 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Glare Detection: Review, Analysis, and Dataset Release
Oct 13, 2021
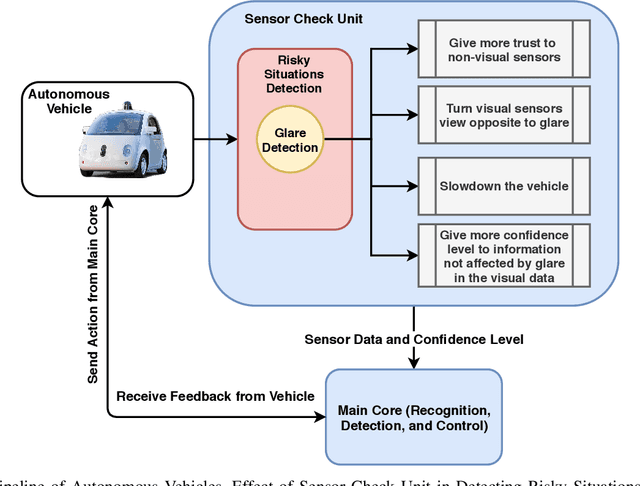

Sun Glare widely exists in the images captured by unmanned ground and aerial vehicles performing in outdoor environments. The existence of such artifacts in images will result in wrong feature extraction and failure of autonomous systems. Humans will try to adapt their view once they observe a glare (especially when driving), and this behavior is an essential requirement for the next generation of autonomous vehicles. The source of glare is not limited to the sun, and glare can be seen in the images captured during the nighttime and in indoor environments, which is due to the presence of different light sources; reflective surfaces also influence the generation of such artifacts. The glare's visual characteristics are different on images captured by various cameras and depend on several factors such as the camera's shutter speed and exposure level. Hence, it is challenging to introduce a general - robust and accurate - algorithm for glare detection that can perform well in various captured images. This research aims to introduce the first dataset for glare detection, which includes images captured by different cameras. Besides, the effect of multiple image representations and their combination in glare detection is examined using the proposed deep network architecture. The released dataset is available at https://github.com/maesfahani/glaredetection
Visual Enhanced 3D Point Cloud Reconstruction from A Single Image
Aug 17, 2021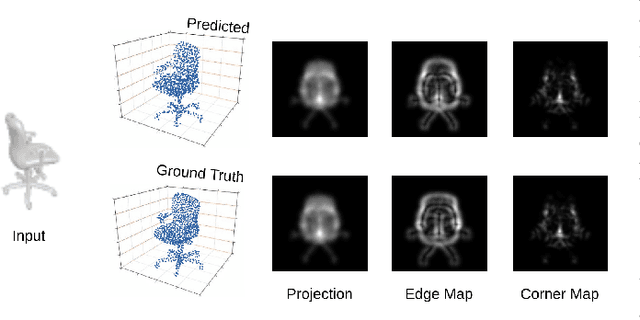
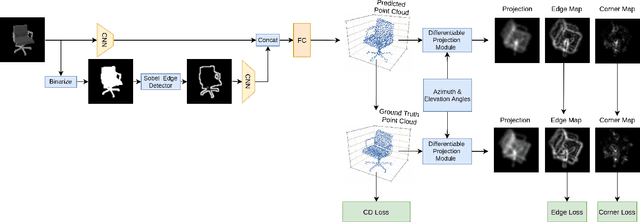
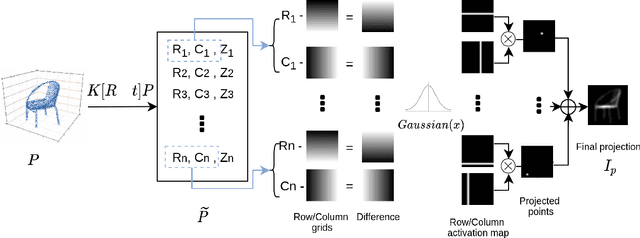

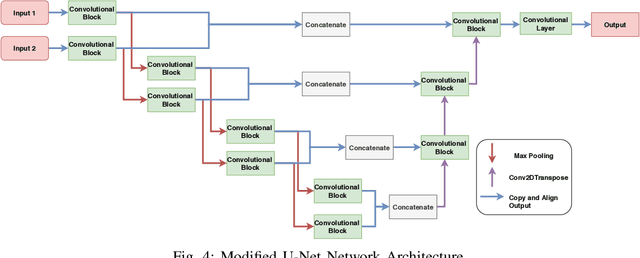
Solving the challenging problem of 3D object reconstruction from a single image appropriately gives existing technologies the ability to perform with a single monocular camera rather than requiring depth sensors. In recent years, thanks to the development of deep learning, 3D reconstruction of a single image has demonstrated impressive progress. Existing researches use Chamfer distance as a loss function to guide the training of the neural network. However, the Chamfer loss will give equal weights to all points inside the 3D point clouds. It tends to sacrifice fine-grained and thin structures to avoid incurring a high loss, which will lead to visually unsatisfactory results. This paper proposes a framework that can recover a detailed three-dimensional point cloud from a single image by focusing more on boundaries (edge and corner points). Experimental results demonstrate that the proposed method outperforms existing techniques significantly, both qualitatively and quantitatively, and has fewer training parameters.