 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Twitter Data to Understand Public Perceptions of Approved versus Off-label Use for COVID-19-related Medications
Jun 29, 2022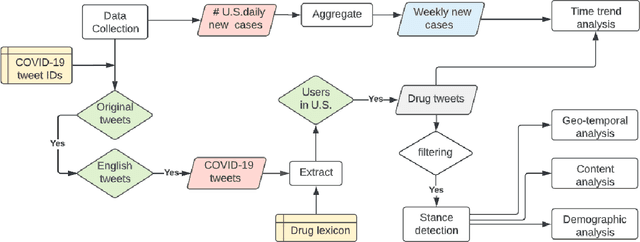

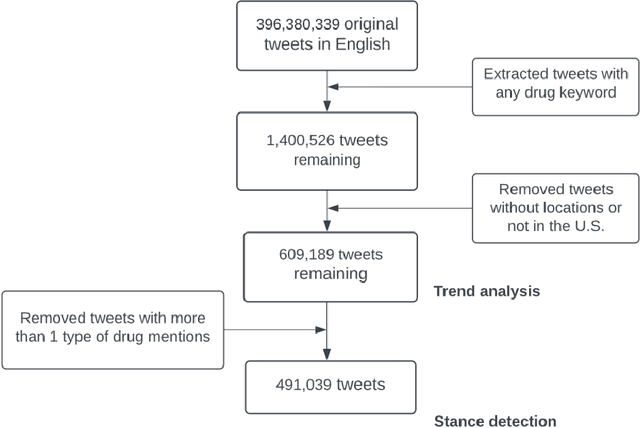
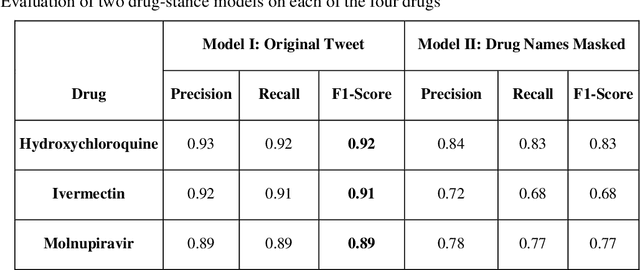
Understanding public discourse on emergency use of unproven therapeutics is essential to monitor safe use and combat misinformation. We developed a natural language processing (NLP)-based pipeline to understand public perceptions of and stances on COVID-19-related drugs on Twitter across time. This retrospective study included 609,189 US-based tweets between January 29th, 2020 and November 30th, 2021 on four drugs that gained wide public attention during the COVID-19 pandemic: 1) Hydroxychloroquine and Ivermectin, drug therapies with anecdotal evidence; and 2) Molnupiravir and Remdesivir, FDA-approved treatment options for eligible patients. Time-trend analysis was used to understand the popularity and related events. Content and demographic analyses were conducted to explore potential rationales of people's stances on each drug. Time-trend analysis revealed that Hydroxychloroquine and Ivermectin received much more discussion than Molnupiravir and Remdesivir, particularly during COVID-19 surges. Hydroxychloroquine and Ivermectin were highly politicized, related to conspiracy theories, hearsay, celebrity effects, etc. The distribution of stance between the two major US political parties was significantly different (p<0.001); Republicans were much more likely to support Hydroxychloroquine (+55%) and Ivermectin (+30%) than Democrats. People with healthcare backgrounds tended to oppose Hydroxychloroquine (+7%) more than the general population; in contrast, the general population was more likely to support Ivermectin (+14%). We make all the data, code, and models available at https://github.com/ningkko/COVID-drug.
