 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Anomaly Detection and Localisation with Multi-scale Interpolated Gaussian Descriptors
Jan 25, 2021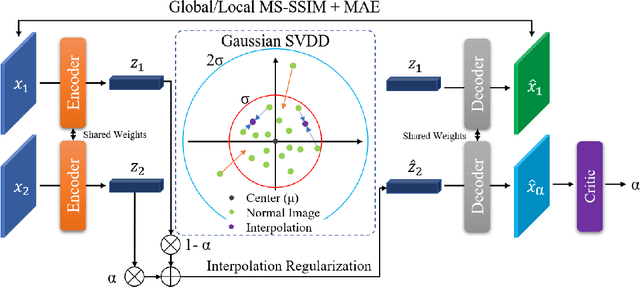
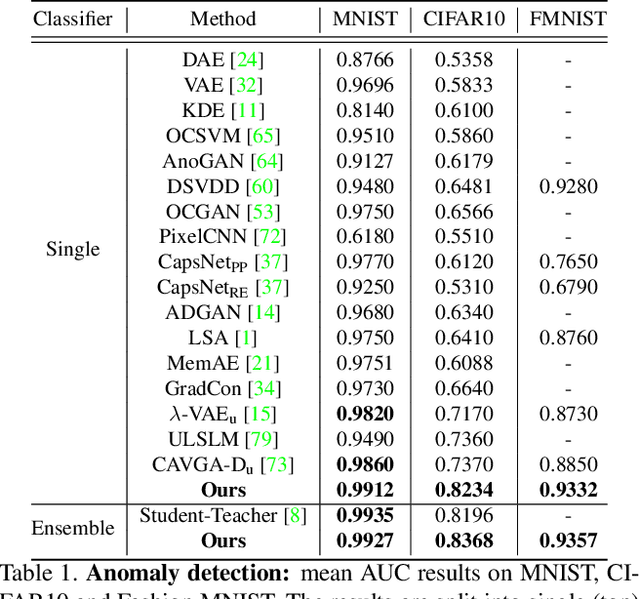
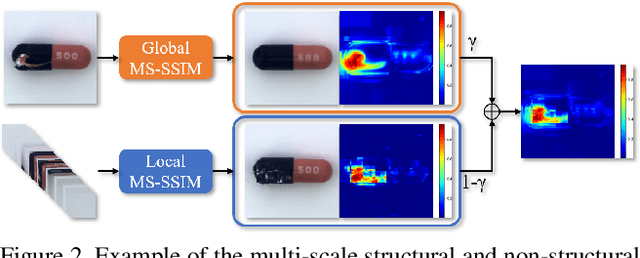
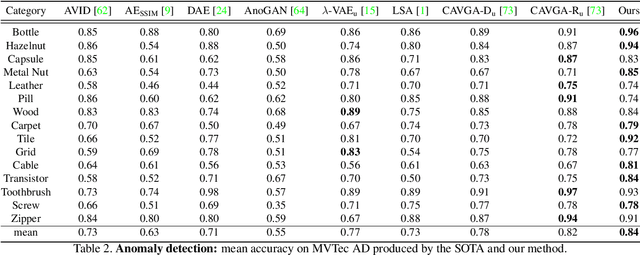
Current unsupervised anomaly detection and localisation systems are commonly formulated as one-class classifiers that depend on an effective estimation of the distribution of normal images and robust criteria to identify anomalies. However, the distribution of normal images estimated by current systems tends to be unstable for classes of normal images that are under-represented in the training set, and the anomaly identification criteria commonly explored in the field does not work well for multi-scale structural and non-structural anomalies. In this paper, we introduce an unsupervised anomaly detection and localisation method designed to address these two issues. More specifically, we introduce a normal image distribution estimation method that is robust to under-represented classes of normal images -- this method is based on adversarially interpolated descriptors from training images and a Gaussian classifier. We also propose a new anomaly identification criterion that can accurately detect and localise multi-scale structural and non-structural anomalies. In extensive experiments on MNIST, Fashion MNIST, CIFAR10 and MVTec AD data sets, our approach shows better results than the current state of the arts in the standard experimental setup for unsupervised anomaly detection and localisation. Code is available at https://github.com/tianyu0207/IGD.
