 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Forgetting in Deep Learning Beyond Continual Learning
Jul 23, 2023Forgetting refers to the loss or deterioration of previously acquired information or knowledge. While the existing surveys on forgetting have primarily focused on continual learning, forgetting is a prevalent phenomenon observed in various other research domains within deep learning. Forgetting manifests in research fields such as generative models due to generator shifts, and federated learning due to heterogeneous data distributions across clients. Addressing forgetting encompasses several challenges, including balancing the retention of old task knowledge with fast learning of new tasks, managing task interference with conflicting goals, and preventing privacy leakage, etc. Moreover, most existing surveys on continual learning implicitly assume that forgetting is always harmful. In contrast, our survey argues that forgetting is a double-edged sword and can be beneficial and desirable in certain cases, such as privacy-preserving scenarios. By exploring forgetting in a broader context, we aim to present a more nuanced understanding of this phenomenon and highlight its potential advantages. Through this comprehensive survey, we aspire to uncover potential solutions by drawing upon ideas and approaches from various fields that have dealt with forgetting. By examining forgetting beyond its conventional boundaries, in future work, we hope to encourage the development of novel strategies for mitigating, harnessing, or even embracing forgetting in real applications. A comprehensive list of papers about forgetting in various research fields is available at \url{https://github.com/EnnengYang/Awesome-Forgetting-in-Deep-Learning}.
AlpaGasus: Training A Better Alpaca with Fewer Data
Jul 17, 2023



Large language models~(LLMs) obtain instruction-following capability through instruction-finetuning (IFT) on supervised instruction/response data. However, widely used IFT datasets (e.g., Alpaca's 52k data) surprisingly contain many low-quality instances with incorrect or irrelevant responses, which are misleading and detrimental to IFT. In this paper, we propose a simple and effective data selection strategy that automatically identifies and removes low-quality data using a strong LLM (e.g., ChatGPT). To this end, we introduce AlpaGasus, which is finetuned on only 9k high-quality data filtered from the 52k Alpaca data. AlpaGasus significantly outperforms the original Alpaca as evaluated by GPT-4 on multiple test sets and its 13B variant matches $>90\%$ performance of its teacher LLM (i.e., Text-Davinci-003) on test tasks. It also provides 5.7x faster training, reducing the training time for a 7B variant from 80 minutes (for Alpaca) to 14 minutes \footnote{We apply IFT for the same number of epochs as Alpaca(7B) but on fewer data, using 4$\times$NVIDIA A100 (80GB) GPUs and following the original Alpaca setting and hyperparameters.}. Overall, AlpaGasus demonstrates a novel data-centric IFT paradigm that can be generally applied to instruction-tuning data, leading to faster training and better instruction-following models. Our project page is available at: \url{https://lichang-chen.github.io/AlpaGasus/}.
Cooperation or Competition: Avoiding Player Domination for Multi-Target Robustness via Adaptive Budgets
Jun 27, 2023



Despite incredible advances, deep learning has been shown to be susceptible to adversarial attacks. Numerous approaches have been proposed to train robust networks both empirically and certifiably. However, most of them defend against only a single type of attack, while recent work takes steps forward in defending against multiple attacks. In this paper, to understand multi-target robustness, we view this problem as a bargaining game in which different players (adversaries) negotiate to reach an agreement on a joint direction of parameter updating. We identify a phenomenon named player domination in the bargaining game, namely that the existing max-based approaches, such as MAX and MSD, do not converge. Based on our theoretical analysis, we design a novel framework that adjusts the budgets of different adversaries to avoid any player dominance. Experiments on standard benchmarks show that employing the proposed framework to the existing approaches significantly advances multi-target robustness.
Prediction of Post-Operative Renal and Pulmonary Complications Using Transformers
Jun 06, 2023Postoperative complications pose a significant challenge in the healthcare industry, resulting in elevated healthcare expenses and prolonged hospital stays, and in rare instances, patient mortality. To improve patient outcomes and reduce healthcare costs, healthcare providers rely on various perioperative risk scores to guide clinical decisions and prioritize care. In recent years, machine learning techniques have shown promise in predicting postoperative complications and fatality, with deep learning models achieving remarkable success in healthcare applications. However, research on the application of deep learning models to intra-operative anesthesia management data is limited. In this paper, we evaluate the performance of transformer-based models in predicting postoperative acute renal failure, postoperative pulmonary complications, and postoperative in-hospital mortality. We compare our method's performance with state-of-the-art tabular data prediction models, including gradient boosting trees and sequential attention models, on a clinical dataset. Our results demonstrate that transformer-based models can achieve superior performance in predicting postoperative complications and outperform traditional machine learning models. This work highlights the potential of deep learning techniques, specifically transformer-based models, in revolutionizing the healthcare industry's approach to postoperative care.
