 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-QSAR: an Auto-ML Tool for Molecular Property Prediction
Apr 24, 2023



Recently deep learning based quantitative structure-activity relationship (QSAR) models has shown surpassing performance than traditional methods for property prediction tasks in drug discovery. However, most DL based QSAR models are restricted to limited labeled data to achieve better performance, and also are sensitive to model scale and hyper-parameters. In this paper, we propose Uni-QSAR, a powerful Auto-ML tool for molecule property prediction tasks. Uni-QSAR combines molecular representation learning (MRL) of 1D sequential tokens, 2D topology graphs, and 3D conformers with pretraining models to leverage rich representation from large-scale unlabeled data. Without any manual fine-tuning or model selection, Uni-QSAR outperforms SOTA in 21/22 tasks of the Therapeutic Data Commons (TDC) benchmark under designed parallel workflow, with an average performance improvement of 6.09\%. Furthermore, we demonstrate the practical usefulness of Uni-QSAR in drug discovery domains.
Highly Accurate Quantum Chemical Property Prediction with Uni-Mol+
Mar 16, 2023



Recent developments in deep learning have made remarkable progress in speeding up the prediction of quantum chemical (QC) properties by removing the need for expensive electronic structure calculations like density functional theory. However, previous methods that relied on 1D SMILES sequences or 2D molecular graphs failed to achieve high accuracy as QC properties are primarily dependent on the 3D equilibrium conformations optimized by electronic structure methods. In this paper, we propose a novel approach called Uni-Mol+ to tackle this challenge. Firstly, given a 2D molecular graph, Uni-Mol+ generates an initial 3D conformation from inexpensive methods such as RDKit. Then, the initial conformation is iteratively optimized to its equilibrium conformation, and the optimized conformation is further used to predict the QC properties. All these steps are automatically learned using Transformer models. We observed the quality of the optimized conformation is crucial for QC property prediction performance. To effectively optimize conformation, we introduce a two-track Transformer model backbone in Uni-Mol+ and train it together with the QC property prediction task. We also design a novel training approach called linear trajectory injection to ensure proper supervision for the Uni-Mol+ learning process. Our extensive benchmarking results demonstrate that the proposed Uni-Mol+ significantly improves the accuracy of QC property prediction. We have made the code and model publicly available at \url{https://github.com/dptech-corp/Uni-Mol}.
Do Deep Learning Models Really Outperform Traditional Approaches in Molecular Docking?
Feb 23, 2023
Molecular docking, given a ligand molecule and a ligand binding site (called ``pocket'') on a protein, predicting the binding mode of the protein-ligand complex, is a widely used technique in drug design. Many deep learning models have been developed for molecular docking, while most existing deep learning models perform docking on the whole protein, rather than on a given pocket as the traditional molecular docking approaches, which does not match common needs. What's more, they claim to perform better than traditional molecular docking, but the approach of comparison is not fair, since traditional methods are not designed for docking on the whole protein without a given pocket. In this paper, we design a series of experiments to examine the actual performance of these deep learning models and traditional methods. For a fair comparison, we decompose the docking on the whole protein into two steps, pocket searching and docking on a given pocket, and build pipelines to evaluate traditional methods and deep learning methods respectively. We find that deep learning models are actually good at pocket searching, but traditional methods are better than deep learning models at docking on given pockets. Overall, our work explicitly reveals some potential problems in current deep learning models for molecular docking and provides several suggestions for future works.
Do Deep Learning Methods Really Perform Better in Molecular Conformation Generation?
Feb 14, 2023Molecular conformation generation (MCG) is a fundamental and important problem in drug discovery. Many traditional methods have been developed to solve the MCG problem, such as systematic searching, model-building, random searching, distance geometry, molecular dynamics, Monte Carlo methods, etc. However, they have some limitations depending on the molecular structures. Recently, there are plenty of deep learning based MCG methods, which claim they largely outperform the traditional methods. However, to our surprise, we design a simple and cheap algorithm (parameter-free) based on the traditional methods and find it is comparable to or even outperforms deep learning based MCG methods in the widely used GEOM-QM9 and GEOM-Drugs benchmarks. In particular, our design algorithm is simply the clustering of the RDKIT-generated conformations. We hope our findings can help the community to revise the deep learning methods for MCG. The code of the proposed algorithm could be found at https://gist.github.com/ZhouGengmo/5b565f51adafcd911c0bc115b2ef027c.