Weakly-supervised Video Anomaly Detection with Contrastive Learning of Long and Short-range Temporal Features
Jan 25, 2021



In this paper, we address the problem of weakly-supervised video anomaly detection, in which given video-level labels for training, we aim to identify in test videos, the snippets containing abnormal events. Although current methods based on multiple instance learning (MIL) show effective detection performance, they ignore important video temporal dependencies. Also, the number of abnormal snippets can vary per anomaly video, which complicates the training process of MIL-based methods because they tend to focus on the most abnormal snippet -- this can cause it to mistakenly select a normal snippet instead of an abnormal snippet, and also to fail to select all abnormal snippets available. We propose a novel method, named Multi-scale Temporal Network trained with top-K Contrastive Multiple Instance Learning (MTN-KMIL), to address the issues above. The main contributions of MTN-KMIL are: 1) a novel synthesis of a pyramid of dilated convolutions and a self-attention mechanism, with the former capturing the multi-scale short-range temporal dependencies between snippets and the latter capturing long-range temporal dependencies; and 2) a novel contrastive MIL learning method that enforces large margins between the top-K normal and abnormal video snippets at the feature representation level and anomaly score level, resulting in accurate anomaly discrimination. Extensive experiments show that our method outperforms several state-of-the-art methods by a large margin on three benchmark data sets (ShanghaiTech, UCF-Crime and XD-Violence). The code is available at https://github.com/tianyu0207/MTN-KMIL
