 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Full Constituency Parsing with Neighboring Distribution Divergence
Oct 29, 2021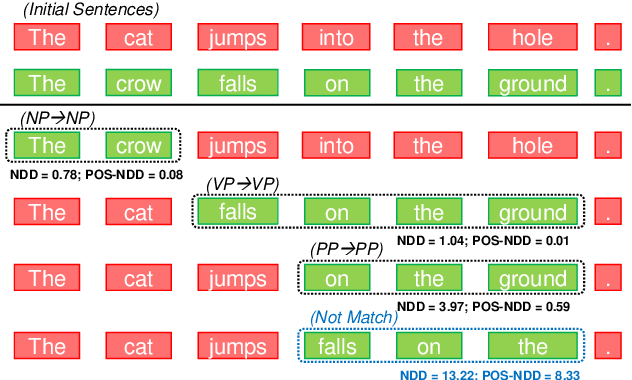


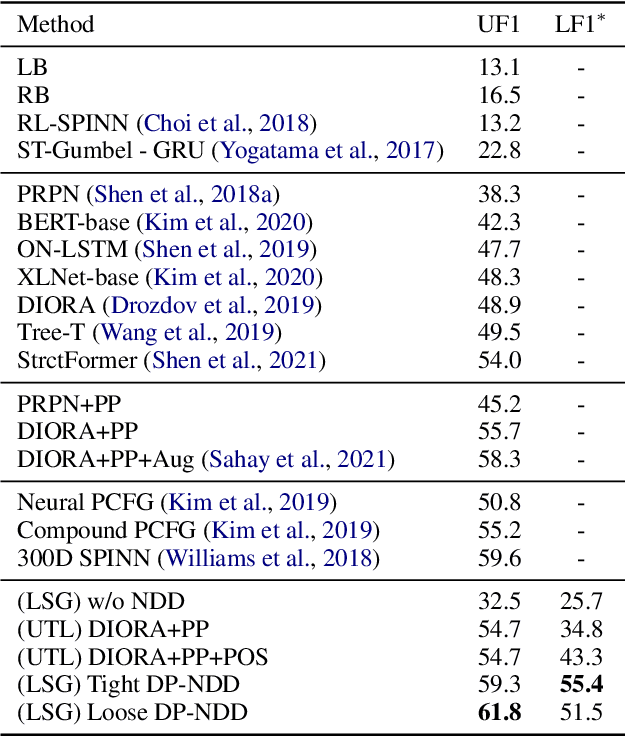
Unsupervised constituency parsing has been explored much but is still far from being solved. Conventional unsupervised constituency parser is only able to capture the unlabeled structure of sentences. Towards unsupervised full constituency parsing, we propose an unsupervised and training-free labeling procedure by exploiting the property of a recently introduced metric, Neighboring Distribution Divergence (NDD), which evaluates semantic similarity between sentences before and after editions. For implementation, we develop NDD into Dual POS-NDD (DP-NDD) and build "molds" to detect constituents and their labels in sentences. We show that DP-NDD not only labels constituents precisely but also inducts more accurate unlabeled constituency trees than all previous unsupervised methods with simpler rules. With two frameworks for labeled constituency trees inference, we set both the new state-of-the-art for unlabeled F1 and strong baselines for labeled F1. In contrast with the conventional predicting-and-evaluating scenario, our method acts as an plausible example to inversely apply evaluating metrics for prediction.
