 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMandarin Singing Voice Synthesis with Denoising Diffusion Probabilistic Wasserstein GAN
Sep 21, 2022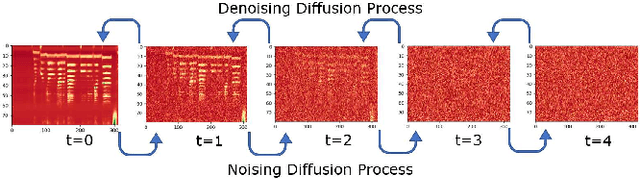

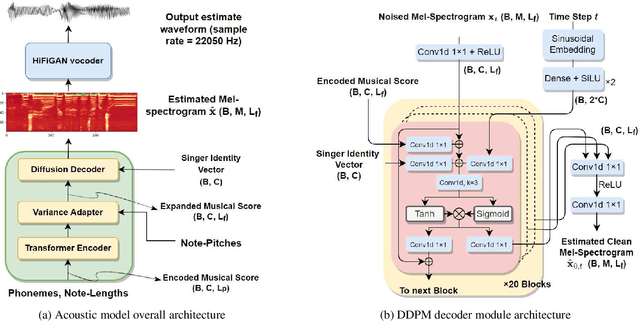
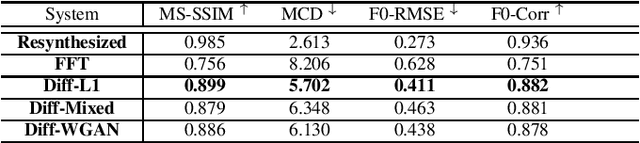
Singing voice synthesis (SVS) is the computer production of a human-like singing voice from given musical scores. To accomplish end-to-end SVS effectively and efficiently, this work adopts the acoustic model-neural vocoder architecture established for high-quality speech and singing voice synthesis. Specifically, this work aims to pursue a higher level of expressiveness in synthesized voices by combining the diffusion denoising probabilistic model (DDPM) and \emph{Wasserstein} generative adversarial network (WGAN) to construct the backbone of the acoustic model. On top of the proposed acoustic model, a HiFi-GAN neural vocoder is adopted with integrated fine-tuning to ensure optimal synthesis quality for the resulting end-to-end SVS system. This end-to-end system was evaluated with the multi-singer Mpop600 Mandarin singing voice dataset. In the experiments, the proposed system exhibits improvements over previous landmark counterparts in terms of musical expressiveness and high-frequency acoustic details. Moreover, the adversarial acoustic model converged stably without the need to enforce reconstruction objectives, indicating the convergence stability of the proposed DDPM and WGAN combined architecture over alternative GAN-based SVS systems.
NASTAR: Noise Adaptive Speech Enhancement with Target-Conditional Resampling
Jun 18, 2022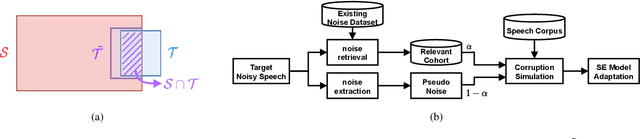
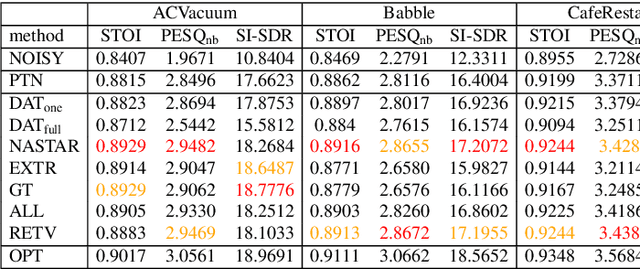
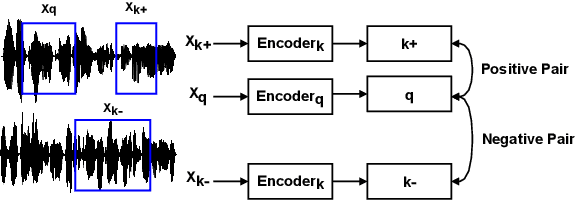
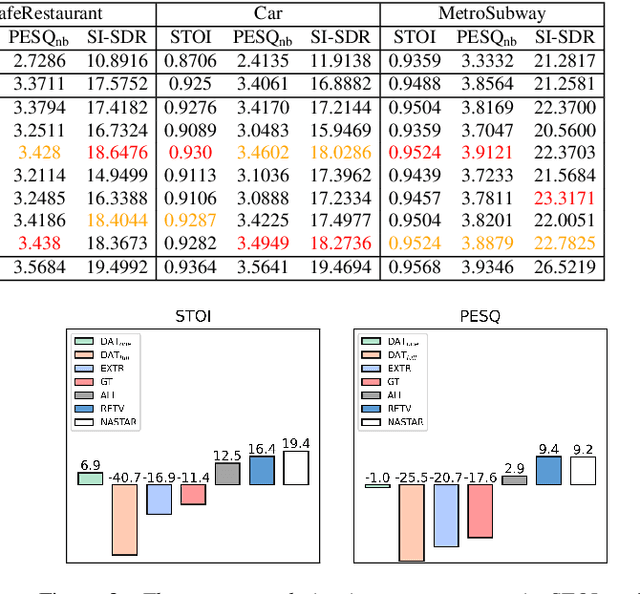
For deep learning-based speech enhancement (SE) systems, the training-test acoustic mismatch can cause notable performance degradation. To address the mismatch issue, numerous noise adaptation strategies have been derived. In this paper, we propose a novel method, called noise adaptive speech enhancement with target-conditional resampling (NASTAR), which reduces mismatches with only one sample (one-shot) of noisy speech in the target environment. NASTAR uses a feedback mechanism to simulate adaptive training data via a noise extractor and a retrieval model. The noise extractor estimates the target noise from the noisy speech, called pseudo-noise. The noise retrieval model retrieves relevant noise samples from a pool of noise signals according to the noisy speech, called relevant-cohort. The pseudo-noise and the relevant-cohort set are jointly sampled and mixed with the source speech corpus to prepare simulated training data for noise adaptation. Experimental results show that NASTAR can effectively use one noisy speech sample to adapt an SE model to a target condition. Moreover, both the noise extractor and the noise retrieval model contribute to model adaptation. To our best knowledge, NASTAR is the first work to perform one-shot noise adaptation through noise extraction and retrieval.