* This is a preliminary version. For full paper please refer to JAMIA
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
Jan 18, 2022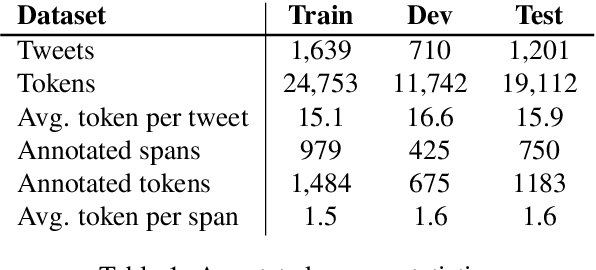
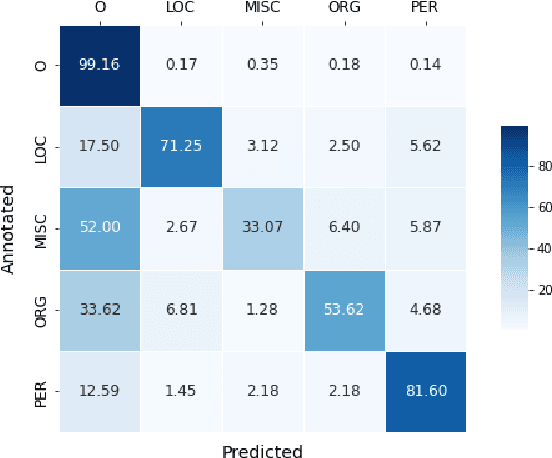
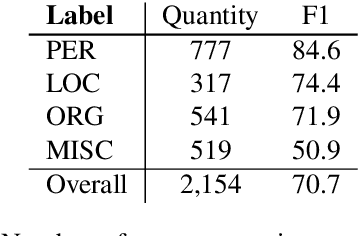

Social media data such as Twitter messages ("tweets") pose a particular challenge to NLP systems because of their short, noisy, and colloquial nature. Tasks such as Named Entity Recognition (NER) and syntactic parsing require highly domain-matched training data for good performance. While there are some publicly available annotated datasets of tweets, they are all purpose-built for solving one task at a time. As yet there is no complete training corpus for both syntactic analysis (e.g., part of speech tagging, dependency parsing) and NER of tweets. In this study, we aim to create Tweebank-NER, an NER corpus based on Tweebank V2 (TB2), and we use these datasets to train state-of-the-art NLP models. We first annotate named entities in TB2 using Amazon Mechanical Turk and measure the quality of our annotations. We train a Stanza NER model on the new benchmark, achieving competitive performance against other non-transformer NER systems. Finally, we train other Twitter NLP models (a tokenizer, lemmatizer, part of speech tagger, and dependency parser) on TB2 based on Stanza, and achieve state-of-the-art or competitive performance on these tasks. We release the dataset and make the models available to use in an "off-the-shelf" manner for future Tweet NLP research. Our source code, data, and pre-trained models are available at: \url{https://github.com/social-machines/TweebankNLP}.
Topic Detection and Tracking with Time-Aware Document Embeddings
Dec 12, 2021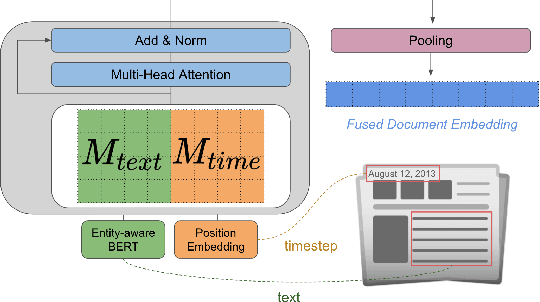

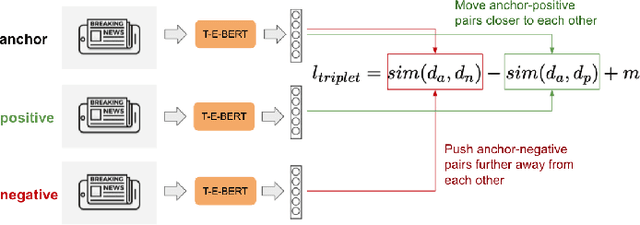
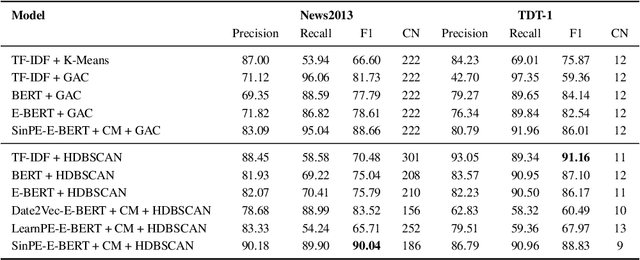
The time at which a message is communicated is a vital piece of metadata in many real-world natural language processing tasks such as Topic Detection and Tracking (TDT). TDT systems aim to cluster a corpus of news articles by event, and in that context, stories that describe the same event are likely to have been written at around the same time. Prior work on time modeling for TDT takes this