain-of-Thought (CoT) has significantly improved the performance of complex reasoning tasks. However, some studies have highlighted the limitations of their application in fundamental NLP tasks. Consequently, this study sought to employ CoT to investigate the capabilities of LLMs in STC tasks. This study introduces Quartet Logic: A Four-Step Reasoning (QLFR) framework. This framework primarily incorporates Syntactic and Semantic Enrichment CoT, effectively decomposing the STC task into four distinct steps: (i) essential concept identification, (ii) common-sense knowledge retrieval, (iii) text rewriting, and (iv) classification. This elicits the inherent knowledge and abilities of LLMs to address the challenges in STC. Surprisingly, we found that QLFR can also improve the performance of smaller models. Therefore, we developed a CoT-Driven Multi-task learning (QLFR-CML) method to facilitate the knowledge transfer from LLMs to smaller models. Extensive experimentation across six short-text benchmarks validated the efficacy of the proposed methods. Notably, QLFR achieved state-of-the-art performance on all datasets, with significant improvements, particularly on the Ohsumed and TagMyNews datasets.
HeightFormer: A Multilevel Interaction and Image-adaptive Classification-regression Network for Monocular Height Estimation with Aerial Images
Oct 12, 2023



Height estimation has long been a pivotal topic within measurement and remote sensing disciplines, proving critical for endeavours such as 3D urban modelling, MR and autonomous driving. Traditional methods utilise stereo matching or multisensor fusion, both well-established techniques that typically necessitate multiple images from varying perspectives and adjunct sensors like SAR, leading to substantial deployment costs. Single image height estimation has emerged as an attractive alternative, boasting a larger data source variety and simpler deployment. However, current methods suffer from limitations such as fixed receptive fields, a lack of global information interaction, leading to noticeable instance-level height deviations. The inherent complexity of height prediction can result in a blurry estimation of object edge depth when using mainstream regression methods based on fixed height division. This paper presents a comprehensive solution for monocular height estimation in remote sensing, termed HeightFormer, combining multilevel interactions and image-adaptive classification-regression. It features the Multilevel Interaction Backbone (MIB) and Image-adaptive Classification-regression Height Generator (ICG). MIB supplements the fixed sample grid in CNN of the conventional backbone network with tokens of different interaction ranges. It is complemented by a pixel-, patch-, and feature map-level hierarchical interaction mechanism, designed to relay spatial geometry information across different scales and introducing a global receptive field to enhance the quality of instance-level height estimation. The ICG dynamically generates height partition for each image and reframes the traditional regression task, using a refinement from coarse to fine classification-regression that significantly mitigates the innate ill-posedness issue and drastically improves edge sharpness.
A 97 fJ/Conversion Neuron-ADC with Reconfigurable Sampling and Static Power Reduction
Nov 28, 2022



A bio-inspired Neuron-ADC with reconfigurable sampling and static power reduction for biomedical applications is proposed in this work. The Neuron-ADC leverages level-crossing sampling and a bio-inspired refractory circuit to compressively converts bio-signal to digital spikes and information-of-interest. The proposed design can not only avoid dissipating ADC energy on unnecessary data but also achieve reconfigurable sampling, making it appropriate for either low power operation or high accuracy conversion when dealing with various kinds of bio-signals. Moreover, the proposed dynamic comparator can reduce static power up to 41.1% when tested with a 10 kHz sinusoidal input. Simulation results of 40 nm CMOS process show that the Neuron-ADC achieves a maximum ENOB of 6.9 bits with a corresponding FoM of 97 fJ/conversion under 0.6 V supply voltage.
