 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA convolutional neural network for teeth margin detection on 3-dimensional dental meshes
Jul 07, 2021We proposed a convolutional neural network for vertex classification on 3-dimensional dental meshes, and used it to detect teeth margins. An expanding layer was constructed to collect statistic values of neighbor vertex features and compute new features for each vertex with convolutional neural networks. An end-to-end neural network was proposed to take vertex features, including coordinates, curvatures and distance, as input and output each vertex classification label. Several network structures with different parameters of expanding layers and a base line network without expanding layers were designed and trained by 1156 dental meshes. The accuracy, recall and precision were validated on 145 dental meshes to rate the best network structures, which were finally tested on another 144 dental meshes. All networks with our expanding layers performed better than baseline, and the best one achieved an accuracy of 0.877 both on validation dataset and test dataset.
One Network to Solve Them All: A Sequential Multi-Task Joint Learning Network Framework for MR Imaging Pipeline
May 14, 2021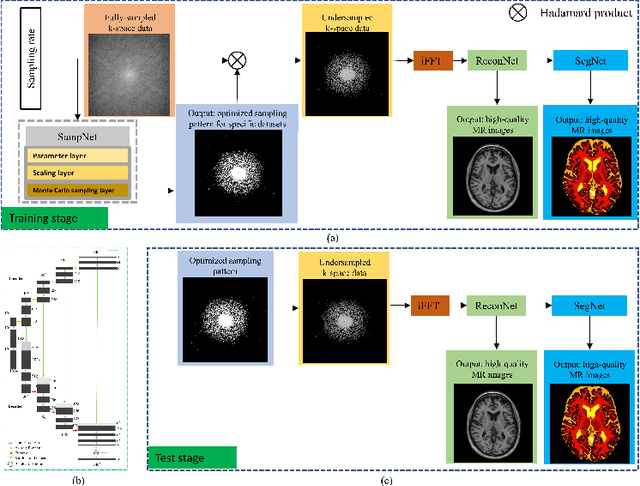
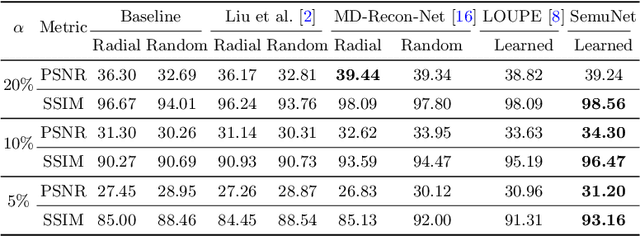
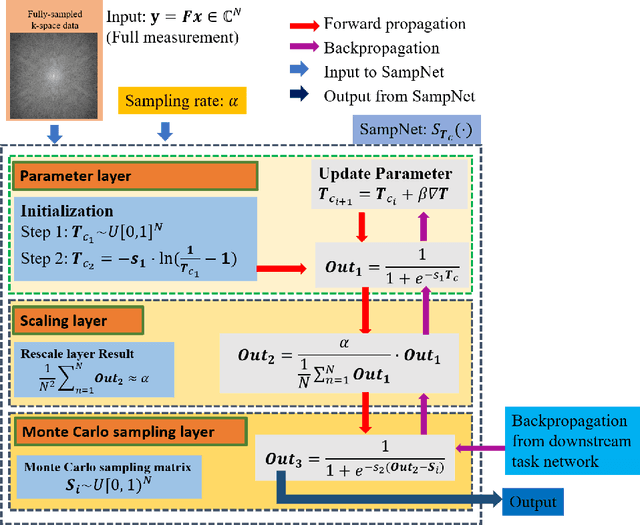
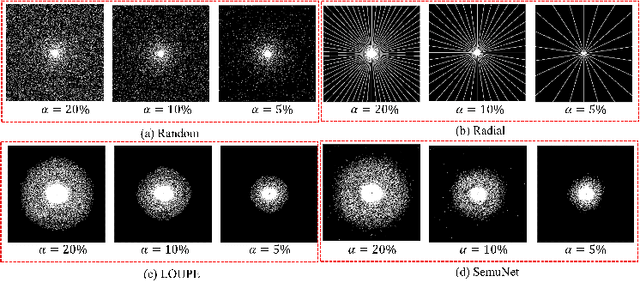
Magnetic resonance imaging (MRI) acquisition, reconstruction, and segmentation are usually processed independently in the conventional practice of MRI workflow. It is easy to notice that there are significant relevances among these tasks and this procedure artificially cuts off these potential connections, which may lead to losing clinically important information for the final diagnosis. To involve these potential relations for further performance improvement, a sequential multi-task joint learning network model is proposed to train a combined end-to-end pipeline in a differentiable way, aiming at exploring the mutual influence among those tasks simultaneously. Our design consists of three cascaded modules: 1) deep sampling pattern learning module optimizes the $k$-space sampling pattern with predetermined sampling rate; 2) deep reconstruction module is dedicated to reconstructing MR images from the undersampled data using the learned sampling pattern; 3) deep segmentation module encodes MR images reconstructed from the previous module to segment the interested tissues. The proposed model retrieves the latently interactive and cyclic relations among those tasks, from which each task will be mutually beneficial. The proposed framework is verified on MRB dataset, which achieves superior performance on other SOTA methods in terms of both reconstruction and segmentation.
