 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModulating early visual processing by language
Dec 18, 2017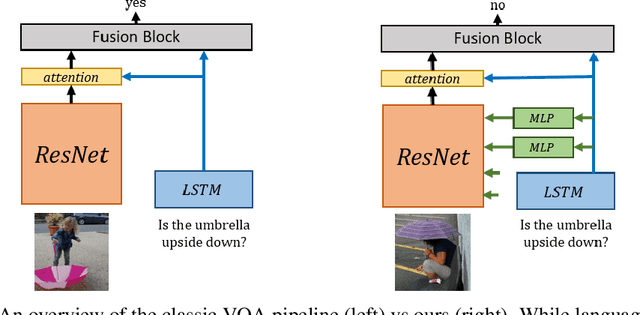
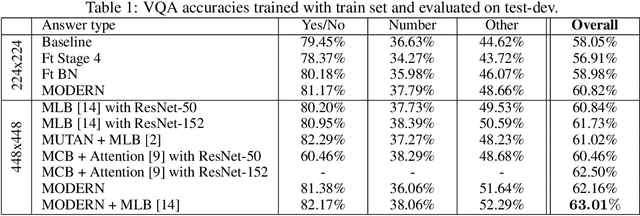
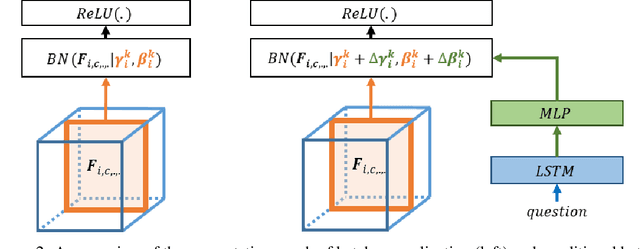
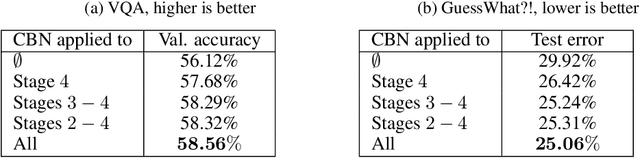
It is commonly assumed that language refers to high-level visual concepts while leaving low-level visual processing unaffected. This view dominates the current literature in computational models for language-vision tasks, where visual and linguistic input are mostly processed independently before being fused into a single representation. In this paper, we deviate from this classic pipeline and propose to modulate the \emph{entire visual processing} by linguistic input. Specifically, we condition the batch normalization parameters of a pretrained residual network (ResNet) on a language embedding. This approach, which we call MOdulated RESnet (\MRN), significantly improves strong baselines on two visual question answering tasks. Our ablation study shows that modulating from the early stages of the visual processing is beneficial.
HoME: a Household Multimodal Environment
Nov 29, 2017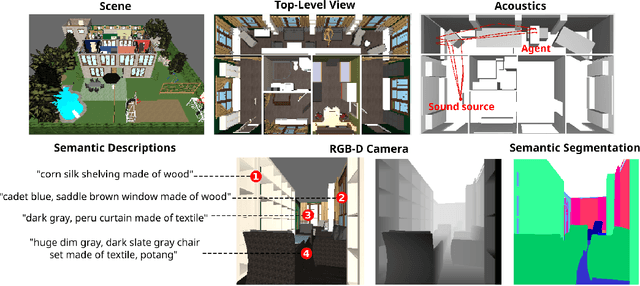


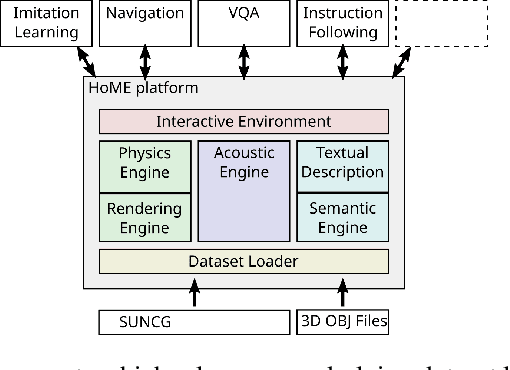
We introduce HoME: a Household Multimodal Environment for artificial agents to learn from vision, audio, semantics, physics, and interaction with objects and other agents, all within a realistic context. HoME integrates over 45,000 diverse 3D house layouts based on the SUNCG dataset, a scale which may facilitate learning, generalization, and transfer. HoME is an open-source, OpenAI Gym-compatible platform extensible to tasks in reinforcement learning, language grounding, sound-based navigation, robotics, multi-agent learning, and more. We hope HoME better enables artificial agents to learn as humans do: in an interactive, multimodal, and richly contextualized setting.
