 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
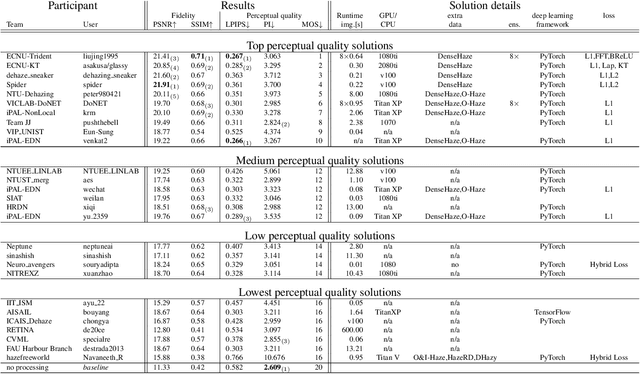
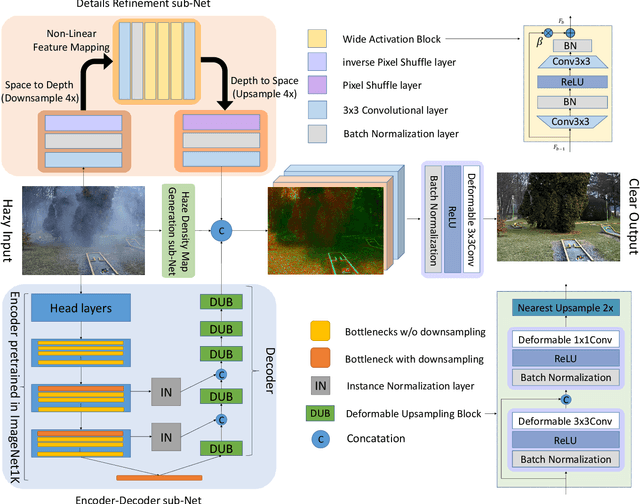
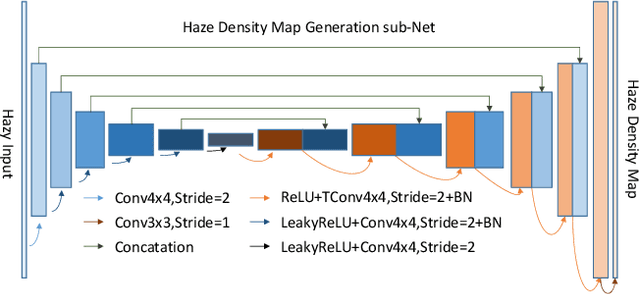
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.
What can computational models learn from human selective attention? A review from an audiovisual crossmodal perspective
Sep 05, 2019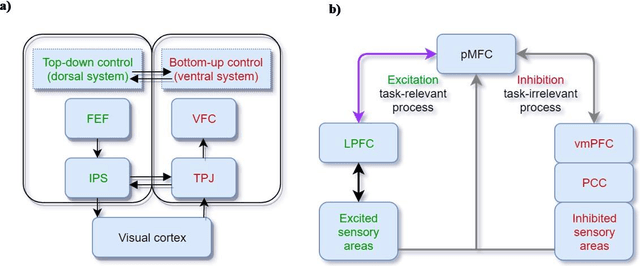

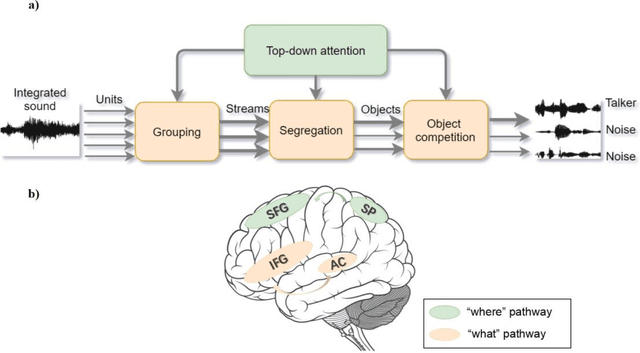
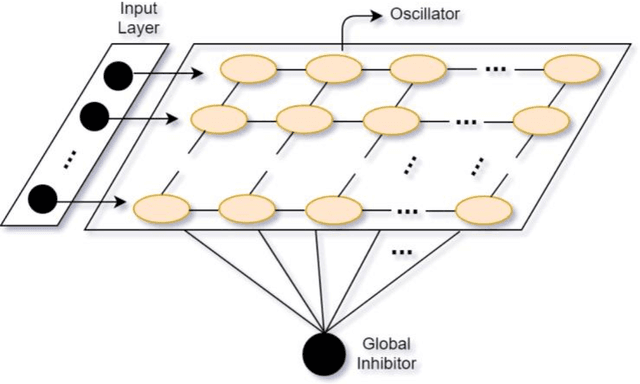
Selective attention plays an essential role in information acquisition and utilization from the environment. In the past 50 years, research on selective attention has been a central topic in cognitive science. Compared with unimodal studies, crossmodal studies are more complex but necessary to solve real-world challenges in both human experiments and computational modeling. Although an increasing number of findings on crossmodal selective attention have shed light on humans' behavioral patterns and neural underpinnings, a much better understanding is still necessary to yield the same benefit for computational intelligent agents. This article reviews studies of selective attention in unimodal visual and auditory and crossmodal audiovisual setups from the multidisciplinary perspectives of psychology and cognitive neuroscience, and evaluates different ways to simulate analogous mechanisms in computational models and robotics. We discuss the gaps between these fields in this interdisciplinary review and provide insights about how to use psychological findings and theories in artificial intelligence from different perspectives.
