 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedICaT: A Dataset of Medical Images, Captions, and Textual References
Paper and Code
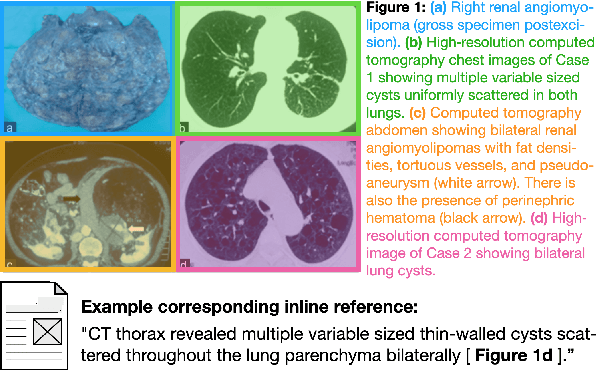

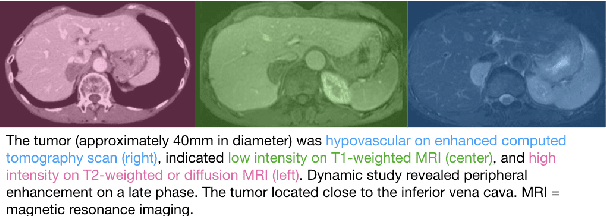
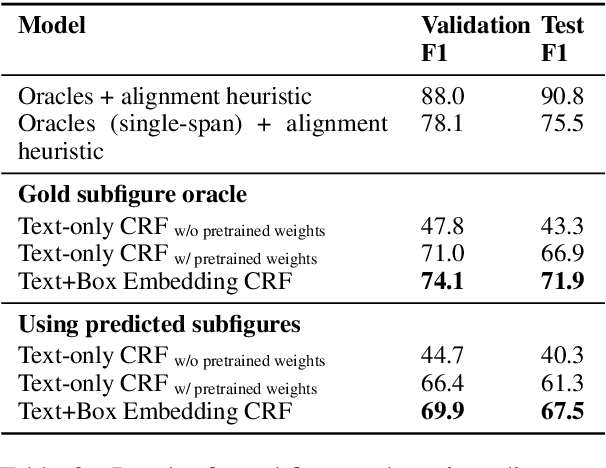
Understanding the relationship between figures and text is key to scientific document understanding. Medical figures in particular are quite complex, often consisting of several subfigures (75% of figures in our dataset), with detailed text describing their content. Previous work studying figures in scientific papers focused on classifying figure content rather than understanding how images relate to the text. To address challenges in figure retrieval and figure-to-text alignment, we introduce MedICaT, a dataset of medical images in context. MedICaT consists of 217K images from 131K open access biomedical papers, and includes captions, inline references for 74% of figures, and manually annotated subfigures and subcaptions for a subset of figures. Using MedICaT, we introduce the task of subfigure to subcaption alignment in compound figures and demonstrate the utility of inline references in image-text matching. Our data and code can be accessed at https://github.com/allenai/medicat.