Structural Modeling for Dialogue Disentanglement
Oct 15, 2021
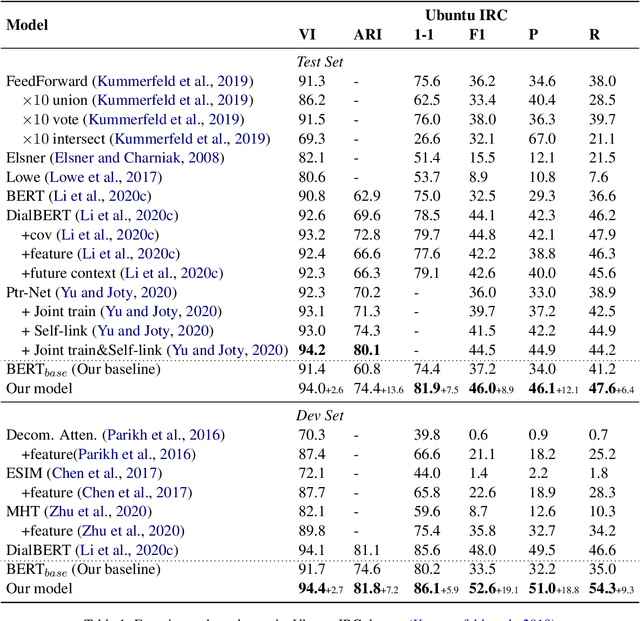
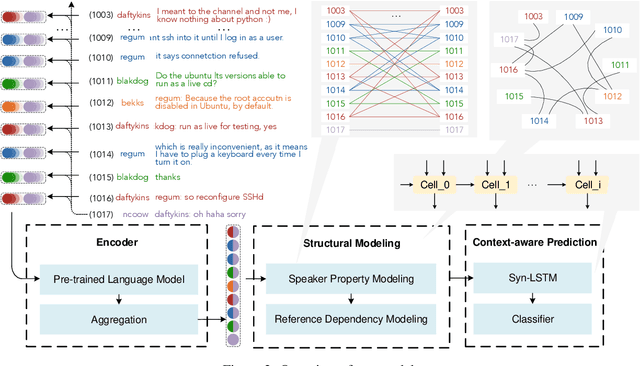

Tangled multi-party dialogue context leads to challenges for dialogue reading comprehension, where multiple dialogue threads flow simultaneously within the same dialogue history, thus increasing difficulties in understanding a dialogue history for both human and machine. Dialogue disentanglement aims to clarify conversation threads in a multi-party dialogue history, thus reducing the difficulty of comprehending the long disordered dialogue passage. Existing studies commonly focus on utterance encoding with carefully designed feature engineering-based methods but pay inadequate attention to dialogue structure. This work designs a novel model to disentangle multi-party history into threads, by taking dialogue structure features into account. Specifically, based on the fact that dialogues are constructed through successive participation of speakers and interactions between users of interest, we extract clues of speaker property and reference of users to model the structure of a long dialogue record. The novel method is evaluated on the Ubuntu IRC dataset and shows state-of-the-art experimental results in dialogue disentanglement.
Tracing Origins: Coref-aware Machine Reading Comprehension
Oct 15, 2021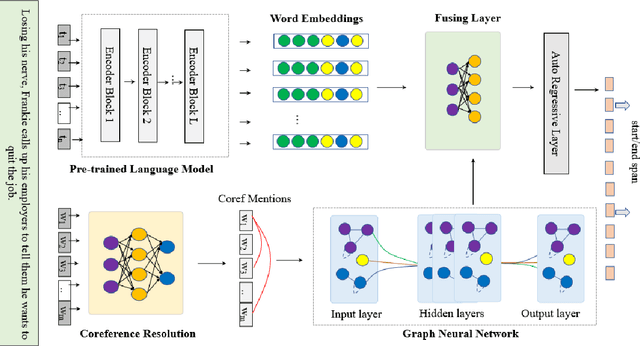

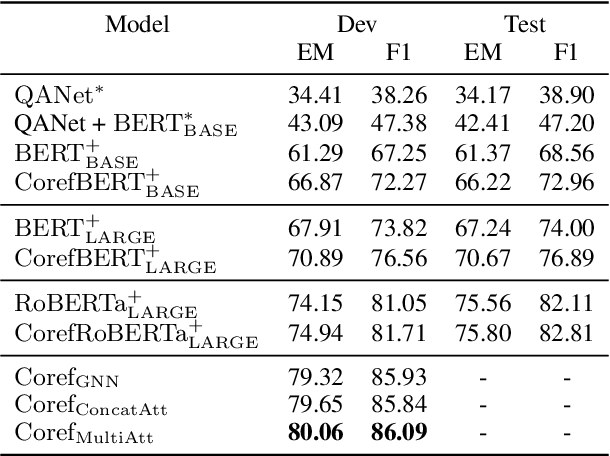
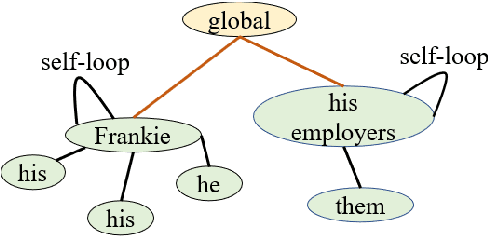
Machine reading comprehension is a heavily-studied research and test field for evaluating new pre-trained models and fine-tuning strategies, and recent studies have enriched the pre-trained models with syntactic, semantic and other linguistic information to improve the performance of the model. In this paper, we imitated the human's reading process in connecting the anaphoric expressions and explicitly leverage the coreference information to enhance the word embeddings