 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Speech-to-Speech Translation into Multiple Target Languages
Jul 17, 2023



Speech-to-speech translation (S2ST) enables spoken communication between people talking in different languages. Despite a few studies on multilingual S2ST, their focus is the multilinguality on the source side, i.e., the translation from multiple source languages to one target language. We present the first work on multilingual S2ST supporting multiple target languages. Leveraging recent advance in direct S2ST with speech-to-unit and vocoder, we equip these key components with multilingual capability. Speech-to-masked-unit (S2MU) is the multilingual extension of S2U, which applies masking to units which don't belong to the given target language to reduce the language interference. We also propose multilingual vocoder which is trained with language embedding and the auxiliary loss of language identification. On benchmark translation testsets, our proposed multilingual model shows superior performance than bilingual models in the translation from English into $16$ target languages.
Pre-training for Speech Translation: CTC Meets Optimal Transport
Jan 27, 2023The gap between speech and text modalities is a major challenge in speech-to-text translation (ST). Different methods have been proposed for reducing this gap, but most of them require architectural changes in ST training. In this work, we propose to mitigate this issue at the pre-training stage, requiring no change in the ST model. First, we show that the connectionist temporal classification (CTC) loss can reduce the modality gap by design. We provide a quantitative comparison with the more common cross-entropy loss, showing that pre-training with CTC consistently achieves better final ST accuracy. Nevertheless, CTC is only a partial solution and thus, in our second contribution, we propose a novel pre-training method combining CTC and optimal transport to further reduce this gap. Our method pre-trains a Siamese-like model composed of two encoders, one for acoustic inputs and the other for textual inputs, such that they produce representations that are close to each other in the Wasserstein space. Extensive experiments on the standard CoVoST-2 and MuST-C datasets show that our pre-training method applied to the vanilla encoder-decoder Transformer achieves state-of-the-art performance under the no-external-data setting, and performs on par with recent strong multi-task learning systems trained with external data. Finally, our method can also be applied on top of these multi-task systems, leading to further improvements for these models.
A Holistic Cascade System, benchmark, and Human Evaluation Protocol for Expressive Speech-to-Speech Translation
Jan 25, 2023



Expressive speech-to-speech translation (S2ST) aims to transfer prosodic attributes of source speech to target speech while maintaining translation accuracy. Existing research in expressive S2ST is limited, typically focusing on a single expressivity aspect at a time. Likewise, this research area lacks standard evaluation protocols and well-curated benchmark datasets. In this work, we propose a holistic cascade system for expressive S2ST, combining multiple prosody transfer techniques previously considered only in isolation. We curate a benchmark expressivity test set in the TV series domain and explored a second dataset in the audiobook domain. Finally, we present a human evaluation protocol to assess multiple expressive dimensions across speech pairs. Experimental results indicate that bi-lingual annotators can assess the quality of expressive preservation in S2ST systems, and the holistic modeling approach outperforms single-aspect systems. Audio samples can be accessed through our demo webpage: https://facebookresearch.github.io/speech_translation/cascade_expressive_s2st.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022



We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
SpeechMatrix: A Large-Scale Mined Corpus of Multilingual Speech-to-Speech Translations
Nov 08, 2022



