 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-task Adversarial Attack Against Face Authentication
Aug 15, 2024Deep-learning-based identity management systems, such as face authentication systems, are vulnerable to adversarial attacks. However, existing attacks are typically designed for single-task purposes, which means they are tailored to exploit vulnerabilities unique to the individual target rather than being adaptable for multiple users or systems. This limitation makes them unsuitable for certain attack scenarios, such as morphing, universal, transferable, and counter attacks. In this paper, we propose a multi-task adversarial attack algorithm called MTADV that are adaptable for multiple users or systems. By interpreting these scenarios as multi-task attacks, MTADV is applicable to both single- and multi-task attacks, and feasible in the white- and gray-box settings. Furthermore, MTADV is effective against various face datasets, including LFW, CelebA, and CelebA-HQ, and can work with different deep learning models, such as FaceNet, InsightFace, and CurricularFace. Importantly, MTADV retains its feasibility as a single-task attack targeting a single user/system. To the best of our knowledge, MTADV is the first adversarial attack method that can target all of the aforementioned scenarios in one algorithm.
Efficient Quantum Gradient and Higher-order Derivative Estimation via Generalized Hadamard Test
Aug 10, 2024In the context of Noisy Intermediate-Scale Quantum (NISQ) computing, parameterized quantum circuits (PQCs) represent a promising paradigm for tackling challenges in quantum sensing, optimal control, optimization, and machine learning on near-term quantum hardware. Gradient-based methods are crucial for understanding the behavior of PQCs and have demonstrated substantial advantages in the convergence rates of Variational Quantum Algorithms (VQAs) compared to gradient-free methods. However, existing gradient estimation methods, such as Finite Difference, Parameter Shift Rule, Hadamard Test, and Direct Hadamard Test, often yield suboptimal gradient circuits for certain PQCs. To address these limitations, we introduce the Flexible Hadamard Test, which, when applied to first-order gradient estimation methods, can invert the roles of ansatz generators and observables. This inversion facilitates the use of measurement optimization techniques to efficiently compute PQC gradients. Additionally, to overcome the exponential cost of evaluating higher-order partial derivatives, we propose the $k$-fold Hadamard Test, which computes the $k^{th}$-order partial derivative using a single circuit. Furthermore, we introduce Quantum Automatic Differentiation (QAD), a unified gradient method that adaptively selects the best gradient estimation technique for individual parameters within a PQC. This represents the first implementation, to our knowledge, that departs from the conventional practice of uniformly applying a single method to all parameters. Through rigorous numerical experiments, we demonstrate the effectiveness of our proposed first-order gradient methods, showing up to an $O(N)$ factor improvement in circuit execution count for real PQC applications. Our research contributes to the acceleration of VQA computations, offering practical utility in the NISQ era of quantum computing.
Hybrid Quantum-Classical Scheduling for Accelerating Neural Network Training with Newton's Gradient Descent
Apr 30, 2024Optimization techniques in deep learning are predominantly led by first-order gradient methodologies, such as SGD. However, neural network training can greatly benefit from the rapid convergence characteristics of second-order optimization. Newton's GD stands out in this category, by rescaling the gradient using the inverse Hessian. Nevertheless, one of its major bottlenecks is matrix inversion, which is notably time-consuming in $O(N^3)$ time with weak scalability. Matrix inversion can be translated into solving a series of linear equations. Given that quantum linear solver algorithms (QLSAs), leveraging the principles of quantum superposition and entanglement, can operate within a $\text{polylog}(N)$ time frame, they present a promising approach with exponential acceleration. Specifically, one of the most recent QLSAs demonstrates a complexity scaling of $O(d\cdot\kappa \log(N\cdot\kappa/\epsilon))$, depending on: {size~$N$, condition number~$\kappa$, error tolerance~$\epsilon$, quantum oracle sparsity~$d$} of the matrix. However, this also implies that their potential exponential advantage may be hindered by certain properties (i.e. $\kappa$ and $d$). We propose Q-Newton, a hybrid quantum-classical scheduler for accelerating neural network training with Newton's GD. Q-Newton utilizes a streamlined scheduling module that coordinates between quantum and classical linear solvers, by estimating & reducing $\kappa$ and constructing $d$ for the quantum solver. Our evaluation showcases the potential for Q-Newton to significantly reduce the total training time compared to commonly used optimizers like SGD. We hypothesize a future scenario where the gate time of quantum machines is reduced, possibly realized by attoseconds physics. Our evaluation establishes an ambitious and promising target for the evolution of quantum computing.
