 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Can Learned Intrinsic Rewards Capture?
Dec 11, 2019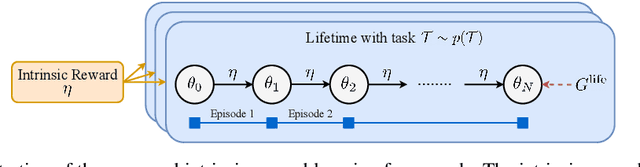
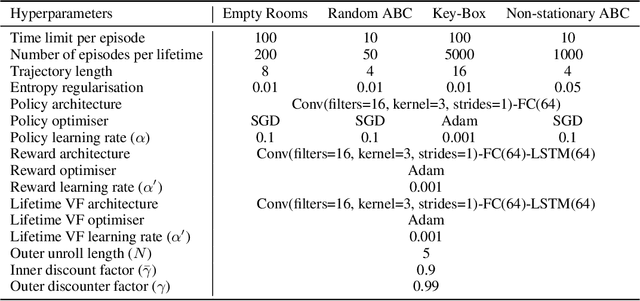
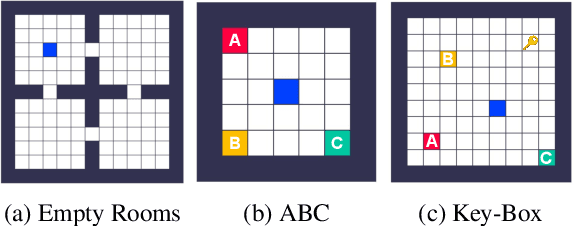
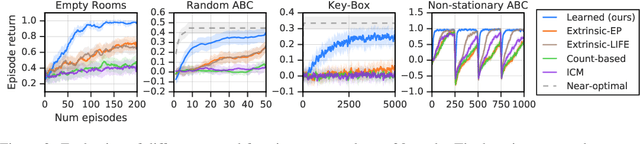
Reinforcement learning agents can include different components, such as policies, value functions, state representations, and environment models. Any or all of these can be the loci of knowledge, i.e., structures where knowledge, whether given or learned, can be deposited and reused. The objective of an agent is to behave so as to maximise the sum of a suitable scalar function of state: the reward. As far as the learning algorithm is concerned, these rewards are typically given and immutable. In this paper we instead consider the proposition that the reward function itself may be a good locus of knowledge. This is consistent with a common use, in the literature, of hand-designed intrinsic rewards to improve the learning dynamics of an agent. We adopt the multi-lifetime setting of the Optimal Rewards Framework, and propose to meta-learn an intrinsic reward function from experience that allows agents to maximise their extrinsic rewards accumulated until the end of their lifetimes. Rewards as a locus of knowledge provide guidance on "what" the agent should strive to do rather than "how" the agent should behave; the latter is more directly captured in policies or value functions for example. Thus, our focus here is on demonstrating the following: (1) that it is feasible to meta-learn good reward functions, (2) that the learned reward functions can capture interesting kinds of "what" knowledge, and (3) that because of the indirectness of this form of knowledge the learned reward functions can generalise to other kinds of agents and to changes in the dynamics of the environment.
Hindsight Credit Assignment
Dec 05, 2019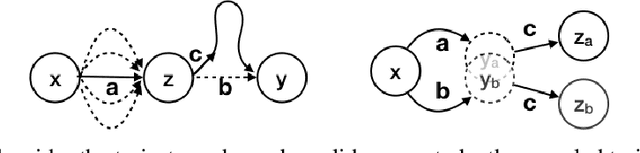

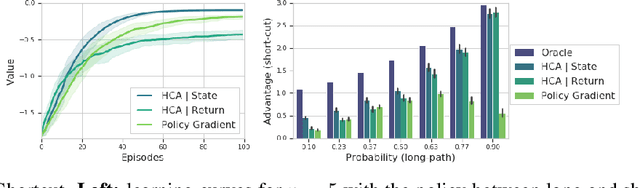
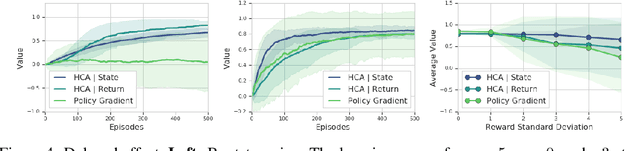
We consider the problem of efficient credit assignment in reinforcement learning. In order to efficiently and meaningfully utilize new data, we propose to explicitly assign credit to past decisions based on the likelihood of them having led to the observed outcome. This approach uses new information in hindsight, rather than employing foresight. Somewhat surprisingly, we show that value functions can be rewritten through this lens, yielding a new family of algorithms. We study the properties of these algorithms, and empirically show that they successfully address important credit assignment challenges, through a set of illustrative tasks.
