 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
Oct 17, 2024



Enabling mobile robots to perform long-term tasks in dynamic real-world environments is a formidable challenge, especially when the environment changes frequently due to human-robot interactions or the robot's own actions. Traditional methods typically assume static scenes, which limits their applicability in the continuously changing real world. To overcome these limitations, we present DovSG, a novel mobile manipulation framework that leverages dynamic open-vocabulary 3D scene graphs and a language-guided task planning module for long-term task execution. DovSG takes RGB-D sequences as input and utilizes vision-language models (VLMs) for object detection to obtain high-level object semantic features. Based on the segmented objects, a structured 3D scene graph is generated for low-level spatial relationships. Furthermore, an efficient mechanism for locally updating the scene graph, allows the robot to adjust parts of the graph dynamically during interactions without the need for full scene reconstruction. This mechanism is particularly valuable in dynamic environments, enabling the robot to continually adapt to scene changes and effectively support the execution of long-term tasks. We validated our system in real-world environments with varying degrees of manual modifications, demonstrating its effectiveness and superior performance in long-term tasks. Our project page is available at: https://BJHYZJ.github.io/DoviSG.
Innovative Thinking, Infinite Humor: Humor Research of Large Language Models through Structured Thought Leaps
Oct 14, 2024



Humor is a culturally nuanced aspect of human language that presents challenges for understanding and generation, requiring participants to possess good creativity and strong associative thinking. Similar to reasoning tasks like solving math problems, humor generation requires continuous reflection and revision to foster creative thinking, rather than relying on a sudden flash of inspiration like Creative Leap-of-Thought (CLoT) paradigm. Although CLoT can realize the ability of remote association generation, this paradigm fails to generate humor content. Therefore, in this paper, we propose a systematic way of thinking about generating humor and based on it, we built Creative Leap of Structured Thought (CLoST) frame. First, a reward model is necessary achieve the purpose of being able to correct errors, since there is currently no expert model of humor and a usable rule to determine whether a piece of content is humorous. Judgement-oriented instructions are designed to improve the capability of a model, and we also propose an open-domain instruction evolutionary method to fully unleash the potential. Then, through reinforcement learning, the model learns to hone its rationales of the thought chain and refine the strategies it uses. Thus, it learns to recognize and correct its mistakes, and finally generate the most humorous and creative answer. These findings deepen our understanding of the creative capabilities of LLMs and provide ways to enhance LLMs' creative abilities for cross-domain innovative applications.
REGNet V2: End-to-End REgion-based Grasp Detection Network for Grippers of Different Sizes in Point Clouds
Oct 12, 2024
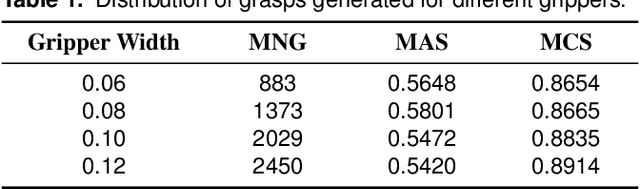
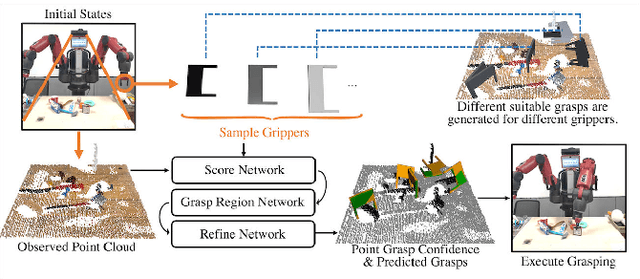
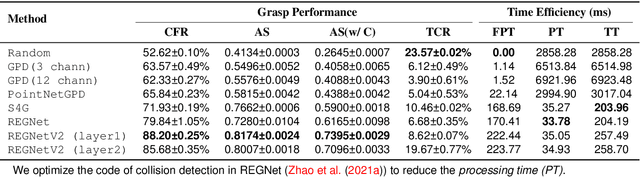
Grasping has been a crucial but challenging problem in robotics for many years. One of the most important challenges is how to make grasping generalizable and robust to novel objects as well as grippers in unstructured environments. We present \regnet, a robotic grasping system that can adapt to different parallel jaws to grasp diversified objects. To support different grippers, \regnet embeds the gripper parameters into point clouds, based on which it predicts suitable grasp configurations. It includes three components: Score Network (SN), Grasp Region Network (GRN), and Refine Network (RN). In the first stage, SN is used to filter suitable points for grasping by grasp confidence scores. In the second stage, based on the selected points, GRN generates a set of grasp proposals. Finally, RN refines the grasp proposals for more accurate and robust predictions. We devise an analytic policy to choose the optimal grasp to be executed from the predicted grasp set. To train \regnet, we construct a large-scale grasp dataset containing collision-free grasp configurations using different parallel-jaw grippers. The experimental results demonstrate that \regnet with the analytic policy achieves the highest success rate of $74.98\%$ in real-world clutter scenes with $20$ objects, significantly outperforming several state-of-the-art methods, including GPD, PointNetGPD, and S4G. The code and dataset are available at https://github.com/zhaobinglei/REGNet-V2.
Bridging OOD Detection and Generalization: A Graph-Theoretic View
Sep 26, 2024In the context of modern machine learning, models deployed in real-world scenarios often encounter diverse data shifts like covariate and semantic shifts, leading to challenges in both out-of-distribution (OOD) generalization and detection. Despite considerable attention to these issues separately, a unified framework for theoretical understanding and practical usage is lacking. To bridge the gap, we introduce a graph-theoretic framework to jointly tackle both OOD generalization and detection problems. By leveraging the graph formulation, data representations are obtained through the factorization of the graph's adjacency matrix, enabling us to derive provable error quantifying OOD generalization and detection performance. Empirical results showcase competitive performance in comparison to existing methods, thereby validating our theoretical underpinnings. Code is publicly available at https://github.com/deeplearning-wisc/graph-spectral-ood.
AdaCAD: Adaptively Decoding to Balance Conflicts between Contextual and Parametric Knowledge
Sep 11, 2024