IDOL-Net: An Interactive Dual-Domain Parallel Network for CT Metal Artifact Reduction
Apr 03, 2021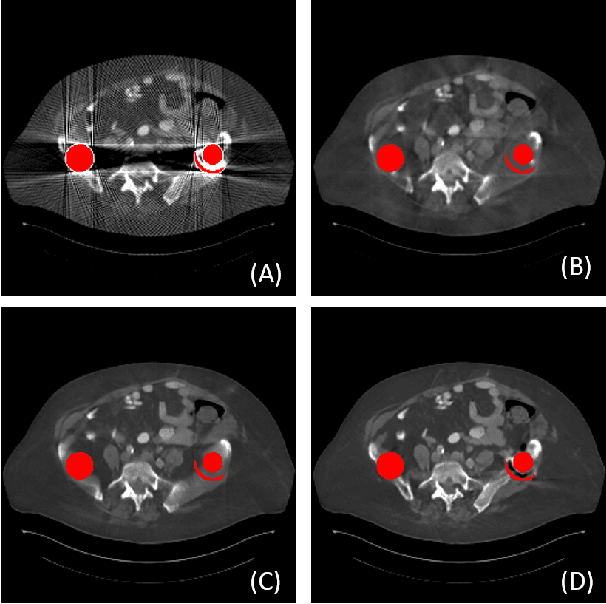
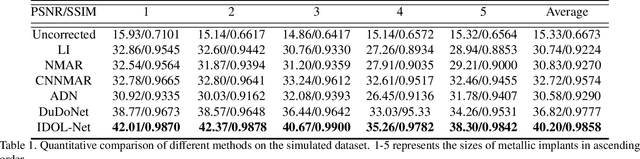
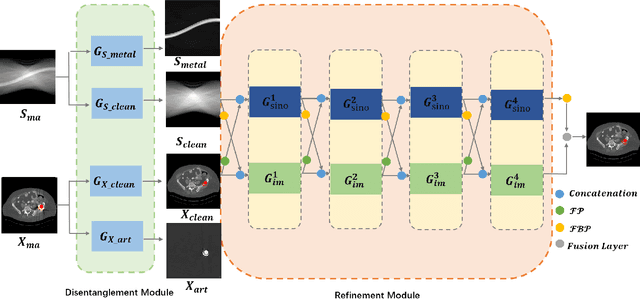

Due to the presence of metallic implants, the imaging quality of computed tomography (CT) would be heavily degraded. With the rapid development of deep learning, several network models have been proposed for metal artifact reduction (MAR). Since the dual-domain MAR methods can leverage the hybrid information from both sinogram and image domains, they have significantly improved the performance compared to single-domain methods. However,current dual-domain methods usually operate on both domains in a specific order, which implicitly imposes a certain priority prior into MAR and may ignore the latent information interaction between both domains. To address this problem, in this paper, we propose a novel interactive dualdomain parallel network for CT MAR, dubbed as IDOLNet. Different from existing dual-domain methods, the proposed IDOL-Net is composed of two modules. The disentanglement module is utilized to generate high-quality prior sinogram and image as the complementary inputs. The follow-up refinement module consists of two parallel and interactive branches that simultaneously operate on image and sinogram domain, fully exploiting the latent information interaction between both domains. The simulated and clinical results demonstrate that the proposed IDOL-Net outperforms several state-of-the-art models in both qualitative and quantitative aspects.