Boosted ab initio Cryo-EM 3D Reconstruction with ACE-EM
Feb 14, 2023The central problem in cryo-electron microscopy (cryo-EM) is to recover the 3D structure from noisy 2D projection images which requires estimating the missing projection angles (poses). Recent methods attempted to solve the 3D reconstruction problem with the autoencoder architecture, which suffers from the latent vector space sampling problem and frequently produces suboptimal pose inferences and inferior 3D reconstructions. Here we present an improved autoencoder architecture called ACE (Asymmetric Complementary autoEncoder), based on which we designed the ACE-EM method for cryo-EM 3D reconstructions. Compared to previous methods, ACE-EM reached higher pose space coverage within the same training time and boosted the reconstruction performance regardless of the choice of decoders. With this method, the Nyquist resolution (highest possible resolution) was reached for 3D reconstructions of both simulated and experimental cryo-EM datasets. Furthermore, ACE-EM is the only amortized inference method that reached the Nyquist resolution.
3D Molecular Generation via Virtual Dynamics
Feb 12, 2023



Structure-based drug design, i.e., finding molecules with high affinities to the target protein pocket, is one of the most critical tasks in drug discovery. Traditional solutions, like virtual screening, require exhaustively searching on a large molecular database, which are inefficient and cannot return novel molecules beyond the database. The pocket-based 3D molecular generation model, i.e., directly generating a molecule with a 3D structure and binding position in the pocket, is a new promising way to address this issue. Herein, we propose VD-Gen, a novel pocket-based 3D molecular generation pipeline. VD-Gen consists of several carefully designed stages to generate fine-grained 3D molecules with binding positions in the pocket cavity end-to-end. Rather than directly generating or sampling atoms with 3D positions in the pocket like in early attempts, in VD-Gen, we first randomly initialize many virtual particles in the pocket; then iteratively move these virtual particles, making the distribution of virtual particles approximate the distribution of molecular atoms. After virtual particles are stabilized in 3D space, we extract a 3D molecule from them. Finally, we further refine atoms in the extracted molecule by iterative movement again, to get a high-quality 3D molecule, and predict a confidence score for it. Extensive experiment results on pocket-based molecular generation demonstrate that VD-Gen can generate novel 3D molecules to fill the target pocket cavity with high binding affinities, significantly outperforming previous baselines.
Quantized Training of Gradient Boosting Decision Trees
Jul 20, 2022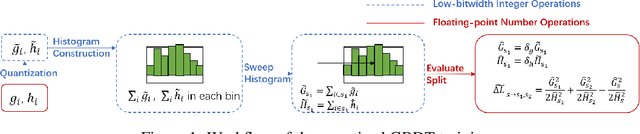
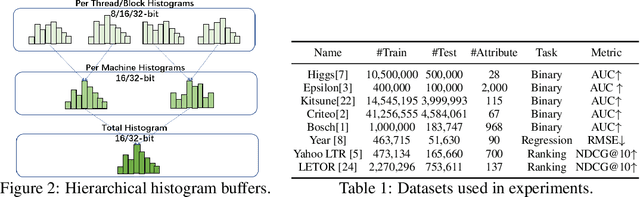
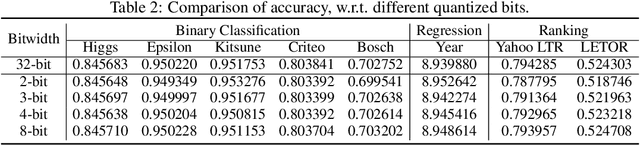
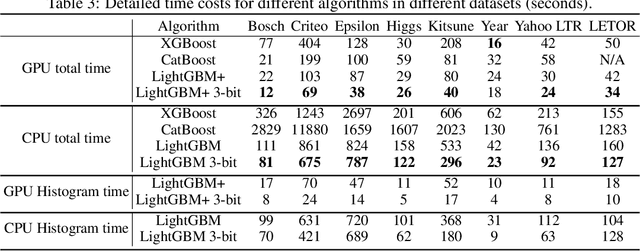
Recent years have witnessed significant success in Gradient Boosting Decision Trees (GBDT) for a wide range of machine learning applications. Generally, a consensus about GBDT's training algorithms is gradients and statistics are computed based on high-precision floating points. In this paper, we investigate an essentially important question which has been largely ignored by the previous literature: how many bits are needed for representing gradients in training GBDT? To solve this mystery, we propose to quantize all the high-precision gradients in a very simple yet effective way in the GBDT's training algorithm. Surprisingly, both our theoretical analysis and empirical studies show that the necessary precisions of gradients without hurting any performance can be quite low, e.g., 2 or 3 bits. With low-precision gradients, most arithmetic operations in GBDT training can be replaced by integer operations of 8, 16, or 32 bits. Promisingly, these findings may pave the way for much more efficient training of GBDT from several aspects: (1) speeding up the computation of gradient statistics in histograms; (2) compressing the communication cost of high-precision statistical information during distributed training; (3) the inspiration of utilization and development of hardware architectures which well support low-precision computation for GBDT training. Benchmarked on CPU, GPU, and distributed clusters, we observe up to 2$\times$ speedup of our simple quantization strategy compared with SOTA GBDT systems on extensive datasets, demonstrating the effectiveness and potential of the low-precision training of GBDT. The code will be released to the official repository of LightGBM.
