 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProKD: An Unsupervised Prototypical Knowledge Distillation Network for Zero-Resource Cross-Lingual Named Entity Recognition
Jan 21, 2023For named entity recognition (NER) in zero-resource languages, utilizing knowledge distillation methods to transfer language-independent knowledge from the rich-resource source languages to zero-resource languages is an effective means. Typically, these approaches adopt a teacher-student architecture, where the teacher network is trained in the source language, and the student network seeks to learn knowledge from the teacher network and is expected to perform well in the target language. Despite the impressive performance achieved by these methods, we argue that they have two limitations. Firstly, the teacher network fails to effectively learn language-independent knowledge shared across languages due to the differences in the feature distribution between the source and target languages. Secondly, the student network acquires all of its knowledge from the teacher network and ignores the learning of target language-specific knowledge. Undesirably, these limitations would hinder the model's performance in the target language. This paper proposes an unsupervised prototype knowledge distillation network (ProKD) to address these issues. Specifically, ProKD presents a contrastive learning-based prototype alignment method to achieve class feature alignment by adjusting the distance among prototypes in the source and target languages, boosting the teacher network's capacity to acquire language-independent knowledge. In addition, ProKD introduces a prototypical self-training method to learn the intrinsic structure of the language by retraining the student network on the target data using samples' distance information from prototypes, thereby enhancing the student network's ability to acquire language-specific knowledge. Extensive experiments on three benchmark cross-lingual NER datasets demonstrate the effectiveness of our approach.
Label Mask AutoEncoder(L-MAE): A Pure Transformer Method to Augment Semantic Segmentation Datasets
Nov 21, 2022



Semantic segmentation models based on the conventional neural network can achieve remarkable performance in such tasks, while the dataset is crucial to the training model process. Significant progress in expanding datasets has been made in semi-supervised semantic segmentation recently. However, completing the pixel-level information remains challenging due to possible missing in a label. Inspired by Mask AutoEncoder, we present a simple yet effective Pixel-Level completion method, Label Mask AutoEncoder(L-MAE), that fully uses the existing information in the label to predict results. The proposed model adopts the fusion strategy that stacks the label and the corresponding image, namely Fuse Map. Moreover, since some of the image information is lost when masking the Fuse Map, direct reconstruction may lead to poor performance. Our proposed Image Patch Supplement algorithm can supplement the missing information, as the experiment shows, an average of 4.1% mIoU can be improved. The Pascal VOC2012 dataset (224 crop size, 20 classes) and the Cityscape dataset (448 crop size, 19 classes) are used in the comparative experiments. With the Mask Ratio setting to 50%, in terms of the prediction region, the proposed model achieves 91.0% and 86.4% of mIoU on Pascal VOC 2012 and Cityscape, respectively, outperforming other current supervised semantic segmentation models. Our code and models are available at https://github.com/jjrccop/Label-Mask-Auto-Encoder.
A Novel Few-Shot Relation Extraction Pipeline Based on Adaptive Prototype Fusion
Oct 15, 2022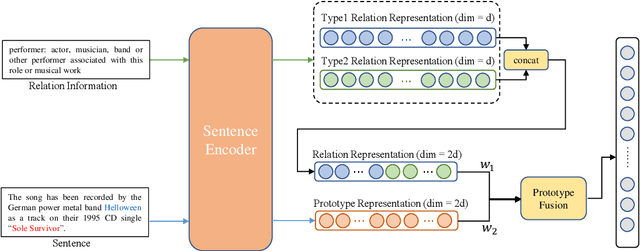
Few-shot relation extraction (FSRE) aims at recognizing unseen relations by learning with merely a handful of annotated instances. To more effectively generalize to new relations, this paper proposes a novel pipeline for the FSRE task based on adaptive prototype fusion. Specifically, for each relation class, the pipeline fully explores the relation information by concatenating two types of embedding, and then elaborately combine the relation representation with the adaptive prototype fusion mechanism. The whole framework can be effectively and efficiently optimized in an end-to-end fashion. Experiments on the benchmark dataset FewRel 1.0 show a significant improvement of our method against state-of-the-art methods.