Recent Trends and Future Prospects of Neural Recording Circuits and Systems: A Tutorial Brief
May 27, 2022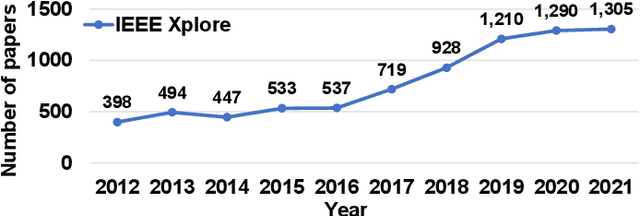
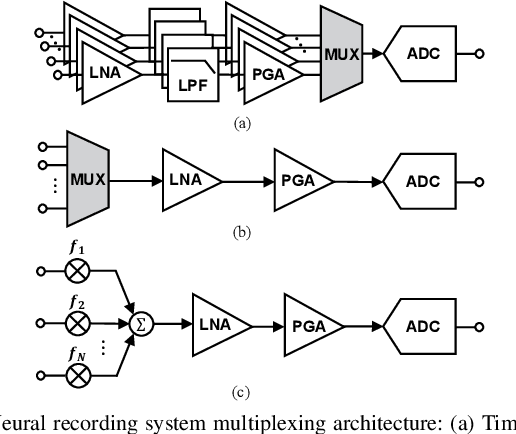
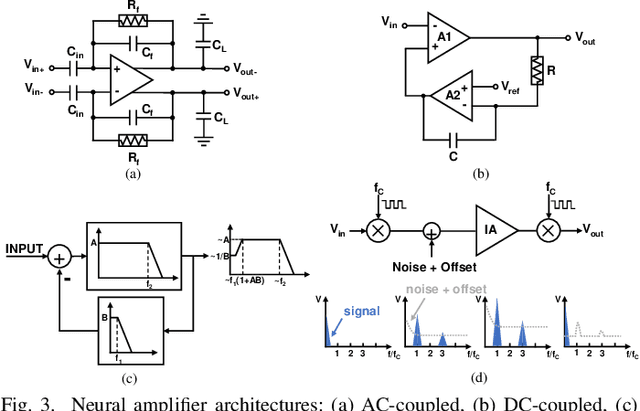
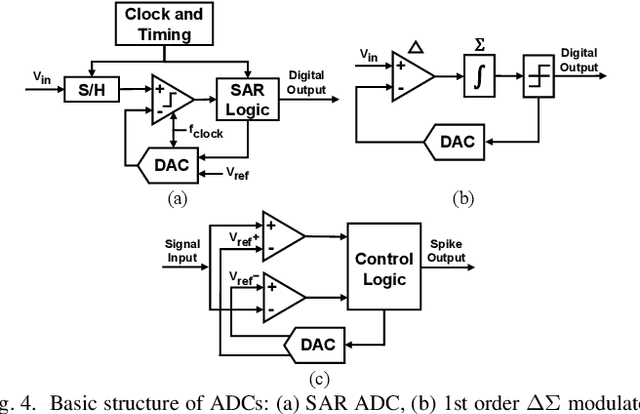
Recent years have seen fast advances in neural recording circuits and systems as they offer a promising way to investigate real-time brain monitoring and the closed-loop modulation of psychological disorders and neurodegenerative diseases. In this context, this tutorial brief presents a concise overview of concepts and design methodologies of neural recording, highlighting neural signal characteristics, system-level specifications and architectures, circuit-level implementation, and noise reduction techniques. Future trends and challenges of neural recording are finally discussed.
SimVQA: Exploring Simulated Environments for Visual Question Answering
Mar 31, 2022
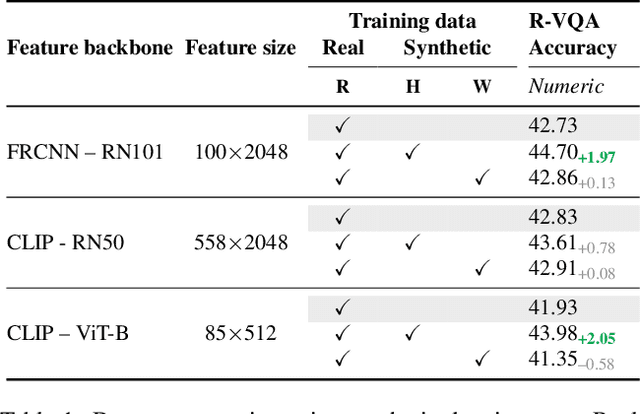
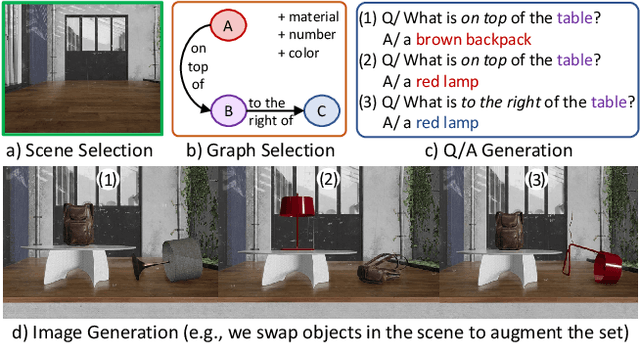
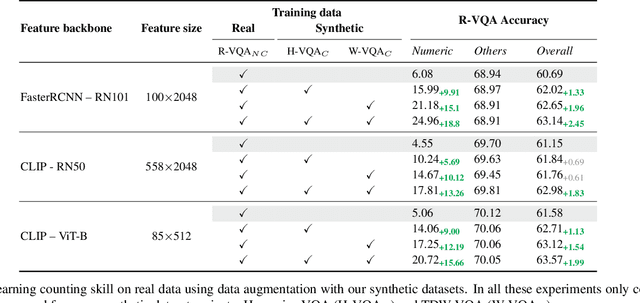
Existing work on VQA explores data augmentation to achieve better generalization by perturbing the images in the dataset or modifying the existing questions and answers. While these methods exhibit good performance, the diversity of the questions and answers are constrained by the available image set. In this work we explore using synthetic computer-generated data to fully control the visual and language space, allowing us to provide more diverse scenarios. We quantify the effect of synthetic data in real-world VQA benchmarks and to which extent it produces results that generalize to real data. By exploiting 3D and physics simulation platforms, we provide a pipeline to generate synthetic data to expand and replace type-specific questions and answers without risking the exposure of sensitive or personal data that might be present in real images. We offer a comprehensive analysis while expanding existing