 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudge Like Human Examiners: A Weighted Importance Multi-Point Evaluation Framework for Generative Tasks with Long-form Answers
Apr 14, 2026Evaluating the quality of model responses remains challenging in generative tasks with long-form answers, as the expected answers usually contain multiple semantically distinct yet complementary factors that should be factorized for fine-grained assessment. Recent evaluation methods resort to relying on either task-level rubrics or question-aware checklists. However, they still 1) struggle to assess whether a response is genuinely grounded in provided contexts; 2) fail to capture the heterogeneous importance of different aspects of reference answers. Inspired by human examiners, we propose a Weighted Importance Multi-Point Evaluation (WIMPE) framework, which factorizes each reference answer into weighted context-bound scoring points. Two complementary metrics, namely Weighted Point-wise Alignment (WPA) and Point-wise Conflict Penalty (PCP), are designed to measure the alignment and contradiction between model responses and reference answers. Extensive experiments on 10 generative tasks demonstrate that WIMPE achieves higher correlations with human annotations.
GDCNet: Generative Discrepancy Comparison Network for Multimodal Sarcasm Detection
Jan 28, 2026Multimodal sarcasm detection (MSD) aims to identify sarcasm within image-text pairs by modeling semantic incongruities across modalities. Existing methods often exploit cross-modal embedding misalignment to detect inconsistency but struggle when visual and textual content are loosely related or semantically indirect. While recent approaches leverage large language models (LLMs) to generate sarcastic cues, the inherent diversity and subjectivity of these generations often introduce noise. To address these limitations, we propose the Generative Discrepancy Comparison Network (GDCNet). This framework captures cross-modal conflicts by utilizing descriptive, factually grounded image captions generated by Multimodal LLMs (MLLMs) as stable semantic anchors. Specifically, GDCNet computes semantic and sentiment discrepancies between the generated objective description and the original text, alongside measuring visual-textual fidelity. These discrepancy features are then fused with visual and textual representations via a gated module to adaptively balance modality contributions. Extensive experiments on MSD benchmarks demonstrate GDCNet's superior accuracy and robustness, establishing a new state-of-the-art on the MMSD2.0 benchmark.
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
Dec 30, 2025Multi-step retrieval-augmented generation (RAG) has become a widely adopted strategy for enhancing large language models (LLMs) on tasks that demand global comprehension and intensive reasoning. Many RAG systems incorporate a working memory module to consolidate retrieved information. However, existing memory designs function primarily as passive storage that accumulates isolated facts for the purpose of condensing the lengthy inputs and generating new sub-queries through deduction. This static nature overlooks the crucial high-order correlations among primitive facts, the compositions of which can often provide stronger guidance for subsequent steps. Therefore, their representational strength and impact on multi-step reasoning and knowledge evolution are limited, resulting in fragmented reasoning and weak global sense-making capacity in extended contexts. We introduce HGMem, a hypergraph-based memory mechanism that extends the concept of memory beyond simple storage into a dynamic, expressive structure for complex reasoning and global understanding. In our approach, memory is represented as a hypergraph whose hyperedges correspond to distinct memory units, enabling the progressive formation of higher-order interactions within memory. This mechanism connects facts and thoughts around the focal problem, evolving into an integrated and situated knowledge structure that provides strong propositions for deeper reasoning in subsequent steps. We evaluate HGMem on several challenging datasets designed for global sense-making. Extensive experiments and in-depth analyses show that our method consistently improves multi-step RAG and substantially outperforms strong baseline systems across diverse tasks.
Fed-PISA: Federated Voice Cloning via Personalized Identity-Style Adaptation
Sep 19, 2025Voice cloning for Text-to-Speech (TTS) aims to generate expressive and personalized speech from text using limited data from a target speaker. Federated Learning (FL) offers a collaborative and privacy-preserving framework for this task, but existing approaches suffer from high communication costs and tend to suppress stylistic heterogeneity, resulting in insufficient personalization. To address these issues, we propose Fed-PISA, which stands for Federated Personalized Identity-Style Adaptation. To minimize communication costs, Fed-PISA introduces a disentangled Low-Rank Adaptation (LoRA) mechanism: the speaker's timbre is retained locally through a private ID-LoRA, while only a lightweight style-LoRA is transmitted to the server, thereby minimizing parameter exchange. To harness heterogeneity, our aggregation method, inspired by collaborative filtering, is introduced to create custom models for each client by learning from stylistically similar peers. Experiments show that Fed-PISA improves style expressivity, naturalness, and speaker similarity, outperforming standard federated baselines with minimal communication costs.
