 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey: Collaborative Hardware and Software Design in the Era of Large Language Models
Oct 08, 2024

The rapid development of large language models (LLMs) has significantly transformed the field of artificial intelligence, demonstrating remarkable capabilities in natural language processing and moving towards multi-modal functionality. These models are increasingly integrated into diverse applications, impacting both research and industry. However, their development and deployment present substantial challenges, including the need for extensive computational resources, high energy consumption, and complex software optimizations. Unlike traditional deep learning systems, LLMs require unique optimization strategies for training and inference, focusing on system-level efficiency. This paper surveys hardware and software co-design approaches specifically tailored to address the unique characteristics and constraints of large language models. This survey analyzes the challenges and impacts of LLMs on hardware and algorithm research, exploring algorithm optimization, hardware design, and system-level innovations. It aims to provide a comprehensive understanding of the trade-offs and considerations in LLM-centric computing systems, guiding future advancements in AI. Finally, we summarize the existing efforts in this space and outline future directions toward realizing production-grade co-design methodologies for the next generation of large language models and AI systems.
FedProphet: Memory-Efficient Federated Adversarial Training via Theoretic-Robustness and Low-Inconsistency Cascade Learning
Sep 12, 2024



Federated Learning (FL) provides a strong privacy guarantee by enabling local training across edge devices without training data sharing, and Federated Adversarial Training (FAT) further enhances the robustness against adversarial examples, promoting a step toward trustworthy artificial intelligence. However, FAT requires a large model to preserve high accuracy while achieving strong robustness, and it is impractically slow when directly training with memory-constrained edge devices due to the memory-swapping latency. Moreover, existing memory-efficient FL methods suffer from poor accuracy and weak robustness in FAT because of inconsistent local and global models, i.e., objective inconsistency. In this paper, we propose FedProphet, a novel FAT framework that can achieve memory efficiency, adversarial robustness, and objective consistency simultaneously. FedProphet partitions the large model into small cascaded modules such that the memory-constrained devices can conduct adversarial training module-by-module. A strong convexity regularization is derived to theoretically guarantee the robustness of the whole model, and we show that the strong robustness implies low objective inconsistency in FedProphet. We also develop a training coordinator on the server of FL, with Adaptive Perturbation Adjustment for utility-robustness balance and Differentiated Module Assignment for objective inconsistency mitigation. FedProphet empirically shows a significant improvement in both accuracy and robustness compared to previous memory-efficient methods, achieving almost the same performance of end-to-end FAT with 80% memory reduction and up to 10.8x speedup in training time.