from the pre-trained model, in order to highlight the coreference mentions that must be identified for coreference-intensive question answering in QUOREF, a relatively new dataset that is specifically designed to evaluate the coreference-related performance of a model. We used an additional BERT layer to focus on the coreference mentions, and a Relational Graph Convolutional Network to model the coreference relations. We demonstrated that the explicit incorporation of the coreference information in fine-tuning stage performed better than the incorporation of the coreference information in training a pre-trained language models.
Representation Decoupling for Open-Domain Passage Retrieval
Oct 14, 2021
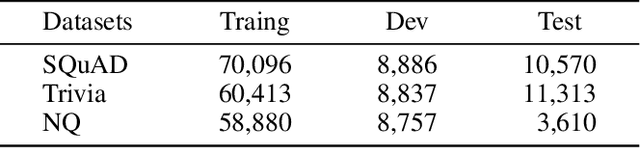
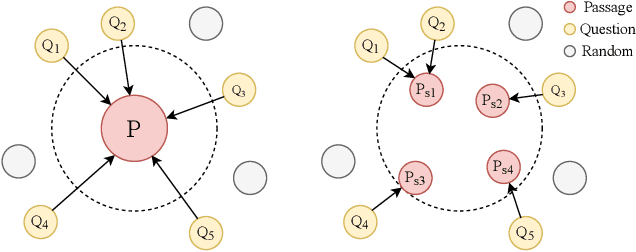

Training dense passage representations via contrastive learning (CL) has been shown effective for Open-Domain Passage Retrieval (ODPR). Recent studies mainly focus on optimizing this CL framework by improving the sampling strategy or extra pretraining. Different from previous studies, this work devotes itself to investigating the influence of conflicts in the widely used CL strategy in ODPR, motivated by our observation that a passage can be organized by multiple semantically different sentences, thus modeling such a passage as a unified dense vector is not optimal. We call such conflicts Contrastive Conflicts. In this work, we propose to solve it with a representation decoupling method, by decoupling the passage representations into contextual sentence-level ones, and design specific CL strategies to mediate these conflicts. Experiments on widely used datasets including Natural Questions, Trivia QA, and SQuAD verify the effectiveness of our method, especially on the dataset where the conflicting problem is severe. Our method also presents good transferability across the datasets, which further supports our idea of mediating Contrastive Conflicts.