Novel 3D Scene Understanding Applications From Recurrence in a Single Image
Oct 14, 2022


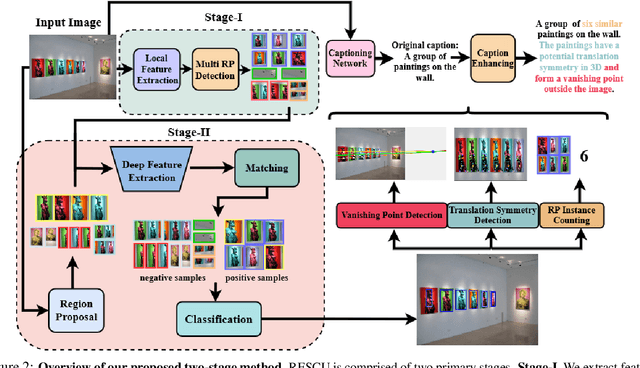
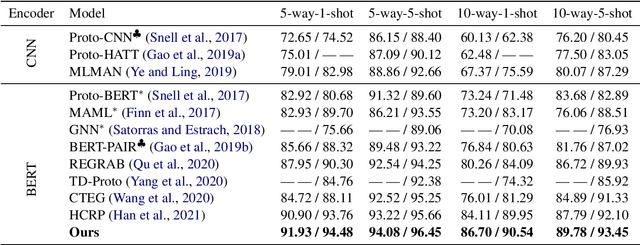
We demonstrate the utility of recurring pattern discovery from a single image for spatial understanding of a 3D scene in terms of (1) vanishing point detection, (2) hypothesizing 3D translation symmetry and (3) counting the number of RP instances in the image. Furthermore, we illustrate the feasibility of leveraging RP discovery output to form a more precise, quantitative text description of the scene. Our quantitative evaluations on a new 1K+ Recurring Pattern (RP) benchmark with diverse variations show that visual perception of recurrence from one single view leads to scene understanding outcomes that are as good as or better than existing supervised methods and/or unsupervised methods that use millions of images.
NDD: A 3D Point Cloud Descriptor Based on Normal Distribution for Loop Closure Detection
Sep 26, 2022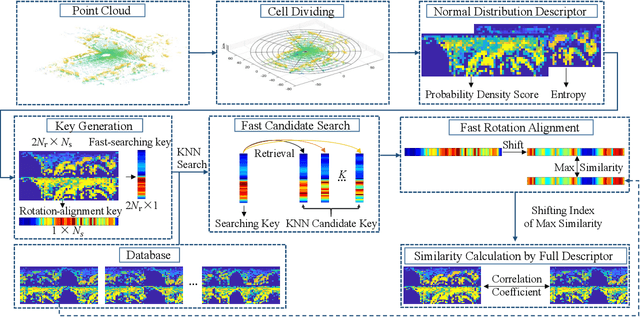
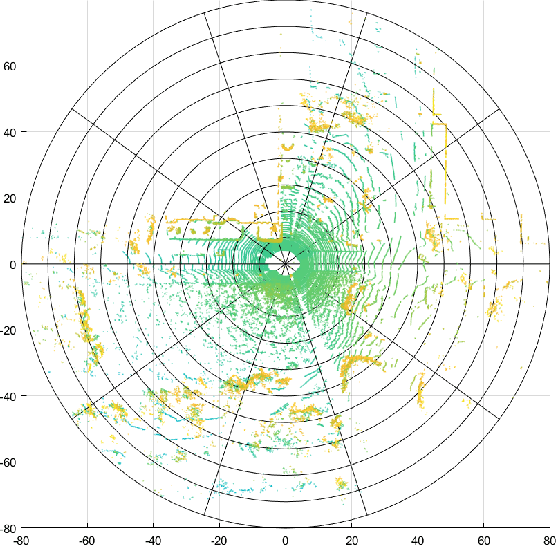
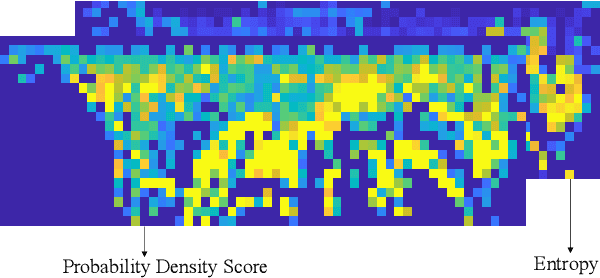

Loop closure detection is a key technology for long-term robot navigation in complex environments. In this paper, we present a global descriptor, named Normal Distribution Descriptor (NDD), for 3D point cloud loop closure detection. The descriptor encodes both the probability density score and entropy of a point cloud as the descriptor. We also propose a fast rotation alignment process and use correlation coefficient as the similarity between descriptors. Experimental results show that our approach outperforms the state-of-the-art point cloud descriptors in both accuracy and efficency. The source code is available and can be integrated into existing LiDAR odometry and mapping (LOAM) systems.
