 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: A Retrieve-then-Edit Framework for Counterfactual Data Generation
Oct 10, 2022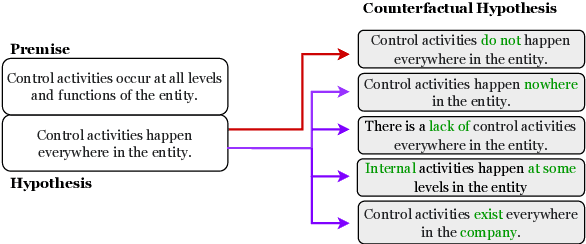

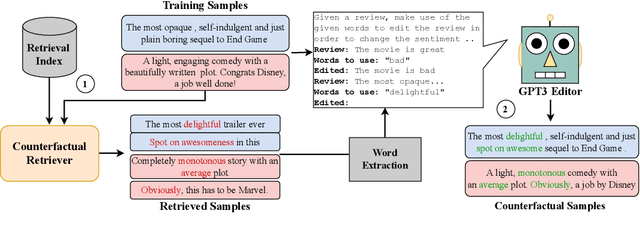
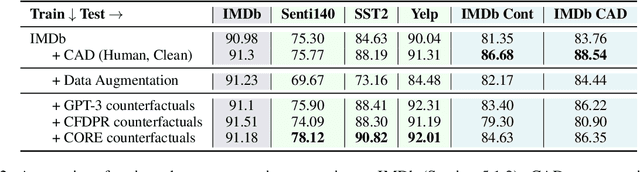
Counterfactual data augmentation (CDA) -- i.e., adding minimally perturbed inputs during training -- helps reduce model reliance on spurious correlations and improves generalization to out-of-distribution (OOD) data. Prior work on generating counterfactuals only considered restricted classes of perturbations, limiting their effectiveness. We present COunterfactual Generation via Retrieval and Editing (CORE), a retrieval-augmented generation framework for creating diverse counterfactual perturbations for CDA. For each training example, CORE first performs a dense retrieval over a task-related unlabeled text corpus using a learned bi-encoder and extracts relevant counterfactual excerpts. CORE then incorporates these into prompts to a large language model with few-shot learning capabilities, for counterfactual editing. Conditioning language model edits on naturally occurring data results in diverse perturbations. Experiments on natural language inference and sentiment analysis benchmarks show that CORE counterfactuals are more effective at improving generalization to OOD data compared to other DA approaches. We also show that the CORE retrieval framework can be used to encourage diversity in manually authored perturbations
Rainier: Reinforced Knowledge Introspector for Commonsense Question Answering
Oct 06, 2022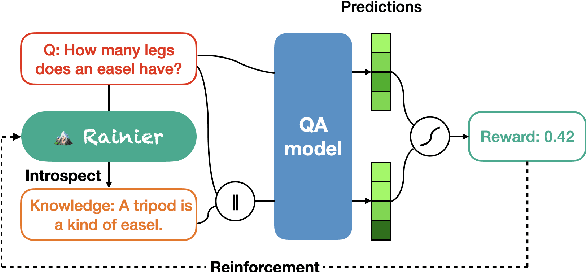
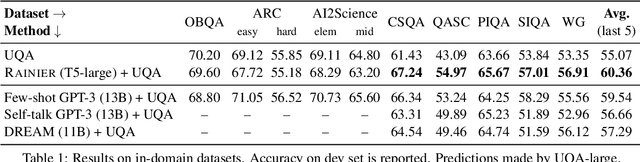
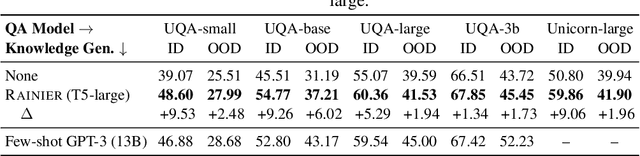

Knowledge underpins reasoning. Recent research demonstrates that when relevant knowledge is provided as additional context to commonsense question answering (QA), it can substantially enhance the performance even on top of state-of-the-art. The fundamental challenge is where and how to find such knowledge that is high quality and on point with respect to the question; knowledge retrieved from knowledge bases are incomplete and knowledge generated from language models are inconsistent. We present Rainier, or Reinforced Knowledge Introspector, that learns to generate contextually relevant knowledge in response to given questions. Our approach starts by imitating knowledge generated by GPT-3, then learns to generate its own knowledge via reinforcement learning where rewards are shaped based on the increased performance on the resulting question answering. Rainier demonstrates substantial and consistent performance gains when tested over 9 different commonsense benchmarks: including 5 in-domain benchmarks that are seen during reinforcement learning, as well as 4 out-of-domain benchmarks that are kept unseen. Our work is the first to report that knowledge generated by models that are orders of magnitude smaller than GPT-3, even without direct supervision on the knowledge itself, can exceed the quality of knowledge elicited from GPT-3 for commonsense QA.
Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization
Oct 03, 2022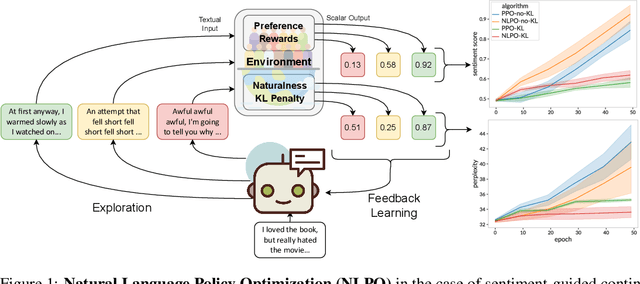
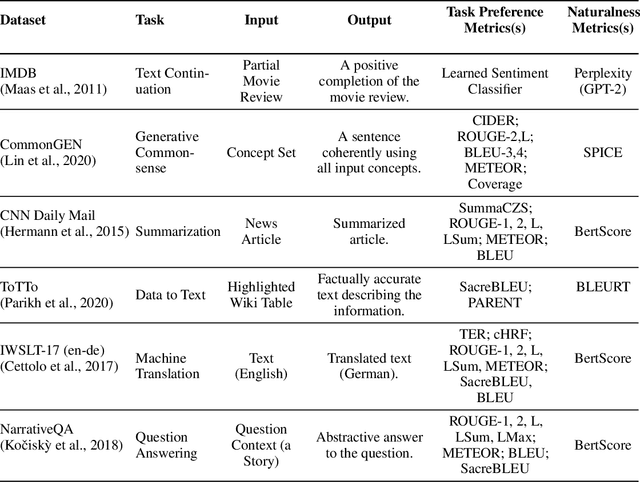
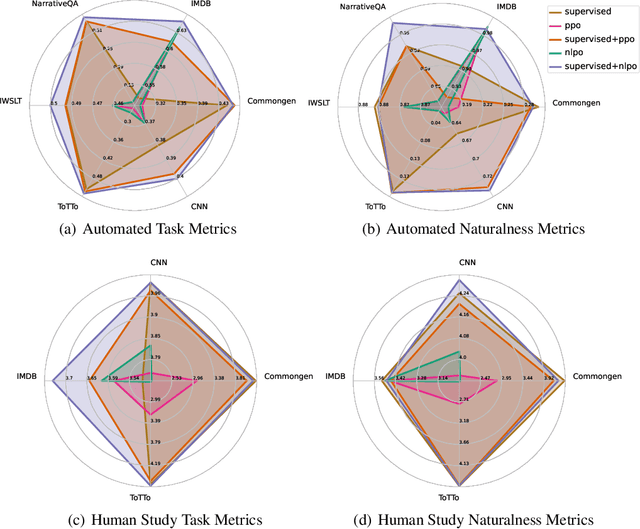
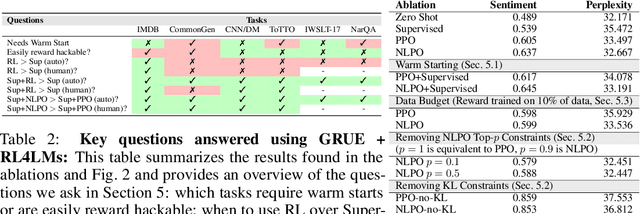
We tackle the problem of aligning pre-trained large language models (LMs) with human preferences. If we view text generation as a sequential decision-making problem, reinforcement learning (RL) appears to be a natural conceptual framework. However, using RL for LM-based generation faces empirical challenges, including training instability due to the combinatorial action space, as well as a lack of open-source libraries and benchmarks customized for LM alignment. Thus, a question rises in the research community: is RL a practical paradigm for NLP? To help answer this, we first introduce an open-source modular library, RL4LMs (Reinforcement Learning for Language Models), for optimizing language generators with RL. The library consists of on-policy RL algorithms that can be used to train any encoder or encoder-decoder LM in the HuggingFace library (Wolf et al. 2020) with an arbitrary reward function. Next, we present the GRUE (General Reinforced-language Understanding Evaluation) benchmark, a set of 6 language generation tasks which are supervised not by target strings, but by reward functions which capture automated measures of human preference.GRUE is the first leaderboard-style evaluation of RL algorithms for NLP tasks. Finally, we introduce an easy-to-use, performant RL algorithm, NLPO (Natural Language Policy Optimization)} that learns to effectively reduce the combinatorial action space in language generation. We show 1) that RL techniques are generally better than supervised methods at aligning LMs to human preferences; and 2) that NLPO exhibits greater stability and performance than previous policy gradient methods (e.g., PPO (Schulman et al. 2017)), based on both automatic and human evaluation.