Conditional Importance Sampling for Off-Policy Learning
Oct 16, 2019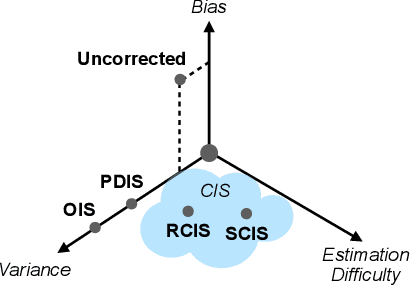

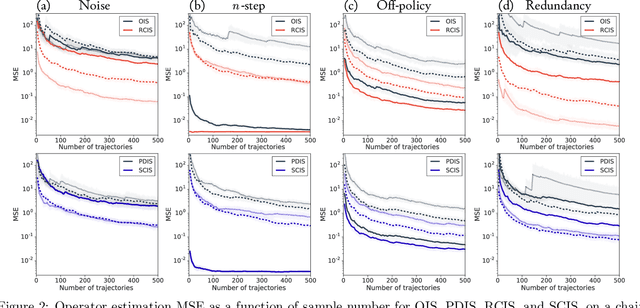
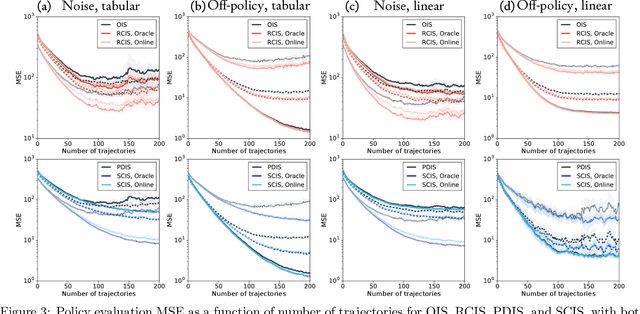
The principal contribution of this paper is a conceptual framework for off-policy reinforcement learning, based on conditional expectations of importance sampling ratios. This framework yields new perspectives and understanding of existing off-policy algorithms, and reveals a broad space of unexplored algorithms. We theoretically analyse this space, and concretely investigate several algorithms that arise from this framework.
Discovery of Useful Questions as Auxiliary Tasks
Sep 10, 2019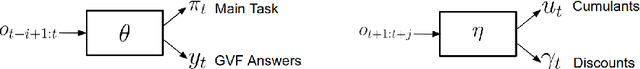

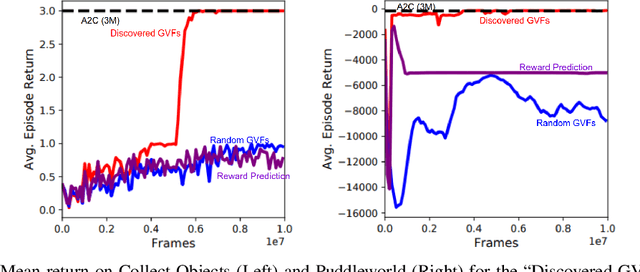
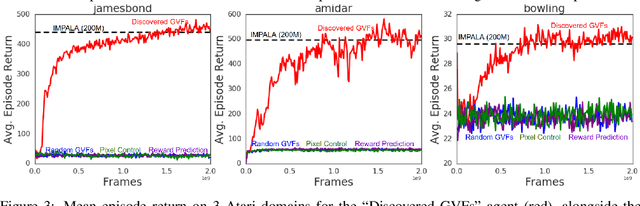
Arguably, intelligent agents ought to be able to discover their own questions so that in learning answers for them they learn unanticipated useful knowledge and skills; this departs from the focus in much of machine learning on agents learning answers to externally defined questions. We present a novel method for a reinforcement learning (RL) agent to discover questions formulated as general value functions or GVFs, a fairly rich form of knowledge representation. Specifically, our method uses non-myopic meta-gradients to learn GVF-questions such that learning answers to them, as an auxiliary task, induces useful representations for the main task faced by the RL agent. We demonstrate that auxiliary tasks based on the discovered GVFs are sufficient, on their own, to build representations that support main task learning, and that they do so better than popular hand-designed auxiliary tasks from the literature. Furthermore, we show, in the context of Atari 2600 videogames, how such auxiliary tasks, meta-learned alongside the main task, can improve the data efficiency of an actor-critic agent.