QuantumSEA: In-Time Sparse Exploration for Noise Adaptive Quantum Circuits
Jan 10, 2024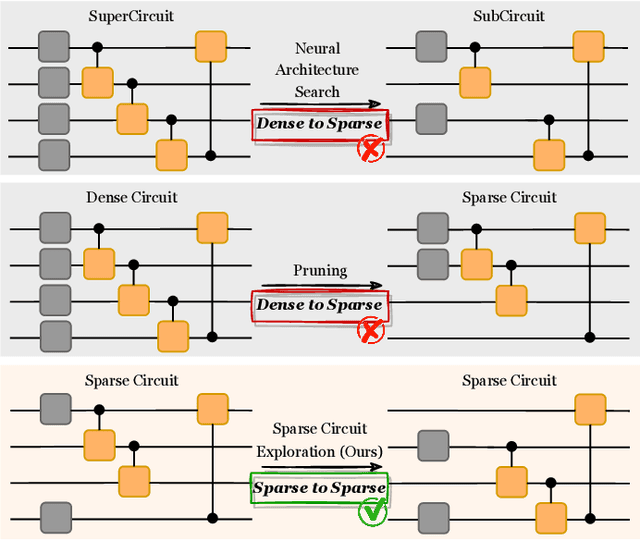
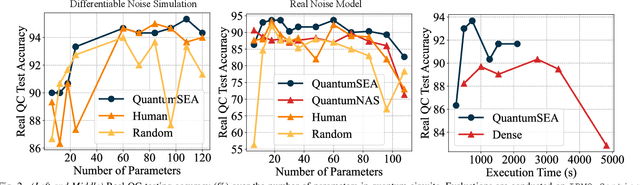
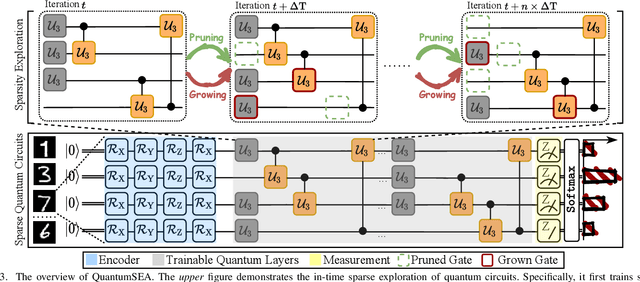
Parameterized Quantum Circuits (PQC) have obtained increasing popularity thanks to their great potential for near-term Noisy Intermediate-Scale Quantum (NISQ) computers. Achieving quantum advantages usually requires a large number of qubits and quantum circuits with enough capacity. However, limited coherence time and massive quantum noises severely constrain the size of quantum circuits that can be executed reliably on real machines. To address these two pain points, we propose QuantumSEA, an in-time sparse exploration for noise-adaptive quantum circuits, aiming to achieve two key objectives: (1) implicit circuits capacity during training - by dynamically exploring the circuit's sparse connectivity and sticking a fixed small number of quantum gates throughout the training which satisfies the coherence time and enjoy light noises, enabling feasible executions on real quantum devices; (2) noise robustness - by jointly optimizing the topology and parameters of quantum circuits under real device noise models. In each update step of sparsity, we leverage the moving average of historical gradients to grow necessary gates and utilize salience-based pruning to eliminate insignificant gates. Extensive experiments are conducted with 7 Quantum Machine Learning (QML) and Variational Quantum Eigensolver (VQE) benchmarks on 6 simulated or real quantum computers, where QuantumSEA consistently surpasses noise-aware search, human-designed, and randomly generated quantum circuit baselines by a clear performance margin. For example, even in the most challenging on-chip training regime, our method establishes state-of-the-art results with only half the number of quantum gates and ~2x time saving of circuit executions. Codes are available at https://github.com/VITA-Group/QuantumSEA.