Multiscale sequence modeling with a learned dictionary
Jul 05, 2017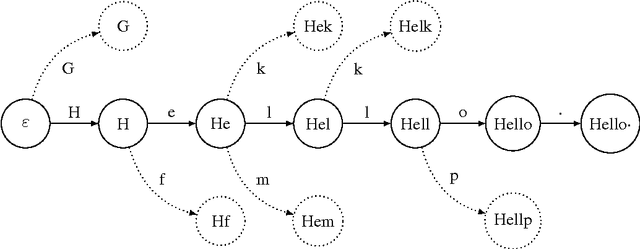

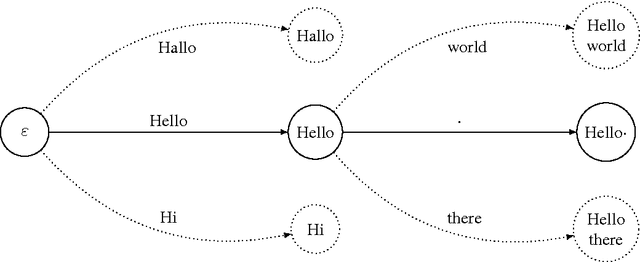

We propose a generalization of neural network sequence models. Instead of predicting one symbol at a time, our multi-scale model makes predictions over multiple, potentially overlapping multi-symbol tokens. A variation of the byte-pair encoding (BPE) compression algorithm is used to learn the dictionary of tokens that the model is trained with. When applied to language modelling, our model has the flexibility of character-level models while maintaining many of the performance benefits of word-level models. Our experiments show that this model performs better than a regular LSTM on language modeling tasks, especially for smaller models.
Recurrent Mixture Density Network for Spatiotemporal Visual Attention
Feb 11, 2017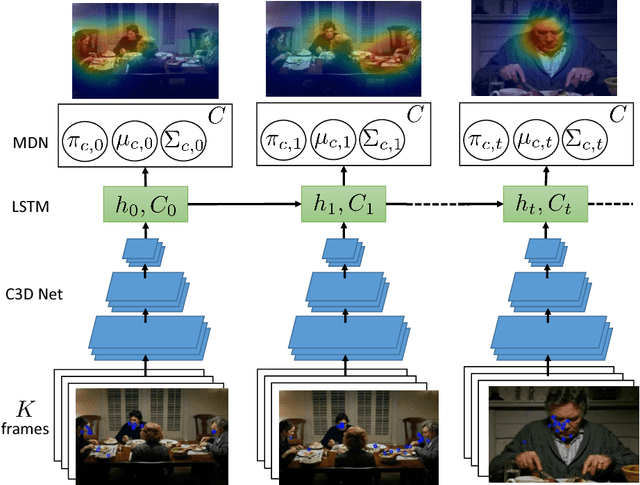
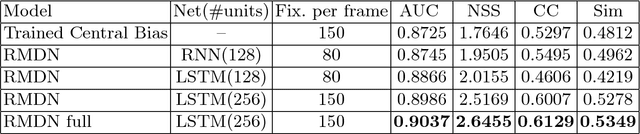
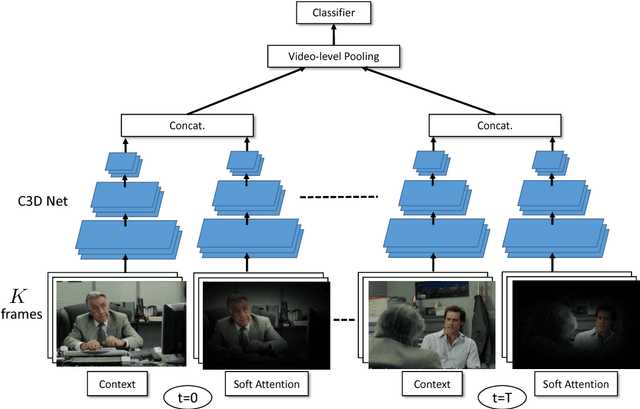
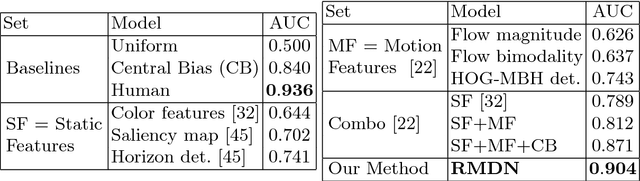
In many computer vision tasks, the relevant information to solve the problem at hand is mixed to irrelevant, distracting information. This has motivated researchers to design attentional models that can dynamically focus on parts of images or videos that are salient, e.g., by down-weighting irrelevant pixels. In this work, we propose a spatiotemporal attentional model that learns where to look in a video directly from human fixation data. We model visual attention with a mixture of Gaussians at each frame. This distribution is used to express the probability of saliency for each pixel. Time consistency in videos is modeled