We present SpeechMatrix, a large-scale multilingual corpus of speech-to-speech translations mined from real speech of European Parliament recordings. It contains speech alignments in 136 language pairs with a total of 418 thousand hours of speech. To evaluate the quality of this parallel speech, we train bilingual speech-to-speech translation models on mined data only and establish extensive baseline results on EuroParl-ST, VoxPopuli and FLEURS test sets. Enabled by the multilinguality of SpeechMatrix, we also explore multilingual speech-to-speech translation, a topic which was addressed by few other works. We also demonstrate that model pre-training and sparse scaling using Mixture-of-Experts bring large gains to translation performance. The mined data and models are freely available.
Improving Speech-to-Speech Translation Through Unlabeled Text
Oct 26, 2022Direct speech-to-speech translation (S2ST) is among the most challenging problems in the translation paradigm due to the significant scarcity of S2ST data. While effort has been made to increase the data size from unlabeled speech by cascading pretrained speech recognition (ASR), machine translation (MT) and text-to-speech (TTS) models; unlabeled text has remained relatively under-utilized to improve S2ST. We propose an effective way to utilize the massive existing unlabeled text from different languages to create a large amount of S2ST data to improve S2ST performance by applying various acoustic effects to the generated synthetic data. Empirically our method outperforms the state of the art in Spanish-English translation by up to 2 BLEU. Significant gains by the proposed method are demonstrated in extremely low-resource settings for both Spanish-English and Russian-English translations.
T-Modules: Translation Modules for Zero-Shot Cross-Modal Machine Translation
May 24, 2022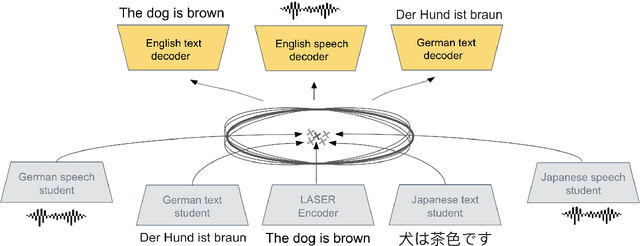

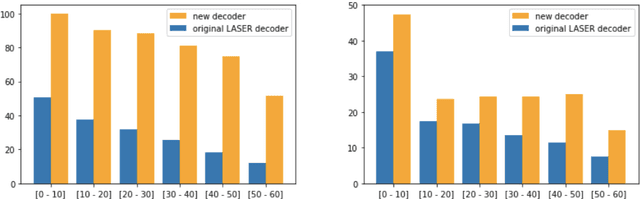
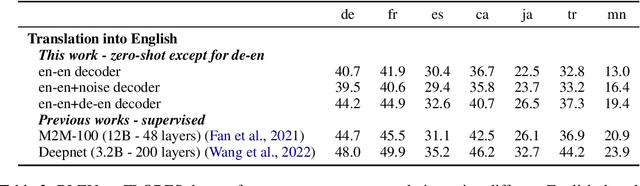
We present a new approach to perform zero-shot cross-modal transfer between speech and text for translation tasks. Multilingual speech and text are encoded in a joint fixed-size representation space. Then, we compare different approaches to decode these multimodal and multilingual fixed-size representations, enabling zero-shot translation between languages and modalities. All our models are trained without the need of cross-modal labeled translation data. Despite a fixed-size representation, we achieve very competitive results on several text and speech translation tasks. In particular, we significantly improve the state-of-the-art for zero-shot speech translation on Must-C. Incorporating a speech decoder in our framework, we introduce the first results for zero-shot direct speech-to-speech and text-to-speech translation.
Unified Speech-Text Pre-training for Speech Translation and Recognition
Apr 11, 2022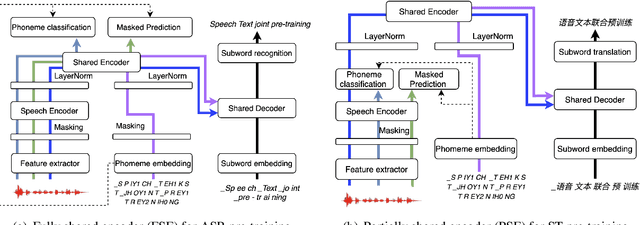

