 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoMan: Temporally Consistent Human Geometry Estimation using Image-to-Video Diffusion
May 29, 2025Estimating accurate and temporally consistent 3D human geometry from videos is a challenging problem in computer vision. Existing methods, primarily optimized for single images, often suffer from temporal inconsistencies and fail to capture fine-grained dynamic details. To address these limitations, we present GeoMan, a novel architecture designed to produce accurate and temporally consistent depth and normal estimations from monocular human videos. GeoMan addresses two key challenges: the scarcity of high-quality 4D training data and the need for metric depth estimation to accurately model human size. To overcome the first challenge, GeoMan employs an image-based model to estimate depth and normals for the first frame of a video, which then conditions a video diffusion model, reframing video geometry estimation task as an image-to-video generation problem. This design offloads the heavy lifting of geometric estimation to the image model and simplifies the video model's role to focus on intricate details while using priors learned from large-scale video datasets. Consequently, GeoMan improves temporal consistency and generalizability while requiring minimal 4D training data. To address the challenge of accurate human size estimation, we introduce a root-relative depth representation that retains critical human-scale details and is easier to be estimated from monocular inputs, overcoming the limitations of traditional affine-invariant and metric depth representations. GeoMan achieves state-of-the-art performance in both qualitative and quantitative evaluations, demonstrating its effectiveness in overcoming longstanding challenges in 3D human geometry estimation from videos.
PersonaCraft: Personalized Full-Body Image Synthesis for Multiple Identities from Single References Using 3D-Model-Conditioned Diffusion
Nov 27, 2024



Personalized image generation has been significantly advanced, enabling the creation of highly realistic and customized images. However, existing methods often struggle with generating images of multiple people due to occlusions and fail to accurately personalize full-body shapes. In this paper, we propose PersonaCraft, a novel approach that combines diffusion models with 3D human modeling to address these limitations. Our method effectively manages occlusions by incorporating 3D-aware pose conditioning with SMPLx-ControlNet and accurately personalizes human full-body shapes through SMPLx fitting. Additionally, PersonaCraft enables user-defined body shape adjustments, adding flexibility for individual body customization. Experimental results demonstrate the superior performance of PersonaCraft in generating high-quality, realistic images of multiple individuals while resolving occlusion issues, thus establishing a new standard for multi-person personalized image synthesis. Project page: https://gwang-kim.github.io/persona_craft
A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
May 22, 2024



Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
BeyondScene: Higher-Resolution Human-Centric Scene Generation With Pretrained Diffusion
Apr 06, 2024



Generating higher-resolution human-centric scenes with details and controls remains a challenge for existing text-to-image diffusion models. This challenge stems from limited training image size, text encoder capacity (limited tokens), and the inherent difficulty of generating complex scenes involving multiple humans. While current methods attempted to address training size limit only, they often yielded human-centric scenes with severe artifacts. We propose BeyondScene, a novel framework that overcomes prior limitations, generating exquisite higher-resolution (over 8K) human-centric scenes with exceptional text-image correspondence and naturalness using existing pretrained diffusion models. BeyondScene employs a staged and hierarchical approach to initially generate a detailed base image focusing on crucial elements in instance creation for multiple humans and detailed descriptions beyond token limit of diffusion model, and then to seamlessly convert the base image to a higher-resolution output, exceeding training image size and incorporating details aware of text and instances via our novel instance-aware hierarchical enlargement process that consists of our proposed high-frequency injected forward diffusion and adaptive joint diffusion. BeyondScene surpasses existing methods in terms of correspondence with detailed text descriptions and naturalness, paving the way for advanced applications in higher-resolution human-centric scene creation beyond the capacity of pretrained diffusion models without costly retraining. Project page: https://janeyeon.github.io/beyond-scene.
Detailed Human-Centric Text Description-Driven Large Scene Synthesis
Nov 30, 2023