hyper-realistic datasets to be used for VQA. We also propose Feature Swapping (F-SWAP) -- where we randomly switch object-level features during training to make a VQA model more domain invariant. We show that F-SWAP is effective for enhancing a currently existing VQA dataset of real images without compromising on the accuracy to answer existing questions in the dataset.
Learning Token-based Representation for Image Retrieval
Dec 12, 2021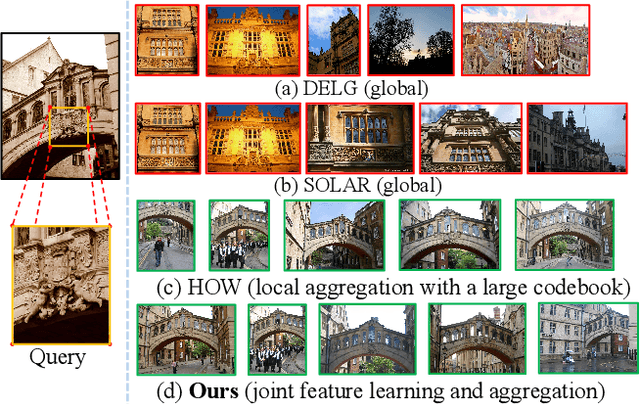
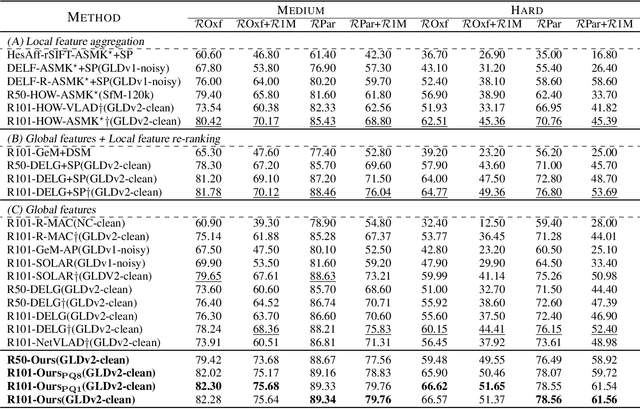
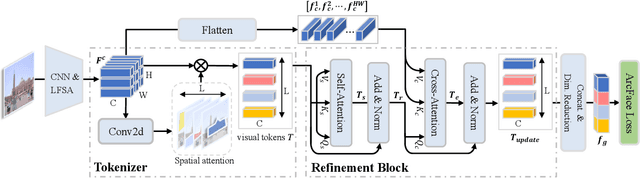
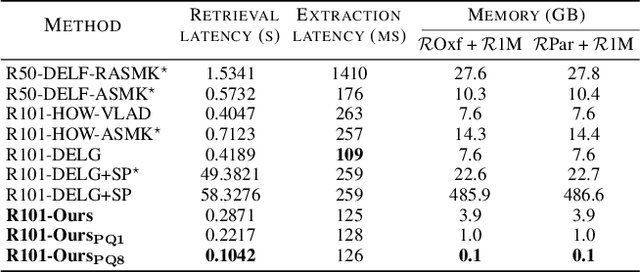
In image retrieval, deep local features learned in a data-driven manner have been demonstrated effective to improve retrieval performance. To realize efficient retrieval on large image database, some approaches quantize deep local features with a large codebook and match images with aggregated match kernel. However, the complexity of these approaches is non-trivial with large memory footprint, which limits their capability to jointly perform feature learning and aggregation. To generate compact global representations while maintaining regional matching capability, we propose a unified framework to jointly learn local feature representation and aggregation. In our framework, we first extract deep local features using CNNs. Then, we design a tokenizer module to aggregate them into a few visual tokens, each corresponding to a specific visual pattern. This helps to remove background noise, and capture more discriminative regions in the image. Next, a refinement block is introduced to enhance the visual tokens with self-attention and cross-attention. Finally, different visual tokens are concatenated to generate a compact global representation. The whole framework is trained end-to-end with image-level labels. Extensive experiments are conducted to evaluate our approach, which outperforms the state-of-the-art methods on the Revisited Oxford and Paris datasets.