into account, but does not well capture how time interacts with the semantic nature of the event. For example, stories about a tropical storm are likely to be written within a short time interval, while stories about a movie release may appear over weeks or months. In our work, we design a neural method that fuses temporal and textual information into a single representation of news documents for event detection. We fine-tune these time-aware document embeddings with a triplet loss architecture, integrate the model into downstream TDT systems, and evaluate the systems on two benchmark TDT data sets in English. In the retrospective setting, we apply clustering algorithms to the time-aware embeddings and show substantial improvements over baselines on the News2013 data set. In the online streaming setting, we add our document encoder to an existing state-of-the-art TDT pipeline and demonstrate that it can benefit the overall performance. We conduct ablation studies on the time representation and fusion algorithm strategies, showing that our proposed model outperforms alternative strategies. Finally, we probe the model to examine how it handles recurring events more effectively than previous TDT systems.
Topic-time Heatmaps for Human-in-the-loop Topic Detection and Tracking
Oct 12, 2021
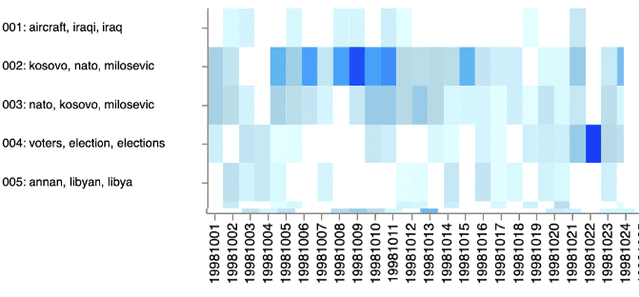
The essential task of Topic Detection and Tracking (TDT) is to organize a collection of news media into clusters of stories that pertain to the same real-world event. To apply TDT models to practical applications such as search engines and discovery tools, human guidance is needed to pin down the scope of an "event" for the corpus of interest. In this work in progress, we explore a human-in-the-loop method that helps users iteratively fine-tune TDT algorithms so that both the algorithms and the users themselves better understand the nature of the events. We generate a visual overview of the entire corpus, allowing the user to select regions of interest from the overview, and then ask a series of questions to affirm (or reject) that the selected documents belong to the same event. The answers to these questions supplement the training data for the event similarity model that underlies the system.