Optimizing SLAM Evaluation Footprint Through Dynamic Range Coverage Analysis of Datasets
Sep 13, 2022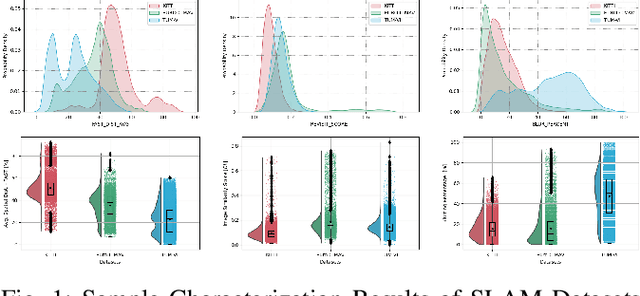
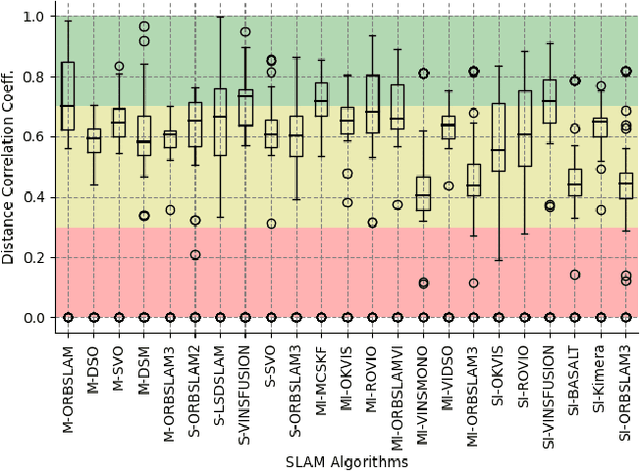
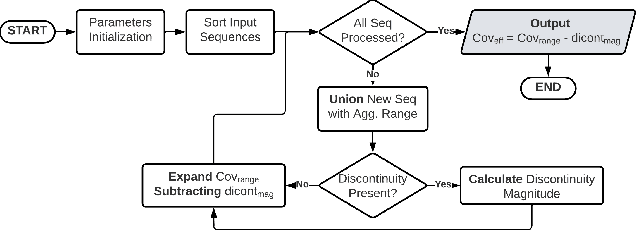
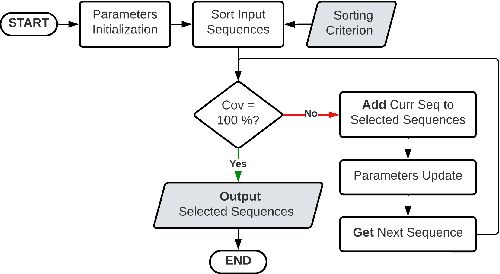
Simultaneous Localization and Mapping (SLAM) is considered an ever-evolving problem due to its usage in many applications. Evaluation of SLAM is done typically using publicly available datasets which are increasing in number and the level of difficulty. Each dataset provides a certain level of dynamic range coverage that is a key aspect of measuring the robustness and resilience of SLAM. In this paper, we provide a systematic analysis of the dynamic range coverage of datasets based on a number of characterization metrics, and our analysis shows a huge level of redundancy within and between datasets. Subsequently, we propose a dynamic programming (DP) algorithm for eliminating the redundancy in the evaluation process of SLAM by selecting a subset of sequences that matches a single or multiple dynamic range coverage objectives. It is shown that, with the help of dataset characterization and DP selection algorithm, a reduction in the evaluation effort can be achieved while maintaining the same level of coverage. Finally, we show that, in a multi-objective SLAM setup, the aggregation of multiple runs of the algorithm can achieve the same conclusions in localization accuracy by a SLAM algorithms.