DGR: Tackling Drifted and Correlated Noise in Quantum Error Correction via Decoding Graph Re-weighting
Dec 07, 2023



Quantum hardware suffers from high error rates and noise, which makes directly running applications on them ineffective. Quantum Error Correction (QEC) is a critical technique towards fault tolerance which encodes the quantum information distributively in multiple data qubits and uses syndrome qubits to check parity. Minimum-Weight-Perfect-Matching (MWPM) is a popular QEC decoder that takes the syndromes as input and finds the matchings between syndromes that infer the errors. However, there are two paramount challenges for MWPM decoders. First, as noise in real quantum systems can drift over time, there is a potential misalignment with the decoding graph's initial weights, leading to a severe performance degradation in the logical error rates. Second, while the MWPM decoder addresses independent errors, it falls short when encountering correlated errors typical on real hardware, such as those in the 2Q depolarizing channel. We propose DGR, an efficient decoding graph edge re-weighting strategy with no quantum overhead. It leverages the insight that the statistics of matchings across decoding iterations offer rich information about errors on real quantum hardware. By counting the occurrences of edges and edge pairs in decoded matchings, we can statistically estimate the up-to-date probabilities of each edge and the correlations between them. The reweighting process includes two vital steps: alignment re-weighting and correlation re-weighting. The former updates the MWPM weights based on statistics to align with actual noise, and the latter adjusts the weight considering edge correlations. Extensive evaluations on surface code and honeycomb code under various settings show that DGR reduces the logical error rate by 3.6x on average-case noise mismatch with exceeding 5000x improvement under worst-case mismatch.
Transformer-QEC: Quantum Error Correction Code Decoding with Transferable Transformers
Nov 27, 2023



Quantum computing has the potential to solve problems that are intractable for classical systems, yet the high error rates in contemporary quantum devices often exceed tolerable limits for useful algorithm execution. Quantum Error Correction (QEC) mitigates this by employing redundancy, distributing quantum information across multiple data qubits and utilizing syndrome qubits to monitor their states for errors. The syndromes are subsequently interpreted by a decoding algorithm to identify and correct errors in the data qubits. This task is complex due to the multiplicity of error sources affecting both data and syndrome qubits as well as syndrome extraction operations. Additionally, identical syndromes can emanate from different error sources, necessitating a decoding algorithm that evaluates syndromes collectively. Although machine learning (ML) decoders such as multi-layer perceptrons (MLPs) and convolutional neural networks (CNNs) have been proposed, they often focus on local syndrome regions and require retraining when adjusting for different code distances. We introduce a transformer-based QEC decoder which employs self-attention to achieve a global receptive field across all input syndromes. It incorporates a mixed loss training approach, combining both local physical error and global parity label losses. Moreover, the transformer architecture's inherent adaptability to variable-length inputs allows for efficient transfer learning, enabling the decoder to adapt to varying code distances without retraining. Evaluation on six code distances and ten different error configurations demonstrates that our model consistently outperforms non-ML decoders, such as Union Find (UF) and Minimum Weight Perfect Matching (MWPM), and other ML decoders, thereby achieving best logical error rates. Moreover, the transfer learning can save over 10x of training cost.
