 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMnasFPN: Learning Latency-aware Pyramid Architecture for Object Detection on Mobile Devices
Dec 02, 2019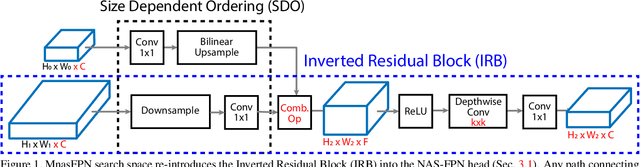

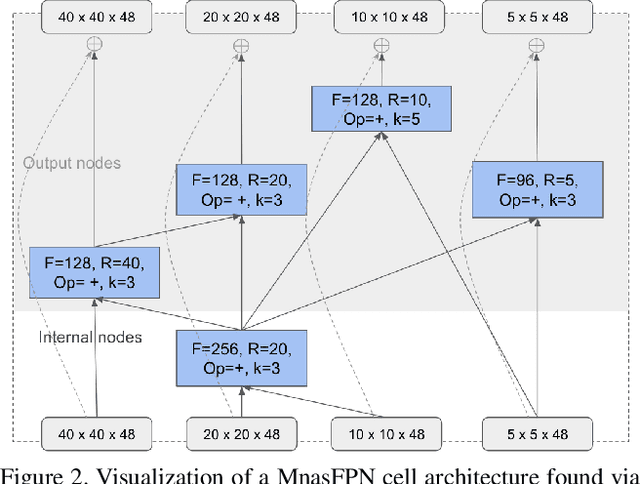
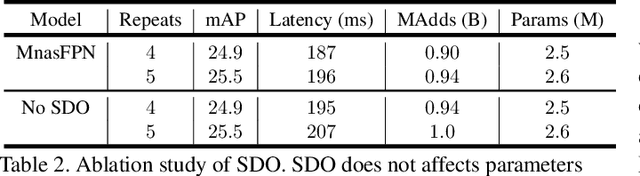
Despite the blooming success of architecture search for vision tasks in resource-constrained environments, the design of on-device object detection architectures have mostly been manual. The few automated search efforts are either centered around non-mobile-friendly search spaces or not guided by on-device latency. We propose Mnasfpn, a mobile-friendly search space for the detection head, and combine it with latency-aware architecture search to produce efficient object detection models. The learned Mnasfpn head, when paired with MobileNetV2 body, outperforms MobileNetV3+SSDLite by 1.8 mAP at similar latency on Pixel. It is also both 1.0 mAP more accurate and 10% faster than NAS-FPNLite. Ablation studies show that the majority of the performance gain comes from innovations in the search space. Further explorations reveal an interesting coupling between the search space design and the search algorithm, and that the complexity of Mnasfpn search space may be at a local optimum.
Neural Predictor for Neural Architecture Search
Dec 02, 2019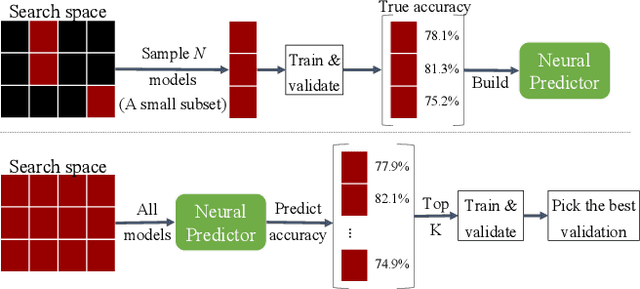
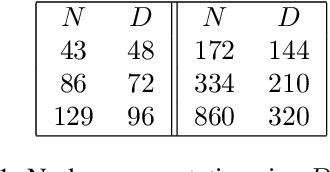

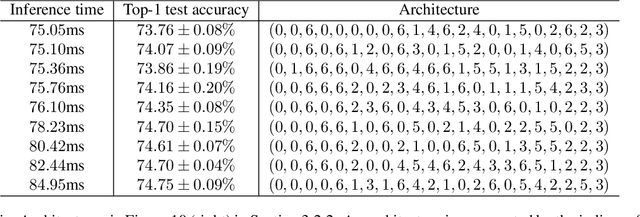
Neural Architecture Search methods are effective but often use complex algorithms to come up with the best architecture. We propose an approach with three basic steps that is conceptually much simpler. First we train N random architectures to generate N (architecture, validation accuracy) pairs and use them to train a regression model that predicts accuracy based on the architecture. Next, we use this regression model to predict the validation accuracies of a large number of random architectures. Finally, we train the top-K predicted architectures and deploy the model with the best validation result. While this approach seems simple, it is more than 20 times as sample efficient as Regularized Evolution on the NASBench-101 benchmark and can compete on ImageNet with more complex approaches based on weight sharing, such as ProxylessNAS.
