 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust automatic brain vessel segmentation in 3D CTA scans using dynamic 4D-CTA data
Jan 30, 2026In this study, we develop a novel methodology for annotating the brain vasculature using dynamic 4D-CTA head scans. By using multiple time points from dynamic CTA acquisitions, we subtract bone and soft tissue to enhance the visualization of arteries and veins, reducing the effort required to obtain manual annotations of brain vessels. We then train deep learning models on our ground truth annotations by using the same segmentation for multiple phases from the dynamic 4D-CTA collection, effectively enlarging our dataset by 4 to 5 times and inducing robustness to contrast phases. In total, our dataset comprises 110 training images from 25 patients and 165 test images from 14 patients. In comparison with two similarly-sized datasets for CTA-based brain vessel segmentation, a nnUNet model trained on our dataset can achieve significantly better segmentations across all vascular regions, with an average mDC of 0.846 for arteries and 0.957 for veins in the TopBrain dataset. Furthermore, metrics such as average directed Hausdorff distance (adHD) and topology sensitivity (tSens) reflected similar trends: using our dataset resulted in low error margins (aDHD of 0.304 mm for arteries and 0.078 for veins) and high sensitivity (tSens of 0.877 for arteries and 0.974 for veins), indicating excellent accuracy in capturing vessel morphology. Our code and model weights are available online: https://github.com/alceballosa/robust-vessel-segmentation
LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction
Dec 15, 2025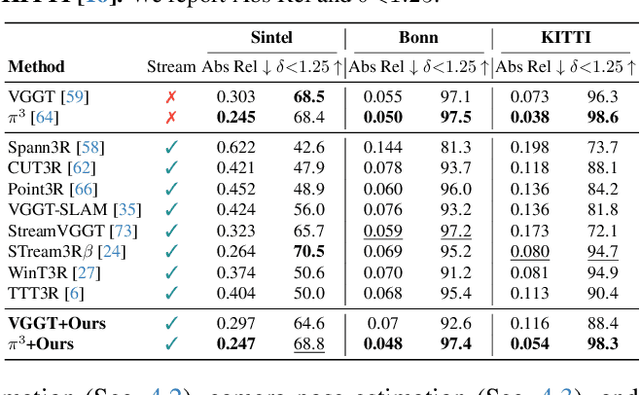
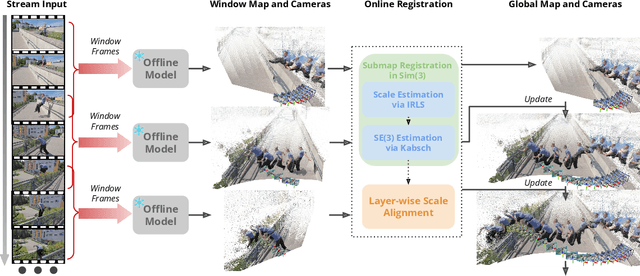
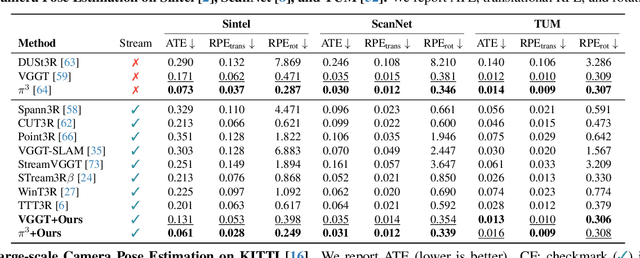
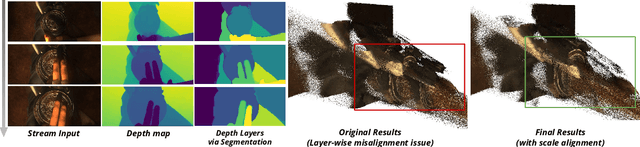
Recent feed-forward reconstruction models like VGGT and $π^3$ achieve impressive reconstruction quality but cannot process streaming videos due to quadratic memory complexity, limiting their practical deployment. While existing streaming methods address this through learned memory mechanisms or causal attention, they require extensive retraining and may not fully leverage the strong geometric priors of state-of-the-art offline models. We propose LASER, a training-free framework that converts an offline reconstruction model into a streaming system by aligning predictions across consecutive temporal windows. We observe that simple similarity transformation ($\mathrm{Sim}(3)$) alignment fails due to layer depth misalignment: monocular scale ambiguity causes relative depth scales of different scene layers to vary inconsistently between windows. To address this, we introduce layer-wise scale alignment, which segments depth predictions into discrete layers, computes per-layer scale factors, and propagates them across both adjacent windows and timestamps. Extensive experiments show that LASER achieves state-of-the-art performance on camera pose estimation and point map reconstruction %quality with offline models while operating at 14 FPS with 6 GB peak memory on a RTX A6000 GPU, enabling practical deployment for kilometer-scale streaming videos. Project website: $\href{https://neu-vi.github.io/LASER/}{\texttt{https://neu-vi.github.io/LASER/}}$
Automated anatomy-based post-processing reduces false positives and improved interpretability of deep learning intracranial aneurysm detection
Jul 01, 2025Introduction: Deep learning (DL) models can help detect intracranial aneurysms on CTA, but high false positive (FP) rates remain a barrier to clinical translation, despite improvement in model architectures and strategies like detection threshold tuning. We employed an automated, anatomy-based, heuristic-learning hybrid artery-vein segmentation post-processing method to further reduce FPs. Methods: Two DL models, CPM-Net and a deformable 3D convolutional neural network-transformer hybrid (3D-CNN-TR), were trained with 1,186 open-source CTAs (1,373 annotated aneurysms), and evaluated with 143 held-out private CTAs (218 