General non-linear Bellman equations
Jul 08, 2019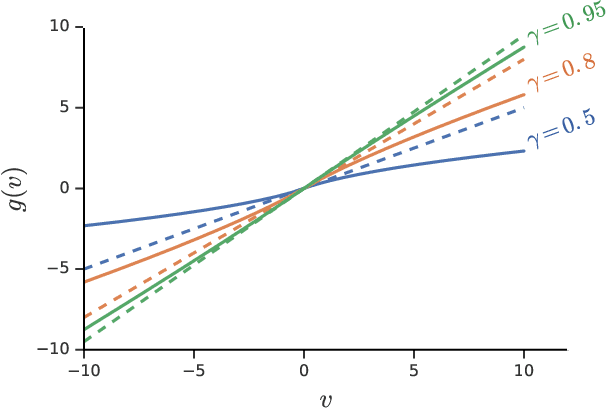
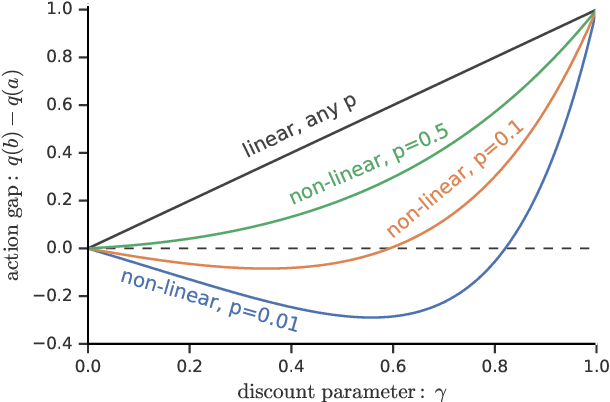
We consider a general class of non-linear Bellman equations. These open up a design space of algorithms that have interesting properties, which has two potential advantages. First, we can perhaps better model natural phenomena. For instance, hyperbolic discounting has been proposed as a mathematical model that matches human and animal data well, and can therefore be used to explain preference orderings. We present a different mathematical model that matches the same data, but that makes very different predictions under other circumstances. Second, the larger design space can perhaps lead to algorithms that perform better, similar to how discount factors are often used in practice even when the true objective is undiscounted. We show that many of the resulting Bellman operators still converge to a fixed point, and therefore that the resulting algorithms are reasonable and inherit many beneficial properties of their linear counterparts.
On Inductive Biases in Deep Reinforcement Learning
Jul 05, 2019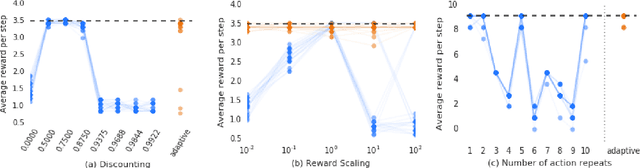
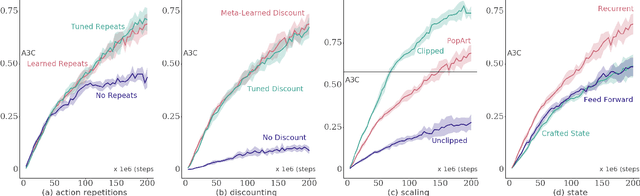
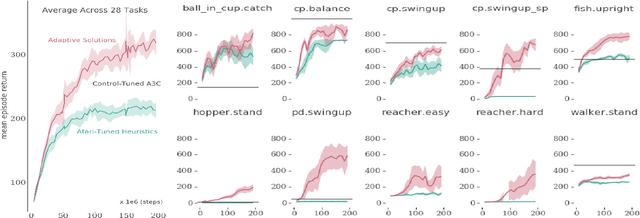
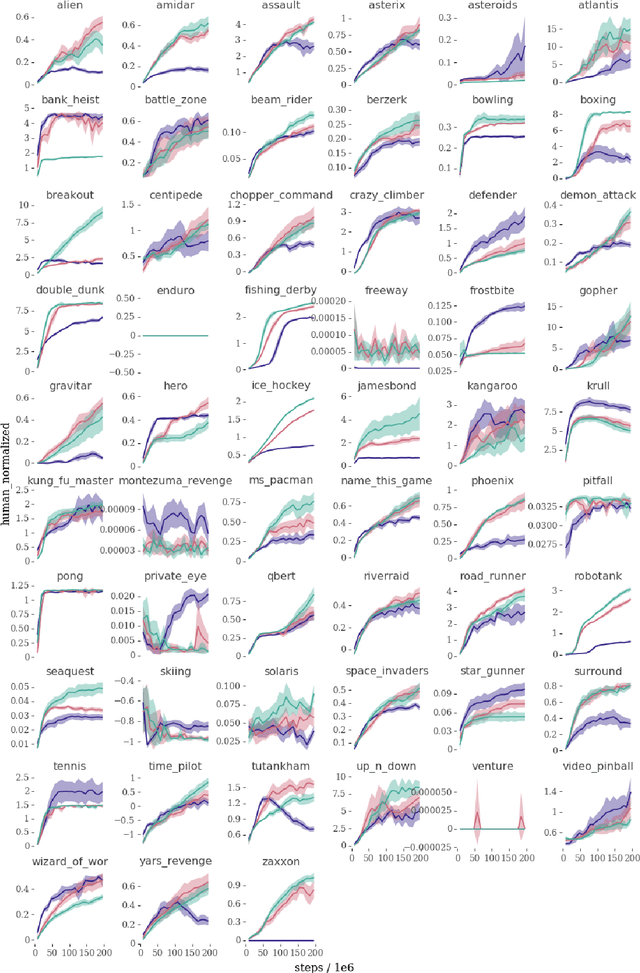
Many deep reinforcement learning algorithms contain inductive biases that sculpt the agent's objective and its interface to the environment. These inductive biases can take many forms, including domain knowledge and pretuned hyper-parameters. In general, there is a trade-off between generality and performance when algorithms use such biases. Stronger