Predicting microsatellite instability and key biomarkers in colorectal cancer from H&E-stained images: Achieving SOTA with Less Data using Swin Transformer
Aug 22, 2022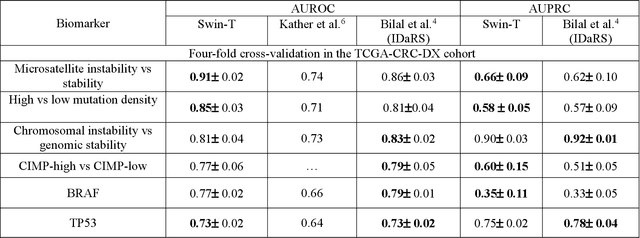
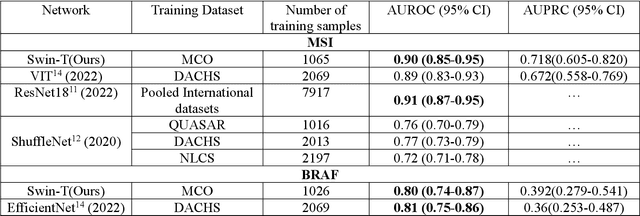
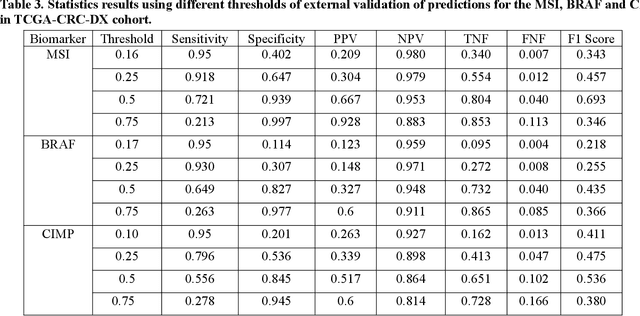
Artificial intelligence (AI) models have been developed for predicting clinically relevant biomarkers, including microsatellite instability (MSI), for colorectal cancers (CRC). However, the current deep-learning networks are data-hungry and require large training datasets, which are often lacking in the medical domain. In this study, based on the latest Hierarchical Vision Transformer using Shifted Windows (Swin-T), we developed an efficient workflow for biomarkers in CRC (MSI, hypermutation, chromosomal instability, CpG island methylator phenotype, BRAF, and TP53 mutation) that only required relatively small datasets, but achieved the state-of-the-art (SOTA) predictive performance. Our Swin-T workflow not only substantially outperformed published models in an intra-study cross-validation experiment using TCGA-CRC-DX dataset (N = 462), but also showed excellent generalizability in cross-study external validation and delivered a SOTA AUROC of 0.90 for MSI using the MCO dataset for training (N = 1065) and the same TCGA-CRC-DX for testing. Similar performance (AUROC=0.91) was achieved by Echle and colleagues using 8000 training samples (ResNet18) on the same testing dataset. Swin-T was extremely efficient using small training datasets and exhibits robust predictive performance with only 200-500 training samples. These data indicate that Swin-T may be 5-10 times more efficient than the current state-of-the-art algorithms for MSI based on ResNet18 and ShuffleNet. Furthermore, the Swin-T models showed promise as pre-screening tests for MSI status and BRAF mutation status, which could exclude and reduce the samples before the subsequent standard testing in a cascading diagnostic workflow to allow turnaround time reduction and cost saving.
