 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetailAnywhere: Fashion Detail Generation via Cross-Modal Feature Alignment Distillation
Jul 02, 2026Diffusion-based generative AI has achieved remarkable success in e-commerce applications such as virtual try-on, poster generation, and product background synthesis. However, when making online purchasing decisions for apparel, consumers also desire the freedom to examine specific detail regions of interest, such as collars, cuffs, and fabric textures, yet existing methods have not explicitly studied this setting. We therefore formalize a new, non-template task: Fashion Detail Generation with focus conditioning, and release FDBench, the first benchmark comprising 40K+ human-verified reference-detail pairs across 41 different categories. This task poses a unique semantic gap challenge: the model must bridge the correspondence between a focus marker on a product reference image and a photorealistic close-up view of the indicated region, while faithfully preserving the garment's identity, without any precise prompt. To bridge this gap, we propose Cross-modal Feature Alignment Distillation (CFAD), which leverages a fine-tuned DINOv3 teacher to align both branches of a Multimodal Diffusion Transformer in a shared semantic space via dual-branch distillation. To further improve consistency between generated details and reference images, we introduce a consistency reward model that jointly scores image pairs along three quality axes and optimizes generation via reinforcement learning. Experiments show that our model DetailAnywhere significantly outperforms all state-of-the-art opensource methods across all metrics and human evaluations.
CaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
May 12, 2026In this paper, we propose Concentrate and Concentrate (CaC), a coarse-to-fine anomaly reward model based on Vision-Language Models. During inference, it first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding within the localized interval, and finally derives robust judgments via structured spatiotemporal Chain-of-Thought reasoning. To equip the model with these capabilities, we construct the first large-scale generated video anomaly dataset with per-frame bounding-box annotations, temporal anomaly windows, and fine-grained attribution labels. Building on this dataset, we design a three-stage progressive training paradigm. The model initially learns spatial and temporal anchoring through single- and multi-frame supervised fine-tuning, and then is optimized by a reinforcement learning strategy based on two-turn Group Relative Policy Optimization (GRPO). Beyond conventional accuracy rewards, we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process, effectively guiding the model toward more grounded and interpretable spatiotemporal reasoning. Extensive experiments demonstrate that CaC can stably concentrate on subtle anomalies, achieving a 25.7% accuracy improvement on fine-grained anomaly benchmarks and, when used as a reward signal, CaC reduces generated-video anomalies by 11.7% while improving overall video quality.
OmniDiT: Extending Diffusion Transformer to Omni-VTON Framework
Mar 20, 2026Despite the rapid advancement of Virtual Try-On (VTON) and Try-Off (VTOFF) technologies, existing VTON methods face challenges with fine-grained detail preservation, generalization to complex scenes, complicated pipeline, and efficient inference. To tackle these problems, we propose OmniDiT, an omni Virtual Try-On framework based on the Diffusion Transformer, which combines try-on and try-off tasks into one unified model. Specifically, we first establish a self-evolving data curation pipeline to continuously produce data, and construct a large VTON dataset Omni-TryOn, which contains over 380k diverse and high-quality garment-model-tryon image pairs and detailed text prompts. Then, we employ the token concatenation and design an adaptive position encoding to effectively incorporate multiple reference conditions. To relieve the bottleneck of long sequence computation, we are the first to introduce Shifted Window Attention into the diffusion model, thus achieving a linear complexity. To remedy the performance degradation caused by local window attention, we utilize multiple timestep prediction and an alignment loss to improve generation fidelity. Experiments reveal that, under various complex scenes, our method achieves the best performance in both the model-free VTON and VTOFF tasks and a performance comparable to current SOTA methods in the model-based VTON task.