PointShuffleNet: Learning Non-Euclidean Features with Homotopy Equivalence and Mutual Information
Mar 31, 2021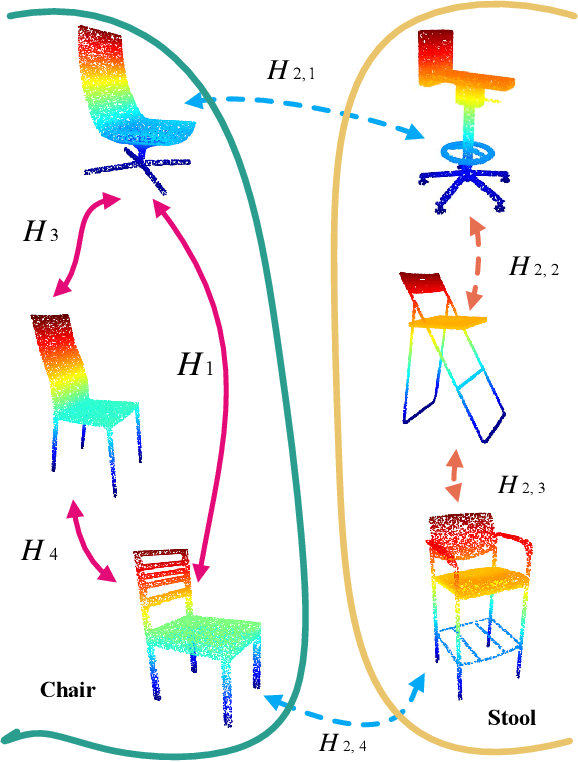
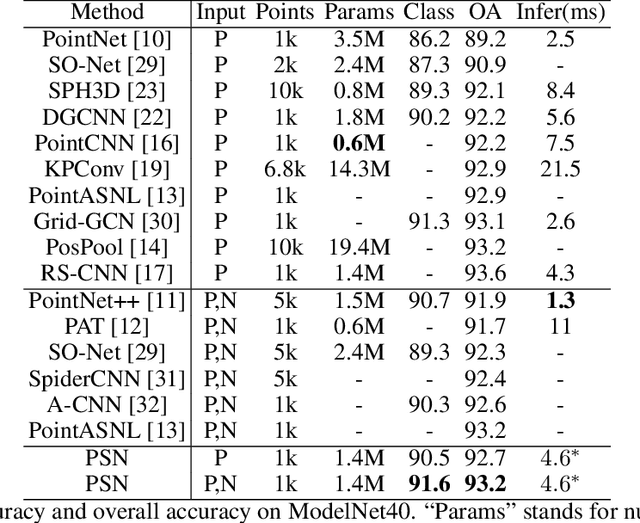
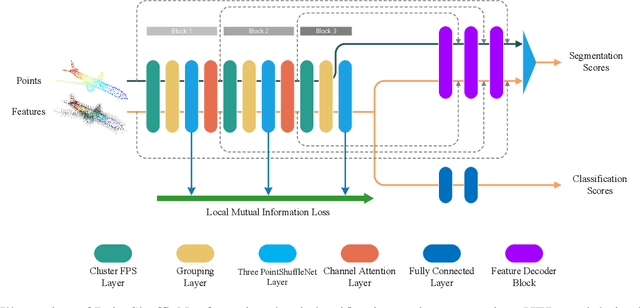
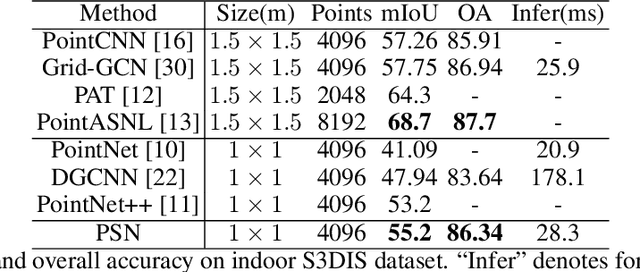
Point cloud analysis is still a challenging task due to the disorder and sparsity of samplings of their geometric structures from 3D sensors. In this paper, we introduce the homotopy equivalence relation (HER) to make the neural networks learn the data distribution from a high-dimension manifold. A shuffle operation is adopted to construct HER for its randomness and zero-parameter. In addition, inspired by prior works, we propose a local mutual information regularizer (LMIR) to cut off the trivial path that leads to a classification error from HER. LMIR utilizes mutual information to measure the distance between the original feature and HER transformed feature and learns common features in a contrastive learning scheme. Thus, we combine HER and LMIR to give our model the ability to learn non-Euclidean features from a high-dimension manifold. This is named the non-Euclidean feature learner. Furthermore, we propose a new heuristics and efficiency point sampling algorithm named ClusterFPS to obtain approximate uniform sampling but at faster speed. ClusterFPS uses a cluster algorithm to divide a point cloud into several clusters and deploy the farthest point sampling algorithm on each cluster in parallel. By combining the above methods, we propose a novel point cloud analysis neural network called PointShuffleNet (PSN), which shows great promise in point cloud classification and segmentation. Extensive experiments show that our PSN achieves state-of-the-art results on ModelNet40, ShapeNet and S3DIS with high efficiency. Theoretically, we provide mathematical analysis toward understanding of what the data distribution HER has developed and why LMIR can drop the trivial path by maximizing mutual information implicitly.
