 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated anatomy-based post-processing reduces false positives and improved interpretability of deep learning intracranial aneurysm detection
Jul 01, 2025Introduction: Deep learning (DL) models can help detect intracranial aneurysms on CTA, but high false positive (FP) rates remain a barrier to clinical translation, despite improvement in model architectures and strategies like detection threshold tuning. We employed an automated, anatomy-based, heuristic-learning hybrid artery-vein segmentation post-processing method to further reduce FPs. Methods: Two DL models, CPM-Net and a deformable 3D convolutional neural network-transformer hybrid (3D-CNN-TR), were trained with 1,186 open-source CTAs (1,373 annotated aneurysms), and evaluated with 143 held-out private CTAs (218 annotated aneurysms). Brain, artery, vein, and cavernous venous sinus (CVS) segmentation masks were applied to remove possible FPs in the DL outputs that overlapped with: (1) brain mask; (2) vein mask; (3) vein more than artery masks; (4) brain plus vein mask; (5) brain plus vein more than artery masks. Results: CPM-Net yielded 139 true-positives (TP); 79 false-negative (FN); 126 FP. 3D-CNN-TR yielded 179 TP; 39 FN; 182 FP. FPs were commonly extracranial (CPM-Net 27.3%; 3D-CNN-TR 42.3%), venous (CPM-Net 56.3%; 3D-CNN-TR 29.1%), arterial (CPM-Net 11.9%; 3D-CNN-TR 53.3%), and non-vascular (CPM-Net 25.4%; 3D-CNN-TR 9.3%) structures. Method 5 performed best, reducing CPM-Net FP by 70.6% (89/126) and 3D-CNN-TR FP by 51.6% (94/182), without reducing TP, lowering the FP/case rate from 0.88 to 0.26 for CPM-NET, and from 1.27 to 0.62 for the 3D-CNN-TR. Conclusion: Anatomy-based, interpretable post-processing can improve DL-based aneurysm detection model performance. More broadly, automated, domain-informed, hybrid heuristic-learning processing holds promise for improving the performance and clinical acceptance of aneurysm detection models.
Cross Pairwise Ranking for Unbiased Item Recommendation
Apr 26, 2022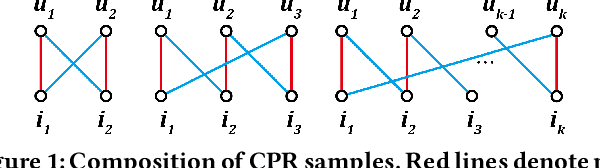
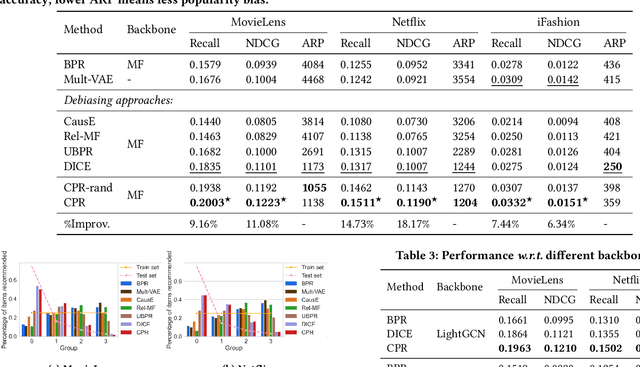
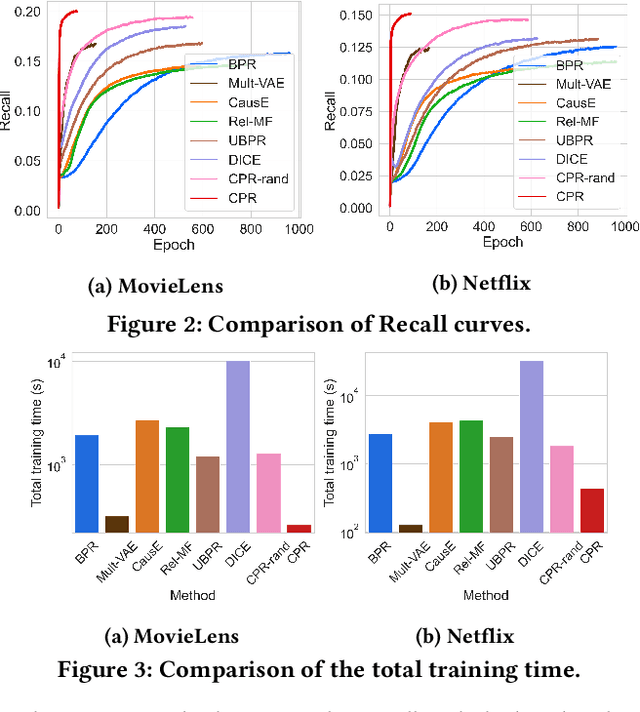
Most recommender systems optimize the model on observed interaction data, which is affected by the previous exposure mechanism and exhibits many biases like popularity bias. The loss functions, such as the mostly used pointwise Binary Cross-Entropy and pairwise Bayesian Personalized Ranking, are not designed to consider the biases in observed data. As a result, the model optimized on the loss would inherit the data biases, or even worse, amplify the biases. For example, a few popular items take up more and more exposure opportunities, severely hurting the recommendation quality on niche items -- known as the notorious Mathew effect. In this work, we develop a new learning paradigm named Cross Pairwise Ranking (CPR) that achieves unbiased recommendation without knowing the exposure mechanism. Distinct from inverse propensity scoring (IPS), we change the loss term of a sample -- we innovatively sample multiple observed interactions once and form the loss as the combination of their predictions. We prove in theory that this way offsets the influence of user/item propensity on the learning, removing the influence of data biases caused by the exposure mechanism. Advantageous to IPS, our proposed CPR ensures unbiased learning for each training instance without the need of setting the propensity scores. Experimental results demonstrate the superiority of CPR over state-of-the-art debiasing solutions in both model generalization and training efficiency. The codes are available at https://github.com/Qcactus/CPR.