A Study of Using Cepstrogram for Countermeasure Against Replay Attacks
Apr 09, 2022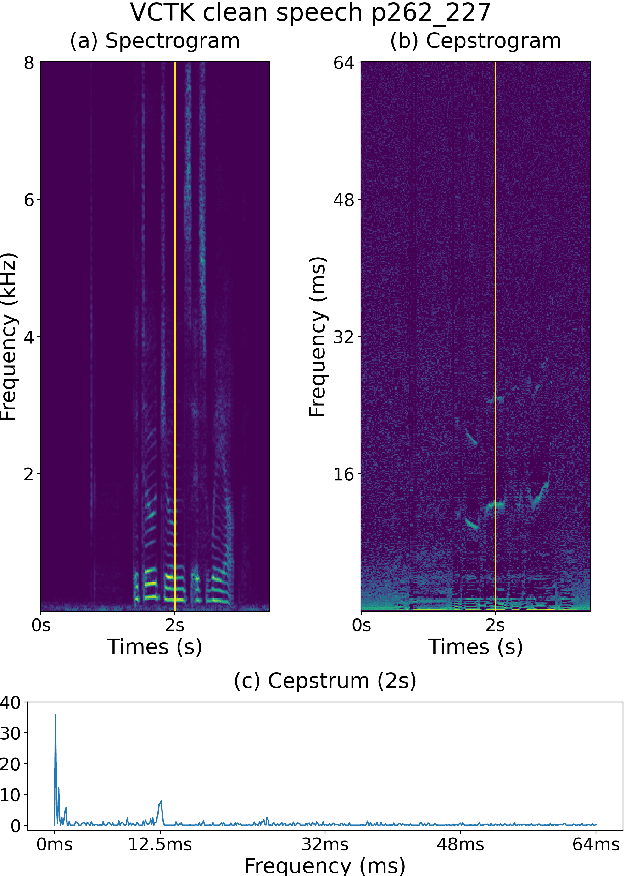
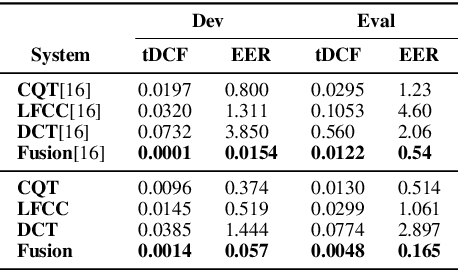
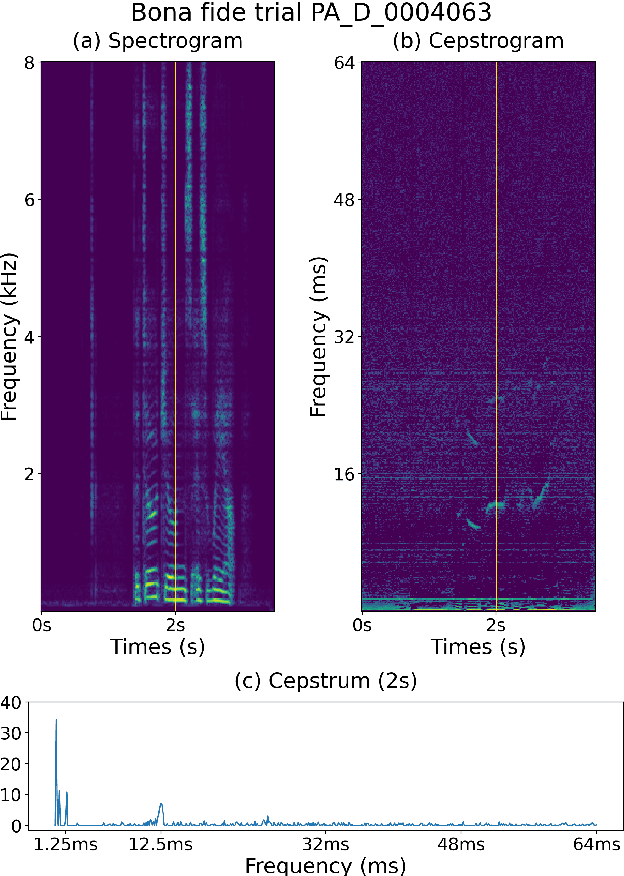
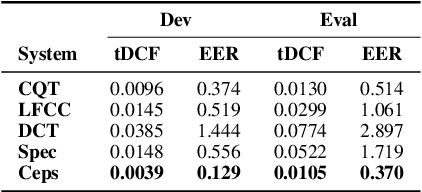
In this paper, we investigate the properties of the cepstrogram and demonstrate its effectiveness as a powerful feature for countermeasure against replay attacks. Cepstrum analysis of replay attacks suggests that crucial information for anti-spoofing against replay attacks may retain in the cepstrogram. Experimental results on the ASVspoof 2019 physical access (PA) database demonstrate that, compared with other features, the cepstrogram dominates in both single and fusion systems when building countermeasures against replay attacks. Our LCNN-based single and fusion systems with the cepstrogram feature outperform the corresponding LCNN-based systems without using the cepstrogram feature and several state-of-the-art (SOTA) single and fusion systems in the literature.
MTI-Net: A Multi-Target Speech Intelligibility Prediction Model
Apr 07, 2022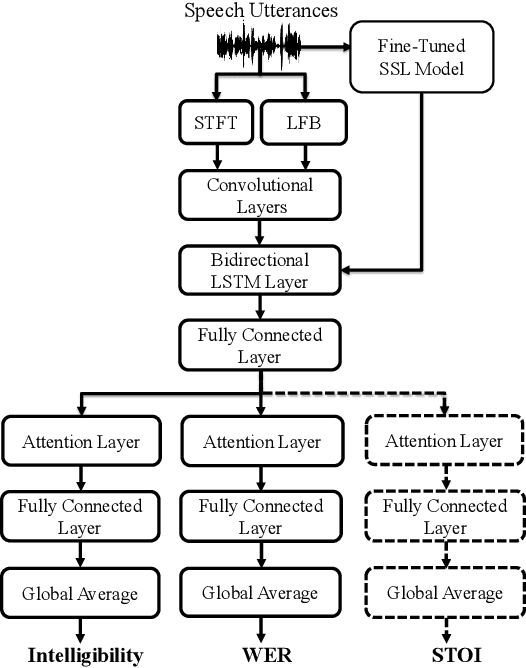
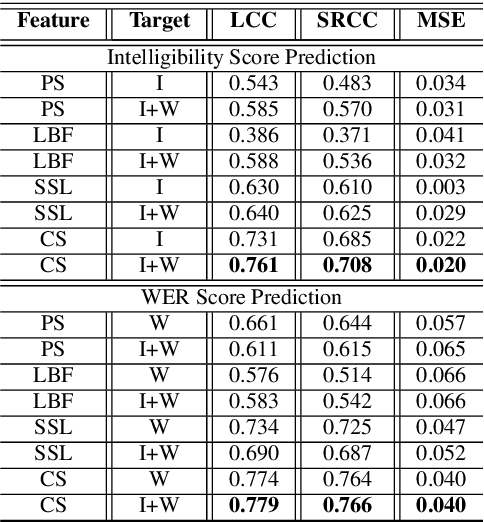
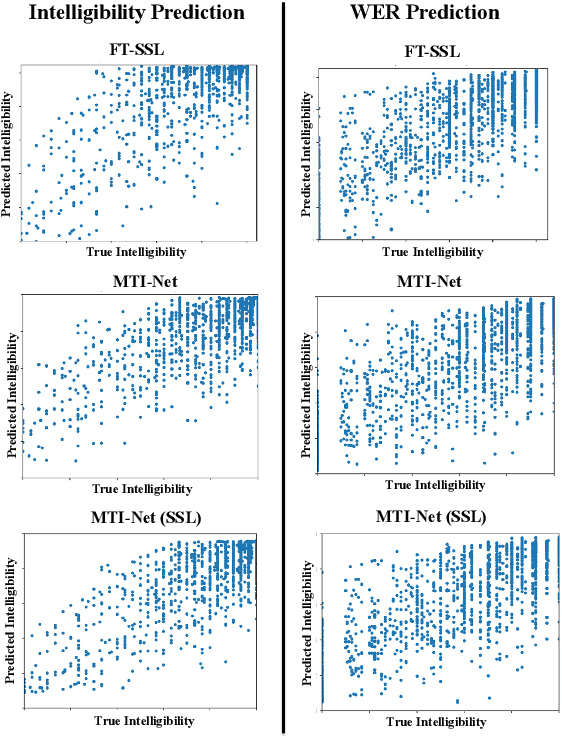
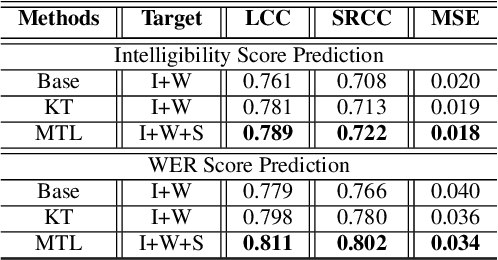