annotated aneurysms). Brain, artery, vein, and cavernous venous sinus (CVS) segmentation masks were applied to remove possible FPs in the DL outputs that overlapped with: (1) brain mask; (2) vein mask; (3) vein more than artery masks; (4) brain plus vein mask; (5) brain plus vein more than artery masks. Results: CPM-Net yielded 139 true-positives (TP); 79 false-negative (FN); 126 FP. 3D-CNN-TR yielded 179 TP; 39 FN; 182 FP. FPs were commonly extracranial (CPM-Net 27.3%; 3D-CNN-TR 42.3%), venous (CPM-Net 56.3%; 3D-CNN-TR 29.1%), arterial (CPM-Net 11.9%; 3D-CNN-TR 53.3%), and non-vascular (CPM-Net 25.4%; 3D-CNN-TR 9.3%) structures. Method 5 performed best, reducing CPM-Net FP by 70.6% (89/126) and 3D-CNN-TR FP by 51.6% (94/182), without reducing TP, lowering the FP/case rate from 0.88 to 0.26 for CPM-NET, and from 1.27 to 0.62 for the 3D-CNN-TR. Conclusion: Anatomy-based, interpretable post-processing can improve DL-based aneurysm detection model performance. More broadly, automated, domain-informed, hybrid heuristic-learning processing holds promise for improving the performance and clinical acceptance of aneurysm detection models.
Struct2D: A Perception-Guided Framework for Spatial Reasoning in Large Multimodal Models
Jun 04, 2025Unlocking spatial reasoning in Large Multimodal Models (LMMs) is crucial for enabling intelligent interaction with 3D environments. While prior efforts often rely on explicit 3D inputs or specialized model architectures, we ask: can LMMs reason about 3D space using only structured 2D representations derived from perception? We introduce Struct2D, a perception-guided prompting framework that combines bird's-eye-view (BEV) images with object marks and object-centric metadata, optionally incorporating egocentric keyframes when needed. Using Struct2D, we conduct an in-depth zero-shot analysis of closed-source LMMs (e.g., GPT-o3) and find that they exhibit surprisingly strong spatial reasoning abilities when provided with structured 2D inputs, effectively handling tasks such as relative direction estimation and route planning. Building on these insights, we construct Struct2D-Set, a large-scale instruction tuning dataset with 200K fine-grained QA pairs across eight spatial reasoning categories, generated automatically from 3D indoor scenes. We fine-tune an open-source LMM (Qwen2.5VL) on Struct2D-Set, achieving competitive performance on multiple benchmarks, including 3D question answering, dense captioning, and object grounding. Our approach demonstrates that structured 2D inputs can effectively bridge perception and language reasoning in LMMs-without requiring explicit 3D representations as input. We will release both our code and dataset to support future research.
Absolute Coordinates Make Motion Generation Easy
May 26, 2025State-of-the-art text-to-motion generation models rely on the kinematic-aware, local-relative motion representation popularized by HumanML3D, which encodes motion relative to the pelvis and to the previous frame with built-in redundancy. While this design simplifies training for earlier generation models, it introduces critical limitations for diffusion models and hinders applicability to downstream tasks. In this work, we revisit the motion representation and propose a radically simplified and long-abandoned alternative for text-to-motion generation: absolute joint coordinates in global space. Through systematic analysis of design choices, we show that this formulation achieves significantly higher motion fidelity, improved text alignment, and strong scalability, even with a simple Transformer backbone and no auxiliary kinematic-aware losses. Moreover, our formulation naturally supports downstream tasks such as text-driven motion control and temporal/spatial editing without additional task-specific reengineering and costly classifier guidance generation from control signals. Finally, we demonstrate promising generalization to directly generate SMPL-H mesh vertices in motion from text, laying a strong foundation for future research and motion-related applications.