METRO: Efficient Denoising Pretraining of Large Scale Autoencoding Language Models with Model Generated Signals
Apr 16, 2022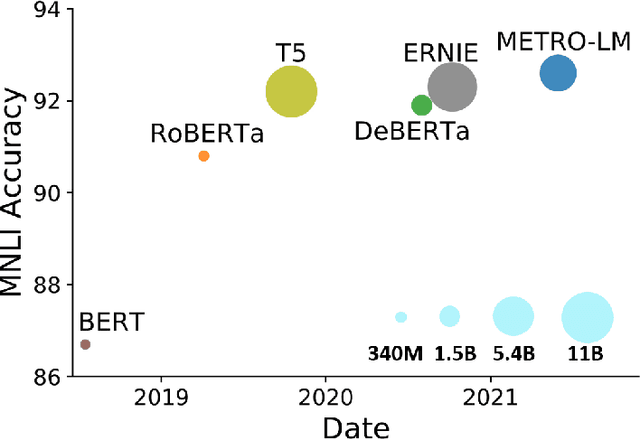
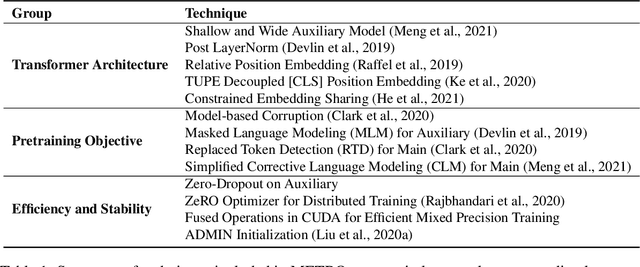
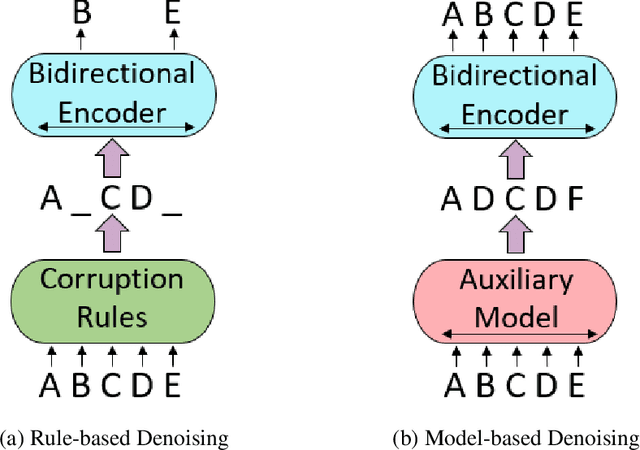
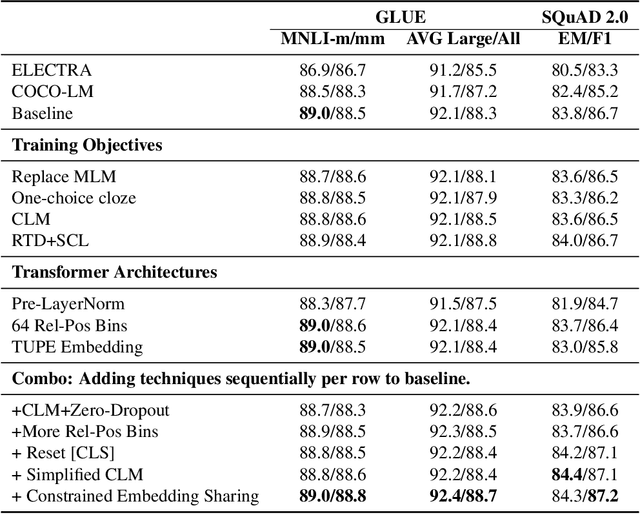
We present an efficient method of pretraining large-scale autoencoding language models using training signals generated by an auxiliary model. Originated in ELECTRA, this training strategy has demonstrated sample-efficiency to pretrain models at the scale of hundreds of millions of parameters. In this work, we conduct a comprehensive empirical study, and propose a recipe, namely "Model generated dEnoising TRaining Objective" (METRO), which incorporates some of the best modeling techniques developed recently to speed up, stabilize, and enhance pretrained language models without compromising model effectiveness. The resultant models, METRO-LM, consisting of up to 5.4 billion parameters, achieve new state-of-the-art on the GLUE, SuperGLUE, and SQuAD benchmarks. More importantly, METRO-LM are efficient in that they often outperform previous large models with significantly smaller model sizes and lower pretraining cost.