Recently, deep learning (DL)-based non-intrusive speech assessment models have attracted great attention. Many studies report that these DL-based models yield satisfactory assessment performance and good flexibility, but their performance in unseen environments remains a challenge. Furthermore, compared to quality scores, fewer studies elaborate deep learning models to estimate intelligibility scores. This study proposes a multi-task speech intelligibility prediction model, called MTI-Net, for simultaneously predicting human and machine intelligibility measures. Specifically, given a speech utterance, MTI-Net is designed to predict subjective listening test results and word error rate (WER) scores. We also investigate several methods that can improve the prediction performance of MTI-Net. First, we compare different features (including low-level features and embeddings from self-supervised learning (SSL) models) and prediction targets of MTI-Net. Second, we explore the effect of transfer learning and multi-tasking learning on training MTI-Net. Finally, we examine the potential advantages of fine-tuning SSL embeddings. Experimental results demonstrate the effectiveness of using cross-domain features, multi-task learning, and fine-tuning SSL embeddings. Furthermore, it is confirmed that the intelligibility and WER scores predicted by MTI-Net are highly correlated with the ground-truth scores.
MBI-Net: A Non-Intrusive Multi-Branched Speech Intelligibility Prediction Model for Hearing Aids
Apr 07, 2022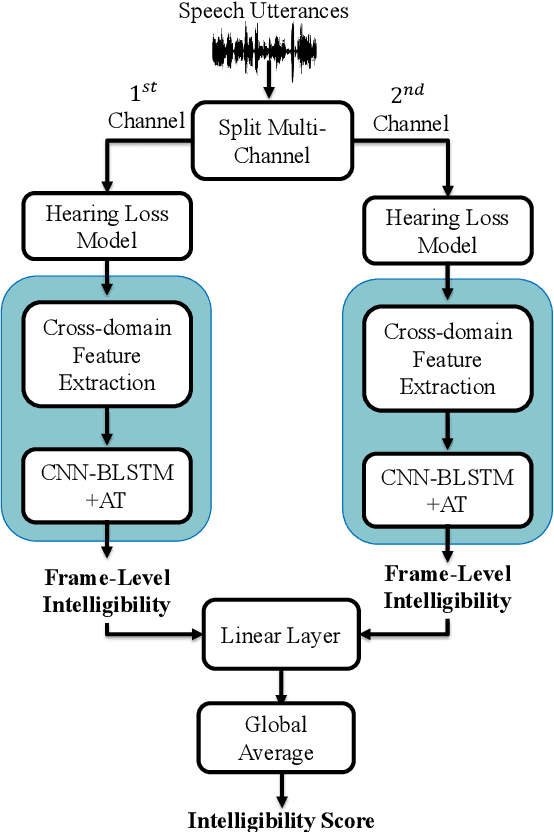