Modeling and Interpreting Real-world Human Risk Decision Making with Inverse Reinforcement Learning
Jun 13, 2019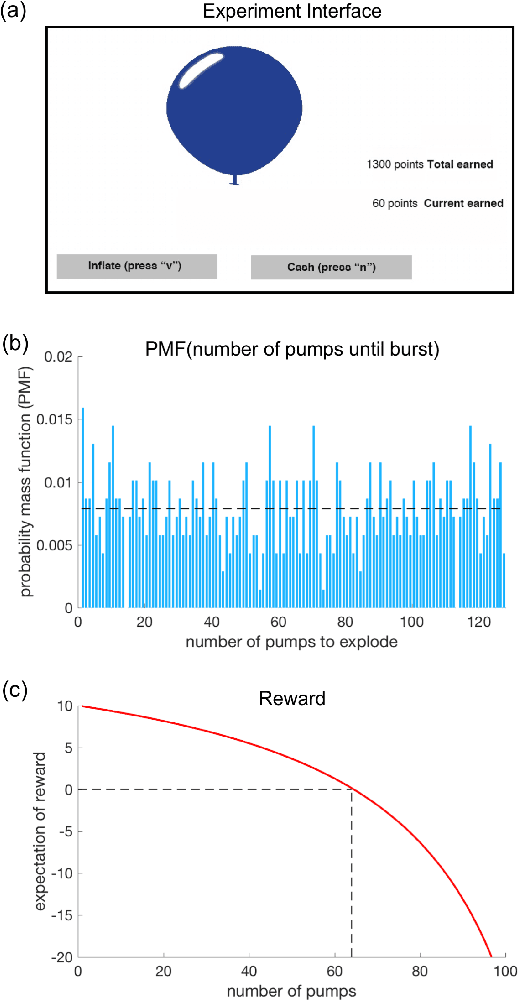

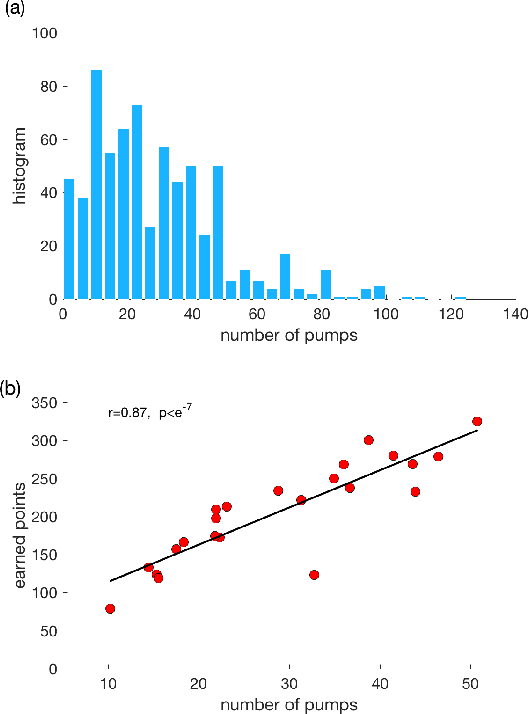
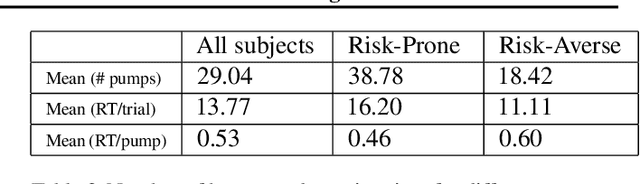
We model human decision-making behaviors in a risk-taking task using inverse reinforcement learning (IRL) for the purposes of understanding real human decision making under risk. To the best of our knowledge, this is the first work applying IRL to reveal the implicit reward function in human risk-taking decision making and to interpret risk-prone and risk-averse decision-making policies. We hypothesize that the state history (e.g. rewards and decisions in previous trials) are related to the human reward function, which leads to risk-averse and risk-prone decisions. We design features that reflect these factors in the reward function of IRL and learn the corresponding weight that is interpretable as the importance of features. The results confirm the sub-optimal risk-related decisions of human-driven by the personalized reward function. In particular, the risk-prone person tends to decide based on the current pump number, while the risk-averse person relies on burst information from the previous trial and the average end status. Our results demonstrate that IRL is an effective tool to model human decision-making behavior, as well as to help interpret the human psychological process in risk decision-making.