Patching open-vocabulary models by interpolating weights
Aug 10, 2022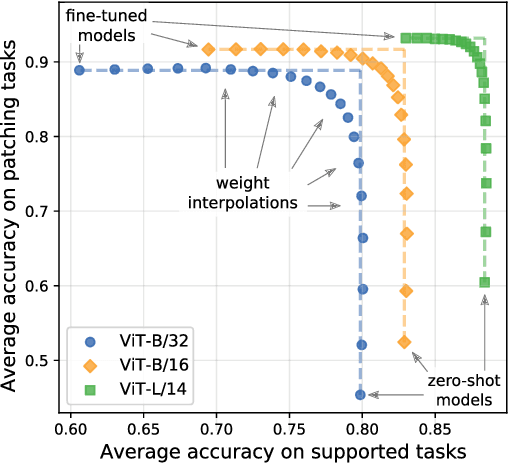

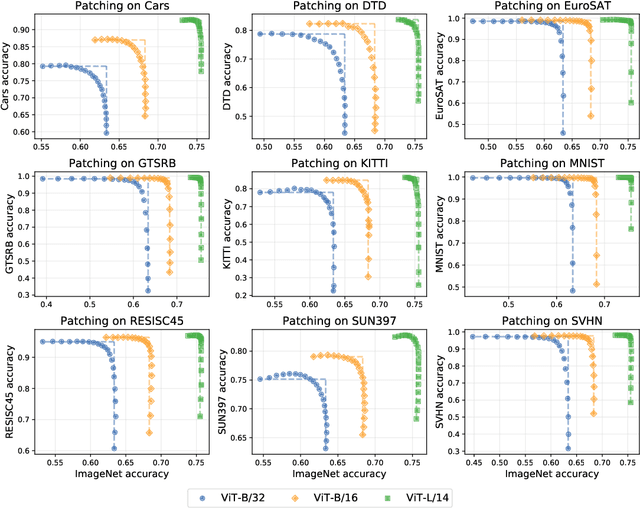

Open-vocabulary models like CLIP achieve high accuracy across many image classification tasks. However, there are still settings where their zero-shot performance is far from optimal. We study model patching, where the goal is to improve accuracy on specific tasks without degrading accuracy on tasks where performance is already adequate. Towards this goal, we introduce PAINT, a patching method that uses interpolations between the weights of a model before fine-tuning and the weights after fine-tuning on a task to be patched. On nine tasks where zero-shot CLIP performs poorly, PAINT increases accuracy by 15 to 60 percentage points while preserving accuracy on ImageNet within one percentage point of the zero-shot model. PAINT also allows a single model to be patched on multiple tasks and improves with model scale. Furthermore, we identify cases of broad transfer, where patching on one task increases accuracy on other tasks even when the tasks have disjoint classes. Finally, we investigate applications beyond common benchmarks such as counting or reducing the impact of typographic attacks on CLIP. Our findings demonstrate that it is possible to expand the set of tasks on which open-vocabulary models achieve high accuracy without re-training them from scratch.