MANAS: Multi-Scale and Multi-Level Neural Architecture Search for Low-Dose CT Denoising
Mar 24, 2021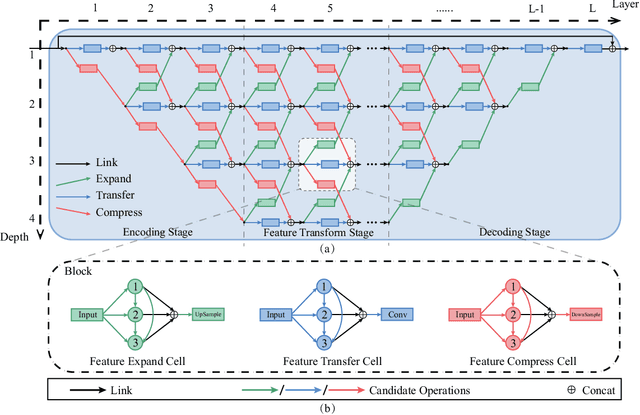

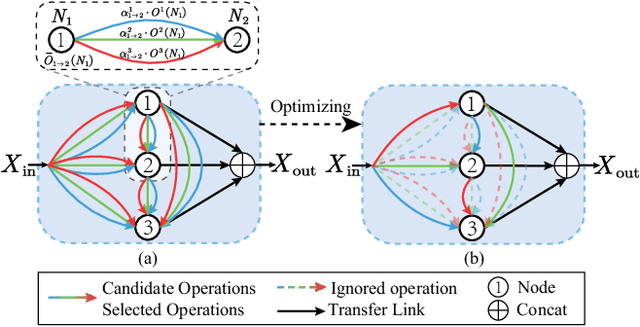
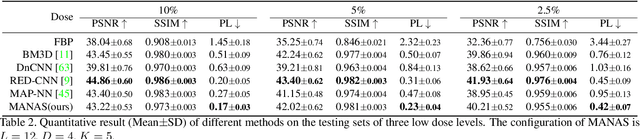
Lowering the radiation dose in computed tomography (CT) can greatly reduce the potential risk to public health. However, the reconstructed images from the dose-reduced CT or low-dose CT (LDCT) suffer from severe noise, compromising the subsequent diagnosis and analysis. Recently, convolutional neural networks have achieved promising results in removing noise from LDCT images; the network architectures used are either handcrafted or built on top of conventional networks such as ResNet and U-Net. Recent advance on neural network architecture search (NAS) has proved that the network architecture has a dramatic effect on the model performance, which indicates that current network architectures for LDCT may be sub-optimal. Therefore, in this paper, we make the first attempt to apply NAS to LDCT and propose a multi-scale and multi-level NAS for LDCT denoising, termed MANAS. On the one hand, the proposed MANAS fuses features extracted by different scale cells to capture multi-scale image structural details. On the other hand, the proposed MANAS can search a hybrid cell- and network-level structure for better performance. Extensively experimental results on three different dose levels demonstrate that the proposed MANAS can achieve better performance in terms of preserving image structural details than several state-of-the-art methods. In addition, we also validate the effectiveness of the multi-scale and multi-level architecture for LDCT denoising.
ATCSpeechNet: A multilingual end-to-end speech recognition framework for air traffic control systems
Feb 17, 2021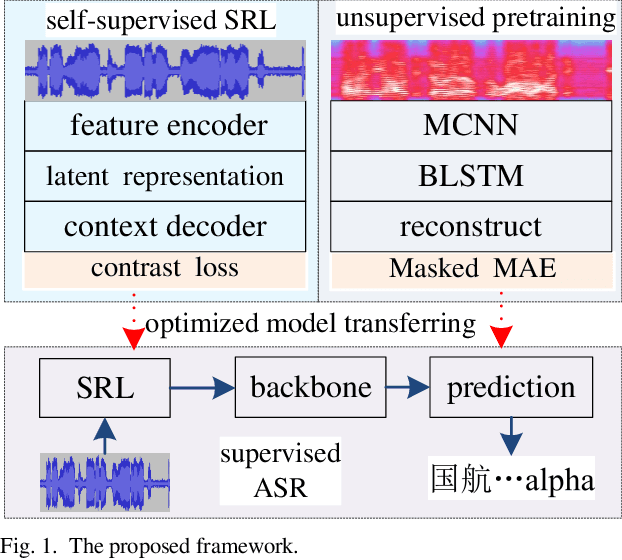
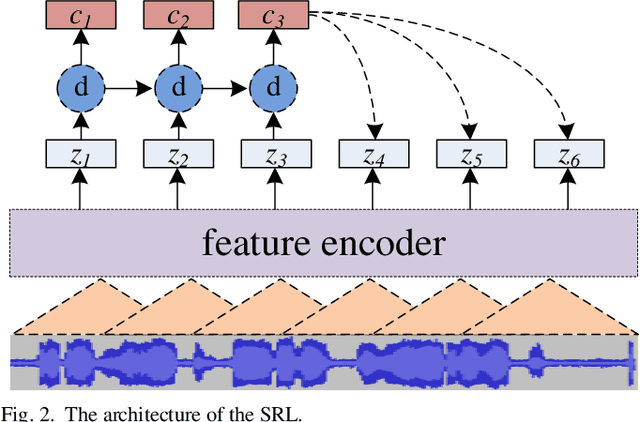
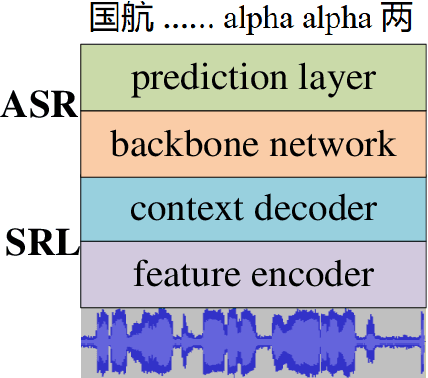
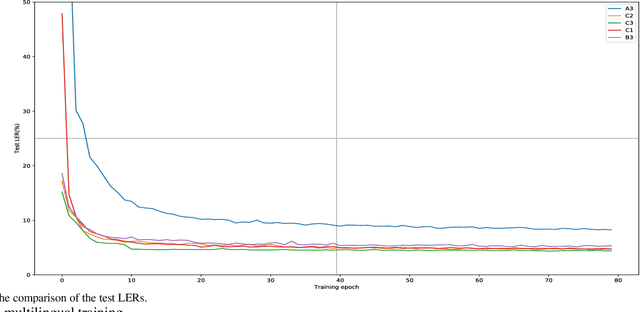
In this paper, a multilingual end-to-end framework, called as ATCSpeechNet, is proposed to tackle the issue of translating communication speech into human-readable text in air traffic control (ATC) systems. In the proposed framework, we focus on integrating the multilingual automatic speech recognition (ASR) into one model, in which an end-to-end paradigm is developed to convert speech waveform into text directly, without any feature engineering or lexicon. In order to make up for the deficiency of the handcrafted feature engineering caused by ATC challenges, a speech representation learning (SRL) network is proposed to capture robust and discriminative speech representations from the raw wave. The self-supervised training strategy is adopted