LNN-EL: A Neuro-Symbolic Approach to Short-text Entity Linking
Jun 17, 2021
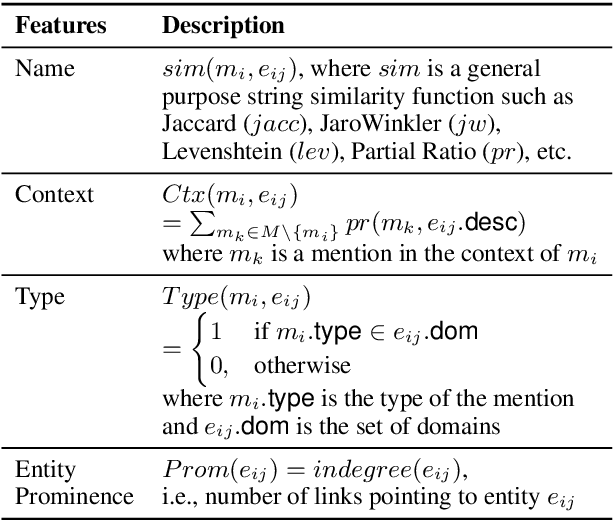
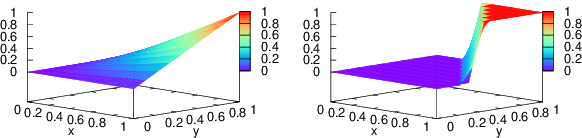
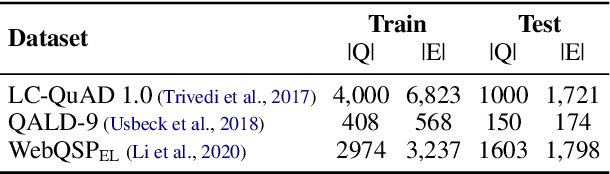
Entity linking (EL), the task of disambiguating mentions in text by linking them to entities in a knowledge graph, is crucial for text understanding, question answering or conversational systems. Entity linking on short text (e.g., single sentence or question) poses particular challenges due to limited context. While prior approaches use either heuristics or black-box neural methods, here we propose LNN-EL, a neuro-symbolic approach that combines the advantages of using interpretable rules based on first-order logic with the performance of neural learning. Even though constrained to using rules, LNN-EL performs competitively against SotA black-box neural approaches, with the added benefits of extensibility and transferability. In particular, we show that we can easily blend existing rule templates given by a human expert, with multiple types of features (priors, BERT encodings, box embeddings, etc), and even scores resulting from previous EL methods, thus improving on such methods. For instance, on the LC-QuAD-1.0 dataset, we show more than $4$\% increase in F1 score over previous SotA. Finally, we show that the inductive bias offered by using logic results in learned rules that transfer well across datasets, even without fine tuning, while maintaining high accuracy.
Contrastive Learning of Medical Visual Representations from Paired Images and Text
Oct 02, 2020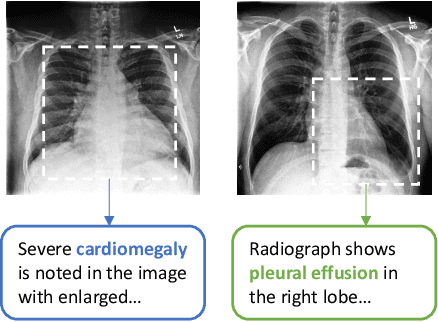
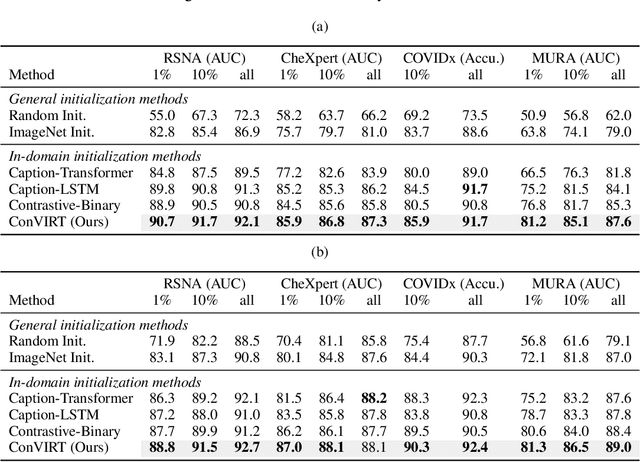
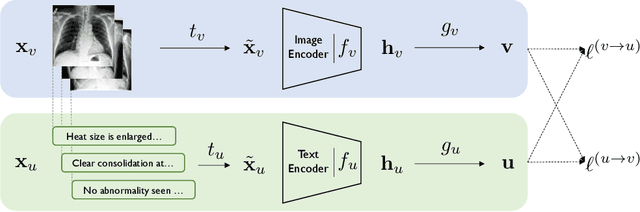
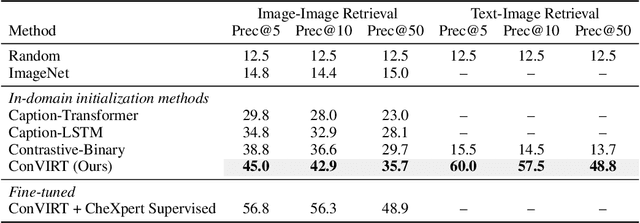
Learning visual representations of medical images is core to medical image understanding but its progress has been held back by the small size of hand-labeled datasets. Existing work commonly relies on transferring weights from ImageNet pretraining, which is suboptimal due to drastically different image characteristics, or rule-based label extraction from the textual report data paired with medical images, which is inaccurate and hard to generalize. We propose an alternative unsupervised strategy to learn medical visual representations directly from the naturally occurring pairing of images and textual data. Our method of pretraining medical image encoders with the paired text data via a bidirectional contrastive objective between the two modalities is domain-agnostic, and requires no additional expert input. We test our method by transferring our pretrained weights to 4 medical image classification tasks and 2 zero-shot retrieval tasks, and show that our method leads to image representations that considerably outperform strong baselines in most settings. Notably, in all 4 classification tasks, our method requires only 10% as much labeled training data as an ImageNet initialized counterpart to achieve better or comparable performance, demonstrating superior data efficiency.