Knowledge conflict arises from discrepancies between information in the context of a large language model (LLM) and the knowledge stored in its parameters. This can hurt performance when using standard decoding techniques, which tend to ignore the context. Existing test-time contrastive methods seek to address this by comparing the LLM's output distribution with and without the context and adjust the model according to the contrast between them. However, we find that these methods frequently misjudge the degree of conflict and struggle to handle instances that vary in their amount of conflict, with static methods over-adjusting when conflict is absent. We propose a fine-grained, instance-level approach called AdaCAD, which dynamically infers the weight of adjustment based on the degree of conflict, as measured by the Jensen-Shannon divergence between distributions representing contextual and parametric knowledge. Our experiments across four models on six diverse question-answering (QA) datasets and three summarization tasks demonstrate that our training-free adaptive method consistently outperforms other decoding methods on QA, with average accuracy gains of 14.21% (absolute) over a static contrastive baseline, and improves the factuality of summaries by 5.59 (AlignScore). Furthermore, our analysis shows that while decoding with contrastive baselines hurts performance when conflict is absent, AdaCAD mitigates these losses, making it more applicable to real-world datasets in which some examples have conflict and others do not.
q-exponential family for policy optimization
Aug 14, 2024Policy optimization methods benefit from a simple and tractable policy functional, usually the Gaussian for continuous action spaces. In this paper, we consider a broader policy family that remains tractable: the $q$-exponential family. This family of policies is flexible, allowing the specification of both heavy-tailed policies ($q>1$) and light-tailed policies ($q<1$). This paper examines the interplay between $q$-exponential policies for several actor-critic algorithms conducted on both online and offline problems. We find that heavy-tailed policies are more effective in general and can consistently improve on Gaussian. In particular, we find the Student's t-distribution to be more stable than the Gaussian across settings and that a heavy-tailed $q$-Gaussian for Tsallis Advantage Weighted Actor-Critic consistently performs well in offline benchmark problems. Our code is available at \url{https://github.com/lingweizhu/qexp}.
MultiHateClip: A Multilingual Benchmark Dataset for Hateful Video Detection on YouTube and Bilibili
Jul 28, 2024