GDP: Generalized Device Placement for Dataflow Graphs
Sep 28, 2019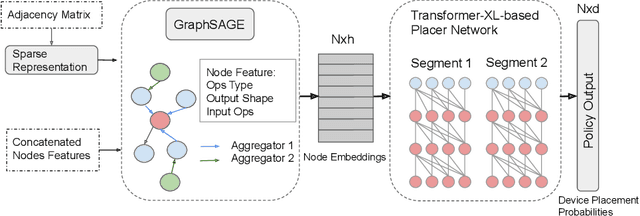
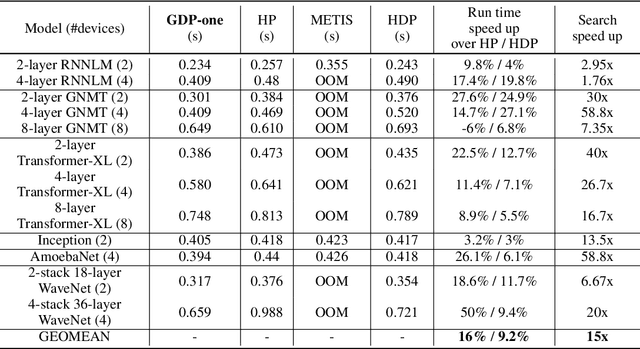
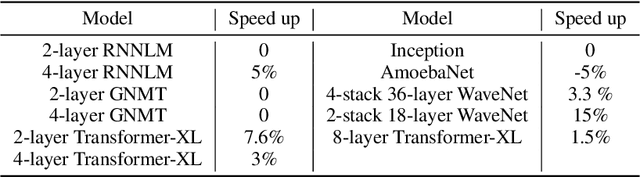
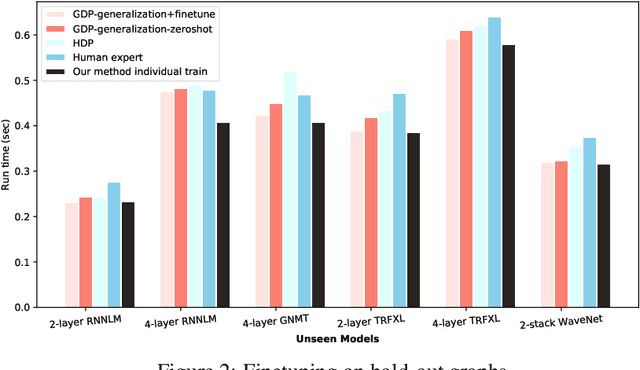
Runtime and scalability of large neural networks can be significantly affected by the placement of operations in their dataflow graphs on suitable devices. With increasingly complex neural network architectures and heterogeneous device characteristics, finding a reasonable placement is extremely challenging even for domain experts. Most existing automated device placement approaches are impractical due to the significant amount of compute required and their inability to generalize to new, previously held-out graphs. To address both limitations, we propose an efficient end-to-end method based on a scalable sequential attention mechanism over a graph neural network that is transferable to new graphs. On a diverse set of representative deep learning models, including Inception-v3, AmoebaNet, Transformer-XL, and WaveNet, our method on average achieves 16% improvement over human experts and 9.2% improvement over the prior art with 15 times faster convergence. To further reduce the computation cost, we pre-train the policy network on a set of dataflow graphs and use a superposition network to fine-tune it on each individual graph, achieving state-of-the-art performance on large hold-out graphs with over 50k nodes, such as an 8-layer GNMT.