Data augmentation with Möbius transformations
Feb 07, 2020
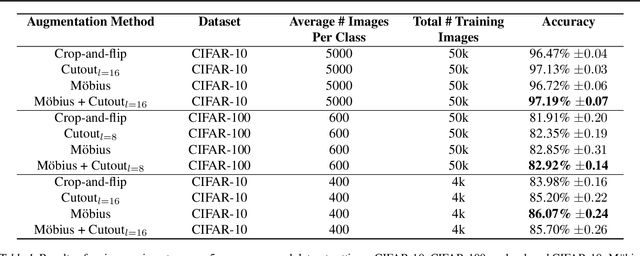

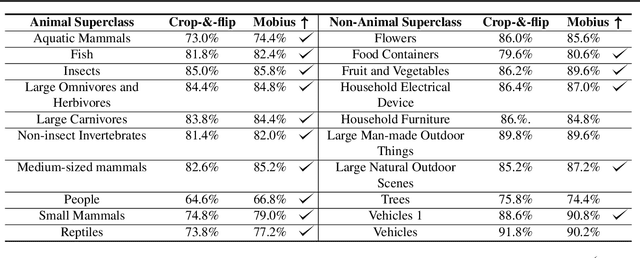
Data augmentation has led to substantial improvements in the performance and generalization of deep models, and remain a highly adaptable method to evolving model architectures and varying amounts of data---in particular, extremely scarce amounts of available training data. In this paper, we present a novel method of applying M\"obius transformations to augment input images during training. M\"obius transformations are bijective conformal maps that generalize image translation to operate over complex inversion in pixel space. As a result, M\"obius transformations can operate on the sample level and preserve data labels. We show that the inclusion of M\"obius transformations during training enables improved generalization over prior sample-level data augmentation techniques such as cutout and standard crop-and-flip transformations, most notably in low data regimes.