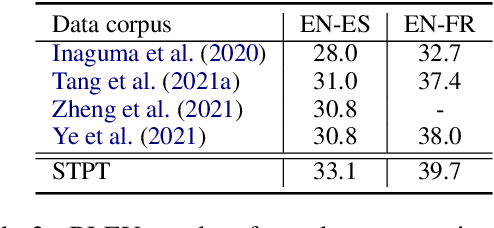
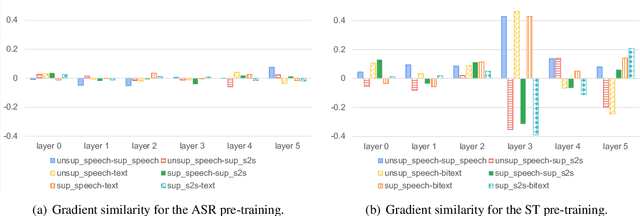
We describe a method to jointly pre-train speech and text in an encoder-decoder modeling framework for speech translation and recognition. The proposed method incorporates four self-supervised and supervised subtasks for cross modality learning. A self-supervised speech subtask leverages unlabelled speech data, and a (self-)supervised text to text subtask makes use of abundant text training data. Two auxiliary supervised speech tasks are included to unify speech and text modeling space. Our contribution lies in integrating linguistic information from the text corpus into the speech pre-training. Detailed analysis reveals learning interference among subtasks. Two pre-training configurations for speech translation and recognition, respectively, are presented to alleviate subtask interference. Our experiments show the proposed method can effectively fuse speech and text information into one model. It achieves between 1.7 and 2.3 BLEU improvement above the state of the art on the MuST-C speech translation dataset and comparable WERs to wav2vec 2.0 on the Librispeech speech recognition task.
Efficient Language Modeling with Sparse all-MLP
Mar 16, 2022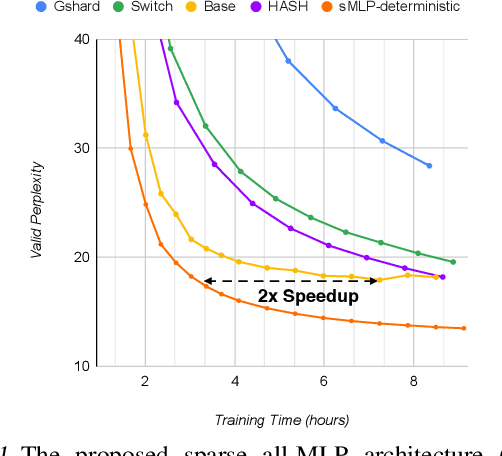