Advances in Multi-turn Dialogue Comprehension: A Survey
Oct 12, 2021

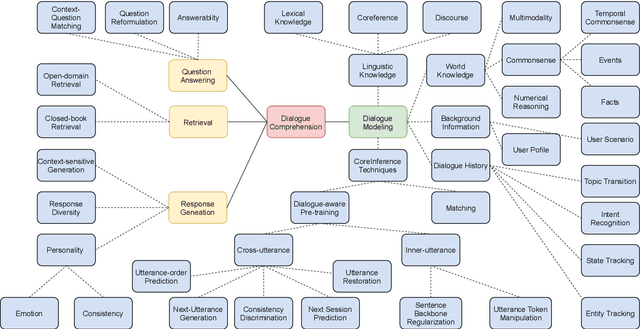
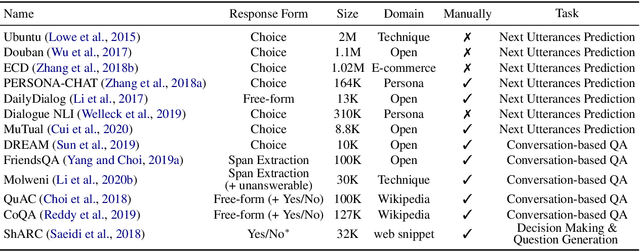
Training machines to understand natural language and interact with humans is an elusive and essential task of artificial intelligence. A diversity of dialogue systems has been designed with the rapid development of deep learning techniques, especially the recent pre-trained language models (PrLMs). Among these studies, the fundamental yet challenging type of task is dialogue comprehension whose role is to teach the machines to read and comprehend the dialogue context before responding. In this paper, we review the previous methods from the technical perspective of dialogue modeling for the dialogue comprehension task. We summarize the characteristics and challenges of dialogue comprehension in contrast to plain-text reading comprehension. Then, we discuss three typical patterns of dialogue modeling. In addition, we categorize dialogue-related pre-training techniques which are employed to enhance PrLMs in dialogue scenarios. Finally, we highlight the technical advances in recent years and point out the lessons from the empirical analysis and the prospects towards a new frontier of researches.
Multi-tasking Dialogue Comprehension with Discourse Parsing
Oct 07, 2021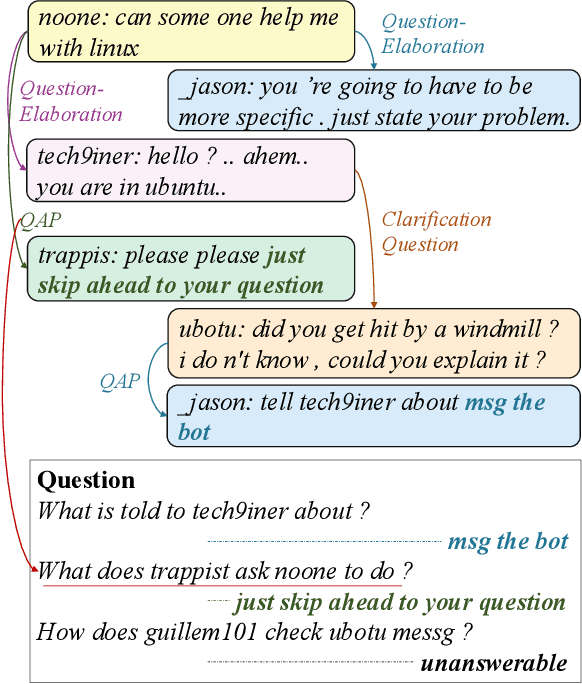