RobustState: Boosting Fidelity of Quantum State Preparation via Noise-Aware Variational Training
Nov 27, 2023



Quantum state preparation, a crucial subroutine in quantum computing, involves generating a target quantum state from initialized qubits. Arbitrary state preparation algorithms can be broadly categorized into arithmetic decomposition (AD) and variational quantum state preparation (VQSP). AD employs a predefined procedure to decompose the target state into a series of gates, whereas VQSP iteratively tunes ansatz parameters to approximate target state. VQSP is particularly apt for Noisy-Intermediate Scale Quantum (NISQ) machines due to its shorter circuits. However, achieving noise-robust parameter optimization still remains challenging. We present RobustState, a novel VQSP training methodology that combines high robustness with high training efficiency. The core idea involves utilizing measurement outcomes from real machines to perform back-propagation through classical simulators, thus incorporating real quantum noise into gradient calculations. RobustState serves as a versatile, plug-and-play technique applicable for training parameters from scratch or fine-tuning existing parameters to enhance fidelity on target machines. It is adaptable to various ansatzes at both gate and pulse levels and can even benefit other variational algorithms, such as variational unitary synthesis. Comprehensive evaluation of RobustState on state preparation tasks for 4 distinct quantum algorithms using 10 real quantum machines demonstrates a coherent error reduction of up to 7.1 $\times$ and state fidelity improvement of up to 96\% and 81\% for 4-Q and 5-Q states, respectively. On average, RobustState improves fidelity by 50\% and 72\% for 4-Q and 5-Q states compared to baseline approaches.
Benchmarking variational quantum circuits with permutation symmetry
Nov 23, 2022



We propose SnCQA, a set of hardware-efficient variational circuits of equivariant quantum convolutional circuits respective to permutation symmetries and spatial lattice symmetries with the number of qubits $n$. By exploiting permutation symmetries of the system, such as lattice Hamiltonians common to many quantum many-body and quantum chemistry problems, Our quantum neural networks are suitable for solving machine learning problems where permutation symmetries are present, which could lead to significant savings of computational costs. Aside from its theoretical novelty, we find our simulations perform well in practical instances of learning ground states in quantum computational chemistry, where we could achieve comparable performances to traditional methods with few tens of parameters. Compared to other traditional variational quantum circuits, such as the pure hardware-efficient ansatz (pHEA), we show that SnCQA is more scalable, accurate, and noise resilient (with $20\times$ better performance on $3 \times 4$ square lattice and $200\% - 1000\%$ resource savings in various lattice sizes and key criterions such as the number of layers, parameters, and times to converge in our cases), suggesting a potentially favorable experiment on near-time quantum devices.
QuEst: Graph Transformer for Quantum Circuit Reliability Estimation
Oct 30, 2022Among different quantum algorithms, PQC for QML show promises on near-term devices. To facilitate the QML and PQC research, a recent python library called TorchQuantum has been released. It can construct, simulate, and train PQC for machine learning tasks with high speed and convenient debugging supports. Besides quantum for ML, we want to raise the community's attention on the reversed direction: ML for quantum. Specifically, the TorchQuantum library also supports using data-driven ML models to solve problems in quantum system research, such as predicting the impact of quantum noise on circuit fidelity and improving the quantum circuit compilation efficiency. This paper presents a case study of the ML for quantum part. Since estimating the noise impact on circuit reliability is an essential step toward understanding and mitigating noise, we propose to leverage classical ML to predict noise impact on circuit fidelity. Inspired by the natural graph representation of quantum circuits, we propose to leverage a graph transformer model to predict the noisy circuit fidelity. We firstly collect a large dataset with a variety of quantum circuits and obtain their fidelity on noisy simulators and real machines. Then we embed each circuit into a graph with gate and noise properties as node features, and adopt a graph transformer to predict the fidelity. Evaluated on 5 thousand random and algorithm circuits, the graph transformer predictor can provide accurate fidelity estimation with RMSE error 0.04 and outperform a simple neural network-based model by 0.02 on average. It can achieve 0.99 and 0.95 R$^2$ scores for random and algorithm circuits, respectively. Compared with circuit simulators, the predictor has over 200X speedup for estimating the fidelity.