FedGP: Correlation-Based Active Client Selection for Heterogeneous Federated Learning
Mar 24, 2021
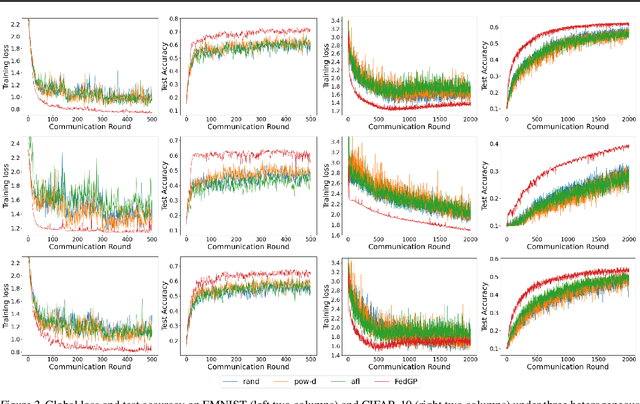
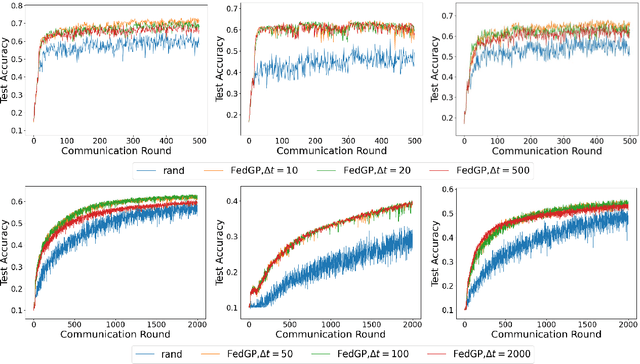
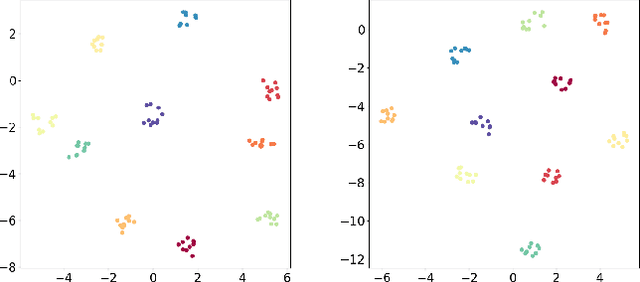
Client-wise heterogeneity is one of the major issues that hinder effective training in federated learning (FL). Since the data distribution on each client may differ dramatically, the client selection strategy can largely influence the convergence rate of the FL process. Several recent studies adopt active client selection strategies. However, they neglect the loss correlations between the clients and achieve marginal improvement compared to the uniform selection strategy. In this work, we propose FedGP -- a federated learning framework built on a correlation-based client selection strategy, to boost the convergence rate of FL. Specifically, we first model the loss correlations between the clients with a Gaussian Process (GP). To make the GP training feasible in the communication-bounded FL process, we develop a GP training method utilizing the historical samples efficiently to reduce the communication cost. Finally, based on the correlations we learned, we derive the client selection with an enlarged reduction of expected global loss in each round. Our experimental results show that compared to the latest active client selection strategy, FedGP can improve the convergence rates by $1.3\sim2.3\times$ and $1.2\sim1.4\times$ on FMNIST and CIFAR-10, respectively.
Exploring Bit-Slice Sparsity in Deep Neural Networks for Efficient ReRAM-Based Deployment
Sep 18, 2019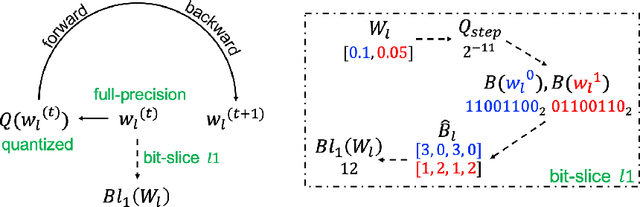
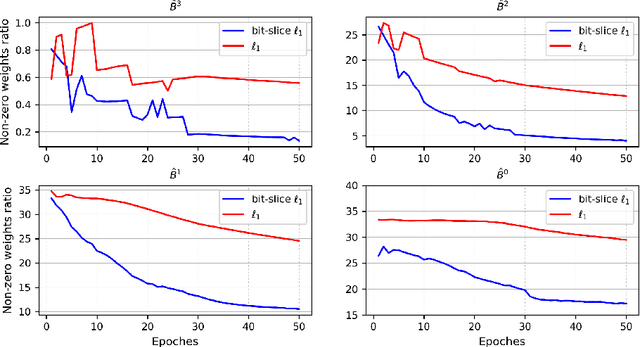
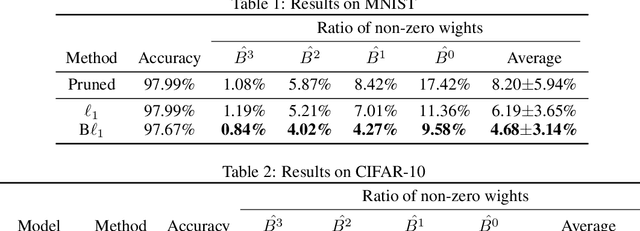

Emerging resistive random-access memory (ReRAM) has recently been intensively investigated to accelerate the processing of deep neural networks (DNNs). Due to the in-situ computation capability, analog ReRAM crossbars yield significant throughput improvement and energy reduction compared to traditional digital methods. However, the power hungry analog-to-digital converters (ADCs) prevent the practical deployment of ReRAM-based DNN accelerators on end devices with limited chip area and power budget. We observe that due to the limited bit-density of ReRAM cells, DNN weights are bit sliced and correspondingly stored on multiple ReRAM bitlines. The accumulated current on bitlines resulted by weights directly dictates the overhead of ADCs. As such, bitwise weight sparsity rather than the sparsity of the full weight, is desirable for efficient ReRAM deployment. In this work, we propose bit-slice L1, the first algorithm to induce bit-slice sparsity during the training of dynamic fixed-point DNNs. Experiment results show that our approach achieves 2x sparsity improvement compared to previous algorithms. The resulting sparsity allows the ADC resolution to be reduced to 1-bit of the most significant bit-slice and down to 3-bit for the others bits, which significantly speeds up processing and reduces power and area overhead.