hierarchically by: 1) deep 3D convolutional features to represent spatial and short-term time relations and 2) a long short-term memory network on top that aggregates the clip-level representation of sequential clips and therefore expands the temporal domain from few frames to seconds. The parameters of the proposed model are optimized via maximum likelihood estimation using human fixations as training data, without knowledge of the action in each video. Our experiments on Hollywood2 show state-of-the-art performance on saliency prediction for video. We also show that our attentional model trained on Hollywood2 generalizes well to UCF101 and it can be leveraged to improve action classification accuracy on both datasets.
GuessWhat?! Visual object discovery through multi-modal dialogue
Feb 06, 2017
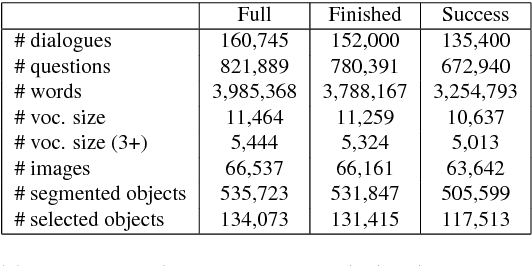

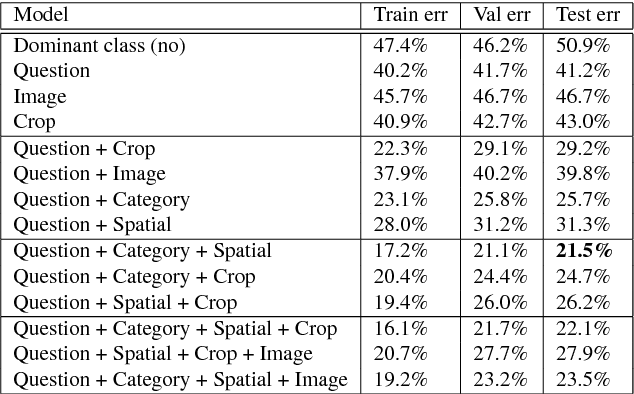
We introduce GuessWhat?!, a two-player guessing game as a testbed for research on the interplay of computer vision and dialogue systems. The goal of the game is to locate an unknown object in a rich image scene by asking a sequence of questions. Higher-level image understanding, like spatial reasoning and language grounding, is required to solve the proposed task. Our key contribution is the collection of a large-scale dataset consisting of 150K human-played games with a total of 800K visual question-answer pairs on 66K images. We explain our design decisions in collecting the dataset and introduce the oracle and questioner tasks that are associated with the two players of the game. We prototyped deep learning models to establish initial baselines of the introduced tasks.