Detecting, Localising and Classifying Polyps from Colonoscopy Videos using Deep Learning
Jan 09, 2021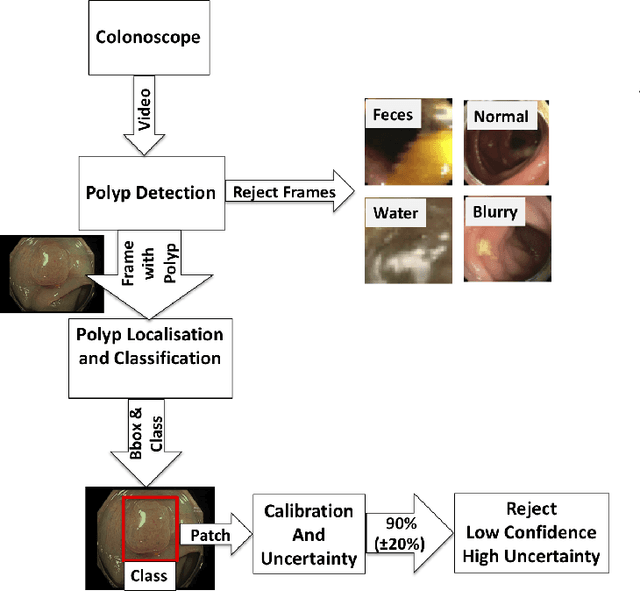
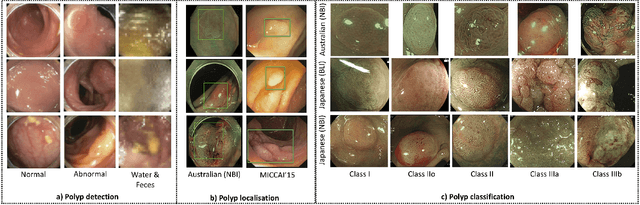
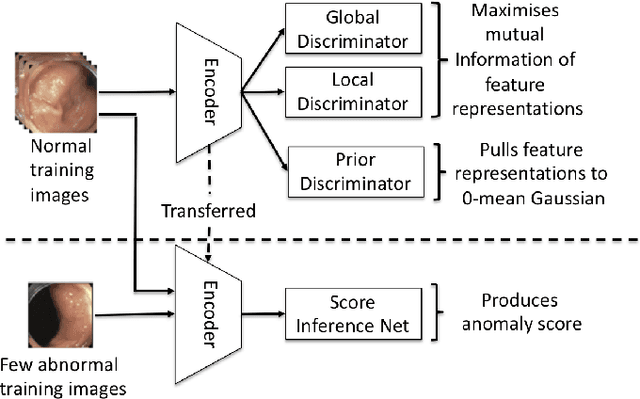
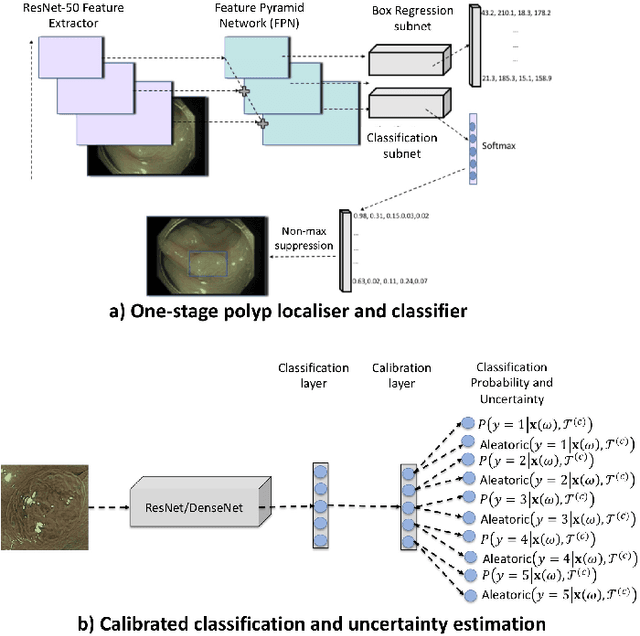
In this paper, we propose and analyse a system that can automatically detect, localise and classify polyps from colonoscopy videos. The detection of frames with polyps is formulated as a few-shot anomaly classification problem, where the training set is highly imbalanced with the large majority of frames consisting of normal images and a small minority comprising frames with polyps. Colonoscopy videos may contain blurry images and frames displaying feces and water jet sprays to clean the colon -- such frames can mistakenly be detected as anomalies, so we have implemented a classifier to reject these two types of frames before polyp detection takes place. Next, given a frame containing a polyp, our method localises (with a bounding box around the polyp) and classifies it into five different classes. Furthermore, we study a method to improve the reliability and interpretability of the classification result using uncertainty estimation and classification calibration. Classification uncertainty and calibration not only help improve classification accuracy by rejecting low-confidence and high-uncertain results, but can be used by doctors to decide how to decide on the classification of a polyp. All the proposed detection, localisation and classification methods are tested using large data sets and compared with relevant baseline approaches.