DARTS: Differentiable Architecture Search
Jun 24, 2018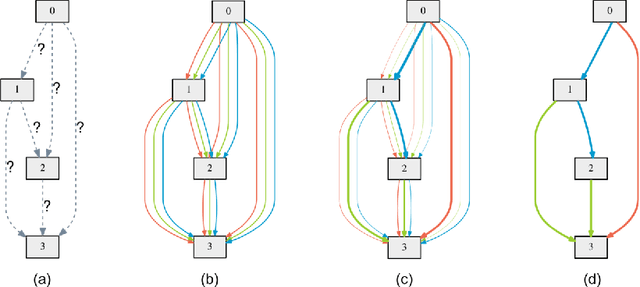
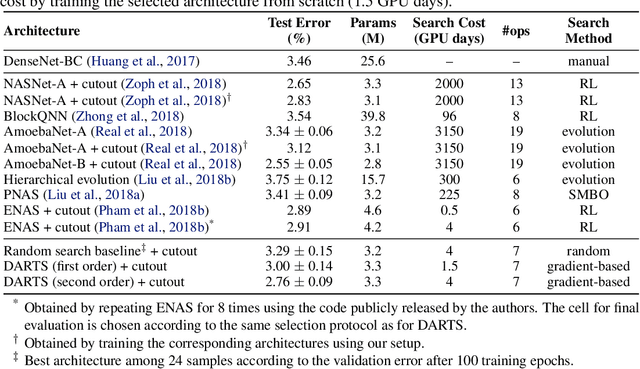
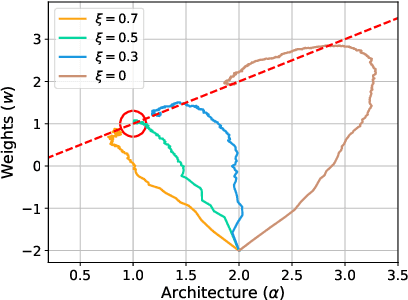
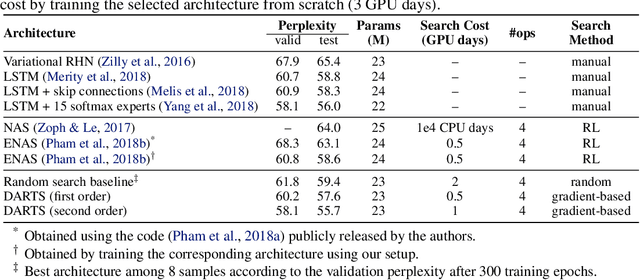
This paper addresses the scalability challenge of architecture search by formulating the task in a differentiable manner. Unlike conventional approaches of applying evolution or reinforcement learning over a discrete and non-differentiable search space, our method is based on the continuous relaxation of the architecture representation, allowing efficient search of the architecture using gradient descent. Extensive experiments on CIFAR-10, ImageNet, Penn Treebank and WikiText-2 show that our algorithm excels in discovering high-performance convolutional architectures for image classification and recurrent architectures for language modeling, while being orders of magnitude faster than state-of-the-art non-differentiable techniques.