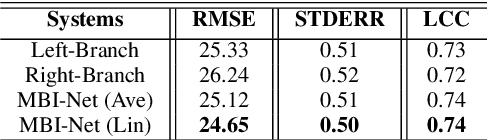
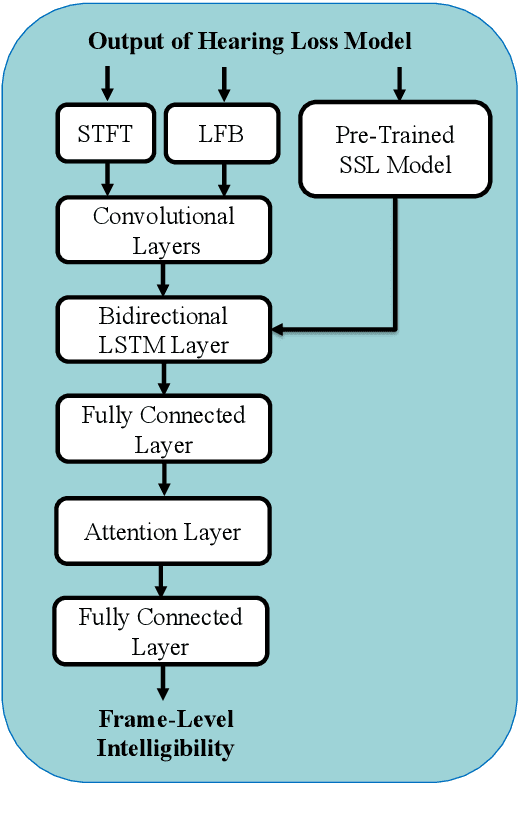
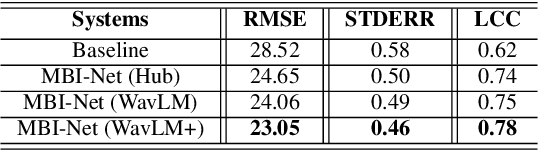
Improving the user's hearing ability to understand speech in noisy environments is critical to the development of hearing aid (HA) devices. For this, it is important to derive a metric that can fairly predict speech intelligibility for HA users. A straightforward approach is to conduct a subjective listening test and use the test results as an evaluation metric. However, conducting large-scale listening tests is time-consuming and expensive. Therefore, several evaluation metrics were derived as surrogates for subjective listening test results. In this study, we propose a multi-branched speech intelligibility prediction model (MBI-Net), for predicting the subjective intelligibility scores of HA users. MBI-Net consists of two branches of models, with each branch consisting of a hearing loss model, a cross-domain feature extraction module, and a speech intelligibility prediction model, to process speech signals from one channel. The outputs of the two branches are fused through a linear layer to obtain predicted speech intelligibility scores. Experimental results confirm the effectiveness of MBI-Net, which produces higher prediction scores than the baseline system in Track 1 and Track 2 on the Clarity Prediction Challenge 2022 dataset.