Hate speech is a pressing issue in modern society, with significant effects both online and offline. Recent research in hate speech detection has primarily centered on text-based media, largely overlooking multimodal content such as videos. Existing studies on hateful video datasets have predominantly focused on English content within a Western context and have been limited to binary labels (hateful or non-hateful), lacking detailed contextual information. This study presents MultiHateClip1 , an novel multilingual dataset created through hate lexicons and human annotation. It aims to enhance the detection of hateful videos on platforms such as YouTube and Bilibili, including content in both English and Chinese languages. Comprising 2,000 videos annotated for hatefulness, offensiveness, and normalcy, this dataset provides a cross-cultural perspective on gender-based hate speech. Through a detailed examination of human annotation results, we discuss the differences between Chinese and English hateful videos and underscore the importance of different modalities in hateful and offensive video analysis. Evaluations of state-of-the-art video classification models, such as VLM, GPT-4V and Qwen-VL, on MultiHateClip highlight the existing challenges in accurately distinguishing between hateful and offensive content and the urgent need for models that are both multimodally and culturally nuanced. MultiHateClip represents a foundational advance in enhancing hateful video detection by underscoring the necessity of a multimodal and culturally sensitive approach in combating online hate speech.
Disentangling Masked Autoencoders for Unsupervised Domain Generalization
Jul 10, 2024



Domain Generalization (DG), designed to enhance out-of-distribution (OOD) generalization, is all about learning invariance against domain shifts utilizing sufficient supervision signals. Yet, the scarcity of such labeled data has led to the rise of unsupervised domain generalization (UDG) - a more important yet challenging task in that models are trained across diverse domains in an unsupervised manner and eventually tested on unseen domains. UDG is fast gaining attention but is still far from well-studied. To close the research gap, we propose a novel learning framework designed for UDG, termed the Disentangled Masked Auto Encoder (DisMAE), aiming to discover the disentangled representations that faithfully reveal the intrinsic features and superficial variations without access to the class label. At its core is the distillation of domain-invariant semantic features, which cannot be distinguished by domain classifier, while filtering out the domain-specific variations (for example, color schemes and texture patterns) that are unstable and redundant. Notably, DisMAE co-trains the asymmetric dual-branch architecture with semantic and lightweight variation encoders, offering dynamic data manipulation and representation level augmentation capabilities. Extensive experiments on four benchmark datasets (i.e., DomainNet, PACS, VLCS, Colored MNIST) with both DG and UDG tasks demonstrate that DisMAE can achieve competitive OOD performance compared with the state-of-the-art DG and UDG baselines, which shed light on potential research line in improving the generalization ability with large-scale unlabeled data.
Research, Applications and Prospects of Event-Based Pedestrian Detection: A Survey
Jul 05, 2024



Event-based cameras, inspired by the biological retina, have evolved into cutting-edge sensors distinguished by their minimal power requirements, negligible latency, superior temporal resolution, and expansive dynamic range. At present, cameras used for pedestrian detection are mainly frame-based imaging sensors, which have suffered from lethargic response times and hefty data redundancy. In contrast, event-based cameras address these limitations by eschewing extraneous data transmissions and obviating motion blur in high-speed imaging scenarios. On pedestrian detection via event-based cameras, this paper offers an exhaustive review of research and applications particularly in the autonomous driving context. Through methodically scrutinizing relevant literature, the paper outlines the foundational principles, developmental trajectory, and the comparative merits and demerits of eventbased detection relative to traditional frame-based methodologies. This review conducts thorough analyses of various event stream inputs and their corresponding network models to evaluate their applicability across diverse operational environments. It also delves into pivotal elements such as crucial datasets and data acquisition techniques essential for advancing this technology, as well as advanced algorithms for processing event stream data. Culminating with a synthesis of the extant landscape, the review accentuates the unique advantages and persistent challenges inherent in event-based pedestrian detection, offering a prognostic view on potential future developments in this fast-progressing field.
A Bounding Box is Worth One Token: Interleaving Layout and Text in a Large Language Model for Document Understanding
Jul 02, 2024



Recently, many studies have demonstrated that exclusively incorporating OCR-derived text and spatial layouts with large language models (LLMs) can be highly effective for document understanding tasks. However, existing methods that integrate spatial layouts with text have limitations, such as producing overly long text sequences or failing to fully leverage the autoregressive traits of LLMs. In this work, we introduce Interleaving Layout and Text in a Large Language Model (LayTextLLM)} for document understanding. In particular, LayTextLLM projects each bounding box to a single embedding and interleaves it with text, efficiently avoiding long sequence issues while leveraging autoregressive traits of LLMs. LayTextLLM not only streamlines the interaction of layout and textual data but also shows enhanced performance in Key Information Extraction (KIE) and Visual Question Answering (VQA). Comprehensive benchmark evaluations reveal significant improvements, with a 27.0% increase on KIE tasks and 24.1% on VQA tasks compared to previous state-of-the-art document understanding MLLMs, as well as a 15.5% improvement over other SOTA OCR-based LLMs on KIE tasks.