Semantics for Robotic Mapping, Perception and Interaction: A Survey
Jan 02, 2021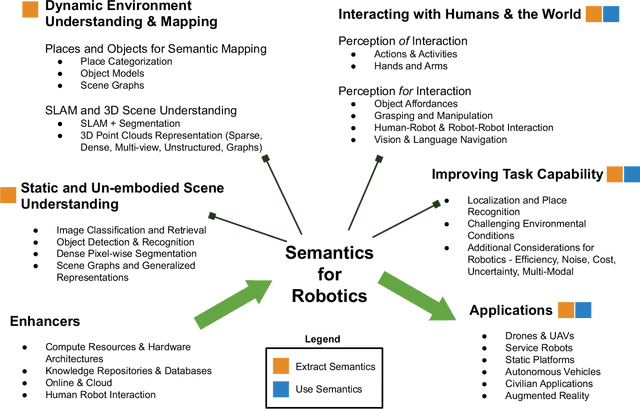
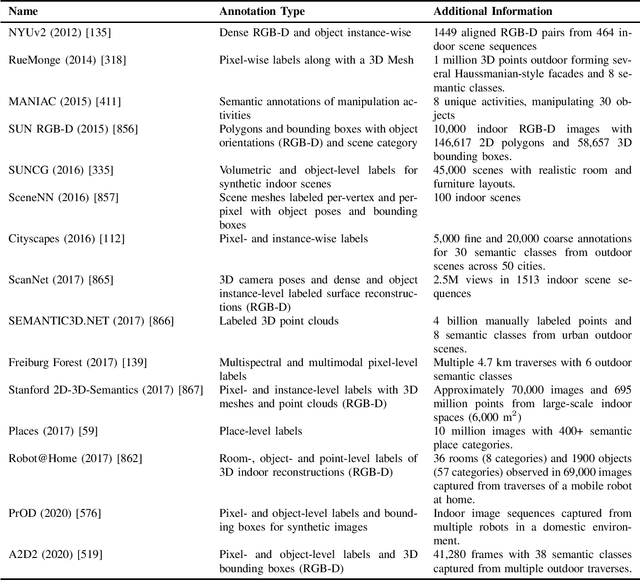
For robots to navigate and interact more richly with the world around them, they will likely require a deeper understanding of the world in which they operate. In robotics and related research fields, the study of understanding is often referred to as semantics, which dictates what does the world "mean" to a robot, and is strongly tied to the question of how to represent that meaning. With humans and robots increasingly operating in the same world, the prospects of human-robot interaction also bring semantics and ontology of natural language into the picture. Driven by need, as well as by enablers like increasing availability of training data and computational resources, semantics is a rapidly growing research area in robotics. The field has received significant attention in the research literature to date, but most reviews and surveys have focused on particular aspects of the topic: the technical research issues regarding its use in specific robotic topics like mapping or segmentation, or its relevance to one particular application domain like autonomous driving. A new treatment is therefore required, and is also timely because so much relevant research has occurred since many of the key surveys were published. This survey therefore provides an overarching snapshot of where semantics in robotics stands today. We establish a taxonomy for semantics research in or relevant to robotics, split into four broad categories of activity, in which semantics are extracted, used, or both. Within these broad categories we survey dozens of major topics including fundamentals from the computer vision field and key robotics research areas utilizing semantics, including mapping, navigation and interaction with the world. The survey also covers key practical considerations, including enablers like increased data availability and improved computational hardware, and major application areas where...
* 81 pages, 1 figure, published in Foundations and Trends in Robotics, 2020
Domain Generalisation with Domain Augmented Supervised Contrastive Learning (Student Abstract)
Dec 27, 2020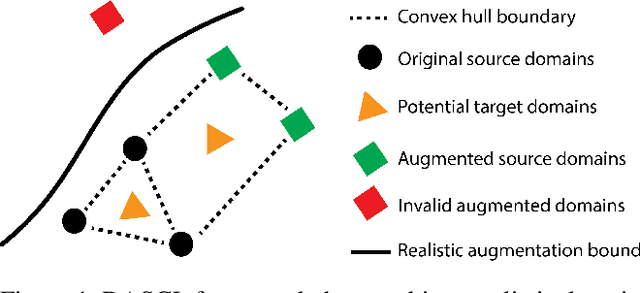
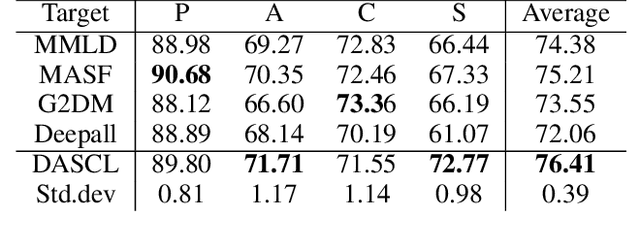
Domain generalisation (DG) methods address the problem of domain shift, when there is a mismatch between the distributions of training and target domains. Data augmentation approaches have emerged as a promising alternative for DG. However, data augmentation alone is not sufficient to achieve lower generalisation errors. This project proposes a new method that combines data augmentation and domain distance minimisation to address the problems associated with data augmentation and provide a guarantee on the learning performance, under an existing framework. Empirically, our method outperforms baseline results on DG benchmarks.