biases can lead to faster learning, but weaker biases can potentially lead to more general algorithms. This trade-off is important because inductive biases are not free; substantial effort may be required to obtain relevant domain knowledge or to tune hyper-parameters effectively. In this paper, we re-examine several domain-specific components that bias the objective and the environmental interface of common deep reinforcement learning agents. We investigated whether the performance deteriorates when these components are replaced with adaptive solutions from the literature. In our experiments, performance sometimes decreased with the adaptive components, as one might expect when comparing to components crafted for the domain, but sometimes the adaptive components performed better. We investigated the main benefit of having fewer domain-specific components, by comparing the learning performance of the two systems on a different set of continuous control problems, without additional tuning of either system. As hypothesized, the system with adaptive components performed better on many of the new tasks.
When to use parametric models in reinforcement learning?
Jun 12, 2019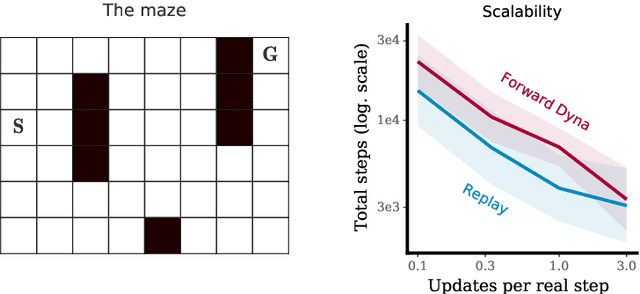
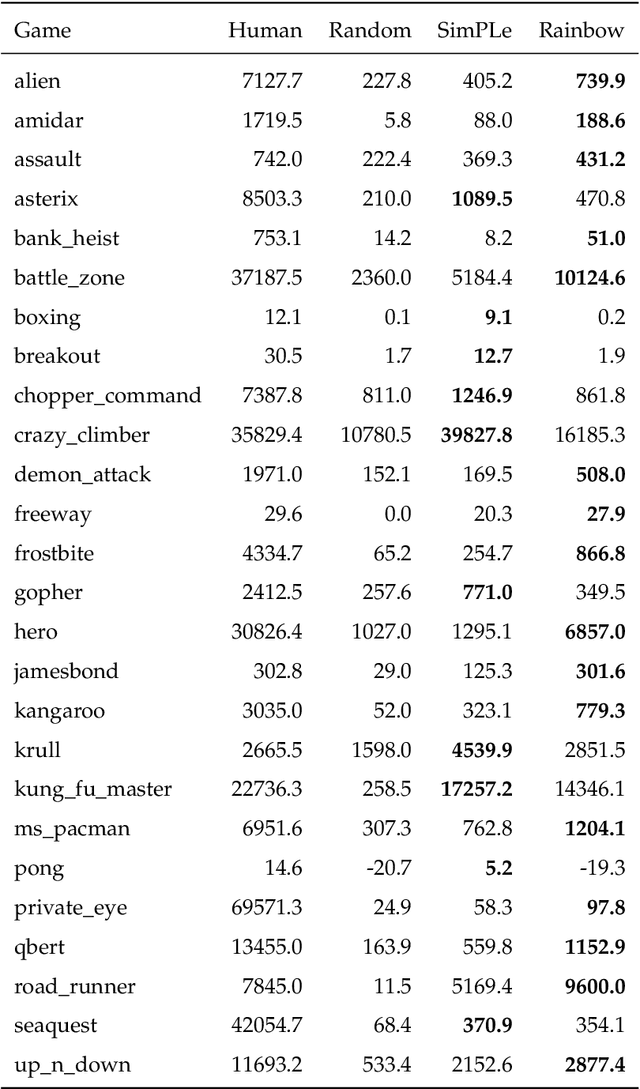
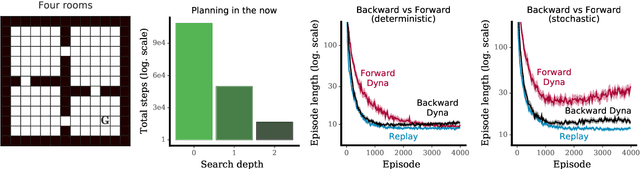

We examine the question of when and how parametric models are most useful in reinforcement learning. In particular, we look at commonalities and differences between parametric models and experience replay. Replay-based learning algorithms share important traits with model-based approaches, including the ability to plan: to use more