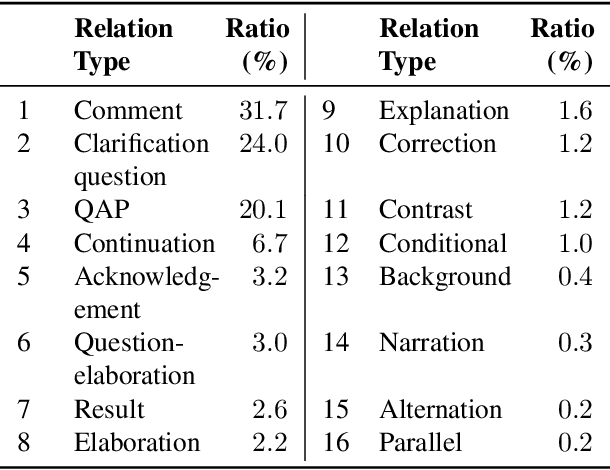
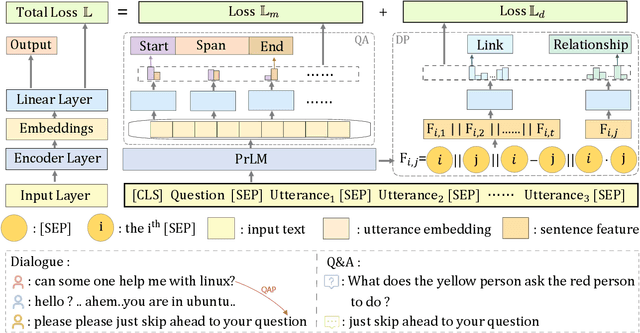
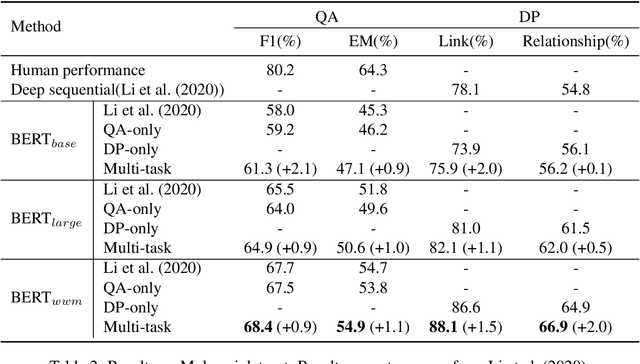
Multi-party dialogue machine reading comprehension (MRC) raises an even more challenging understanding goal on dialogue with more than two involved speakers, compared with the traditional plain passage style MRC. To accurately perform the question-answering (QA) task according to such multi-party dialogue, models have to handle fundamentally different discourse relationships from common non-dialogue plain text, where discourse relations are supposed to connect two far apart utterances in a linguistics-motivated way.To further explore the role of such unusual discourse structure on the correlated QA task in terms of MRC, we propose the first multi-task model for jointly performing QA and discourse parsing (DP) on the multi-party dialogue MRC task. Our proposed model is evaluated on the latest benchmark Molweni, whose results indicate that training with complementary tasks indeed benefits not only QA task, but also DP task itself. We further find that the joint model is distinctly stronger when handling longer dialogues which again verifies the necessity of DP in the related MRC.
A Novel Metric for Evaluating Semantics Preservation
Oct 04, 2021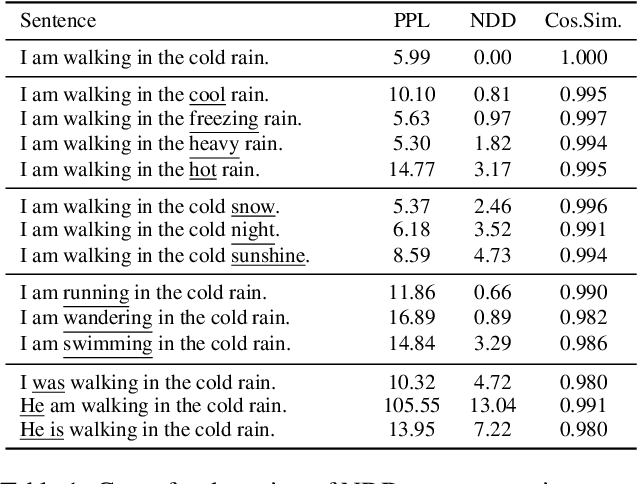
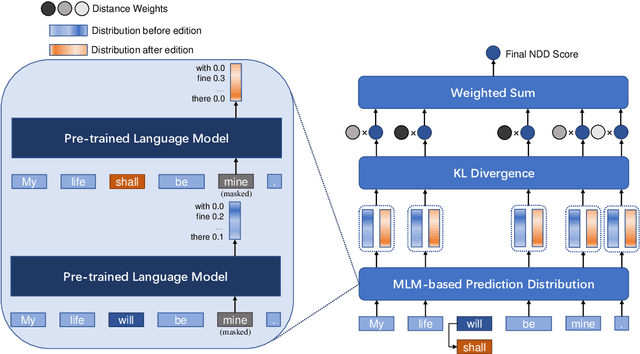