InstructZero: Efficient Instruction Optimization for Black-Box Large Language Models
Jun 05, 2023Large language models~(LLMs) are instruction followers, but it can be challenging to find the best instruction for different situations, especially for black-box LLMs on which backpropagation is forbidden. Instead of directly optimizing the discrete instruction, we optimize a low-dimensional soft prompt applied to an open-source LLM to generate the instruction for the black-box LLM. On each iteration of the proposed method, which we call InstructZero, a soft prompt is converted into an instruction using the open-source LLM, which is then submitted to the black-box LLM for zero-shot evaluation, and the performance is sent to Bayesian optimization to produce new soft prompts improving the zero-shot performance. We evaluate InstructZero on different combinations of open-source LLMs and APIs including Vicuna and ChatGPT. Our results show that InstructZero outperforms SOTA auto-instruction methods across a variety of downstream tasks. Our code and data are publicly available at https://github.com/Lichang-Chen/InstructZero.
Incomplete Multimodal Learning for Complex Brain Disorders Prediction
May 25, 2023



Recent advancements in the acquisition of various brain data sources have created new opportunities for integrating multimodal brain data to assist in early detection of complex brain disorders. However, current data integration approaches typically need a complete set of biomedical data modalities, which may not always be feasible, as some modalities are only available in large-scale research cohorts and are prohibitive to collect in routine clinical practice. Especially in studies of brain diseases, research cohorts may include both neuroimaging data and genetic data, but for practical clinical diagnosis, we often need to make disease predictions only based on neuroimages. As a result, it is desired to design machine learning models which can use all available data (different data could provide complementary information) during training but conduct inference using only the most common data modality. We propose a new incomplete multimodal data integration approach that employs transformers and generative adversarial networks to effectively exploit auxiliary modalities available during training in order to improve the performance of a unimodal model at inference. We apply our new method to predict cognitive degeneration and disease outcomes using the multimodal imaging genetic data from Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort. Experimental results demonstrate that our approach outperforms the related machine learning and deep learning methods by a significant margin.
Prompting Language-Informed Distribution for Compositional Zero-Shot Learning
May 23, 2023



The compositional zero-shot learning (CZSL) task aims to recognize unseen compositional visual concepts (i.e., sliced tomatoes), where the models are learned only from the seen compositions (i.e., sliced potatoes and red tomatoes). Thanks to the prompt tuning on large pre-trained visual language models such as CLIP, recent literature shows impressively better CZSL performance than traditional vision-based methods. However, the key aspects that impact the generalization to unseen compositions, including the diversity and informativeness of class context, and the entanglement between visual primitives (i.e., states and objects), are not properly addressed in existing CLIP-based CZSL literature. In this paper, we propose a model by prompting the language-informed distribution, aka., PLID, for the CZSL task. Specifically, the PLID leverages pre-trained large language models (LLM) to 1) formulate the language-informed class distribution, and 2) enhance the compositionality of the softly prompted class embedding. Moreover, a stochastic logit mixup strategy is proposed to dynamically fuse the decisions from the predictions in the compositional and the primitive logit space. Orthogonal to the existing literature of soft, hard, or distributional prompts, our method advocates prompting the LLM-supported class distribution that leads to a better compositional zero-shot generalization. Experimental results on MIT-States, UT-Zappos, and C-GQA datasets show the superior performance of the PLID to the prior arts. The code and models will be publicly released.
Backdoor Learning on Sequence to Sequence Models
May 03, 2023Backdoor learning has become an emerging research area towards building a trustworthy machine learning system. While a lot of works have studied the hidden danger of backdoor attacks in image or text classification, there is a limited understanding of the model's robustness on backdoor attacks when the output space is infinite and discrete. In this paper, we study a much more challenging problem of testing whether sequence-to-sequence (seq2seq) models are vulnerable to backdoor attacks. Specifically, we find by only injecting 0.2\% samples of the dataset, we can cause the seq2seq model to generate the designated keyword and even the whole sentence. Furthermore, we utilize Byte Pair Encoding (BPE) to create multiple new triggers, which brings new challenges to backdoor detection since these backdoors are not static. Extensive experiments on machine translation and text summarization have been conducted to show our proposed methods could achieve over 90\% attack success rate on multiple datasets and models.