Contextual Similarity Aggregation with Self-attention for Visual Re-ranking
Oct 26, 2021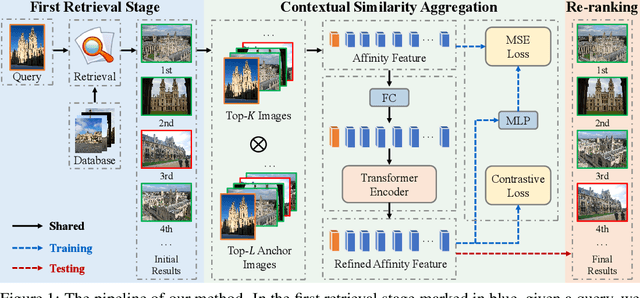
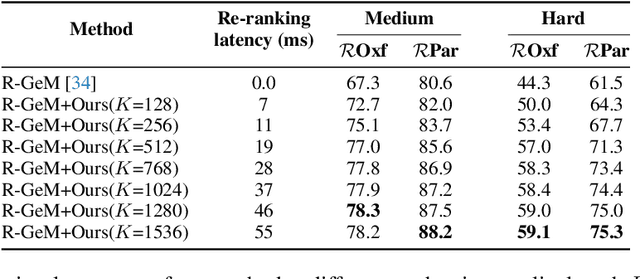
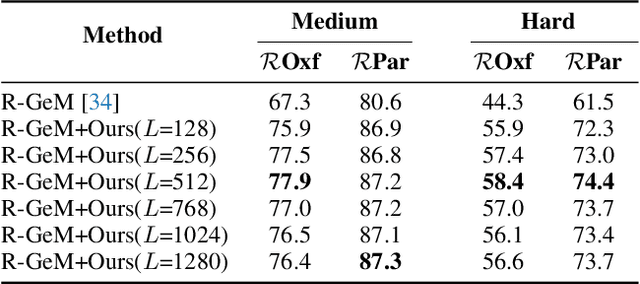
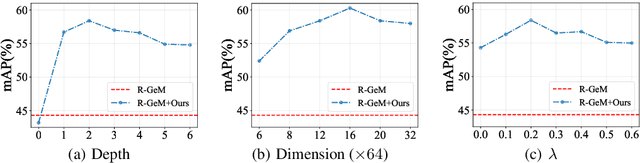
In content-based image retrieval, the first-round retrieval result by simple visual feature comparison may be unsatisfactory, which can be refined by visual re-ranking techniques. In image retrieval, it is observed that the contextual similarity among the top-ranked images is an important clue to distinguish the semantic relevance. Inspired by this observation, in this paper, we propose a visual re-ranking method by contextual similarity aggregation with self-attention. In our approach, for each image in the top-K ranking list, we represent it into an affinity feature vector by comparing it with a set of anchor images. Then, the affinity features of the top-K images are refined by aggregating the contextual information with a transformer encoder. Finally, the affinity features are used to recalculate the similarity scores between the query and the top-K images for re-ranking of the latter. To further improve the robustness of our re-ranking model and enhance the performance of our method, a new data augmentation scheme is designed. Since our re-ranking model is not directly involved with the visual feature used in the initial retrieval, it is ready to be applied to retrieval result lists obtained from various retrieval algorithms. We conduct comprehensive experiments on four benchmark datasets to demonstrate the generality and effectiveness of our proposed visual re-ranking method.