Deep learning trends for focal brain pathology segmentation in MRI
Jan 24, 2017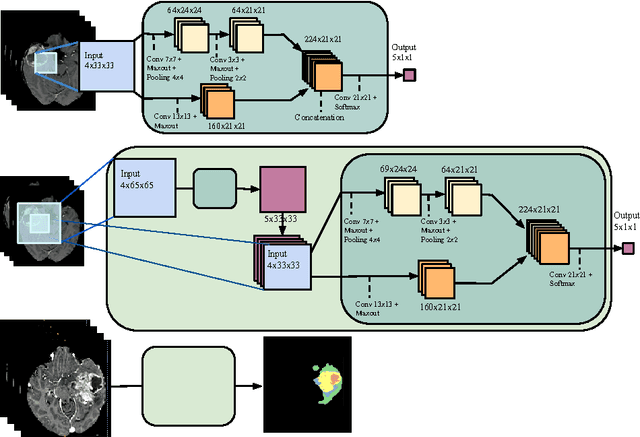
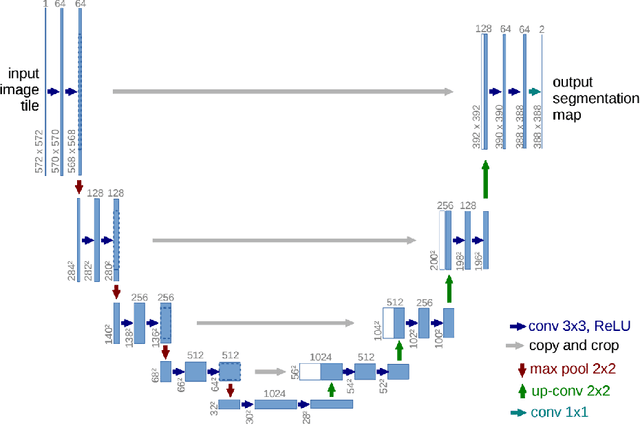
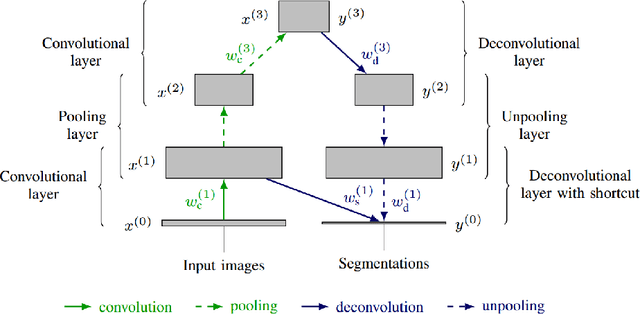
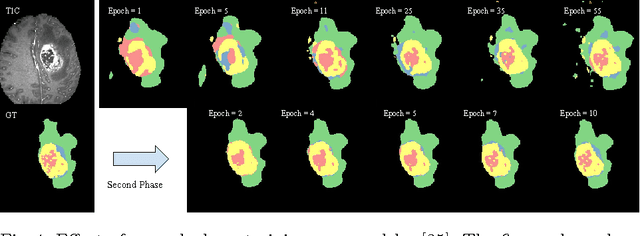
Segmentation of focal (localized) brain pathologies such as brain tumors and brain lesions caused by multiple sclerosis and ischemic strokes are necessary for medical diagnosis, surgical planning and disease development as well as other applications such as tractography. Over the years, attempts have been made to automate this process for both clinical and research reasons. In this regard, machine learning methods have long been a focus of attention. Over the past two years, the medical imaging field has seen a rise in the use of a particular branch of machine learning commonly known as deep learning. In the non-medical computer vision world, deep learning based methods have obtained state-of-the-art results on many datasets. Recent studies in computer aided diagnostics have shown deep learning methods (and especially convolutional neural networks - CNN) to yield promising results. In this chapter, we provide a survey of CNN methods applied to medical imaging with a focus on brain pathology segmentation. In particular, we discuss their characteristic peculiarities and their specific configuration and adjustments that are best suited to segment medical images. We also underline the intrinsic differences deep learning methods have with other machine learning methods.