A Survey on Deep Learning with Noisy Labels: How to train your model when you cannot trust on the annotations?
Dec 05, 2020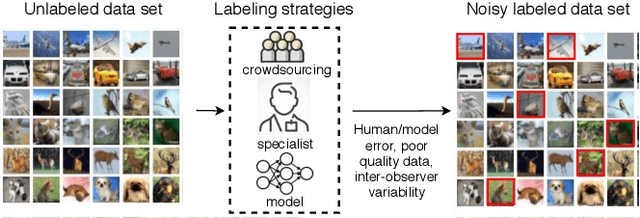
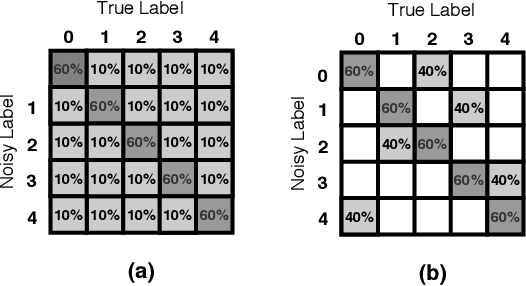
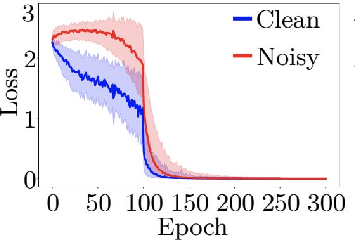
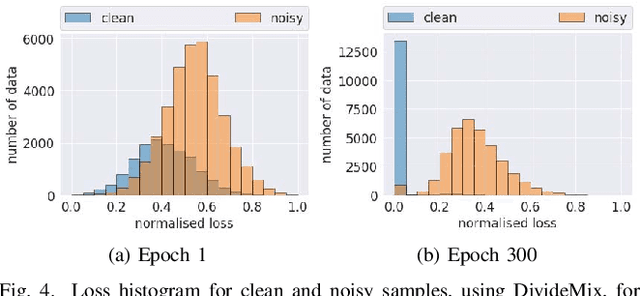
Noisy Labels are commonly present in data sets automatically collected from the internet, mislabeled by non-specialist annotators, or even specialists in a challenging task, such as in the medical field. Although deep learning models have shown significant improvements in different domains, an open issue is their ability to memorize noisy labels during training, reducing their generalization potential. As deep learning models depend on correctly labeled data sets and label correctness is difficult to guarantee, it is crucial to consider the presence of noisy labels for deep learning training. Several approaches have been proposed in the literature to improve the training of deep learning models in the presence of noisy labels. This paper presents a survey on the main techniques in literature, in which we classify the algorithm in the following groups: robust losses, sample weighting, sample selection, meta-learning, and combined approaches. We also present the commonly used experimental setup, data sets, and results of the state-of-the-art models.