PTP: Boosting Stability and Performance of Prompt Tuning with Perturbation-Based Regularizer
May 03, 2023Recent studies show that prompt tuning can better leverage the power of large language models than fine-tuning on downstream natural language understanding tasks. However, the existing prompt tuning methods have training instability issues, as the variance of scores under different random seeds is quite large. To address this critical problem, we first investigate and find that the loss landscape of vanilla prompt tuning is precipitous when it is visualized, where a slight change of input data can cause a big fluctuation in the loss landscape. This is an essential factor that leads to the instability of prompt tuning. Based on this observation, we introduce perturbation-based regularizers, which can smooth the loss landscape, into prompt tuning. We propose a new algorithm, called Prompt Tuning with Perturbation-based regularizer~(PTP), which can not only alleviate training instability dramatically but also boost the performance of prompt tuning. We design two kinds of perturbation-based regularizers, including random-noise-based and adversarial-based. In particular, our proposed perturbations are flexible on both text space and embedding space. Extensive experiments show the effectiveness of our proposed methods in stabilizing the training. Our new algorithms improve the state-of-the-art prompt tuning methods by 1.94\% and 2.34\% on SuperGLUE and FewGLUE benchmarks, respectively.
When do you need Chain-of-Thought Prompting for ChatGPT?
Apr 18, 2023
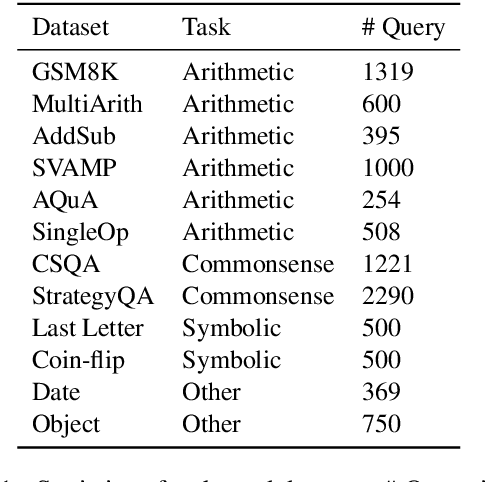
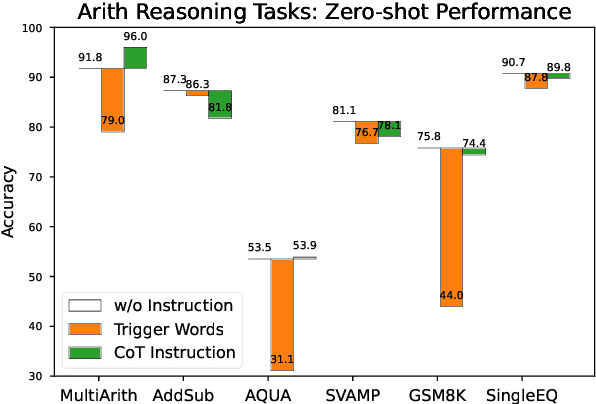
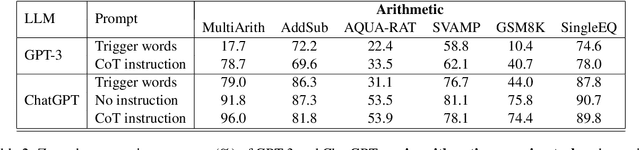
Chain-of-Thought (CoT) prompting can effectively elicit complex multi-step reasoning from Large Language Models~(LLMs). For example, by simply adding CoT instruction ``Let's think step-by-step'' to each input query of MultiArith dataset, GPT-3's accuracy can be improved from 17.7\% to 78.7\%. However, it is not clear whether CoT is still effective on more recent instruction finetuned (IFT) LLMs such as ChatGPT. Surprisingly, on ChatGPT, CoT is no longer effective for certain tasks such as arithmetic reasoning while still keeping effective on other reasoning tasks. Moreover, on the former tasks, ChatGPT usually achieves the best performance and can generate CoT even without being instructed to do so. Hence, it is plausible that ChatGPT has already been trained on these tasks with CoT and thus memorized the instruction so it implicitly follows such an instruction when applied to the same queries, even without CoT. Our analysis reflects a potential risk of overfitting/bias toward instructions introduced in IFT, which becomes more common in training LLMs. In addition, it indicates possible leakage of the pretraining recipe, e.g., one can verify whether a dataset and instruction were used in training ChatGPT. Our experiments report new baseline results of ChatGPT on a variety of reasoning tasks and shed novel insights into LLM's profiling, instruction memorization, and pretraining dataset leakage.