Accelerating Numerical Solvers for Large-Scale Simulation of Dynamical System via NeurVec
Aug 07, 2022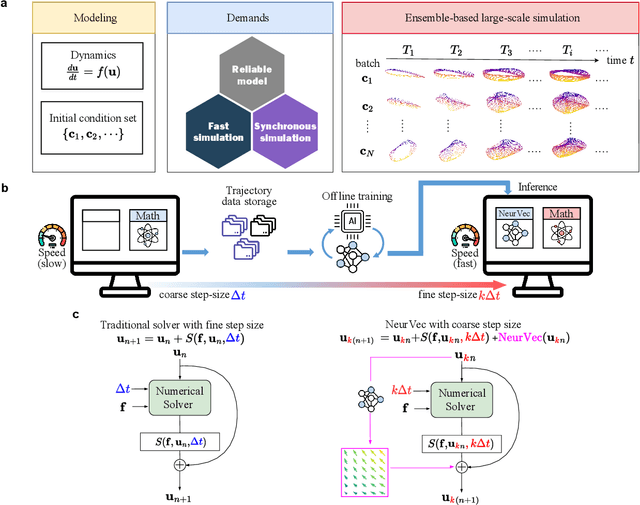

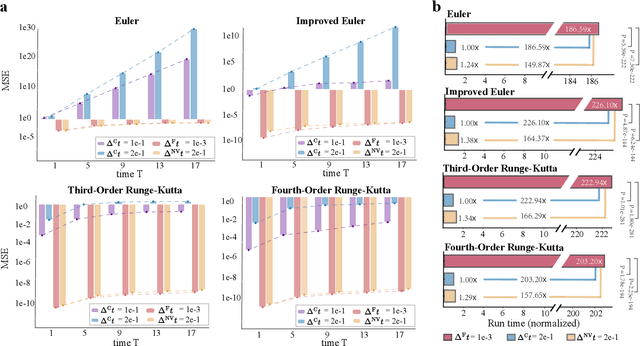
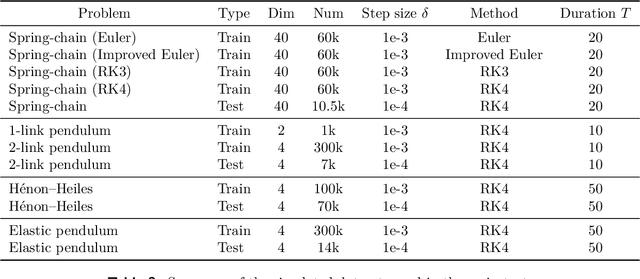
Ensemble-based large-scale simulation of dynamical systems is essential to a wide range of science and engineering problems. Conventional numerical solvers used in the simulation are significantly limited by the step size for time integration, which hampers efficiency and feasibility especially when high accuracy is desired. To overcome this limitation, we propose a data-driven corrector method that allows using large step sizes while compensating for the integration error for high accuracy. This corrector is represented in the form of a vector-valued function and is modeled by a neural network to regress the error in the phase space. Hence we name the corrector neural vector (NeurVec). We show that NeurVec can achieve the same accuracy as traditional solvers with much larger step sizes. We empirically demonstrate that NeurVec can accelerate a variety of numerical solvers significantly and overcome the stability restriction of these solvers. Our results on benchmark problems, ranging from high-dimensional problems to chaotic systems, suggest that NeurVec is capable of capturing the leading error term and maintaining the statistics of ensemble forecasts.