Neural Autoregressive Distribution Estimation
May 27, 2016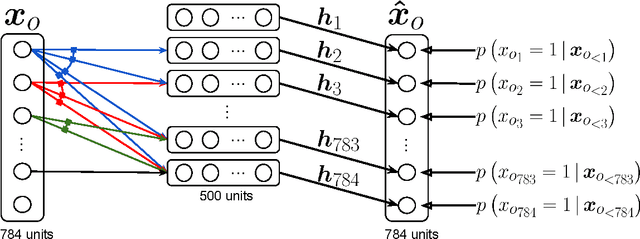
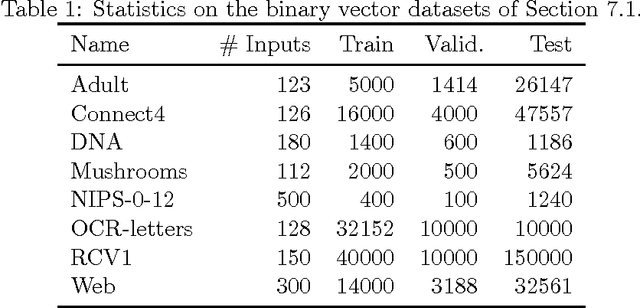
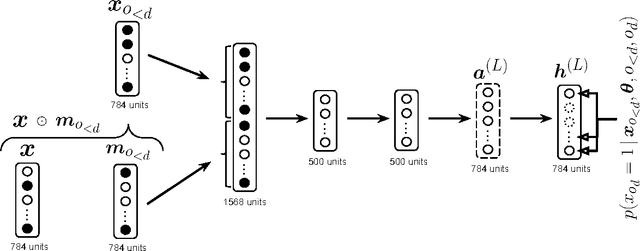
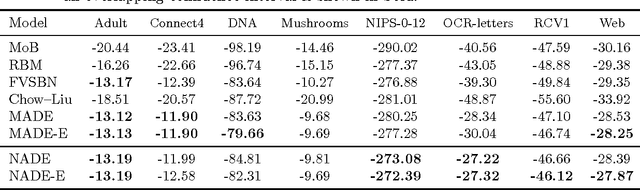
We present Neural Autoregressive Distribution Estimation (NADE) models, which are neural network architectures applied to the problem of unsupervised distribution and density estimation. They leverage the probability product rule and a weight sharing scheme inspired from restricted Boltzmann machines, to yield an estimator that is both tractable and has good generalization performance. We discuss how they achieve competitive performance in modeling both binary and real-valued observations. We also present how deep NADE models can be trained to be agnostic to the ordering of input dimensions used by the autoregressive product rule decomposition. Finally, we also show how to exploit the topological structure of pixels in images using a deep convolutional architecture for NADE.