Learning Depthwise Graph Convolution from Data Manifold
May 23, 2018
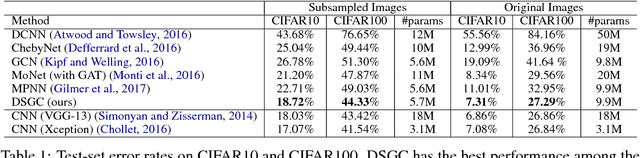
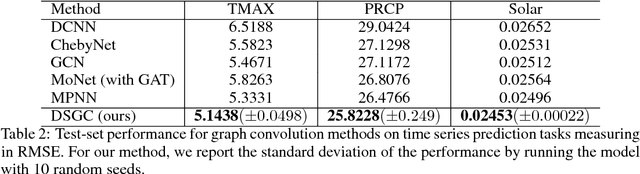
Convolution Neural Network (CNN) has gained tremendous success in computer vision tasks with its outstanding ability to capture the local latent features. Recently, there has been an increasing interest in extending convolution operations to the non-Euclidean geometry. Although various types of convolution operations have been proposed for graphs or manifolds, their connections with traditional convolution over grid-structured data are not well-understood. In this paper, we show that depthwise separable convolution can be successfully generalized for the unification of both graph-based and grid-based convolution methods. Based on this insight we propose a novel Depthwise Separable Graph Convolution (DSGC) approach which is compatible with the tradition convolution network and subsumes existing convolution methods as special cases. It is equipped with the combined strengths in model expressiveness, compatibility (relatively small number of parameters), modularity and computational efficiency in training. Extensive experiments show the outstanding performance of DSGC in comparison with strong baselines on multi-domain benchmark datasets.
Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks
Apr 18, 2018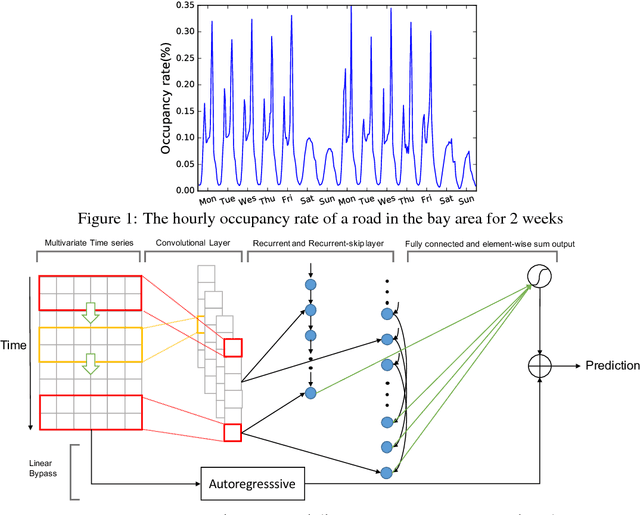
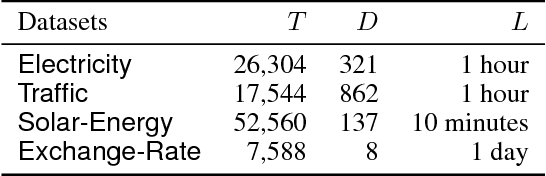
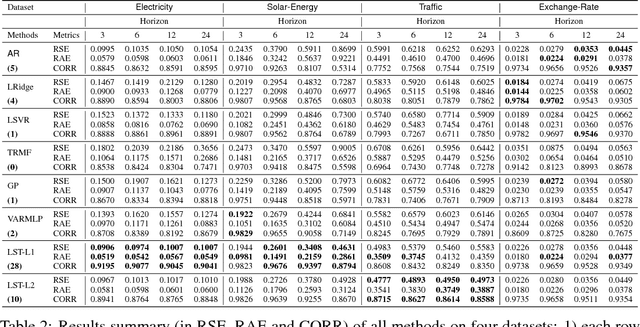
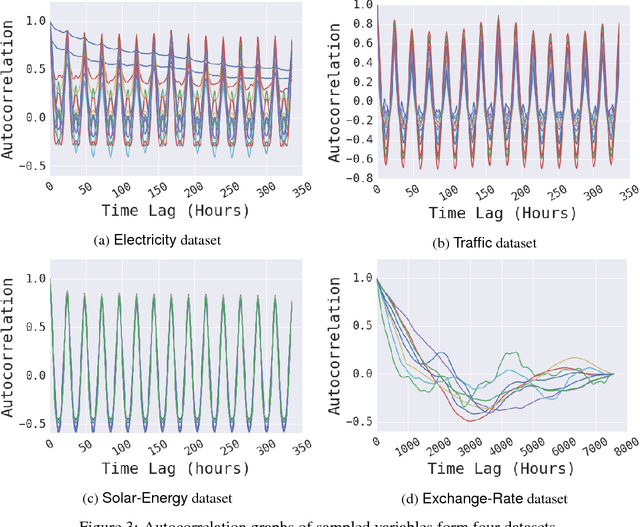
Multivariate time series forecasting is an important machine learning problem across many domains, including predictions of solar plant energy output, electricity consumption, and traffic jam situation. Temporal data arise in these real-world applications often involves a mixture of long-term and short-term patterns, for which traditional