* Paper published at SIBRAPI, 2020 (camera ready version)
EvidentialMix: Learning with Combined Open-set and Closed-set Noisy Labels
Nov 11, 2020
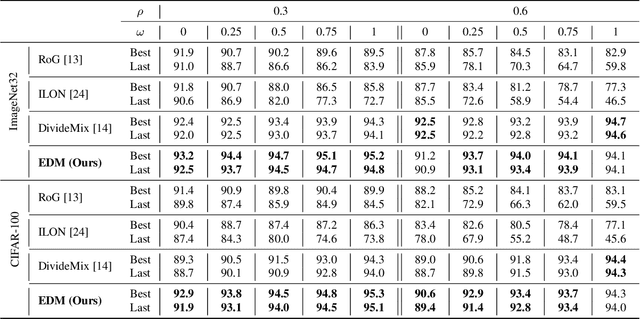
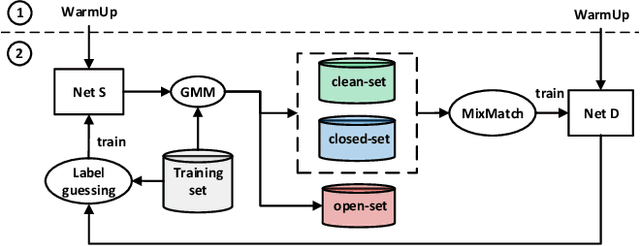
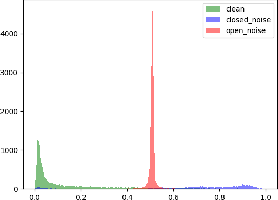
The efficacy of deep learning depends on large-scale data sets that have been carefully curated with reliable data acquisition and annotation processes. However, acquiring such large-scale data sets with precise annotations is very expensive and time-consuming, and the cheap alternatives often yield data sets that have noisy labels. The field has addressed this problem by focusing on training models under two types of label noise: 1) closed-set noise, where some training samples are incorrectly annotated to a training label other than their known true class; and 2) open-set noise, where the training set includes samples that possess a true class that is (strictly) not contained in the set of known training labels. In this work, we study a new variant of the noisy label problem that combines the open-set and closed-set noisy labels, and introduce a benchmark evaluation to assess the performance of training algorithms under this setup. We argue that such problem is more general and better reflects the noisy label scenarios in practice. Furthermore, we propose a novel algorithm, called EvidentialMix, that addresses this problem and compare its performance with the state-of-the-art methods for both closed-set and open-set noise on the proposed benchmark. Our results show that our method produces superior classification results and better feature representations than previous state-of-the-art methods. The code is available at https://github.com/ragavsachdeva/EvidentialMix.
Deep Metric Learning Meets Deep Clustering: An Novel Unsupervised Approach for Feature Embedding
Sep 09, 2020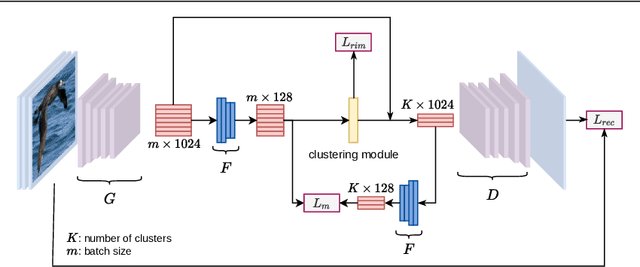
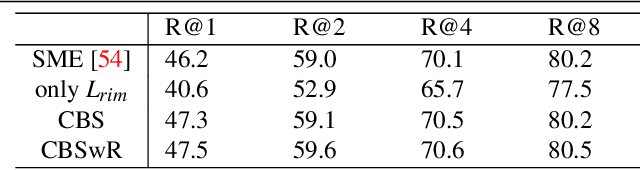


Unsupervised Deep Distance Metric Learning (UDML) aims to learn sample similarities in the embedding space from an unlabeled dataset. Traditional UDML methods usually use the triplet loss or pairwise loss which requires the mining of positive and negative samples w.r.t. anchor data points. This is, however, challenging in an unsupervised setting as the label information is not available. In this paper, we propose a new UDML method that overcomes that challenge. In particular, we propose to use a deep clustering loss to learn centroids, i.e., pseudo labels, that represent semantic classes. During learning, these centroids are also used to reconstruct the input samples. It hence ensures the representativeness of centroids - each centroid represents visually similar samples. Therefore, the centroids give information about positive (visually similar) and negative (visually dissimilar) samples. Based on pseudo labels, we propose a novel unsupervised metric loss which enforces the positive concentration and negative separation of samples in the embedding space. Experimental results on benchmarking datasets show that the proposed approach outperforms other UDML methods.