Separating Skills and Concepts for Novel Visual Question Answering
Jul 19, 2021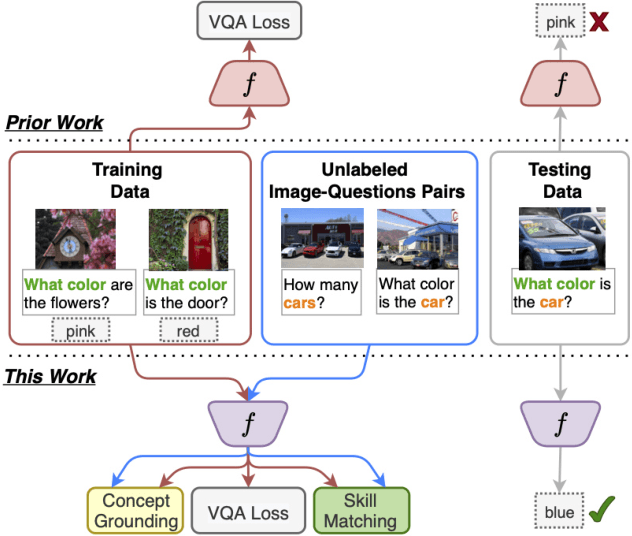
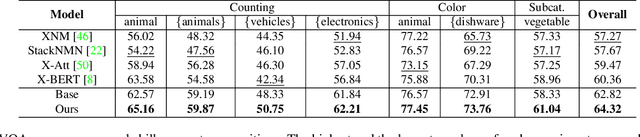
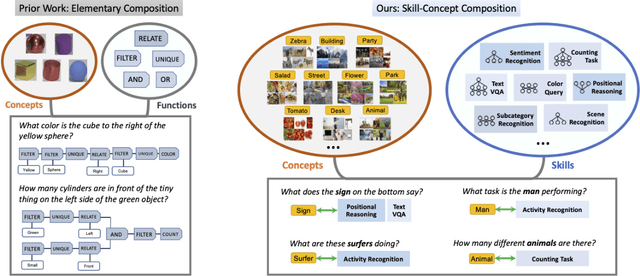
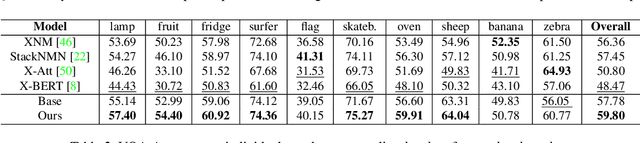
Generalization to out-of-distribution data has been a problem for Visual Question Answering (VQA) models. To measure generalization to novel questions, we propose to separate them into "skills" and "concepts". "Skills" are visual tasks, such as counting or attribute recognition, and are applied to "concepts" mentioned in the question, such as objects and people. VQA methods should be able to compose skills and concepts in novel ways, regardless of whether the specific composition has been seen in training, yet we demonstrate that existing models have much to improve upon towards handling new compositions. We present a novel method for learning to compose skills and concepts that separates these two factors implicitly within a model by learning grounded concept representations and disentangling the encoding of skills from that of concepts. We enforce these properties with a novel contrastive learning procedure that does not rely on external annotations and can be learned from unlabeled image-question pairs. Experiments demonstrate the effectiveness of our approach for improving compositional and grounding performance.
Learning from Lexical Perturbations for Consistent Visual Question Answering
Dec 23, 2020

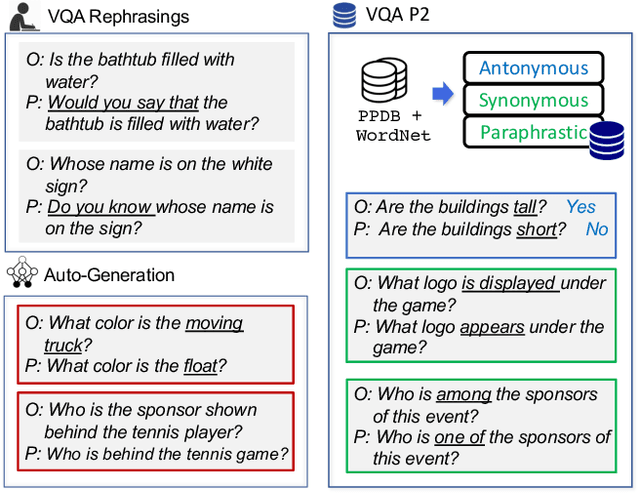
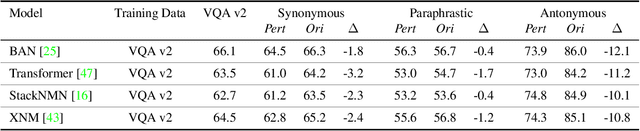
Existing Visual Question Answering (VQA) models are often fragile and sensitive to input variations. In this paper, we propose a novel approach to address this issue based on modular networks, which creates two questions related by linguistic perturbations and regularizes the visual reasoning process between them to be consistent during training. We show that our framework markedly improves consistency and generalization ability, demonstrating the value of controlled linguistic perturbations as a useful and currently underutilized training and regularization tool for VQA models. We also present VQA Perturbed Pairings (VQA P2), a new, low-cost benchmark and augmentation pipeline to create controllable linguistic variations of VQA questions. Our benchmark uniquely draws from large-scale linguistic resources, avoiding human annotation effort while maintaining data quality compared to generative approaches. We benchmark existing VQA models using VQA P2 and provide robustness analysis on each type of linguistic variation.
