 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Joint 2D & 3D Diffusion Models for Complete Molecule Generation
May 21, 2023Designing new molecules is essential for drug discovery and material science. Recently, deep generative models that aim to model molecule distribution have made promising progress in narrowing down the chemical research space and generating high-fidelity molecules. However, current generative models only focus on modeling either 2D bonding graphs or 3D geometries, which are two complementary descriptors for molecules. The lack of ability to jointly model both limits the improvement of generation quality and further downstream applications. In this paper, we propose a new joint 2D and 3D diffusion model (JODO) that generates complete molecules with atom types, formal charges, bond information, and 3D coordinates. To capture the correlation between molecular graphs and geometries in the diffusion process, we develop a Diffusion Graph Transformer to parameterize the data prediction model that recovers the original data from noisy data. The Diffusion Graph Transformer interacts node and edge representations based on our relational attention mechanism, while simultaneously propagating and updating scalar features and geometric vectors. Our model can also be extended for inverse molecular design targeting single or multiple quantum properties. In our comprehensive evaluation pipeline for unconditional joint generation, the results of the experiment show that JODO remarkably outperforms the baselines on the QM9 and GEOM-Drugs datasets. Furthermore, our model excels in few-step fast sampling, as well as in inverse molecule design and molecular graph generation. Our code is provided in https://github.com/GRAPH-0/JODO.
LatentAvatar: Learning Latent Expression Code for Expressive Neural Head Avatar
May 03, 2023Existing approaches to animatable NeRF-based head avatars are either built upon face templates or use the expression coefficients of templates as the driving signal. Despite the promising progress, their performances are heavily bound by the expression power and the tracking accuracy of the templates. In this work, we present LatentAvatar, an expressive neural head avatar driven by latent expression codes. Such latent expression codes are learned in an end-to-end and self-supervised manner without templates, enabling our method to get rid of expression and tracking issues. To achieve this, we leverage a latent head NeRF to learn the person-specific latent expression codes from a monocular portrait video, and further design a Y-shaped network to learn the shared latent expression codes of different subjects for cross-identity reenactment. By optimizing the photometric reconstruction objectives in NeRF, the latent expression codes are learned to be 3D-aware while faithfully capturing the high-frequency detailed expressions. Moreover, by learning a mapping between the latent expression code learned in shared and person-specific settings, LatentAvatar is able to perform expressive reenactment between different subjects. Experimental results show that our LatentAvatar is able to capture challenging expressions and the subtle movement of teeth and even eyeballs, which outperforms previous state-of-the-art solutions in both quantitative and qualitative comparisons. Project page: https://www.liuyebin.com/latentavatar.
CloSET: Modeling Clothed Humans on Continuous Surface with Explicit Template Decomposition
Apr 06, 2023Creating animatable avatars from static scans requires the modeling of clothing deformations in different poses. Existing learning-based methods typically add pose-dependent deformations upon a minimally-clothed mesh template or a learned implicit template, which have limitations in capturing details or hinder end-to-end learning. In this paper, we revisit point-based solutions and propose to decompose explicit garment-related templates and then add pose-dependent wrinkles to them. In this way, the clothing deformations are disentangled such that the pose-dependent wrinkles can be better learned and applied to unseen poses. Additionally, to tackle the seam artifact issues in recent state-of-the-art point-based methods, we propose to learn point features on a body surface, which establishes a continuous and compact feature space to capture the fine-grained and pose-dependent clothing geometry. To facilitate the research in this field, we also introduce a high-quality scan dataset of humans in real-world clothing. Our approach is validated on two existing datasets and our newly introduced dataset, showing better clothing deformation results in unseen poses. The project page with code and dataset can be found at https://www.liuyebin.com/closet.
PriSTI: A Conditional Diffusion Framework for Spatiotemporal Imputation
Feb 20, 2023