EFSA: Towards Event-Level Financial Sentiment Analysis
Apr 08, 2024In this paper, we extend financial sentiment analysis~(FSA) to event-level since events usually serve as the subject of the sentiment in financial text. Though extracting events from the financial text may be conducive to accurate sentiment predictions, it has specialized challenges due to the lengthy and discontinuity of events in a financial text. To this end, we reconceptualize the event extraction as a classification task by designing a categorization comprising coarse-grained and fine-grained event categories. Under this setting, we formulate the \textbf{E}vent-Level \textbf{F}inancial \textbf{S}entiment \textbf{A}nalysis~(\textbf{EFSA} for short) task that outputs quintuples consisting of (company, industry, coarse-grained event, fine-grained event, sentiment) from financial text. A large-scale Chinese dataset containing $12,160$ news articles and $13,725$ quintuples is publicized as a brand new testbed for our task. A four-hop Chain-of-Thought LLM-based approach is devised for this task. Systematically investigations are conducted on our dataset, and the empirical results demonstrate the benchmarking scores of existing methods and our proposed method can reach the current state-of-the-art. Our dataset and framework implementation are available at https://anonymous.4open.science/r/EFSA-645E
Discovering Protagonist of Sentiment with Aspect Reconstructed Capsule Network
Jan 20, 2020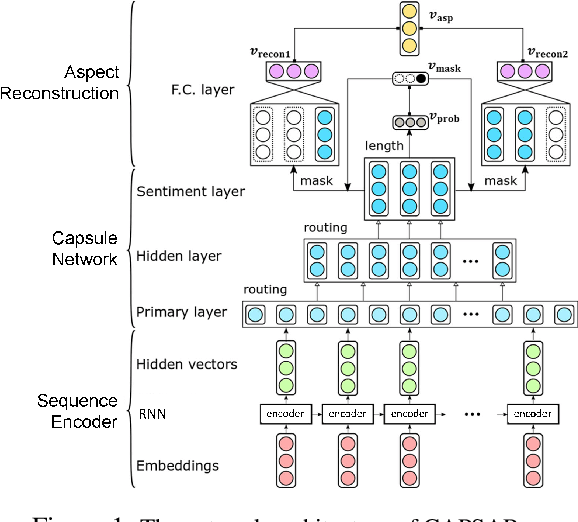
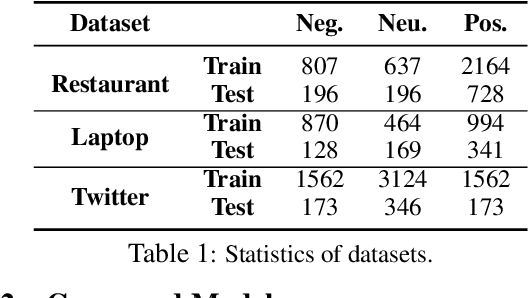
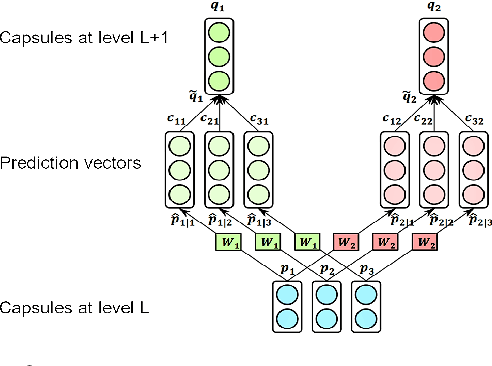
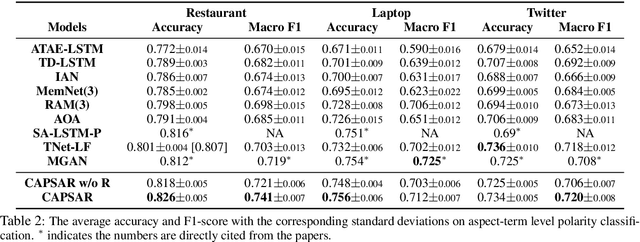
Most recent existing aspect-term level sentiment analysis (ATSA) approaches combined various neural network models with delicately carved attention mechanisms built upon given aspect and context to generate refined sentence representations for better predictions. In these methods, aspect terms are always provided in both training and testing process which may degrade aspect-level analysis into sentence-level prediction. However, the annotated aspect term might be unavailable in real-world scenarios which may challenge the applicability of the existing methods. In this paper, we aim to improve ATSA by discovering the potential aspect terms of the predicted sentiment polarity when the aspect terms of a test sentence are unknown. We access this goal by proposing a capsule network based model named CAPSAR. In CAPSAR, sentiment categories are denoted by capsules and aspect term information is injected into sentiment capsules through a sentiment-aspect reconstruction procedure during the training. As a result, coherent patterns between aspects and sentimental expressions are encapsulated by these sentiment capsules. Experiments on three widely used benchmarks demonstrate these patterns have potential in exploring aspect terms from test sentence when only feeding the sentence to the model. Meanwhile, the proposed CAPSAR can clearly outperform SOTA methods in standard ATSA tasks.