Large Scale Neural Architecture Search with Polyharmonic Splines
Nov 20, 2020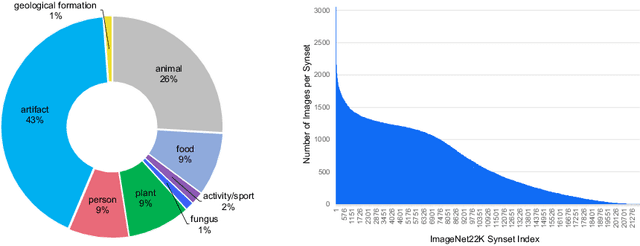
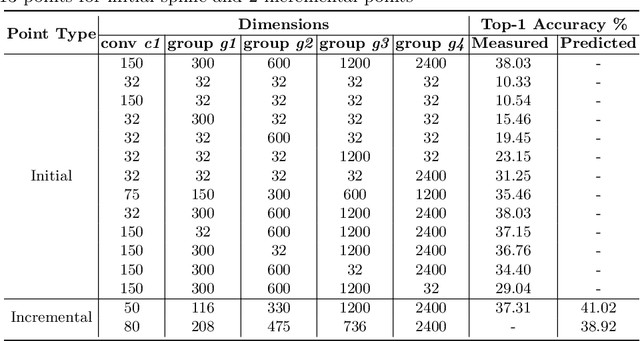
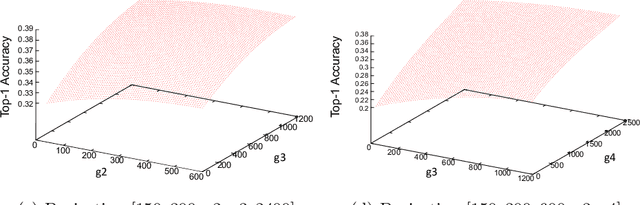
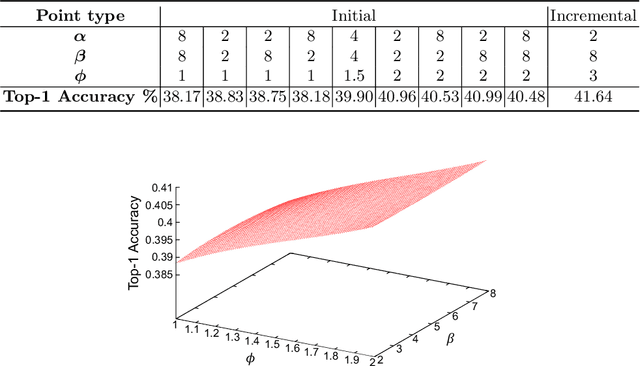
Neural Architecture Search (NAS) is a powerful tool to automatically design deep neural networks for many tasks, including image classification. Due to the significant computational burden of the search phase, most NAS methods have focused so far on small, balanced datasets. All attempts at conducting NAS at large scale have employed small proxy sets, and then transferred the learned architectures to larger datasets by replicating or stacking the searched cells. We propose a NAS method based on polyharmonic splines that can perform search directly on large scale, imbalanced target datasets. We demonstrate the effectiveness of our method on the ImageNet22K benchmark[16], which contains 14 million images distributed in a highly imbalanced manner over 21,841 categories. By exploring the search space of the ResNet [23] and Big-Little Net ResNext [11] architectures directly on ImageNet22K, our polyharmonic splines NAS method designed a model which achieved a top-1 accuracy of 40.03% on ImageNet22K, an absolute improvement of 3.13% over the state of the art with similar global batch size [15].