Automatic Text-based Personality Recognition on Monologues and Multiparty Dialogues Using Attentive Networks and Contextual Embeddings
Nov 21, 2019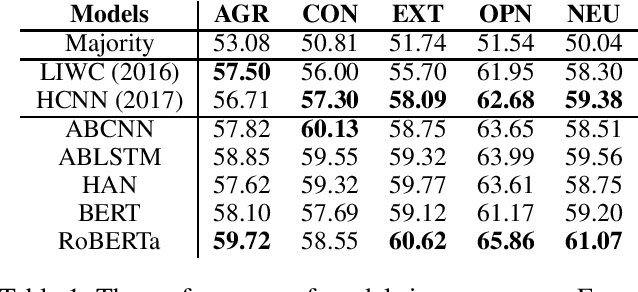
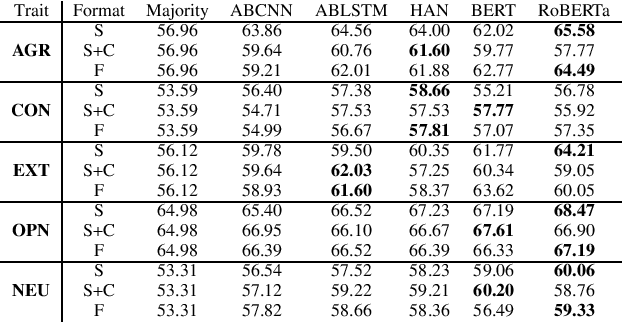
Previous works related to automatic personality recognition focus on using traditional classification models with linguistic features. However, attentive neural networks with contextual embeddings, which have achieved huge success in text classification, are rarely explored for this task. In this project, we have two major contributions. First, we create the first dialogue-based personality dataset, FriendsPersona, by annotating 5 personality traits of speakers from Friends TV Show through crowdsourcing. Second, we present a novel approach to automatic personality recognition using pre-trained contextual embeddings (BERT and RoBERTa) and attentive neural networks. Our models largely improve the state-of-art results on the monologue Essays dataset by 2.49%, and establish a solid benchmark on our FriendsPersona. By comparing results in two datasets, we demonstrate the challenges of modeling personality in multi-party dialogue.
DialectGram: Detecting Dialectal Variation at Multiple Geographic Resolutions
Oct 16, 2019
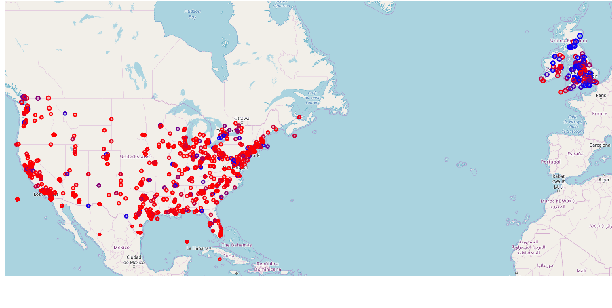
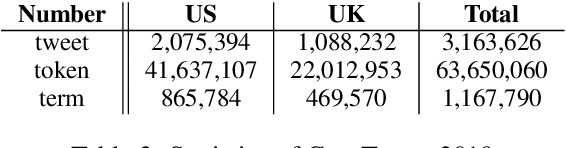
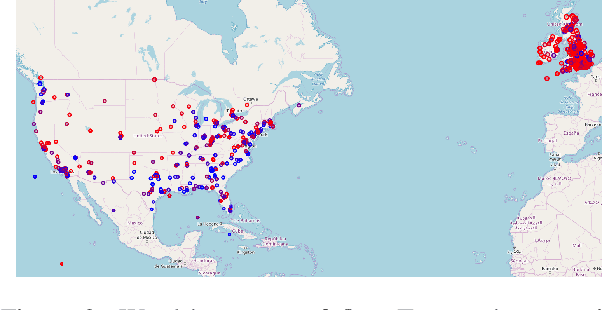
Several computational models have been developed to detect and analyze dialect variation in recent years. Most of these models assume a predefined set of geographical regions over which they detect and analyze dialectal variation. However, dialect variation occurs at multiple levels of geographic resolution ranging from cities within a state, states within a country, and between countries across continents. In this work, we propose a model that enables detection of dialectal variation at multiple levels of geographic resolution obviating the need for a-priori definition of the resolution level. Our method DialectGram, learns dialect-sensitive word embeddings while being agnostic of the geographic resolution. Specifically it only requires one-time training and enables analysis of dialectal variation at a chosen resolution post-hoc -- a significant departure from prior models which need to be re-trained whenever the pre-defined set of regions changes. Furthermore, DialectGram explicitly models senses thus enabling one to estimate the proportion of each sense usage in any given region. Finally, we quantitatively evaluate our model against other baselines on a new evaluation dataset DialectSim (in English) and show that DialectGram can effectively model linguistic variation.
* Hang Jiang, Haoshen Hong, and Yuxing Chen are equal contributors