Filter-based Discriminative Autoencoders for Children Speech Recognition
Apr 01, 2022
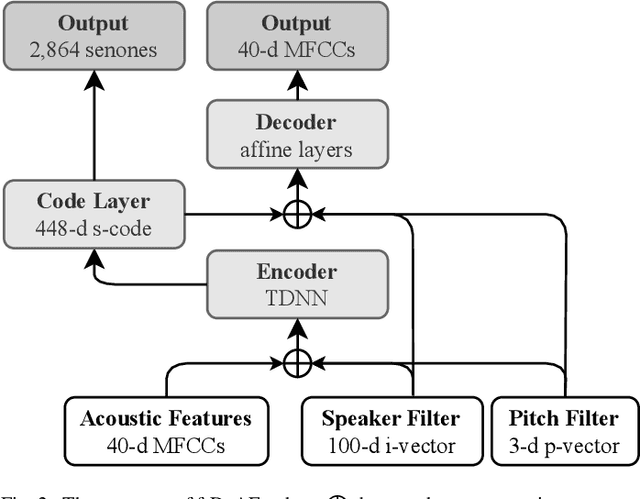
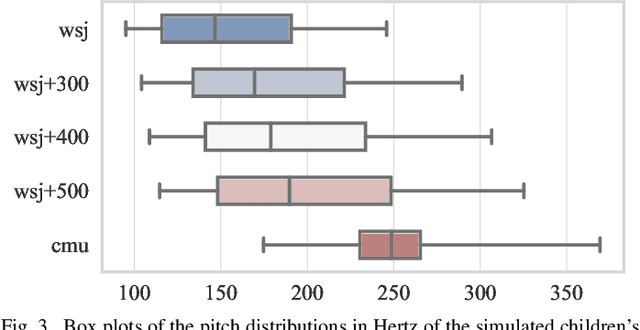
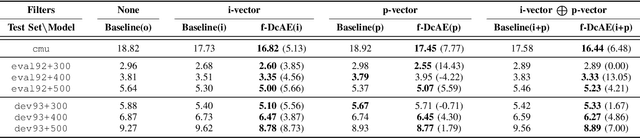
Children speech recognition is indispensable but challenging due to the diversity of children's speech. In this paper, we propose a filter-based discriminative autoencoder for acoustic modeling. To filter out the influence of various speaker types and pitches, auxiliary information of the speaker and pitch features is input into the encoder together with the acoustic features to generate phonetic embeddings. In the training phase, the decoder uses the auxiliary information and the phonetic embedding extracted by the encoder to reconstruct the input acoustic features. The autoencoder is trained by simultaneously minimizing the ASR loss and feature reconstruction error. The framework can make the phonetic embedding purer, resulting in more accurate senone (triphone-state) scores. Evaluated on the test set of the CMU Kids corpus, our system achieves a 7.8% relative WER reduction compared to the baseline system. In the domain adaptation experiment, our system also outperforms the baseline system on the British-accent PF-STAR task.