to optimize the SRL network from unlabeled data, and further to predict the speech features, i.e., wave-to-feature. An end-to-end architecture is improved to complete the ASR task, in which a grapheme-based modeling unit is applied to address the multilingual ASR issue. Facing the problem of small transcribed samples in the ATC domain, an unsupervised approach with mask prediction is applied to pre-train the backbone network of the ASR model on unlabeled data by a feature-to-feature process. Finally, by integrating the SRL with ASR, an end-to-end multilingual ASR framework is formulated in a supervised manner, which is able to translate the raw wave into text in one model, i.e., wave-to-text. Experimental results on the ATCSpeech corpus demonstrate that the proposed approach achieves a high performance with a very small labeled corpus and less resource consumption, only 4.20% label error rate on the 58-hour transcribed corpus. Compared to the baseline model, the proposed approach obtains over 100% relative performance improvement which can be further enhanced with the increasing of the size of the transcribed samples.
DAN-Net: Dual-Domain Adaptive-Scaling Non-local Network for CT Metal Artifact Reduction
Feb 16, 2021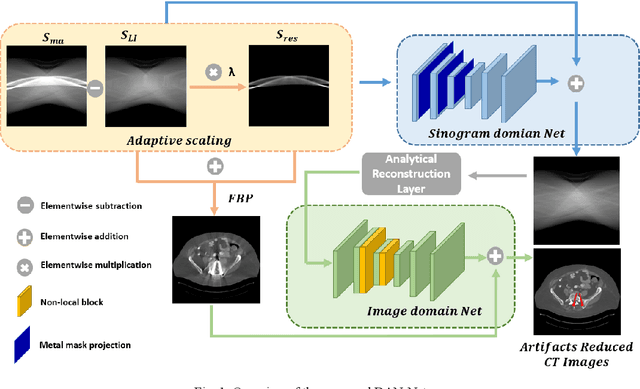
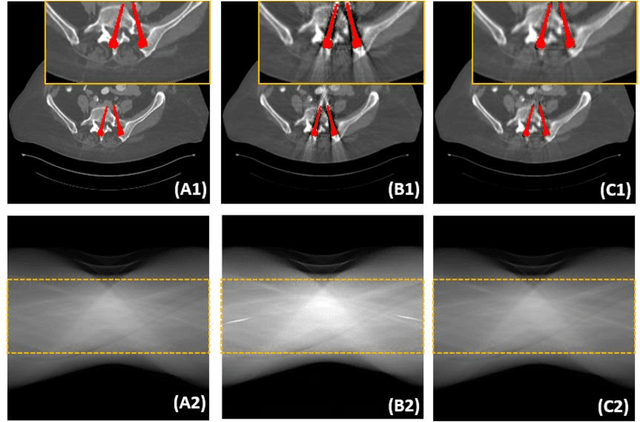
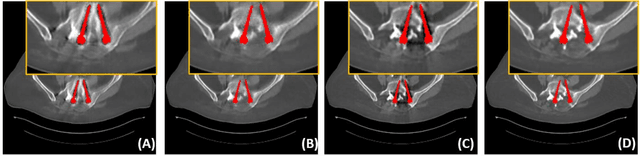
Metal implants can heavily attenuate X-rays in computed tomography (CT) scans, leading to severe artifacts in reconstructed images, which significantly jeopardize image quality and negatively impact subsequent diagnoses and treatment planning. With the rapid development of deep learning in the field of medical imaging, several network models have been proposed for metal artifact reduction (MAR) in CT. Despite the encouraging results achieved by these methods, there is still much room to further improve performance. In this paper, a novel Dual-domain Adaptive-scaling Non-local network (DAN-Net) for MAR. We correct the corrupted sinogram using adaptive scaling first to preserve more tissue and bone details as a more informative input. Then, an end-to-end dual-domain network is adopted to successively process the sinogram and its corresponding reconstructed image generated by the analytical reconstruction layer. In addition, to better suppress the existing artifacts and restrain the potential secondary artifacts caused by inaccurate results of the sinogram-domain network, a novel residual sinogram learning strategy and nonlocal module are leveraged in the proposed network model. In the experiments, the proposed DAN-Net demonstrates performance competitive with several state-of-the-art MAR methods in both qualitative and quantitative aspects.