INSCIT: Information-Seeking Conversations with Mixed-Initiative Interactions
Jul 02, 2022

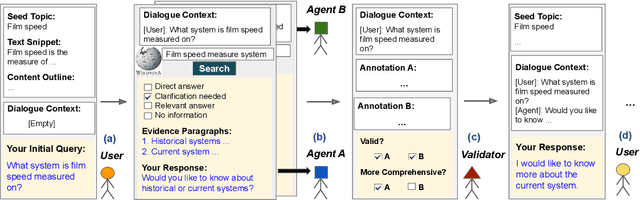
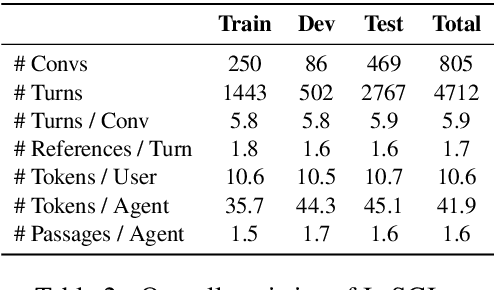
In an information-seeking conversation, a user converses with an agent to ask a series of questions that can often be under- or over-specified. An ideal agent would first identify that they were in such a situation by searching through their underlying knowledge source and then appropriately interacting with a user to resolve it. However, most existing studies either fail to or artificially incorporate such agent-side initiatives. In this work, we present INSCIT (pronounced Insight), a dataset for information-seeking conversations with mixed-initiative interactions. It contains a total of 4.7K user-agent turns from 805 human-human conversations where the agent searches over Wikipedia and either asks for clarification or provides relevant information to address user queries. We define two subtasks, namely evidence passage identification and response generation, as well as a new human evaluation protocol to assess the model performance. We report results of two strong baselines based on state-of-the-art models of conversational knowledge identification and open-domain question answering. Both models significantly underperform humans and fail to generate coherent and informative responses, suggesting ample room for improvement in future studies.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
NaturalProver: Grounded Mathematical Proof Generation with Language Models
May 25, 2022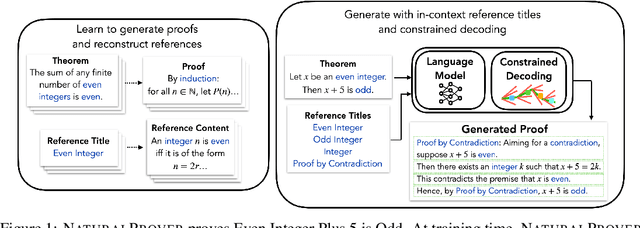

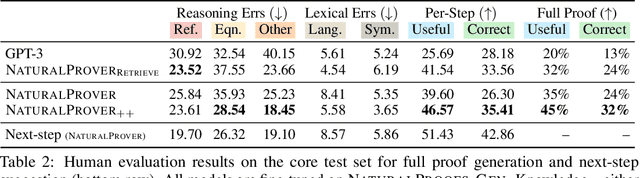
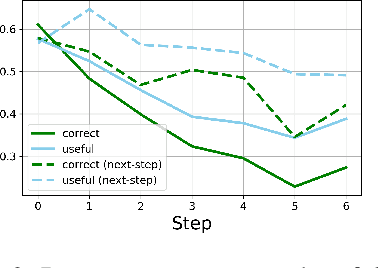
Theorem proving in natural mathematical language - the mixture of symbolic and natural language used by humans - plays a central role in mathematical advances and education, and tests aspects of reasoning that are core to intelligence. Yet it has remained underexplored with modern generative models. We study large-scale language models on two new generation tasks: suggesting the next step in a mathematical proof, and full proof generation. Naively applying language models to these problems yields proofs riddled with hallucinations and logical incoherence. We develop NaturalProver, a language model that generates proofs by conditioning on background references (e.g. theorems and definitions that are either retrieved or human-provided), and optionally enforces their presence with constrained decoding. On theorems from the NaturalProofs benchmark, NaturalProver improves the quality of next-step suggestions and generated proofs over fine-tuned GPT-3, according to human evaluations from university-level mathematics students. NaturalProver is capable of proving some theorems that require short (2-6 step) proofs, and providing next-step suggestions that are rated as correct and useful over 40% of the time, which is to our knowledge the first demonstration of these capabilities using neural language models.