Spatiotemporal data mining plays an important role in air quality monitoring, crowd flow modeling, and climate forecasting. However, the originally collected spatiotemporal data in real-world scenarios is usually incomplete due to sensor failures or transmission loss. Spatiotemporal imputation aims to fill the missing values according to the observed values and the underlying spatiotemporal dependence of them. The previous dominant models impute missing values autoregressively and suffer from the problem of error accumulation. As emerging powerful generative models, the diffusion probabilistic models can be adopted to impute missing values conditioned by observations and avoid inferring missing values from inaccurate historical imputation. However, the construction and utilization of conditional information are inevitable challenges when applying diffusion models to spatiotemporal imputation. To address above issues, we propose a conditional diffusion framework for spatiotemporal imputation with enhanced prior modeling, named PriSTI. Our proposed framework provides a conditional feature extraction module first to extract the coarse yet effective spatiotemporal dependencies from conditional information as the global context prior. Then, a noise estimation module transforms random noise to realistic values, with the spatiotemporal attention weights calculated by the conditional feature, as well as the consideration of geographic relationships. PriSTI outperforms existing imputation methods in various missing patterns of different real-world spatiotemporal data, and effectively handles scenarios such as high missing rates and sensor failure. The implementation code is available at https://github.com/LMZZML/PriSTI.
Conditional Diffusion Based on Discrete Graph Structures for Molecular Graph Generation
Jan 01, 2023



Learning the underlying distribution of molecular graphs and generating high-fidelity samples is a fundamental research problem in drug discovery and material science. However, accurately modeling distribution and rapidly generating novel molecular graphs remain crucial and challenging goals. To accomplish these goals, we propose a novel Conditional Diffusion model based on discrete Graph Structures (CDGS) for molecular graph generation. Specifically, we construct a forward graph diffusion process on both graph structures and inherent features through stochastic differential equations (SDE) and derive discrete graph structures as the condition for reverse generative processes. We present a specialized hybrid graph noise prediction model that extracts the global context and the local node-edge dependency from intermediate graph states. We further utilize ordinary differential equation (ODE) solvers for efficient graph sampling, based on the semi-linear structure of the probability flow ODE. Experiments on diverse datasets validate the effectiveness of our framework. Particularly, the proposed method still generates high-quality molecular graphs in a limited number of steps.
GraphGDP: Generative Diffusion Processes for Permutation Invariant Graph Generation
Dec 04, 2022



Graph generative models have broad applications in biology, chemistry and social science. However, modelling and understanding the generative process of graphs is challenging due to the discrete and high-dimensional nature of graphs, as well as permutation invariance to node orderings in underlying graph distributions. Current leading autoregressive models fail to capture the permutation invariance nature of graphs for the reliance on generation ordering and have high time complexity. Here, we propose a continuous-time generative diffusion process for permutation invariant graph generation to mitigate these issues. Specifically, we first construct a forward diffusion process defined by a stochastic differential equation (SDE), which smoothly converts graphs within the complex distribution to random graphs that follow a known edge probability. Solving the corresponding reverse-time SDE, graphs can be generated from newly sampled random graphs. To facilitate the reverse-time SDE, we newly design a position-enhanced graph score network, capturing the evolving structure and position information from perturbed graphs for permutation equivariant score estimation. Under the evaluation of comprehensive metrics, our proposed generative diffusion process achieves competitive performance in graph distribution learning. Experimental results also show that GraphGDP can generate high-quality graphs in only 24 function evaluations, much faster than previous autoregressive models.
A Geometric-Relational Deep Learning Framework for BIM Object Classification
Dec 02, 2022Interoperability issue is a significant problem in Building Information Modeling (BIM). Object type, as a kind of critical semantic information needed in multiple BIM applications like scan-to-BIM and code compliance checking, also suffers when exchanging BIM data or creating models using software of other domains. It can be supplemented using deep learning. Current deep learning methods mainly learn from the shape information of BIM objects for classification, leaving relational information inherent in the BIM context unused. To address this issue, we introduce a two-branch geometric-relational deep learning framework. It boosts previous geometric classification methods with relational information. We also present a BIM object dataset IFCNet++, which contains both geometric and relational information about the objects. Experiments show that our framework can be flexibly adapted to different geometric methods. And relational features do act as a bonus to general geometric learning methods, obviously improving their classification performance, thus reducing the manual labor of checking models and improving the practical value of enriched BIM models.
Privileged Prior Information Distillation for Image Matting
Nov 25, 2022



Performance of trimap-free image matting methods is limited when trying to decouple the deterministic and undetermined regions, especially in the scenes where foregrounds are semantically ambiguous, chromaless, or high transmittance. In this paper, we propose a novel framework named Privileged Prior Information Distillation for Image Matting (PPID-IM) that can effectively transfer privileged prior environment-aware information to improve the performance of students in solving hard foregrounds. The prior information of trimap regulates only the teacher model during the training stage, while not being fed into the student network during actual inference. In order to achieve effective privileged cross-modality (i.e. trimap and RGB) information distillation, we introduce a Cross-Level Semantic Distillation (CLSD) module that reinforces the trimap-free students with more knowledgeable semantic representations and environment-aware information. We also propose an Attention-Guided Local Distillation module that efficiently transfers privileged local attributes from the trimap-based teacher to trimap-free students for the guidance of local-region optimization. Extensive experiments demonstrate the effectiveness and superiority of our PPID framework on the task of image matting. In addition, our trimap-free IndexNet-PPID surpasses the other competing state-of-the-art methods by a large margin, especially in scenarios with chromaless, weak texture, or irregular objects.
UnconFuse: Avatar Reconstruction from Unconstrained Images
Nov 18, 2022