Generation of Speaker Representations Using Heterogeneous Training Batch Assembly
Mar 30, 2022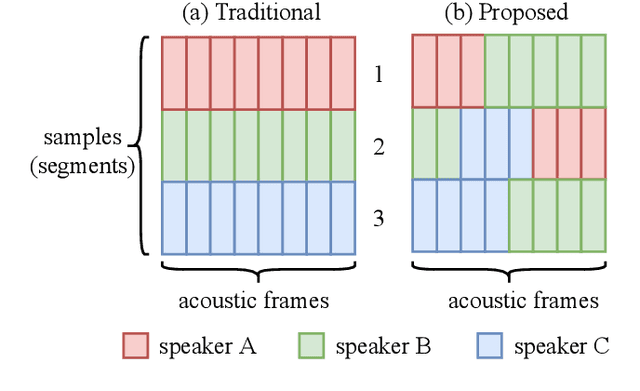
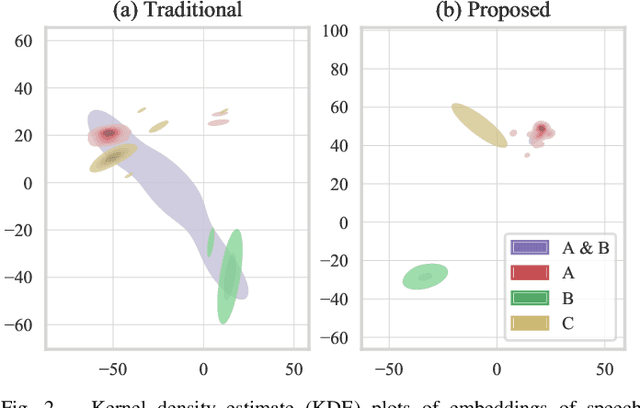
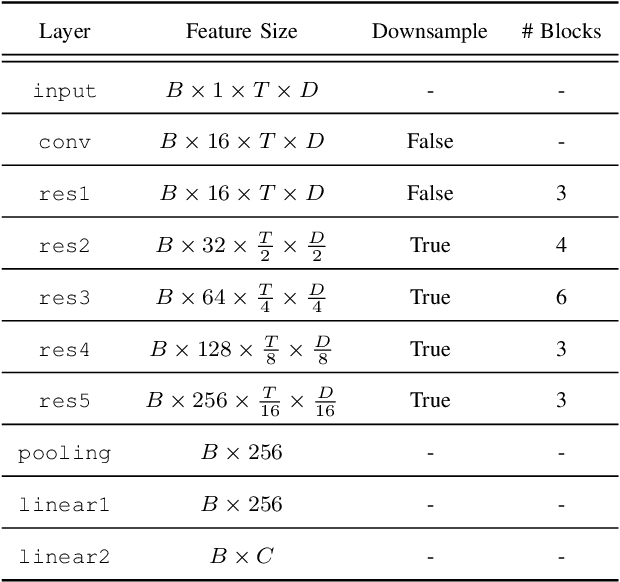
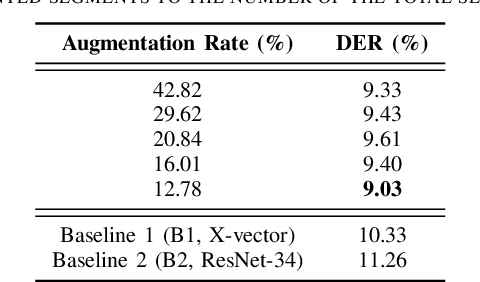
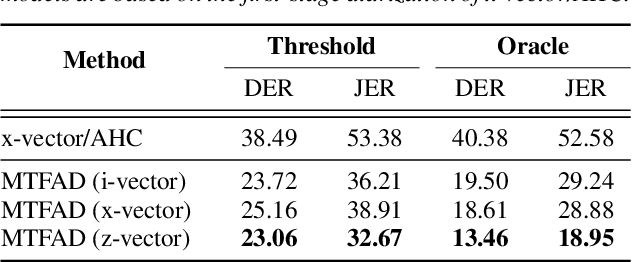
In traditional speaker diarization systems, a well-trained speaker model is a key component to extract representations from consecutive and partially overlapping segments in a long speech session. To be more consistent with the back-end segmentation and clustering, we propose a new CNN-based speaker modeling scheme, which takes into account the heterogeneity of the speakers in each training segment and batch. We randomly and synthetically augment the training data into a set of segments, each of which contains more than one speaker and some overlapping parts. A soft label is imposed on each segment based on its speaker occupation ratio, and the standard cross entropy loss is implemented in model training. In this way, the speaker model should have the ability to generate a geometrically meaningful embedding for each multi-speaker segment. Experimental results show that our system is superior to the baseline system using x-vectors in two speaker diarization tasks. In the CALLHOME task trained on the NIST SRE and Switchboard datasets, our system achieves a relative reduction of 12.93% in DER. In Track 2 of CHiME-6, our system provides 13.24%, 12.60%, and 5.65% relative reductions in DER, JER, and WER, respectively.