LEARN++: Recurrent Dual-Domain Reconstruction Network for Compressed Sensing CT
Dec 13, 2020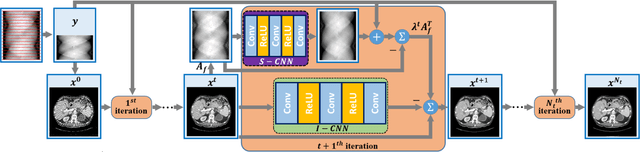
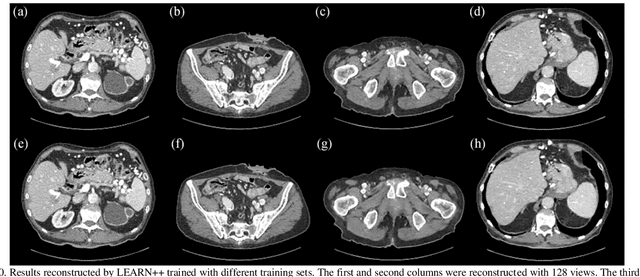
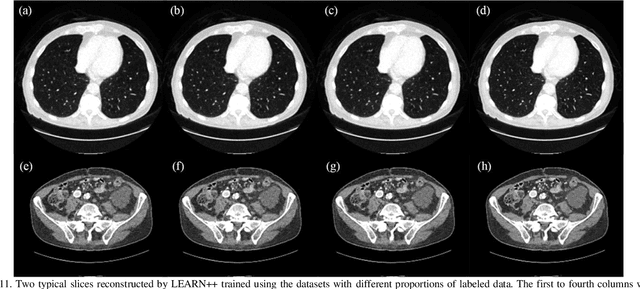
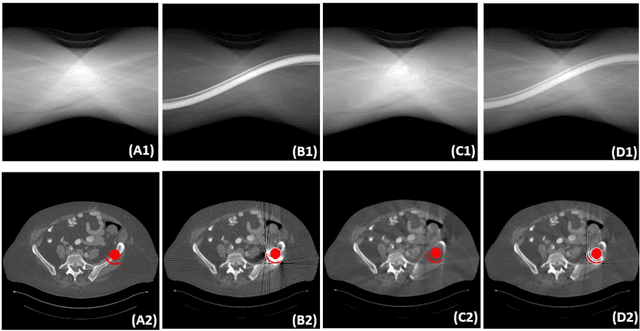
Compressed sensing (CS) computed tomography has been proven to be important for several clinical applications, such as sparse-view computed tomography (CT), digital tomosynthesis and interior tomography. Traditional compressed sensing focuses on the design of handcrafted prior regularizers, which are usually image-dependent and time-consuming. Inspired by recently proposed deep learning-based CT reconstruction models, we extend the state-of-the-art LEARN model to a dual-domain version, dubbed LEARN++. Different from existing iteration unrolling methods, which only involve projection data in the data consistency layer, the proposed LEARN++ model integrates two parallel and interactive subnetworks to perform image restoration and sinogram inpainting operations on both the image and projection domains simultaneously, which can fully explore the latent relations between projection data and reconstructed images. The experimental results demonstrate that the proposed LEARN++ model achieves competitive qualitative and quantitative results compared to several state-of-the-art methods in terms of both artifact reduction and detail preservation.