The report proposes an effective solution about 3D human body reconstruction from multiple unconstrained frames for ECCV 2022 WCPA Challenge: From Face, Body and Fashion to 3D Virtual avatars I (track1: Multi-View Based 3D Human Body Reconstruction). We reproduce the reconstruction method presented in MVP-Human as our baseline, and make some improvements for the particularity of this challenge. We finally achieve the score 0.93 on the official testing set, getting the 1st place on the leaderboard.
CrossHuman: Learning Cross-Guidance from Multi-Frame Images for Human Reconstruction
Jul 20, 2022
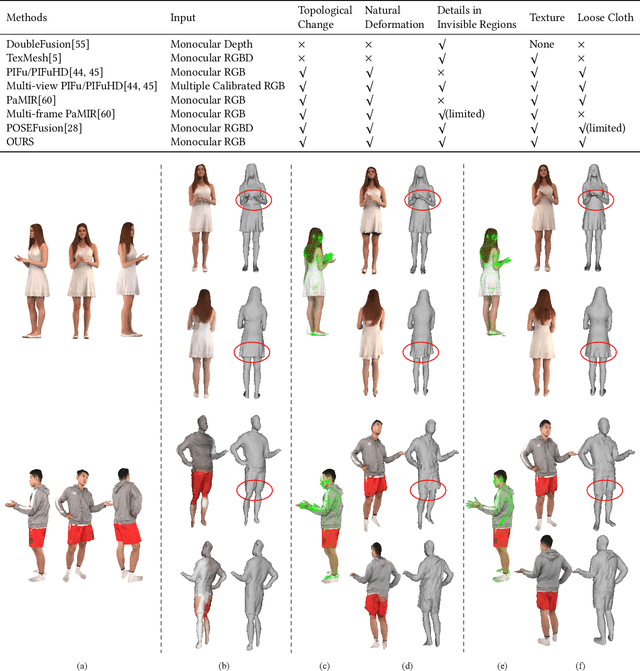
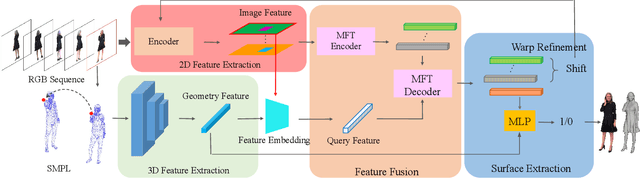
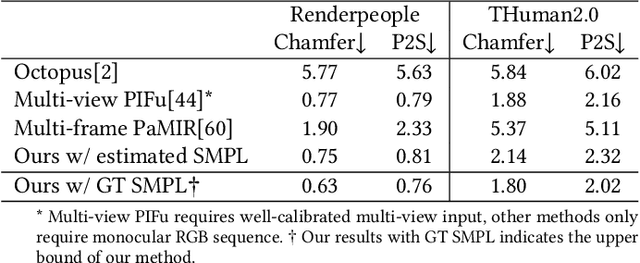
We propose CrossHuman, a novel method that learns cross-guidance from parametric human model and multi-frame RGB images to achieve high-quality 3D human reconstruction. To recover geometry details and texture even in invisible regions, we design a reconstruction pipeline combined with tracking-based methods and tracking-free methods. Given a monocular RGB sequence, we track the parametric human model in the whole sequence, the points (voxels) corresponding to the target frame are warped to reference frames by the parametric body motion. Guided by the geometry priors of the parametric body and spatially aligned features from RGB sequence, the robust implicit surface is fused. Moreover, a multi-frame transformer (MFT) and a self-supervised warp refinement module are integrated to the framework to relax the requirements of parametric body and help to deal with very loose cloth. Compared with previous works, our CrossHuman enables high-fidelity geometry details and texture in both visible and invisible regions and improves the accuracy of the human reconstruction even under estimated inaccurate parametric human models. The experiments demonstrate that our method achieves state-of-the-art (SOTA) performance.