computation without additional data to improve predictions and behaviour. We discuss when to expect benefits from either approach, and interpret prior work in this context. We hypothesise that, under suitable conditions, replay-based algorithms should be competitive to or better than model-based algorithms if the model is used only to generate fictional transitions from observed states for an update rule that is otherwise model-free. We validated this hypothesis on Atari 2600 video games. The replay-based algorithm attained state-of-the-art data efficiency, improving over prior results with parametric models.
Meta-learning of Sequential Strategies
May 08, 2019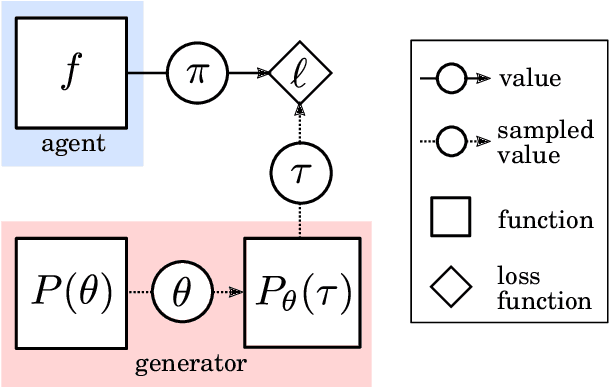
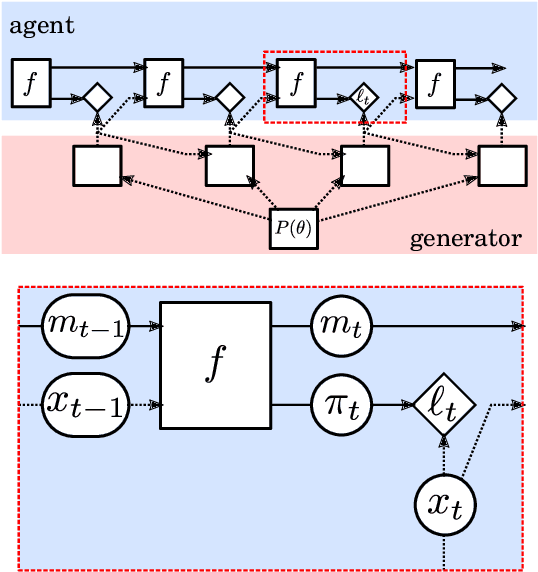
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Universal Successor Features Approximators
Dec 18, 2018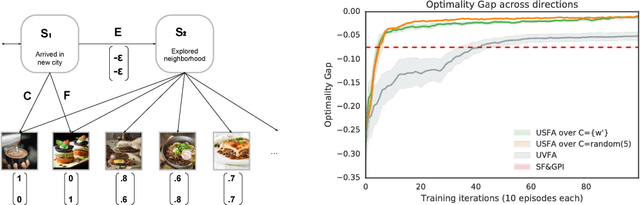

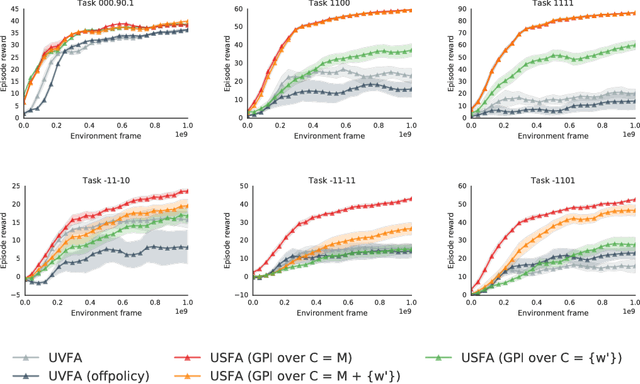

The ability of a reinforcement learning (RL) agent to learn about many reward functions at the same time has many potential benefits, such as the decomposition of complex tasks into simpler ones, the exchange of information between tasks, and the reuse of skills. We focus on one aspect in particular, namely the ability to generalise to unseen tasks. Parametric generalisation relies on the interpolation power of a function approximator that is given the task description as input; one of its most common form are universal value function approximators (UVFAs). Another way to generalise to new tasks is to exploit structure in the RL problem itself. Generalised policy improvement (GPI) combines solutions of