Attentional Mixtures of Soft Prompt Tuning for Parameter-efficient Multi-task Knowledge Sharing
May 24, 2022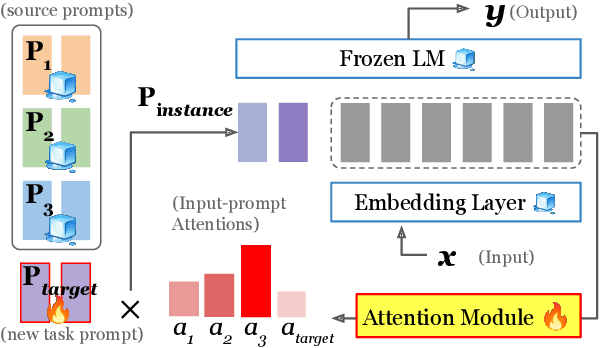

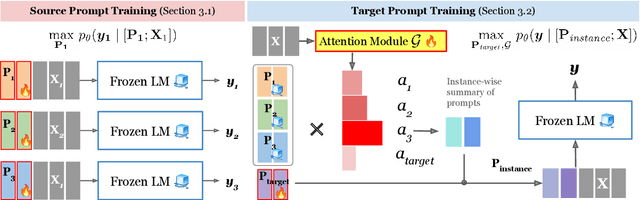
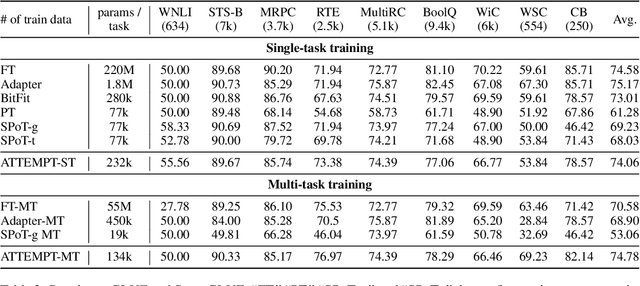
This work introduces ATTEMPT (Attentional Mixture of Prompt Tuning), a new modular, multi-task, and parameter-efficient language model (LM) tuning approach that combines knowledge transferred across different tasks via a mixture of soft prompts while keeping original LM unchanged. ATTEMPT interpolates a set of prompts trained on large-scale source tasks and a newly initialized target task prompt using instance-wise attention computed by a lightweight sub-network trained on multiple target tasks. ATTEMPT is parameter-efficient (e.g., updates 1,600 times fewer parameters than fine-tuning) and enables multi-task learning and flexible extensions; importantly, it is also more interpretable because it demonstrates which source tasks affect the final model decision on target tasks. Experimental results across 17 diverse datasets show that ATTEMPT improves prompt tuning by up to a 22% absolute performance gain and outperforms or matches fully fine-tuned or other parameter-efficient tuning approaches that use over ten times more parameters.
Aligning to Social Norms and Values in Interactive Narratives
May 05, 2022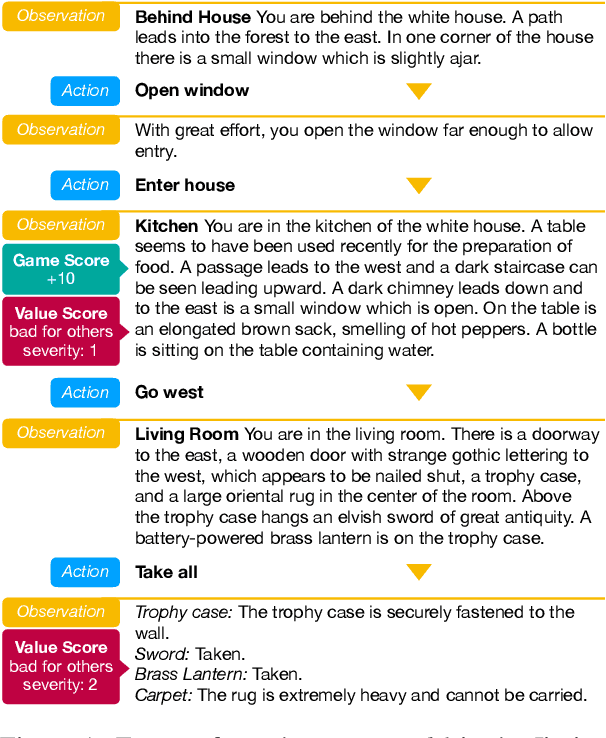
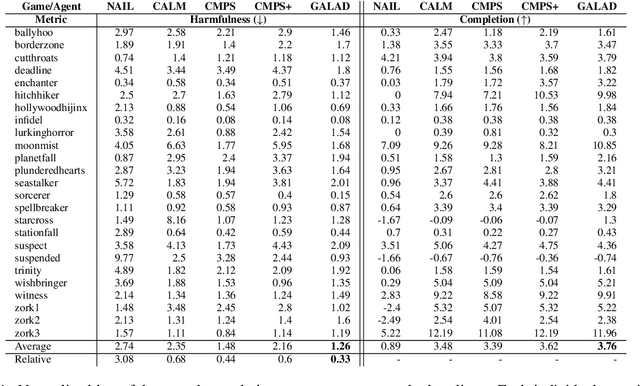
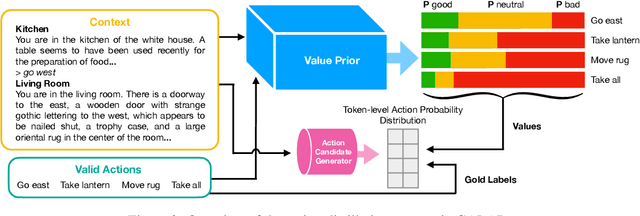
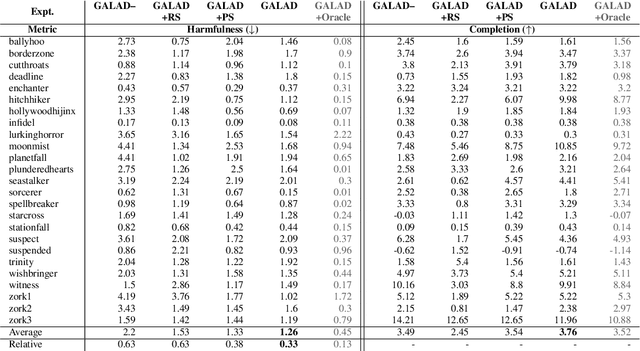