SV4D 2.0: Enhancing Spatio-Temporal Consistency in Multi-View Video Diffusion for High-Quality 4D Generation
Mar 21, 2025



We present Stable Video 4D 2.0 (SV4D 2.0), a multi-view video diffusion model for dynamic 3D asset generation. Compared to its predecessor SV4D, SV4D 2.0 is more robust to occlusions and large motion, generalizes better to real-world videos, and produces higher-quality outputs in terms of detail sharpness and spatio-temporal consistency. We achieve this by introducing key improvements in multiple aspects: 1) network architecture: eliminating the dependency of reference multi-views and designing blending mechanism for 3D and frame attention, 2) data: enhancing quality and quantity of training data, 3) training strategy: adopting progressive 3D-4D training for better generalization, and 4) 4D optimization: handling 3D inconsistency and large motion via 2-stage refinement and progressive frame sampling. Extensive experiments demonstrate significant performance gain by SV4D 2.0 both visually and quantitatively, achieving better detail (-14\% LPIPS) and 4D consistency (-44\% FV4D) in novel-view video synthesis and 4D optimization (-12\% LPIPS and -24\% FV4D) compared to SV4D.
Anatomically-guided masked autoencoder pre-training for aneurysm detection
Feb 28, 2025Intracranial aneurysms are a major cause of morbidity and mortality worldwide, and detecting them manually is a complex, time-consuming task. Albeit automated solutions are desirable, the limited availability of training data makes it difficult to develop such solutions using typical supervised learning frameworks. In this work, we propose a novel pre-training strategy using more widely available unannotated head CT scan data to pre-train a 3D Vision Transformer model prior to fine-tuning for the aneurysm detection task. Specifically, we modify masked auto-encoder (MAE) pre-training in the following ways: we use a factorized self-attention mechanism to make 3D attention computationally viable, we restrict the masked patches to areas near arteries to focus on areas where aneurysms are likely to occur, and we reconstruct not only CT scan intensity values but also artery distance maps, which describe the distance between each voxel and the closest artery, thereby enhancing the backbone's learned representations. Compared with SOTA aneurysm detection models, our approach gains +4-8% absolute Sensitivity at a false positive rate of 0.5. Code and weights will be released.
Rethinking Diffusion for Text-Driven Human Motion Generation
Nov 25, 2024



Since 2023, Vector Quantization (VQ)-based discrete generation methods have rapidly dominated human motion generation, primarily surpassing diffusion-based continuous generation methods in standard performance metrics. However, VQ-based methods have inherent limitations. Representing continuous motion data as limited discrete tokens leads to inevitable information loss, reduces the diversity of generated motions, and restricts their ability to function effectively as motion priors or generation guidance. In contrast, the continuous space generation nature of diffusion-based methods makes them well-suited to address these limitations and with even potential for model scalability. In this work, we systematically investigate why current VQ-based methods perform well and explore the limitations of existing diffusion-based methods from the perspective of motion data representation and distribution. Drawing on these insights, we preserve the inherent strengths of a diffusion-based human motion generation model and gradually optimize it with inspiration from VQ-based approaches. Our approach introduces a human motion diffusion model enabled to perform bidirectional masked autoregression, optimized with a reformed data representation and distribution. Additionally, we also propose more robust evaluation methods to fairly assess different-based methods. Extensive experiments on benchmark human motion generation datasets demonstrate that our method excels previous methods and achieves state-of-the-art performances.
NeuFlow v2: High-Efficiency Optical Flow Estimation on Edge Devices
Aug 21, 2024Real-time high-accuracy optical flow estimation is crucial for various real-world applications. While recent learning-based optical flow methods have achieved high accuracy, they often come with significant computational costs. In this paper, we propose a highly efficient optical flow method that balances high accuracy with reduced computational demands. Building upon NeuFlow v1, we introduce new components including a much more light-weight backbone and a fast refinement module. Both these modules help in keeping the computational demands light while providing close to state of the art accuracy. Compares to other state of the art methods, our model achieves a 10x-70x speedup while maintaining comparable performance on both synthetic and real-world data. It is capable of running at over 20 FPS on 512x384 resolution images on a Jetson Orin Nano. The full training and evaluation code is available at https://github.com/neufieldrobotics/NeuFlow_v2.
Towards Flexible Visual Relationship Segmentation
Aug 15, 2024Visual relationship understanding has been studied separately in human-object interaction(HOI) detection, scene graph generation(SGG), and referring relationships(RR) tasks. Given the complexity and interconnectedness of these tasks, it is crucial to have a flexible framework that can effectively address these tasks in a cohesive manner. In this work, we propose FleVRS, a single model that seamlessly integrates the above three aspects in standard and promptable visual relationship segmentation, and further possesses the capability for open-vocabulary segmentation to adapt to novel scenarios. FleVRS leverages the synergy between text and image modalities, to ground various types of relationships from images and use textual features from vision-language models to visual conceptual understanding. Empirical validation across various datasets demonstrates that our framework outperforms existing models in standard, promptable, and open-vocabulary tasks, e.g., +1.9 $mAP$ on HICO-DET, +11.4 $Acc$ on VRD, +4.7 $mAP$ on unseen HICO-DET. Our FleVRS represents a significant step towards a more intuitive, comprehensive, and scalable understanding of visual relationships.