Text-driven large scene image synthesis has made significant progress with diffusion models, but controlling it is challenging. While using additional spatial controls with corresponding texts has improved the controllability of large scene synthesis, it is still challenging to faithfully reflect detailed text descriptions without user-provided controls. Here, we propose DetText2Scene, a novel text-driven large-scale image synthesis with high faithfulness, controllability, and naturalness in a global context for the detailed human-centric text description. Our DetText2Scene consists of 1) hierarchical keypoint-box layout generation from the detailed description by leveraging large language model (LLM), 2) view-wise conditioned joint diffusion process to synthesize a large scene from the given detailed text with LLM-generated grounded keypoint-box layout and 3) pixel perturbation-based pyramidal interpolation to progressively refine the large scene for global coherence. Our DetText2Scene significantly outperforms prior arts in text-to-large scene synthesis qualitatively and quantitatively, demonstrating strong faithfulness with detailed descriptions, superior controllability, and excellent naturalness in a global context.
DITTO-NeRF: Diffusion-based Iterative Text To Omni-directional 3D Model
Apr 06, 2023The increasing demand for high-quality 3D content creation has motivated the development of automated methods for creating 3D object models from a single image and/or from a text prompt. However, the reconstructed 3D objects using state-of-the-art image-to-3D methods still exhibit low correspondence to the given image and low multi-view consistency. Recent state-of-the-art text-to-3D methods are also limited, yielding 3D samples with low diversity per prompt with long synthesis time. To address these challenges, we propose DITTO-NeRF, a novel pipeline to generate a high-quality 3D NeRF model from a text prompt or a single image. Our DITTO-NeRF consists of constructing high-quality partial 3D object for limited in-boundary (IB) angles using the given or text-generated 2D image from the frontal view and then iteratively reconstructing the remaining 3D NeRF using inpainting latent diffusion model. We propose progressive 3D object reconstruction schemes in terms of scales (low to high resolution), angles (IB angles initially to outer-boundary (OB) later), and masks (object to background boundary) in our DITTO-NeRF so that high-quality information on IB can be propagated into OB. Our DITTO-NeRF outperforms state-of-the-art methods in terms of fidelity and diversity qualitatively and quantitatively with much faster training times than prior arts on image/text-to-3D such as DreamFusion, and NeuralLift-360.
PODIA-3D: Domain Adaptation of 3D Generative Model Across Large Domain Gap Using Pose-Preserved Text-to-Image Diffusion
Apr 04, 2023Recently, significant advancements have been made in 3D generative models, however training these models across diverse domains is challenging and requires an huge amount of training data and knowledge of pose distribution. Text-guided domain adaptation methods have allowed the generator to be adapted to the target domains using text prompts, thereby obviating the need for assembling numerous data. Recently, DATID-3D presents impressive quality of samples in text-guided domain, preserving diversity in text by leveraging text-to-image diffusion. However, adapting 3D generators to domains with significant domain gaps from the source domain still remains challenging due to issues in current text-to-image diffusion models as following: 1) shape-pose trade-off in diffusion-based translation, 2) pose bias, and 3) instance bias in the target domain, resulting in inferior 3D shapes, low text-image correspondence, and low intra-domain diversity in the generated samples. To address these issues, we propose a novel pipeline called PODIA-3D, which uses pose-preserved text-to-image diffusion-based domain adaptation for 3D generative models. We construct a pose-preserved text-to-image diffusion model that allows the use of extremely high-level noise for significant domain changes. We also propose specialized-to-general sampling strategies to improve the details of the generated samples. Moreover, to overcome the instance bias, we introduce a text-guided debiasing method that improves intra-domain diversity. Consequently, our method successfully adapts 3D generators across significant domain gaps. Our qualitative results and user study demonstrates that our approach outperforms existing 3D text-guided domain adaptation methods in terms of text-image correspondence, realism, diversity of rendered images, and sense of depth of 3D shapes in the generated samples
DATID-3D: Diversity-Preserved Domain Adaptation Using Text-to-Image Diffusion for 3D Generative Model
Nov 29, 2022