Self-supervised Depth Estimation to Regularise Semantic Segmentation in Knee Arthroscopy
Jul 05, 2020
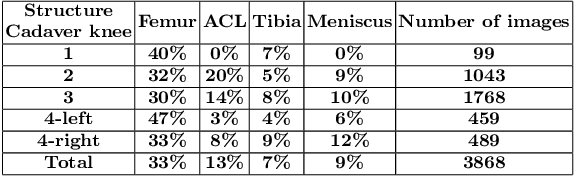
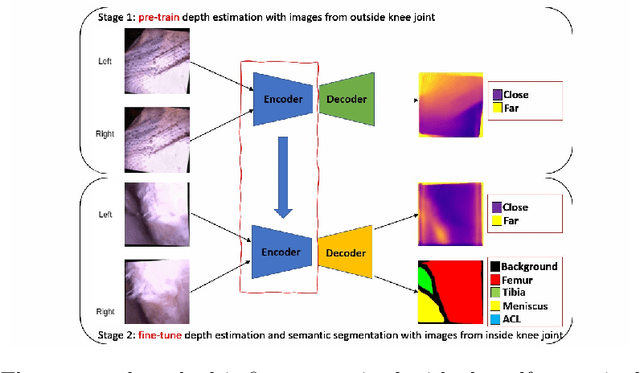
Intra-operative automatic semantic segmentation of knee joint structures can assist surgeons during knee arthroscopy in terms of situational awareness. However, due to poor imaging conditions (e.g., low texture, overexposure, etc.), automatic semantic segmentation is a challenging scenario, which justifies the scarce literature on this topic. In this paper, we propose a novel self-supervised monocular depth estimation to regularise the training of the semantic segmentation in knee arthroscopy. To further regularise the depth estimation, we propose the use of clean training images captured by the stereo arthroscope of routine objects (presenting none of the poor imaging conditions and with rich texture information) to pre-train the model. We fine-tune such model to produce both the semantic segmentation and self-supervised monocular depth using stereo arthroscopic images taken from inside the knee. Using a data set containing 3868 arthroscopic images captured during cadaveric knee arthroscopy with semantic segmentation annotations, 2000 stereo image pairs of cadaveric knee arthroscopy, and 2150 stereo image pairs of routine objects, we show that our semantic segmentation regularised by self-supervised depth estimation produces a more accurate segmentation than a state-of-the-art semantic segmentation approach modeled exclusively with semantic segmentation annotation.
Few-Shot Microscopy Image Cell Segmentation
Jun 29, 2020


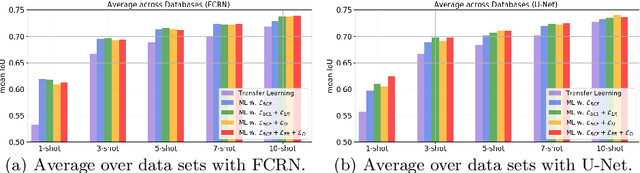
Automatic cell segmentation in microscopy images works well with the support of deep neural networks trained with full supervision. Collecting and annotating images, though, is not a sustainable solution for every new microscopy database and cell type. Instead, we assume that we can access a plethora of annotated image data sets from different domains (sources) and a limited number of annotated image data sets from the domain of interest (target), where each domain denotes not only different image appearance but also a different type of cell segmentation problem. We pose this problem as meta-learning where the goal is to learn a generic and adaptable few-shot learning model from the available source domain data sets and cell segmentation tasks. The model can be afterwards fine-tuned on the few annotated images of the target domain that contains different image appearance and different cell type. In our meta-learning training, we propose the combination of three objective functions to segment the cells, move the segmentation results away from the classification boundary using cross-domain tasks, and learn an invariant representation between tasks of the source domains. Our experiments on five public databases show promising results from 1- to 10-shot meta-learning using standard segmentation neural network architectures.