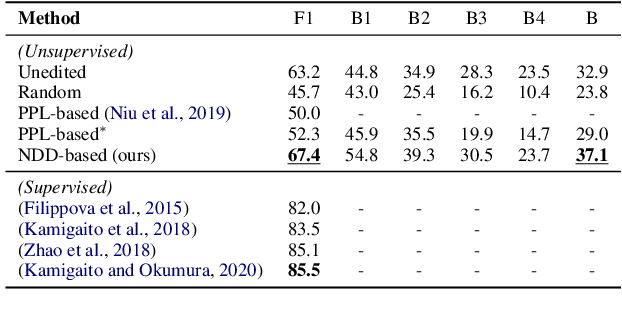

In this paper, we leverage pre-trained language models (PLMs) to precisely evaluate the semantics preservation of edition process on sentences. Our metric, Neighbor Distribution Divergence (NDD), evaluates the disturbance on predicted distribution of neighboring words from mask language model (MLM). NDD is capable of detecting precise changes in semantics which are easily ignored by text similarity. By exploiting the property of NDD, we implement a unsupervised and even training-free algorithm for extractive sentence compression. We show that our NDD-based algorithm outperforms previous perplexity-based unsupervised algorithm by a large margin. For further exploration on interpretability, we evaluate NDD by pruning on syntactic dependency treebanks and apply NDD for predicate detection as well.
Sparse Fuzzy Attention for Structured Sentiment Analysis
Sep 25, 2021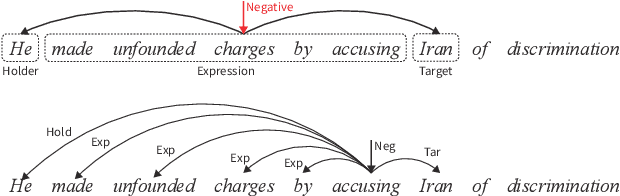
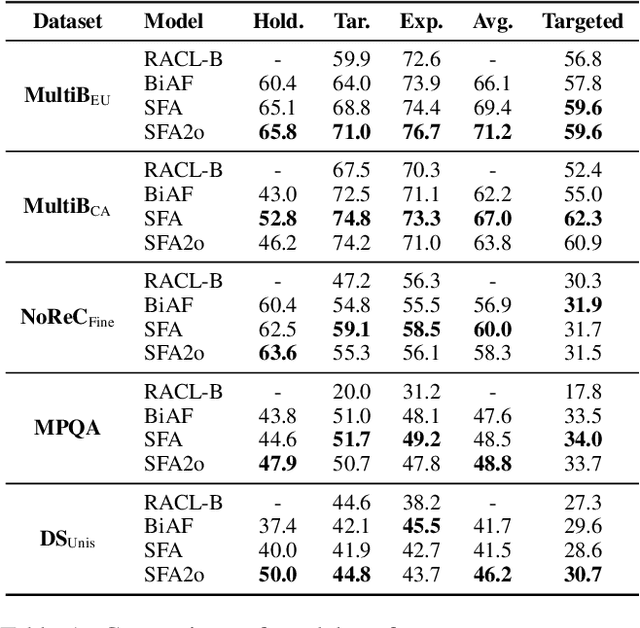
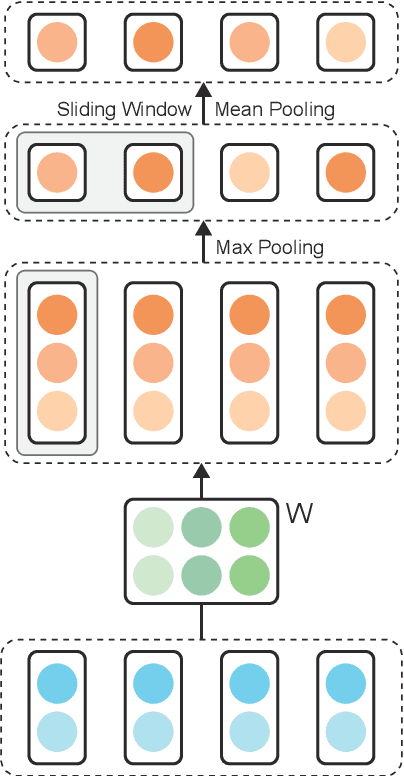
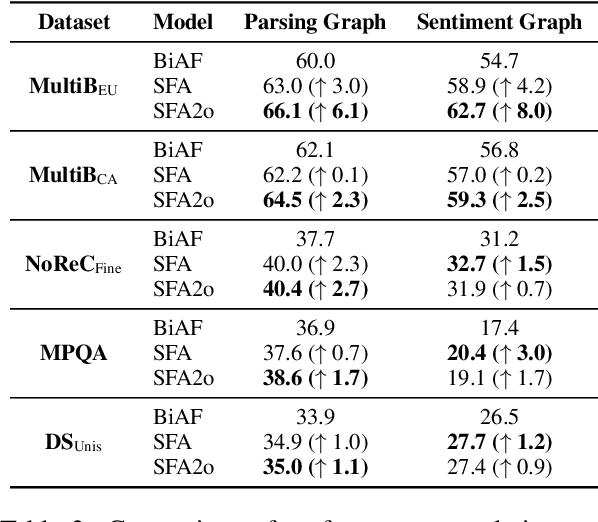
Attention scorers have achieved success in parsing tasks like semantic and syntactic dependency parsing. However, in tasks modeled into parsing, like structured sentiment analysis, "dependency edges" are very sparse which hinders parser performance. Thus we propose a sparse and fuzzy attention