Perspective Phase Angle Model for Polarimetric 3D Reconstruction
Jul 21, 2022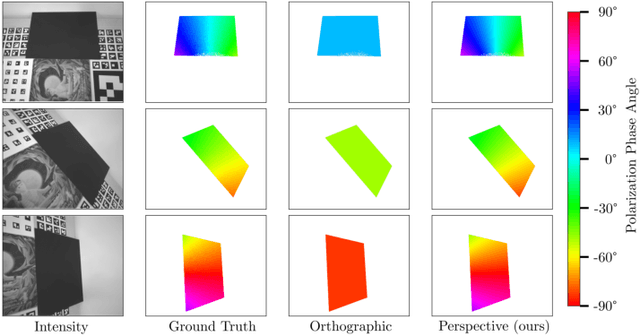

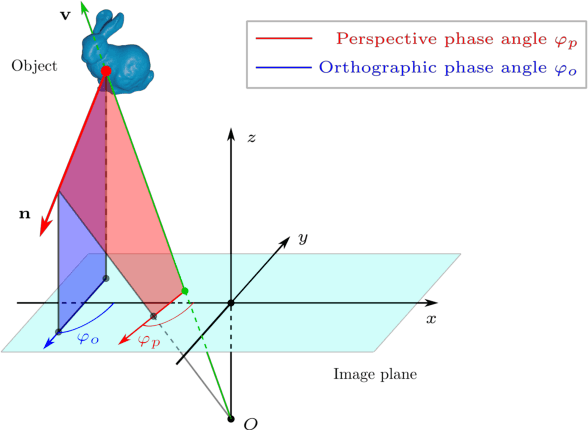
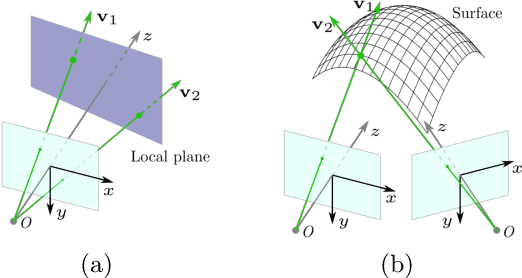
Current polarimetric 3D reconstruction methods, including those in the well-established shape from polarization literature, are all developed under the orthographic projection assumption. In the case of a large field of view, however, this assumption does not hold and may result in significant reconstruction errors in methods that make this assumption. To address this problem, we present the perspective phase angle (PPA) model that is applicable to perspective cameras. Compared with the orthographic model, the proposed PPA model accurately describes the relationship between polarization phase angle and surface normal under perspective projection. In addition, the PPA model makes it possible to estimate surface normals from only one single-view phase angle map and does not suffer from the so-called $\pi$-ambiguity problem. Experiments on real data show that the PPA model is more accurate for surface normal estimation with a perspective camera than the orthographic model.
Highlight Specular Reflection Separation based on Tensor Low-rank and Sparse Decomposition Using Polarimetric Cues
Jul 07, 2022
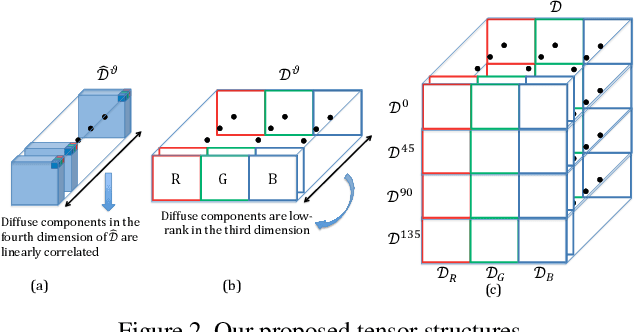
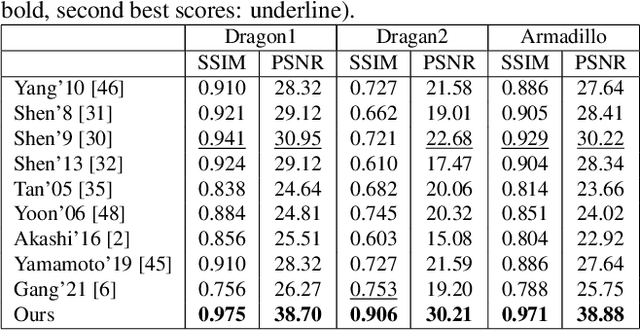
This paper is concerned with specular reflection removal based on tensor low-rank decomposition framework with the help of polarization information. Our method is motivated by the observation that the specular highlight of an image is sparsely distributed while the remaining diffuse reflection can be well approximated by a linear combination of several distinct colors using a low-rank and sparse decomposition framework. Unlike current solutions, our tensor low-rank decomposition keeps the spatial structure of specular and diffuse information which enables us to recover the diffuse image under strong specular reflection or in saturated regions. We further define and impose a new polarization regularization term as constraint on color channels. This regularization boosts the performance of the method to recover an accurate diffuse image by handling the color distortion, a common problem of chromaticity-based methods, especially in case of strong specular reflection. Through comprehensive experiments on both synthetic and real polarization images, we demonstrate that our method is able to significantly improve the accuracy of highlight specular removal, and outperform the competitive methods to recover the diffuse image, especially in regions of strong specular reflection or in saturated areas.