Disentangling the Impacts of Language and Channel Variability on Speech Separation Networks
Mar 30, 2022
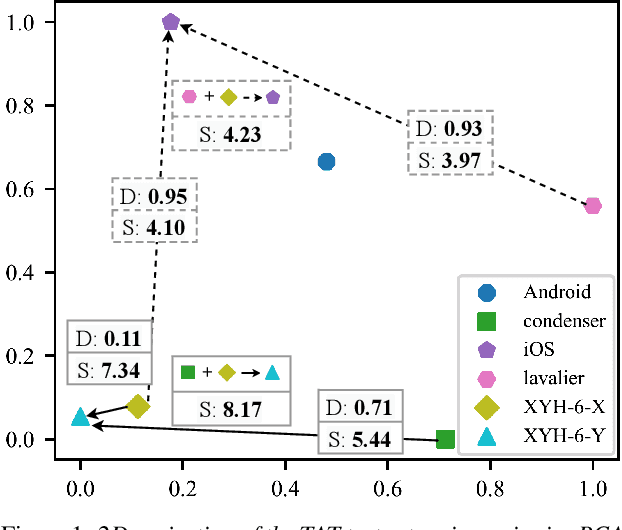
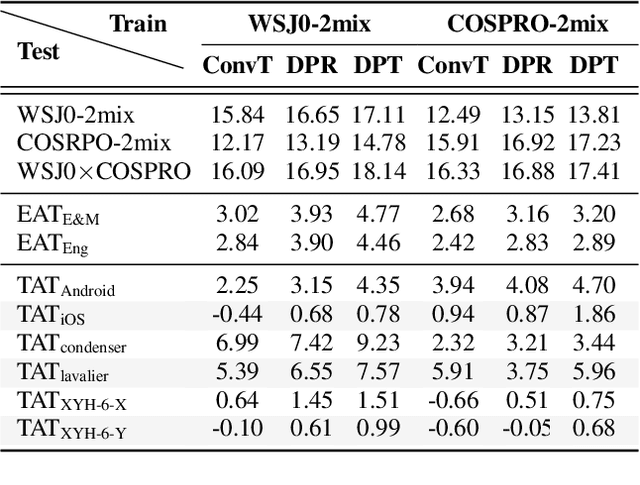
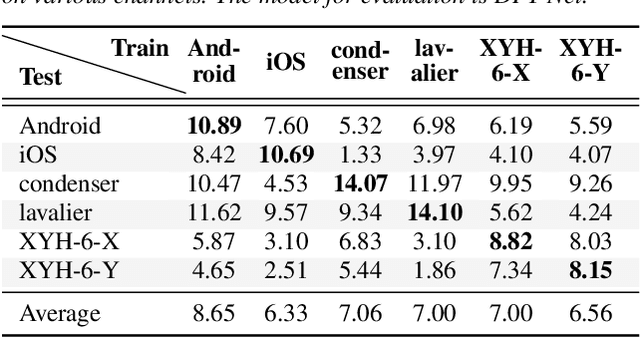
Because the performance of speech separation is excellent for speech in which two speakers completely overlap, research attention has been shifted to dealing with more realistic scenarios. However, domain mismatch between training/test situations due to factors, such as speaker, content, channel, and environment, remains a severe problem for speech separation. Speaker and environment mismatches have been studied in the existing literature. Nevertheless, there are few studies on speech content and channel mismatches. Moreover, the impacts of language and channel in these studies are mostly tangled. In this study, we create several datasets for various experiments. The results show that the impacts of different languages are small enough to be ignored compared to the impacts of different channels. In our experiments, training on data recorded by Android phones leads to the best generalizability. Moreover, we provide a new solution for channel mismatch by evaluating projection, where the channel similarity can be measured and used to effectively select additional training data to improve the performance of in-the-wild test data.
Multi-Target Filter and Detector for Speaker Diarization
Mar 30, 2022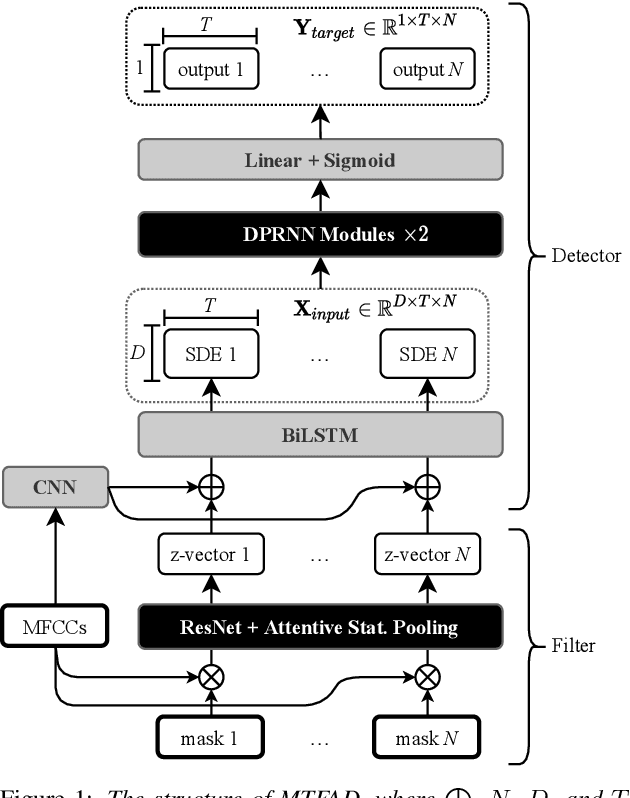
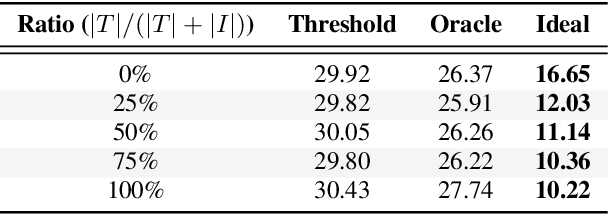
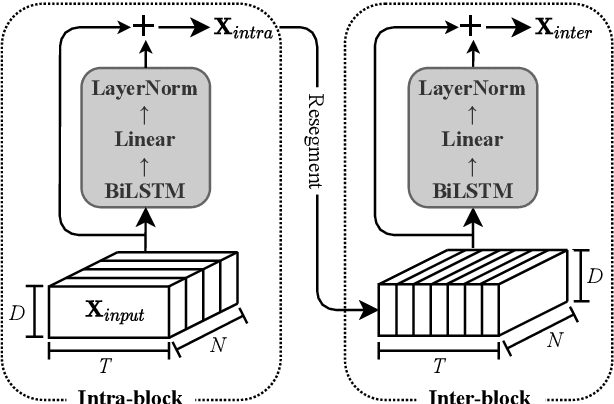
A good representation of a target speaker usually helps to extract important information about the speaker and detect the corresponding temporal regions in a multi-speaker conversation. In this paper, we propose a neural architecture that simultaneously extracts speaker embeddings consistent with the speaker diarization objective and detects the presence of each speaker frame by frame, regardless of the number of speakers in the conversation. To this