scorer with pooling layers which improves parser performance and sets the new state-of-the-art on structured sentiment analysis. We further explore the parsing modeling on structured sentiment analysis with second-order parsing and introduce a novel sparse second-order edge building procedure that leads to significant improvement in parsing performance.
Self- and Pseudo-self-supervised Prediction of Speaker and Key-utterance for Multi-party Dialogue Reading Comprehension
Sep 16, 2021
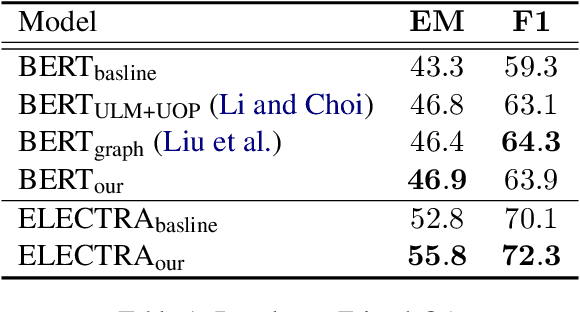
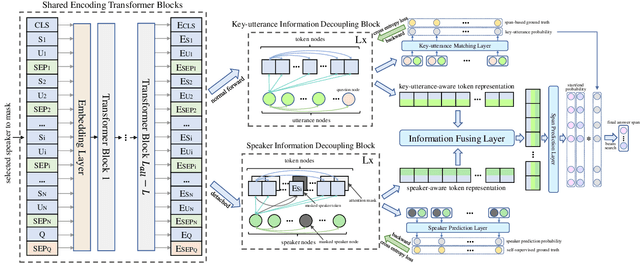
Multi-party dialogue machine reading comprehension (MRC) brings tremendous challenge since it involves multiple speakers at one dialogue, resulting in intricate speaker information flows and noisy dialogue contexts. To alleviate such difficulties, previous models focus on how to incorporate these information using complex graph-based modules and additional manually labeled data, which is usually rare in real scenarios. In this paper, we design two labour-free self- and pseudo-self-supervised prediction tasks on speaker and key-utterance to implicitly model the speaker information flows, and capture salient clues in a long dialogue. Experimental results on two benchmark datasets have justified the effectiveness of our method over competitive baselines and current state-of-the-art models.