Domain-Adversarial Training of Neural Networks
May 26, 2016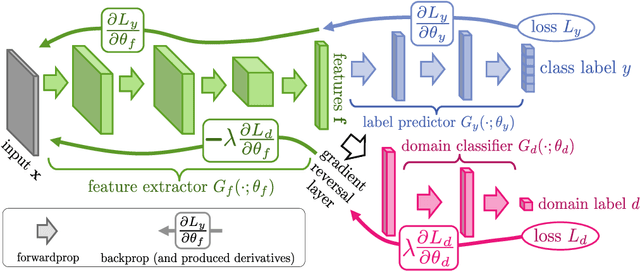
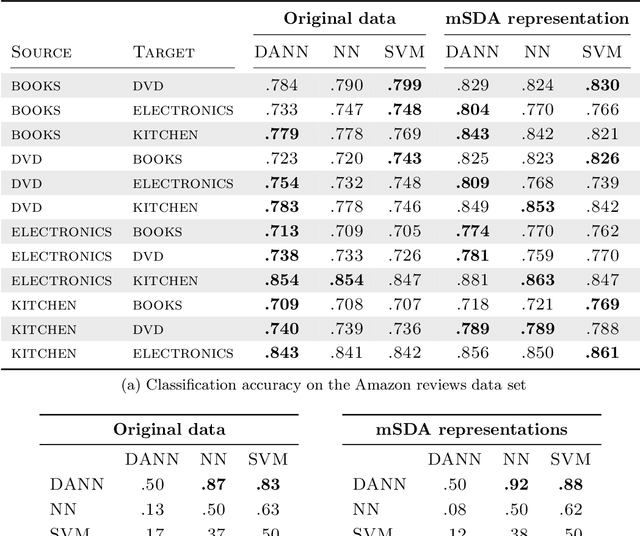
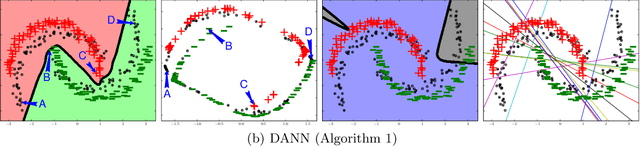
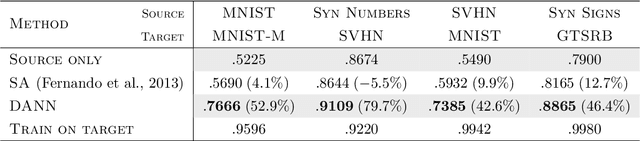
We introduce a new representation learning approach for domain adaptation, in which data at training and test time come from similar but different distributions. Our approach is directly inspired by the theory on domain adaptation suggesting that, for effective domain transfer to be achieved, predictions must be made based on features that cannot discriminate between the training (source) and test (target) domains. The approach implements this idea in the context of neural network architectures that are trained on labeled data from the source domain and unlabeled data from the target domain (no labeled target-domain data is necessary). As the training progresses, the approach promotes the emergence of features that are (i) discriminative for the main learning task on the source domain and (ii) indiscriminate with respect to the shift between the domains. We show that this adaptation behaviour can be achieved in almost any feed-forward model by augmenting it with few standard layers and a new gradient reversal layer. The resulting augmented architecture can be trained using standard backpropagation and stochastic gradient descent, and can thus be implemented with little effort using any of the deep learning packages. We demonstrate the success of our approach for two distinct classification problems (document sentiment analysis and image classification), where state-of-the-art domain adaptation performance on standard benchmarks is achieved. We also validate the approach for descriptor learning task in the context of person re-identification application.