approaches such as Autoregressive models and Gaussian Process may fail. In this paper, we proposed a novel deep learning framework, namely Long- and Short-term Time-series network (LSTNet), to address this open challenge. LSTNet uses the Convolution Neural Network (CNN) and the Recurrent Neural Network (RNN) to extract short-term local dependency patterns among variables and to discover long-term patterns for time series trends. Furthermore, we leverage traditional autoregressive model to tackle the scale insensitive problem of the neural network model. In our evaluation on real-world data with complex mixtures of repetitive patterns, LSTNet achieved significant performance improvements over that of several state-of-the-art baseline methods. All the data and experiment codes are available online.
Hierarchical Representations for Efficient Architecture Search
Feb 22, 2018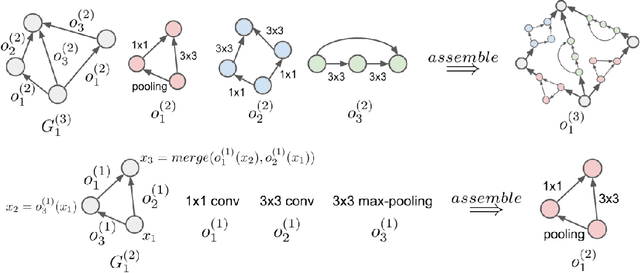
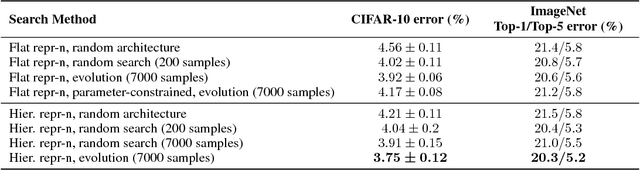
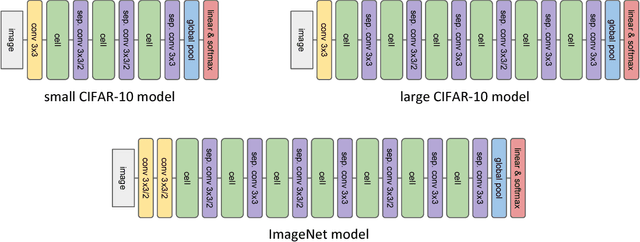

We explore efficient neural architecture search methods and show that a simple yet powerful evolutionary algorithm can discover new architectures with excellent performance. Our approach combines a novel hierarchical genetic representation scheme that imitates the modularized design pattern commonly adopted by human experts, and an expressive search space that supports complex topologies. Our algorithm efficiently discovers architectures that outperform a large number of manually designed models for image classification, obtaining top-1 error of 3.6% on CIFAR-10 and 20.3% when transferred to ImageNet, which is competitive with the best existing neural architecture search approaches. We also present results using random search, achieving 0.3% less top-1 accuracy on CIFAR-10 and 0.1% less on ImageNet whilst reducing the search time from 36 hours down to 1 hour.