Fourth-Order Nonlocal Tensor Decomposition Model for Spectral Computed Tomography
Oct 27, 2020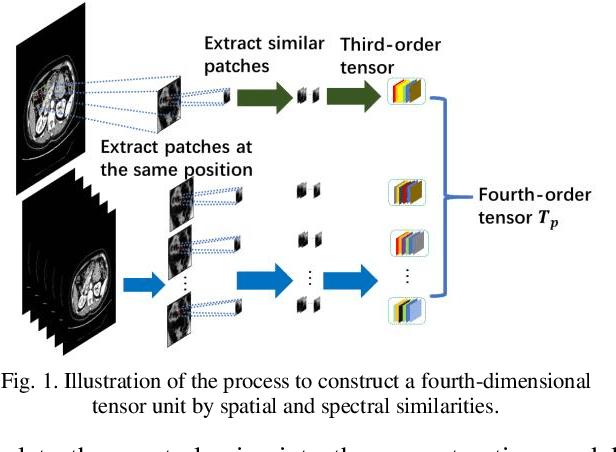

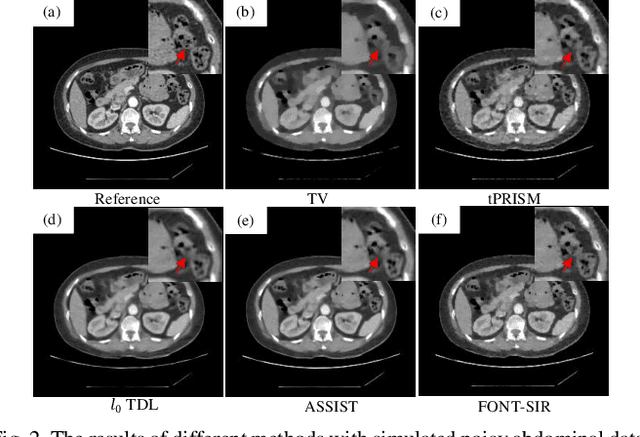
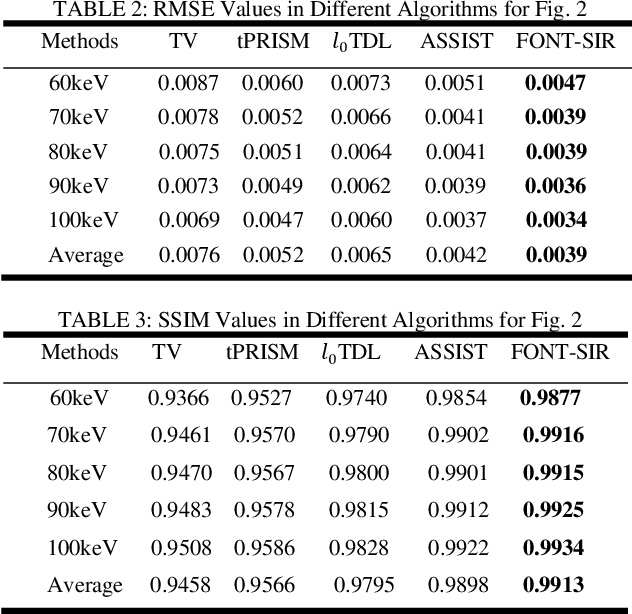
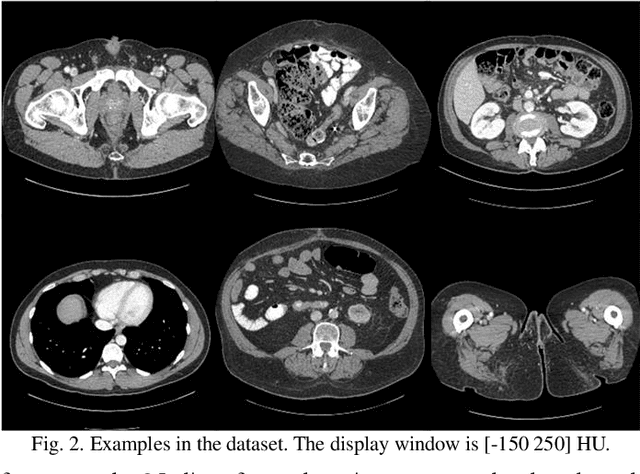
Spectral computed tomography (CT) can reconstruct spectral images from different energy bins using photon counting detectors (PCDs). However, due to the limited photons and counting rate in the corresponding spectral fraction, the reconstructed spectral images usually suffer from severe noise. In this paper, a fourth-order nonlocal tensor decomposition model for spectral CT image reconstruction (FONT-SIR) method is proposed. Similar patches are collected in both spatial and spectral dimensions simultaneously to form the basic tensor unit. Additionally, principal component analysis (PCA) is applied to extract latent features from the patches for a robust and efficient similarity measure. Then, low-rank and sparsity decomposition is performed on the produced fourth-order tensor unit, and the weighted nuclear norm and total variation (TV) norm are used to enforce the low-rank and sparsity constraints, respectively. The alternating direction method of multipliers (ADMM) is adopted to optimize the objective function. The experimental results with our proposed FONT-SIR demonstrates a superior qualitative and quantitative performance for both simulated and real data sets relative to several state-of-the-art methods, in terms of noise suppression and detail preservation.