* Published in JMLR: http://jmlr.org/papers/v17/15-239.html
Hierarchical Memory Networks
May 24, 2016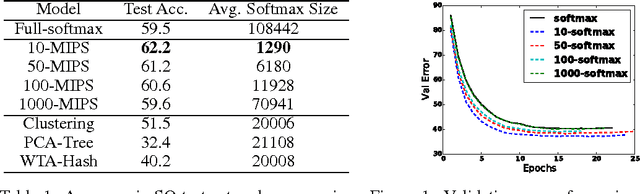
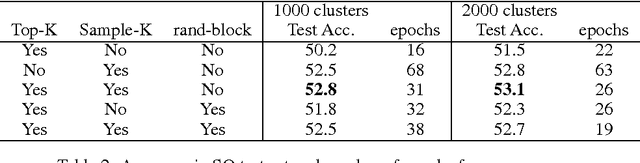
Memory networks are neural networks with an explicit memory component that can be both read and written to by the network. The memory is often addressed in a soft way using a softmax function, making end-to-end training with backpropagation possible. However, this is not computationally scalable for applications which require the network to read from extremely large memories. On the other hand, it is well known that hard attention mechanisms based on reinforcement learning are challenging to train successfully. In this paper, we explore a form of hierarchical memory network, which can be considered as a hybrid between hard and soft attention memory networks. The memory is organized in a hierarchical structure such that reading from it is done with less computation than soft attention over a flat memory, while also being easier to train than hard attention over a flat memory. Specifically, we propose to incorporate Maximum Inner Product Search (MIPS) in the training and inference procedures for our hierarchical memory network. We explore the use of various state-of-the art approximate MIPS techniques and report results on SimpleQuestions, a challenging large scale factoid question answering task.
Dynamic Capacity Networks
May 22, 2016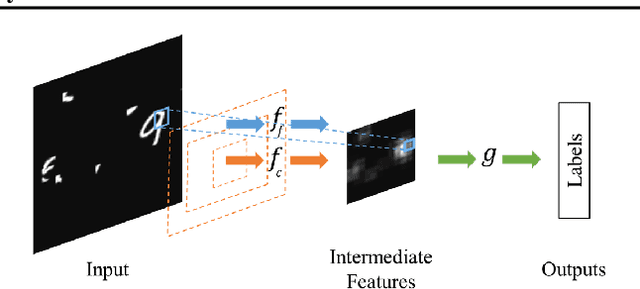
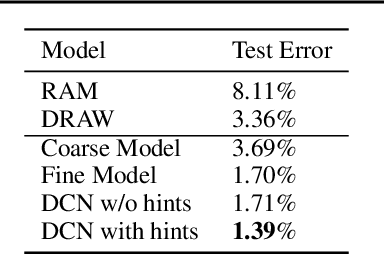
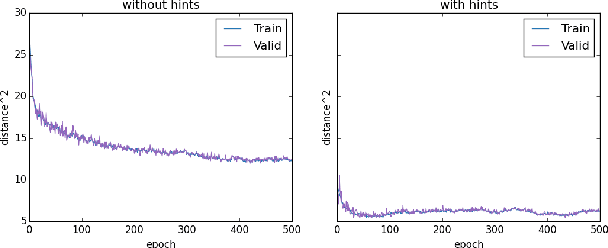
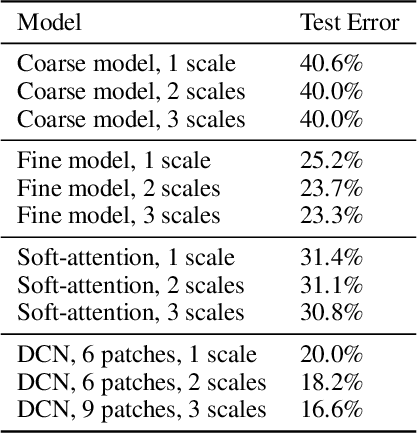
We introduce the Dynamic Capacity Network (DCN), a neural network that can adaptively assign its capacity across different portions of the input data. This is achieved by combining modules of two types: low-capacity sub-networks and high-capacity sub-networks. The low-capacity sub-networks are applied across most of the input, but also provide a guide to select a few portions of the input on which to apply the high-capacity sub-networks. The selection is made using a novel gradient-based attention mechanism, that efficiently identifies input regions for which the DCN's output is most sensitive and to which we should devote more capacity. We focus our empirical evaluation on the Cluttered MNIST and SVHN image datasets. Our findings indicate that DCNs are able to drastically reduce the number of computations, compared to traditional convolutional neural networks, while maintaining similar or even better performance.