Analogical Inference for Multi-Relational Embeddings
Jul 06, 2017

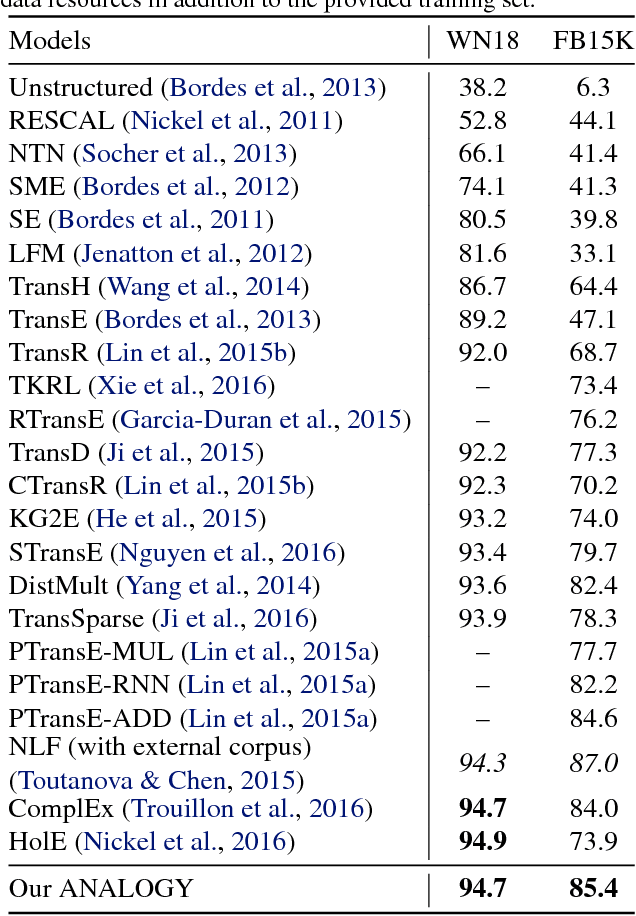
Large-scale multi-relational embedding refers to the task of learning the latent representations for entities and relations in large knowledge graphs. An effective and scalable solution for this problem is crucial for the true success of knowledge-based inference in a broad range of applications. This paper proposes a novel framework for optimizing the latent representations with respect to the \textit{analogical} properties of the embedded entities and relations. By formulating the learning objective in a differentiable fashion, our model enjoys both theoretical power and computational scalability, and significantly outperformed a large number of representative baseline methods on benchmark datasets. Furthermore, the model offers an elegant unification of several well-known methods in multi-relational embedding, which can be proven to be special instantiations of our framework.
Gated-Attention Readers for Text Comprehension
Apr 21, 2017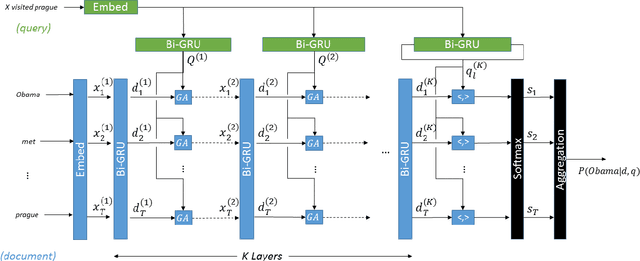
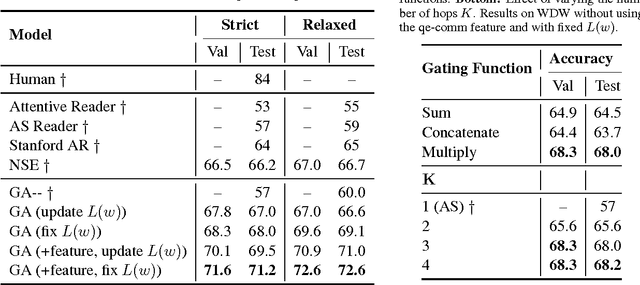
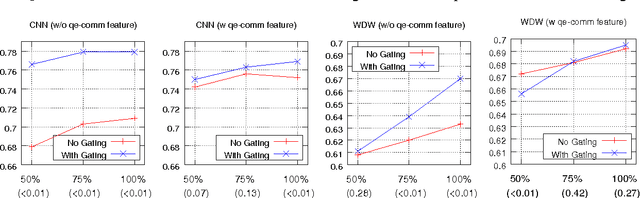
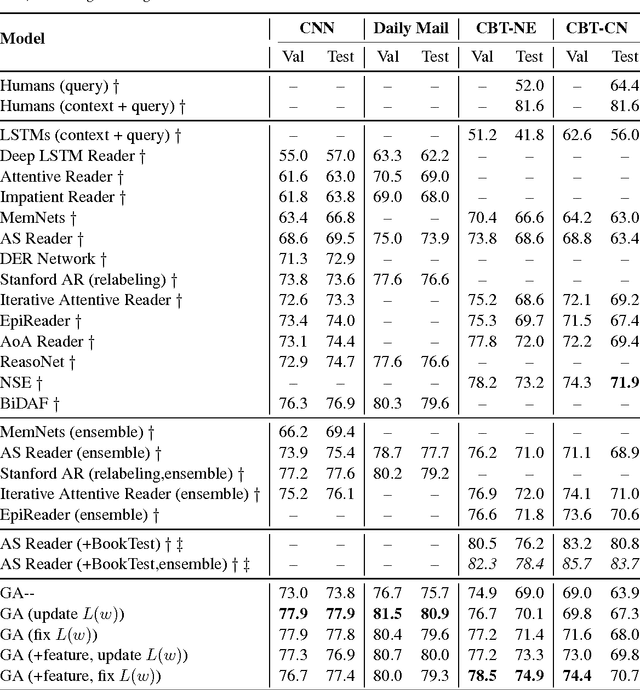