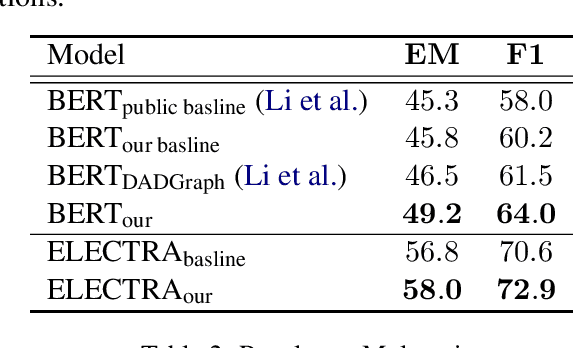
Enhanced Speaker-aware Multi-party Multi-turn Dialogue Comprehension
Sep 09, 2021
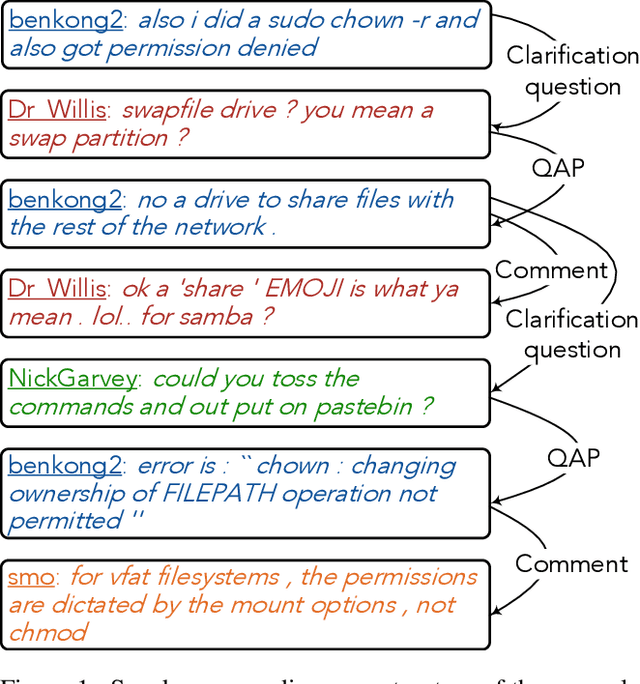
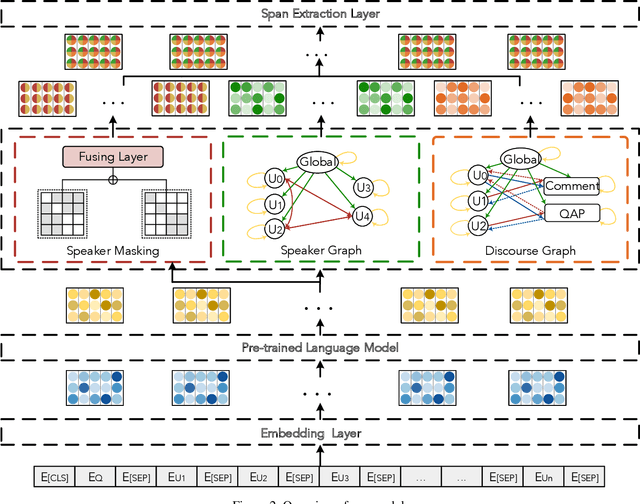

Multi-party multi-turn dialogue comprehension brings unprecedented challenges on handling the complicated scenarios from multiple speakers and criss-crossed discourse relationship among speaker-aware utterances. Most existing methods deal with dialogue contexts as plain texts and pay insufficient attention to the crucial speaker-aware clues. In this work, we propose an enhanced speaker-aware model with masking attention and heterogeneous graph networks to comprehensively capture discourse clues from both sides of speaker property and speaker-aware relationships. With such comprehensive speaker-aware modeling, experimental results show that our speaker-aware model helps achieves state-of-the-art performance on the benchmark dataset Molweni. Case analysis shows that our model enhances the connections between utterances and their own speakers and captures the speaker-aware discourse relations, which are critical for dialogue modeling.