Assessing the Contribution of Semantic Congruency to Multisensory Integration and Conflict Resolution
Oct 15, 2018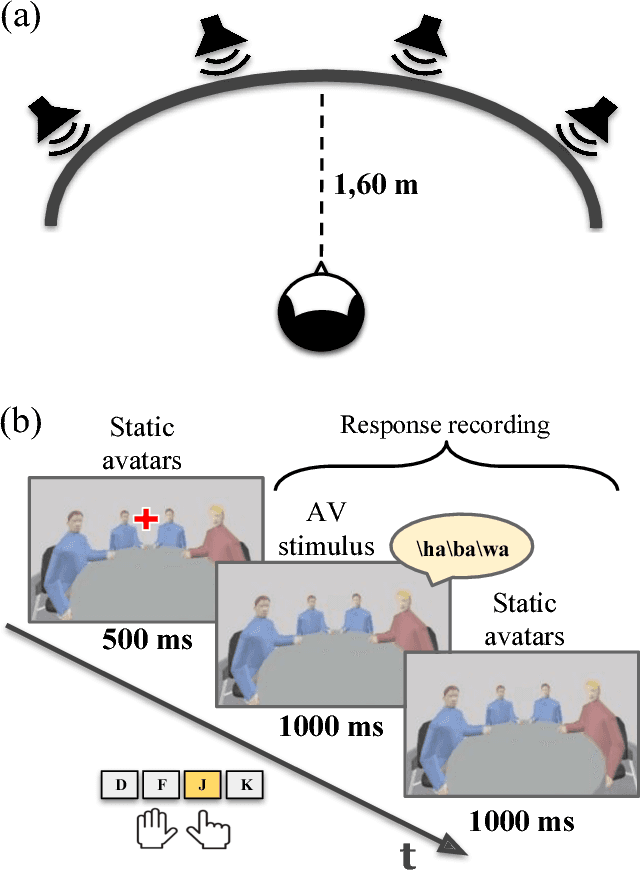
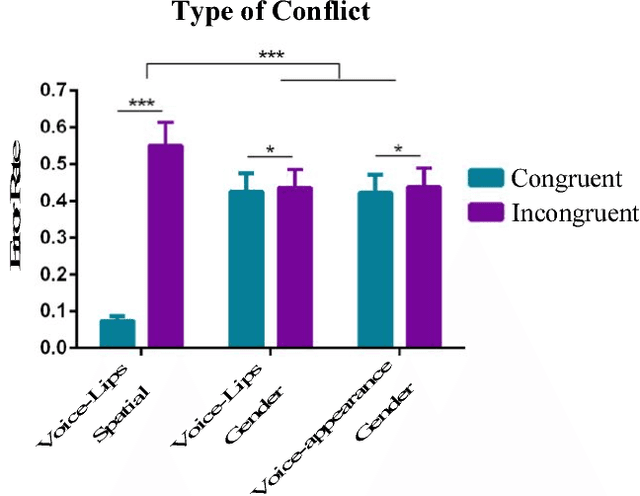
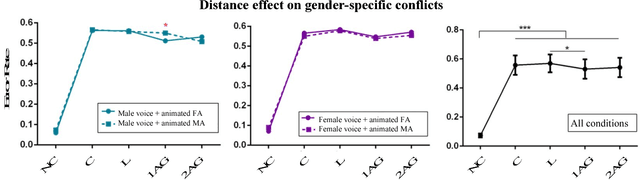
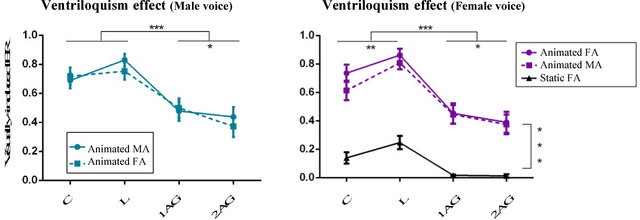
The efficient integration of multisensory observations is a key property of the brain that yields the robust interaction with the environment. However, artificial multisensory perception remains an open issue especially in situations of sensory uncertainty and conflicts. In this work, we extend previous studies on audio-visual (AV) conflict resolution in complex environments. In particular, we focus on quantitatively assessing the contribution of semantic congruency during an AV spatial localization task. In addition to conflicts in the spatial domain (i.e. spatially misaligned stimuli), we consider gender-specific conflicts with male and female avatars. Our results suggest that while semantically related stimuli affect the magnitude of the visual bias (perceptually shifting the location of the sound towards a semantically congruent visual cue), humans still strongly rely on environmental statistics to solve AV conflicts. Together with previously reported results, this work contributes to a better understanding of how multisensory integration and conflict resolution can be modelled in artificial agents and robots operating in real-world environments.