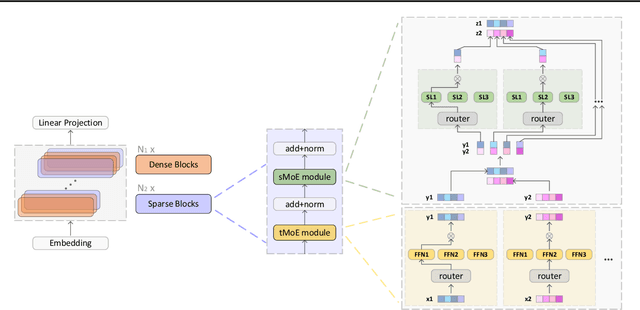

All-MLP architectures have attracted increasing interest as an alternative to attention-based models. In NLP, recent work like gMLP shows that all-MLPs can match Transformers in language modeling, but still lag behind in downstream tasks. In this work, we analyze the limitations of MLPs in expressiveness, and propose sparsely activated MLPs with mixture-of-experts (MoEs) in both feature and input (token) dimensions. Such sparse all-MLPs significantly increase model capacity and expressiveness while keeping the compute constant. We address critical challenges in incorporating conditional computation with two routing strategies. The proposed sparse all-MLP improves language modeling perplexity and obtains up to 2$\times$ improvement in training efficiency compared to both Transformer-based MoEs (GShard, Switch Transformer, Base Layers and HASH Layers) as well as dense Transformers and all-MLPs. Finally, we evaluate its zero-shot in-context learning performance on six downstream tasks, and find that it surpasses Transformer-based MoEs and dense Transformers.
Idiomatic Expression Paraphrasing without Strong Supervision
Dec 16, 2021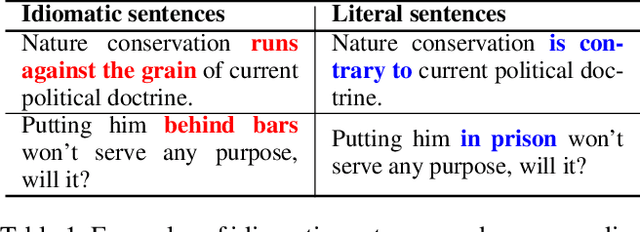
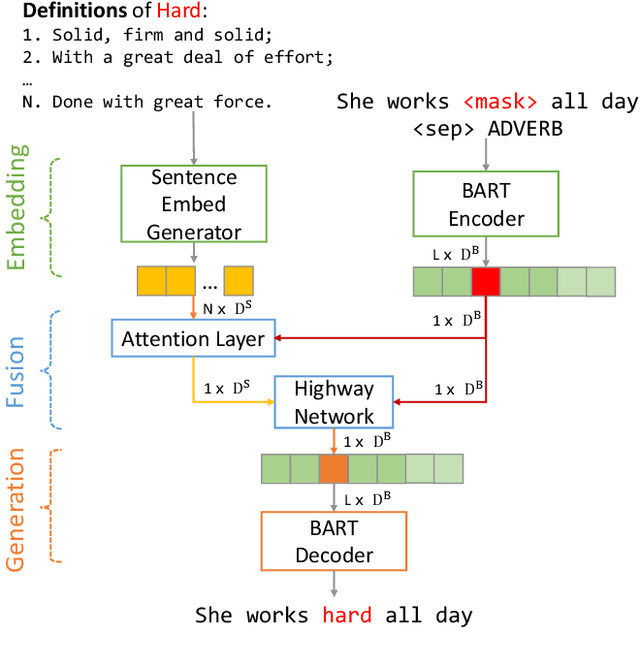
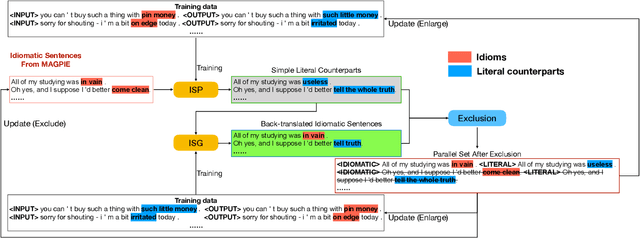
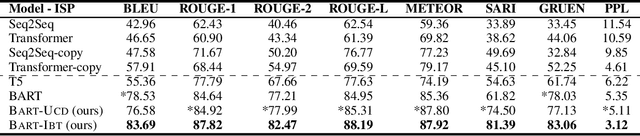
Idiomatic expressions (IEs) play an essential role in natural language. In this paper, we study the task of idiomatic sentence paraphrasing (ISP), which aims to paraphrase a sentence with an IE by replacing the IE with its literal paraphrase. The lack of large-scale corpora with idiomatic-literal parallel sentences is a primary challenge for this task, for which we consider two separate solutions. First, we propose an unsupervised approach to ISP, which leverages an IE's contextual information and definition and does not require a parallel sentence training set. Second, we propose a weakly supervised approach using back-translation to jointly perform paraphrasing and generation of sentences with IEs to enlarge the small-scale parallel sentence training dataset. Other significant derivatives of the study include a model that replaces a literal phrase in a sentence with an IE to generate an idiomatic expression and a large scale parallel dataset with idiomatic/literal sentence pairs. The effectiveness of the proposed solutions compared to competitive baselines is seen in the relative gains of over 5.16 points in BLEU, over 8.75 points in METEOR, and over 19.57 points in SARI when the generated sentences are empirically validated on a parallel dataset using automatic and manual evaluations. We demonstrate the practical utility of ISP as a preprocessing step in En-De machine translation.