UniRef-Image-Edit: Towards Scalable and Consistent Multi-Reference Image Editing
Feb 15, 2026We present UniRef-Image-Edit, a high-performance multi-modal generation system that unifies single-image editing and multi-image composition within a single framework. Existing diffusion-based editing methods often struggle to maintain consistency across multiple conditions due to limited interaction between reference inputs. To address this, we introduce Sequence-Extended Latent Fusion (SELF), a unified input representation that dynamically serializes multiple reference images into a coherent latent sequence. During a dedicated training stage, all reference images are jointly constrained to fit within a fixed-length sequence under a global pixel-budget constraint. Building upon SELF, we propose a two-stage training framework comprising supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we jointly train on single-image editing and multi-image composition tasks to establish a robust generative prior. We adopt a progressive sequence length training strategy, in which all input images are initially resized to a total pixel budget of $1024^2$, and are then gradually increased to $1536^2$ and $2048^2$ to improve visual fidelity and cross-reference consistency. This gradual relaxation of compression enables the model to incrementally capture finer visual details while maintaining stable alignment across references. For the RL stage, we introduce Multi-Source GRPO (MSGRPO), to our knowledge the first reinforcement learning framework tailored for multi-reference image generation. MSGRPO optimizes the model to reconcile conflicting visual constraints, significantly enhancing compositional consistency. We will open-source the code, models, training data, and reward data for community research purposes.
Intelligence of Astronomical Optical Telescope: Present Status and Future Perspectives
Jun 29, 2023


Artificial intelligence technology has been widely used in astronomy, and new artificial intelligence technologies and application scenarios are constantly emerging. There have been a large number of papers reviewing the application of artificial intelligence technology in astronomy. However, relevant articles seldom mention telescope intelligence separately, and it is difficult to understand the current development status and research hotspots of telescope intelligence from these papers. This paper combines the development history of artificial intelligence technology and the difficulties of critical technologies of telescopes, comprehensively introduces the development and research hotspots of telescope intelligence, then conducts statistical analysis on various research directions of telescope intelligence and defines the research directions' merits. All kinds of research directions are evaluated, and the research trend of each telescope's intelligence is pointed out. Finally, according to the advantages of artificial intelligence technology and the development trend of telescopes, future research hotspots of telescope intelligence are given.
A Behavioral Distance for Fuzzy-Transition Systems
Oct 03, 2011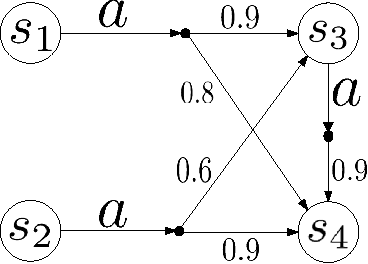
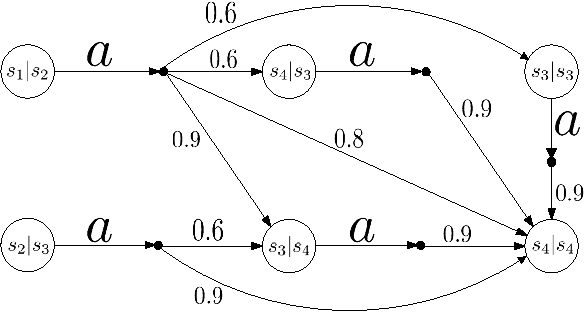
In contrast to the existing approaches to bisimulation for fuzzy systems, we introduce a behavioral distance to measure the behavioral similarity of states in a nondeterministic fuzzy-transition system. This behavioral distance is defined as the greatest fixed point of a suitable monotonic function and provides a quantitative analogue of bisimilarity. The behavioral distance has the important property that two states are at zero distance if and only if they are bisimilar. Moreover, for any given threshold, we find that states with behavioral distances bounded by the threshold are equivalent. In addition, we show that two system combinators---parallel composition and product---are non-expansive with respect to our behavioral distance, which makes compositional verification possible.
Multi-agent coordination using nearest neighbor rules: revisiting the Vicsek model
Jul 14, 2004Recently, Jadbabaie, Lin, and Morse (IEEE TAC, 48(6)2003:988-1001) offered a mathematical analysis of the discrete time model of groups of mobile autonomous agents raised by Vicsek et al. in 1995. In their paper, Jadbabaie et al. showed that all agents shall move in the same heading, provided that these agents are periodically linked together. This paper sharpens this result by showing that coordination will be reached under a very weak condition that requires all agents are finally linked together. This condition is also strictly weaker than the one Jadbabaie et al. desired.