previous tasks into a policy for the unseen task; this relies on instantaneous policy evaluation of old policies under the new reward function, which is made possible through successor features (SFs). Our proposed universal successor features approximators (USFAs) combine the advantages of all of these, namely the scalability of UVFAs, the instant inference of SFs, and the strong generalisation of GPI. We discuss the challenges involved in training a USFA, its generalisation properties and demonstrate its practical benefits and transfer abilities on a large-scale domain in which the agent has to navigate in a first-person perspective three-dimensional environment.
Deep Reinforcement Learning and the Deadly Triad
Dec 06, 2018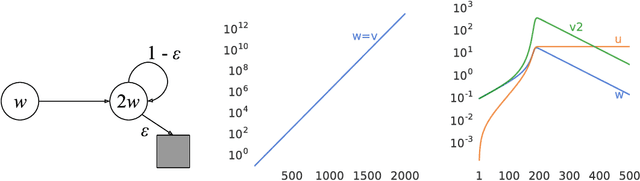
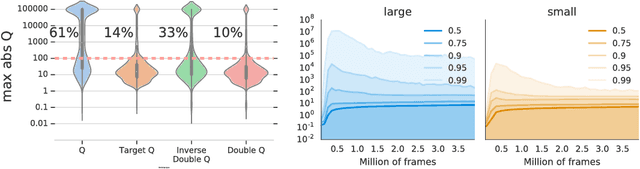
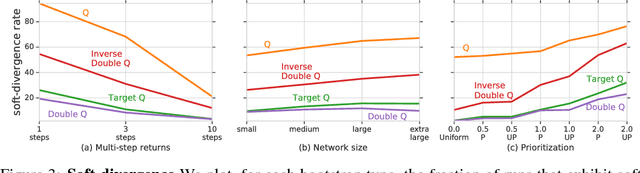
We know from reinforcement learning theory that temporal difference learning can fail in certain cases. Sutton and Barto (2018) identify a deadly triad of function approximation, bootstrapping, and off-policy learning. When these three properties are combined, learning can diverge with the value estimates becoming unbounded. However, several algorithms successfully combine these three properties, which indicates that there is at least a partial gap in our understanding. In this work, we investigate the impact of the deadly triad in practice, in the context of a family of popular deep reinforcement learning models - deep Q-networks trained with experience replay - analysing how the components of this system play a role in the emergence of the deadly triad, and in the agent's performance