PAN: Pulse Ansatz on NISQ Machines
Aug 02, 2022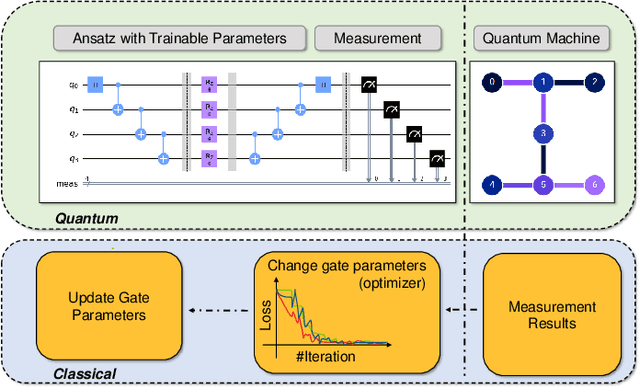
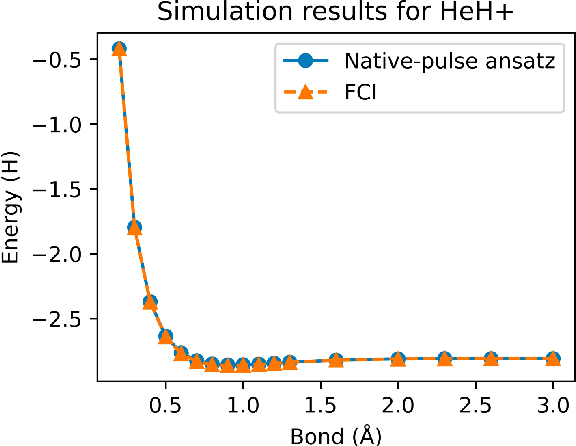
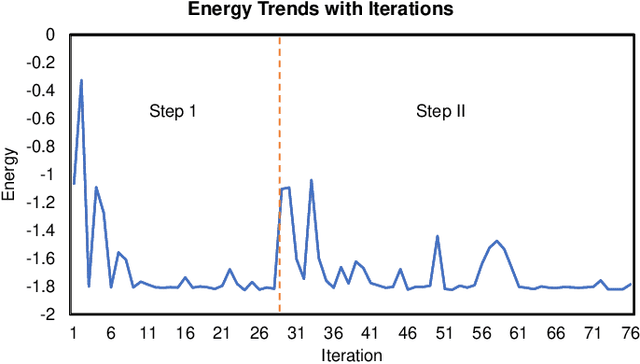

Variational quantum algorithms (VQAs) have demonstrated great potentials in the NISQ era. In the workflow of VQA, the parameters of ansatz are iteratively updated to approximate the desired quantum states. We have seen various efforts to draft better ansatz with less gates. In quantum computers, the gate ansatz will eventually be transformed into control signals such as microwave pulses on transmons. And the control pulses need elaborate calibration to minimize the errors such as over-rotation and under-rotation. In the case of VQAs, this procedure will introduce redundancy, but the variational properties of VQAs can naturally handle problems of over-rotation and under-rotation by updating the amplitude and frequency parameters. Therefore, we propose PAN, a native-pulse ansatz generator framework for VQAs. We generate native-pulse ansatz with trainable parameters for amplitudes and frequencies. In our proposed PAN, we are tuning parametric pulses, which are natively supported on NISQ computers. Considering that parameter-shift rules do not hold for native-pulse ansatz, we need to deploy non-gradient optimizers. To constrain the number of parameters sent to the optimizer, we adopt a progressive way to generate our native-pulse ansatz. Experiments are conducted on both simulators and quantum devices to validate our methods. When adopted on NISQ machines, PAN obtained improved the performance with decreased latency by an average of 86%. PAN is able to achieve 99.336% and 96.482% accuracy for VQE tasks on H2 and HeH+ respectively, even with considerable noises in NISQ machines.