A Neurorobotic Experiment for Crossmodal Conflict Resolution in Complex Environments
Sep 24, 2018
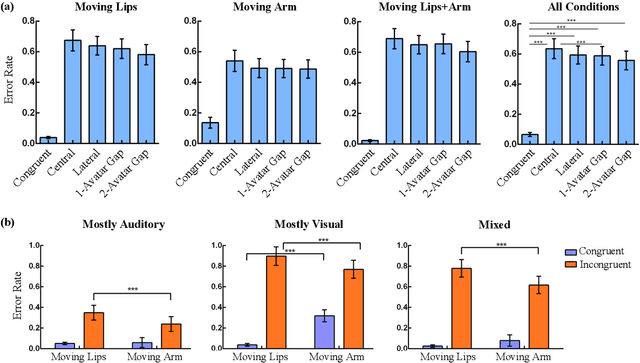
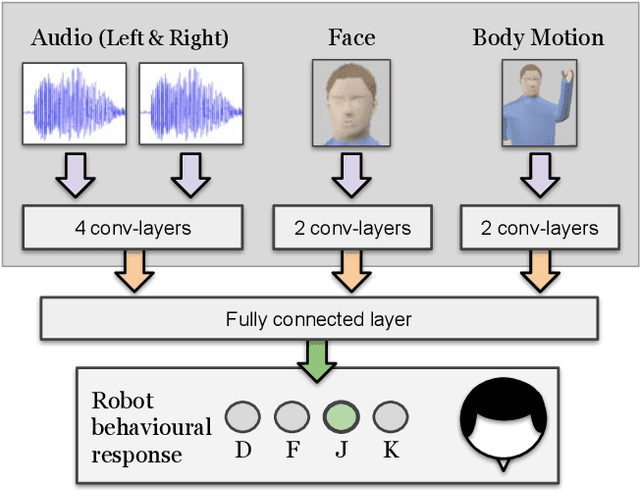
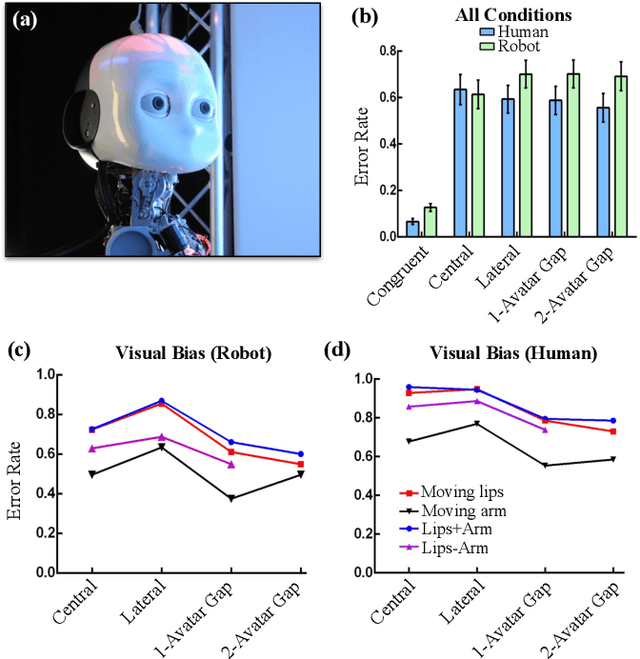
Crossmodal conflict resolution is crucial for robot sensorimotor coupling through the interaction with the environment, yielding swift and robust behaviour also in noisy conditions. In this paper, we propose a neurorobotic experiment in which an iCub robot exhibits human-like responses in a complex crossmodal environment. To better understand how humans deal with multisensory conflicts, we conducted a behavioural study exposing 33 subjects to congruent and incongruent dynamic audio-visual cues. In contrast to previous studies using simplified stimuli, we designed a scenario with four animated avatars and observed that the magnitude and extension of the visual bias are related to the semantics embedded in the scene, i.e., visual cues that are congruent with environmental statistics (moving lips and vocalization) induce the strongest bias. We implement a deep learning model that processes stereophonic sound, facial features, and body motion to trigger a discrete behavioural response. After training the model, we exposed the iCub to the same experimental conditions as the human subjects, showing that the robot can replicate similar responses in real time. Our interdisciplinary work provides important insights into how crossmodal conflict resolution can be modelled in robots and introduces future research directions for the efficient combination of sensory observations with internally generated knowledge and expectations.