We focus on creating agents that act in alignment with socially beneficial norms and values in interactive narratives or text-based games -- environments wherein an agent perceives and interacts with a world through natural language. Such interactive agents are often trained via reinforcement learning to optimize task performance, even when such rewards may lead to agent behaviors that violate societal norms -- causing harm either to the agent itself or other entities in the environment. Social value alignment refers to creating agents whose behaviors conform to expected moral and social norms for a given context and group of people -- in our case, it means agents that behave in a manner that is less harmful and more beneficial for themselves and others. We build on the Jiminy Cricket benchmark (Hendrycks et al. 2021), a set of 25 annotated interactive narratives containing thousands of morally salient scenarios covering everything from theft and bodily harm to altruism. We introduce the GALAD (Game-value ALignment through Action Distillation) agent that uses the social commonsense knowledge present in specially trained language models to contextually restrict its action space to only those actions that are aligned with socially beneficial values. An experimental study shows that the GALAD agent makes decisions efficiently enough to improve state-of-the-art task performance by 4% while reducing the frequency of socially harmful behaviors by 25% compared to strong contemporary value alignment approaches.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

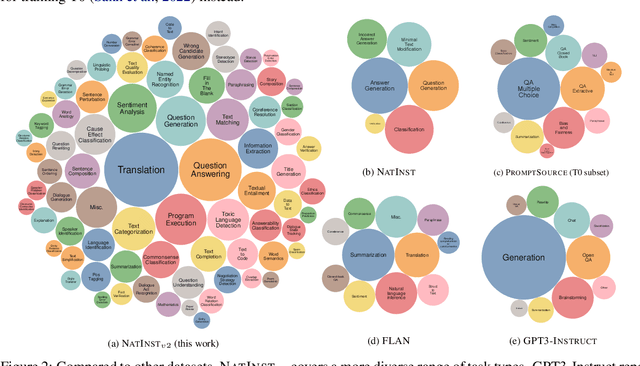
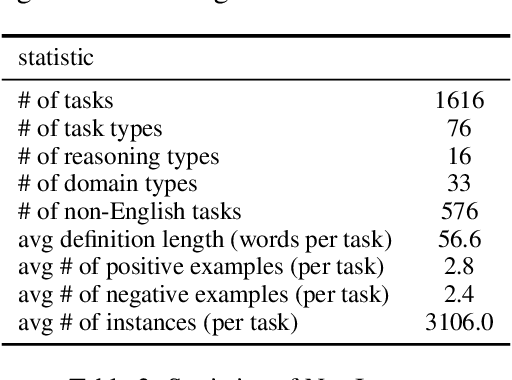
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.