In this paper we study the problem of answering cloze-style questions over documents. Our model, the Gated-Attention (GA) Reader, integrates a multi-hop architecture with a novel attention mechanism, which is based on multiplicative interactions between the query embedding and the intermediate states of a recurrent neural network document reader. This enables the reader to build query-specific representations of tokens in the document for accurate answer selection. The GA Reader obtains state-of-the-art results on three benchmarks for this task--the CNN \& Daily Mail news stories and the Who Did What dataset. The effectiveness of multiplicative interaction is demonstrated by an ablation study, and by comparing to alternative compositional operators for implementing the gated-attention. The code is available at https://github.com/bdhingra/ga-reader.
A Comparative Study of Word Embeddings for Reading Comprehension
Mar 02, 2017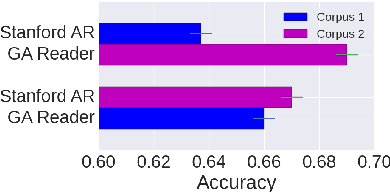

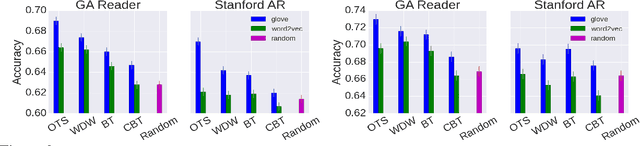
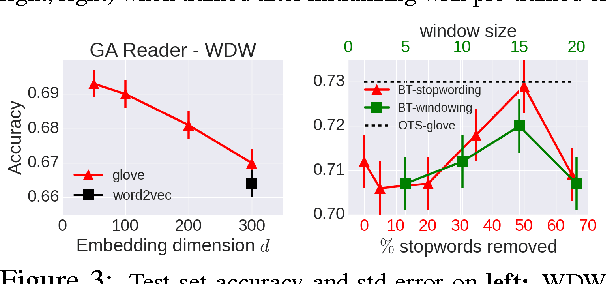
The focus of past machine learning research for Reading Comprehension tasks has been primarily on the design of novel deep learning architectures. Here we show that seemingly minor choices made on (1) the use of pre-trained word embeddings, and (2) the representation of out-of-vocabulary tokens at test time, can turn out to have a larger impact than architectural choices on the final performance. We systematically explore several options for these choices, and provide recommendations to researchers working in this area.