Recent 3D generative models have achieved remarkable performance in synthesizing high resolution photorealistic images with view consistency and detailed 3D shapes, but training them for diverse domains is challenging since it requires massive training images and their camera distribution information. Text-guided domain adaptation methods have shown impressive performance on converting the 2D generative model on one domain into the models on other domains with different styles by leveraging the CLIP (Contrastive Language-Image Pre-training), rather than collecting massive datasets for those domains. However, one drawback of them is that the sample diversity in the original generative model is not well-preserved in the domain-adapted generative models due to the deterministic nature of the CLIP text encoder. Text-guided domain adaptation will be even more challenging for 3D generative models not only because of catastrophic diversity loss, but also because of inferior text-image correspondence and poor image quality. Here we propose DATID-3D, a domain adaptation method tailored for 3D generative models using text-to-image diffusion models that can synthesize diverse images per text prompt without collecting additional images and camera information for the target domain. Unlike 3D extensions of prior text-guided domain adaptation methods, our novel pipeline was able to fine-tune the state-of-the-art 3D generator of the source domain to synthesize high resolution, multi-view consistent images in text-guided targeted domains without additional data, outperforming the existing text-guided domain adaptation methods in diversity and text-image correspondence. Furthermore, we propose and demonstrate diverse 3D image manipulations such as one-shot instance-selected adaptation and single-view manipulated 3D reconstruction to fully enjoy diversity in text.
Adaptive GLCM sampling for transformer-based COVID-19 detection on CT
Jul 04, 2022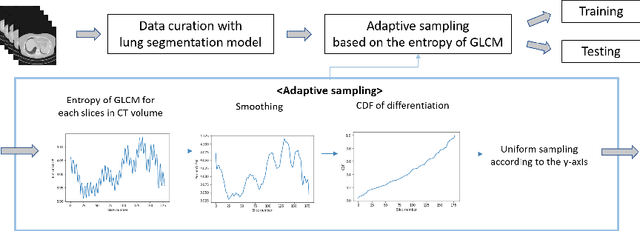
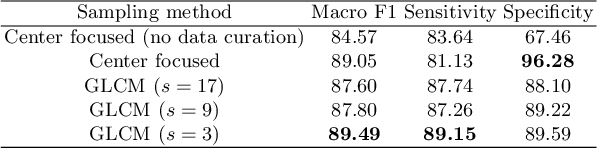
The world has suffered from COVID-19 (SARS-CoV-2) for the last two years, causing much damage and change in people's daily lives. Thus, automated detection of COVID-19 utilizing deep learning on chest computed tomography (CT) scans became promising, which helps correct diagnosis efficiently. Recently, transformer-based COVID-19 detection method on CT is proposed to utilize 3D information in CT volume. However, its sampling method for selecting slices is not optimal. To leverage rich 3D information in CT volume, we propose a transformer-based COVID-19 detection using a novel data curation and adaptive sampling method using gray level co-occurrence matrices (GLCM). To train the model which consists of CNN layer, followed by transformer architecture, we first executed data curation based on lung segmentation and utilized the entropy of GLCM value of every slice in CT volumes to select important slices for the prediction. The experimental results show that the proposed method improve the detection performance with large margin without much difficult modification to the model.
AI can evolve without labels: self-evolving vision transformer for chest X-ray diagnosis through knowledge distillation
Feb 13, 2022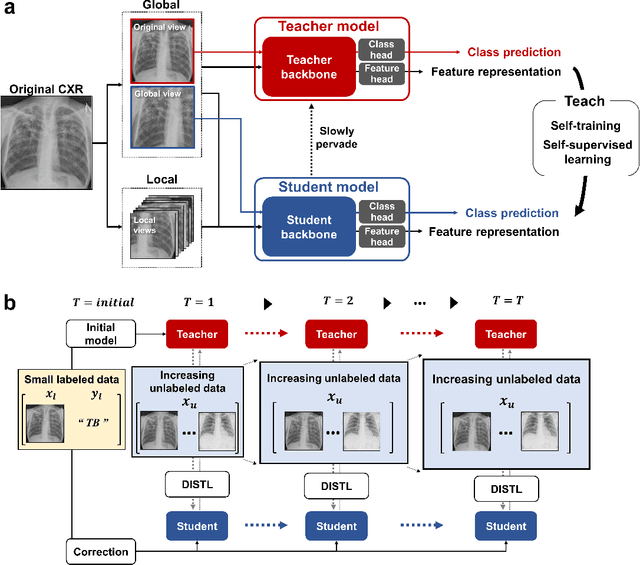
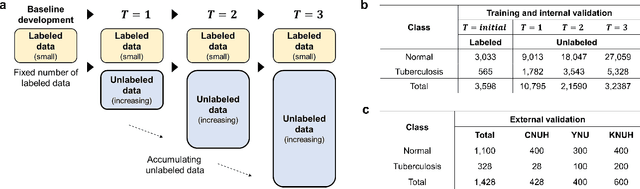
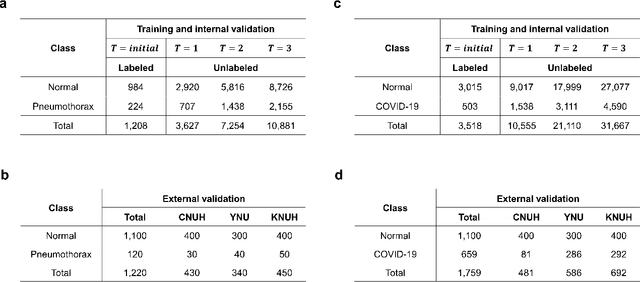
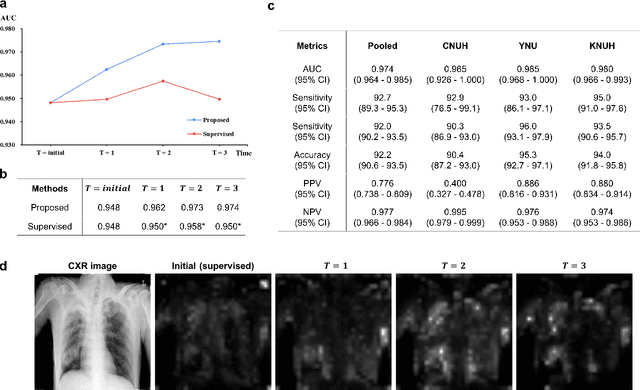
Although deep learning-based computer-aided diagnosis systems have recently achieved expert-level performance, developing a robust deep learning model requires large, high-quality data with manual annotation, which is expensive to obtain. This situation poses the problem that the chest x-rays collected annually in hospitals cannot be used due to the lack of manual labeling by experts, especially in deprived areas. To address this, here we present a novel deep learning framework that uses knowledge distillation through self-supervised learning and self-training, which shows that the performance of the original model trained with a small number of labels can be gradually improved with more unlabeled data. Experimental results show that the proposed framework maintains impressive robustness against a real-world environment and has general applicability to several diagnostic tasks such as tuberculosis, pneumothorax, and COVID-19. Notably, we demonstrated that our model performs even better than those trained with the same amount of labeled data. The proposed framework has a great potential for medical imaging, where plenty of data is accumulated every year, but ground truth annotations are expensive to obtain.