CT Reconstruction with PDF: Parameter-Dependent Framework for Multiple Scanning Geometries and Dose Levels
Oct 27, 2020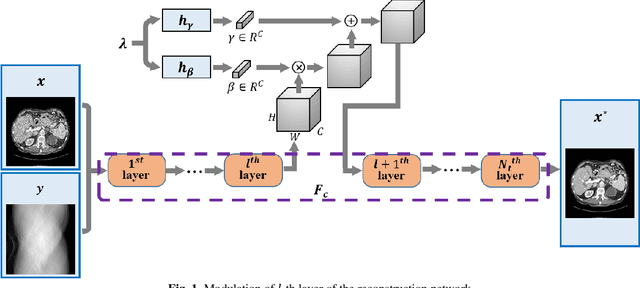
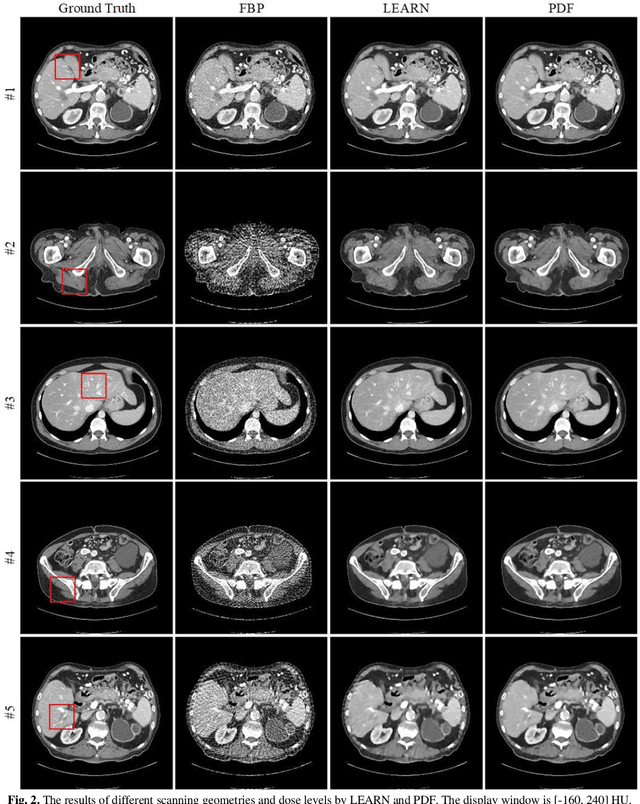
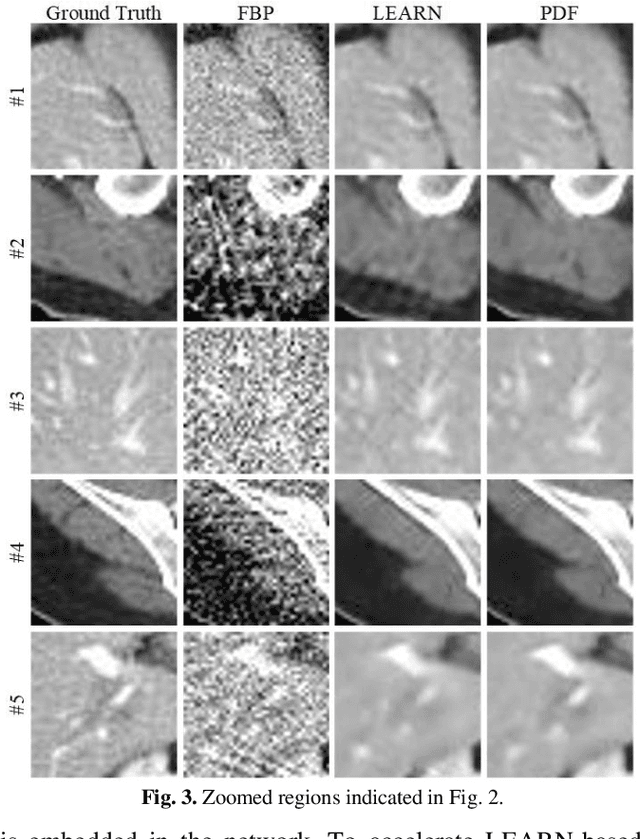
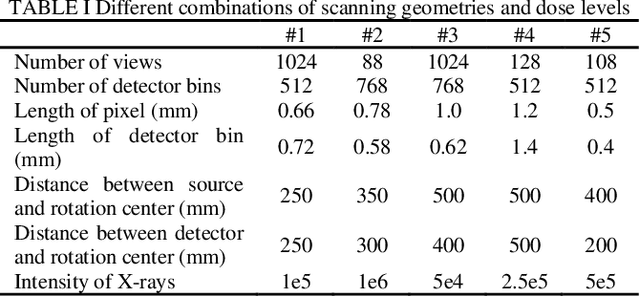
Current mainstream of CT reconstruction methods based on deep learning usually needs to fix the scanning geometry and dose level, which will significantly aggravate the training cost and need more training data for clinical application. In this paper, we propose a parameter-dependent framework (PDF) which trains data with multiple scanning geometries and dose levels simultaneously. In the proposed PDF, the geometry and dose level are parameterized and fed into two multi-layer perceptrons (MLPs). The MLPs are leveraged to modulate the feature maps of CT reconstruction network, which condition the network outputs on different scanning geometries and dose levels. The experiments show that our proposed method can obtain competing performance similar to the original network trained with specific geometry and dose level, which can efficiently save the extra training cost for multiple scanning geometries and dose levels.