end, a residual network (ResNet) and a dual-path recurrent neural network (DPRNN) are integrated into a unified structure. When tested on the 2-speaker CALLHOME corpus, our proposed model outperforms most methods published so far. Evaluated in a more challenging case of concurrent speakers ranging from two to seven, our system also achieves relative diarization error rate reductions of 26.35% and 6.4% over two typical baselines, namely the traditional x-vector clustering system and the attention-based system.
Chain-based Discriminative Autoencoders for Speech Recognition
Mar 28, 2022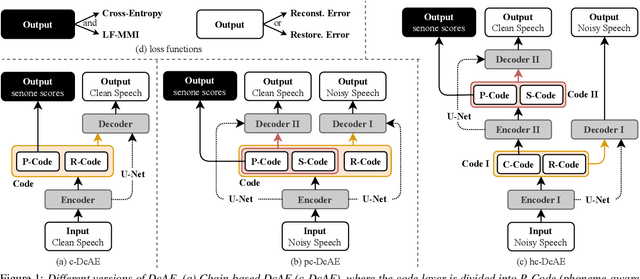
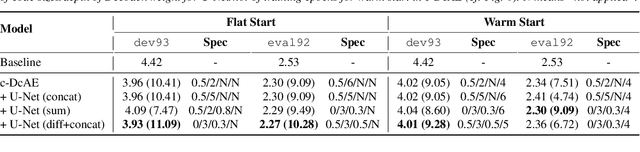
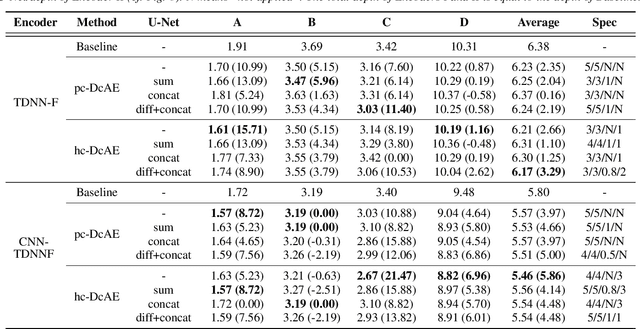
In our previous work, we proposed a discriminative autoencoder (DcAE) for speech recognition. DcAE combines two training schemes into one. First, since DcAE aims to learn encoder-decoder mappings, the squared error between the reconstructed speech and the input speech is minimized. Second, in the code layer, frame-based phonetic embeddings are obtained by minimizing the categorical cross-entropy between ground truth labels and predicted triphone-state scores. DcAE is developed based on the Kaldi toolkit by treating various TDNN models as encoders. In this paper, we further propose three new versions of DcAE. First, a new objective function that considers both categorical cross-entropy and mutual information between ground truth and predicted triphone-state sequences is used. The resulting DcAE is called a chain-based DcAE (c-DcAE). For application to robust speech recognition, we further extend c-DcAE to hierarchical and parallel structures, resulting in hc-DcAE and pc-DcAE. In these two models, both the error between the reconstructed noisy speech and the input noisy speech and the error between the enhanced speech and the reference clean speech are taken into the objective function. Experimental results on the WSJ and Aurora-4 corpora show that our DcAE models outperform baseline systems.