An Empirical Study of Graphormer on Large-Scale Molecular Modeling Datasets
Mar 14, 2022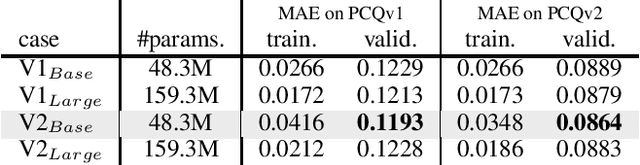
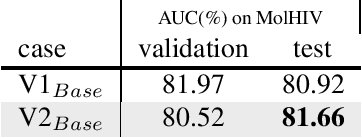
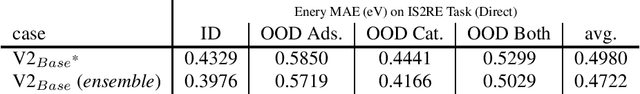

This technical note describes the recent updates of Graphormer, including architecture design modifications, and the adaption to 3D molecular dynamics simulation. The "Graphormer-V2" could attain better results on large-scale molecular modeling datasets than the vanilla one, and the performance gain could be consistently obtained on downstream tasks. In addition, we show that with a global receptive field and an adaptive aggregation strategy, Graphormer is more powerful than classic message-passing-based GNNs. Graphormer-V2 achieves much less MAE than the vanilla Graphormer on the PCQM4M quantum chemistry dataset used in KDD Cup 2021, where the latter one won the first place in this competition. In the meanwhile, Graphormer-V2 greatly outperforms the competitors in the recent Open Catalyst Challenge, which is a competition track on NeurIPS 2021 workshop, and aims to model the catalyst-adsorbate reaction system with advanced AI models. All models could be found at \url{https://github.com/Microsoft/Graphormer}.
Benchmarking Graphormer on Large-Scale Molecular Modeling Datasets
Mar 09, 2022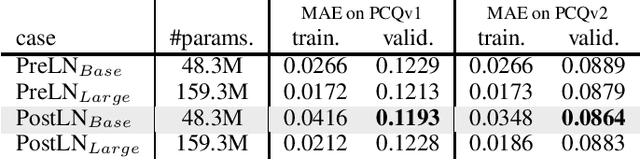
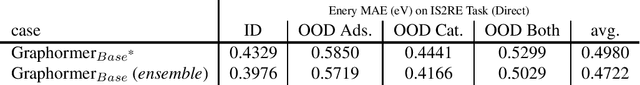
This technical note describes the recent updates of Graphormer, including architecture design modifications, and the adaption to 3D molecular dynamics simulation. With these simple modifications, Graphormer could attain better results on large-scale molecular modeling datasets than the vanilla one, and the performance gain could be consistently obtained on 2D and 3D molecular graph modeling tasks. In addition, we show that with a global receptive field and an adaptive aggregation strategy, Graphormer is more powerful than classic message-passing-based GNNs. Empirically, Graphormer could achieve much less MAE than the originally reported results on the PCQM4M quantum chemistry dataset used in KDD Cup 2021. In the meanwhile, it greatly outperforms the competitors in the recent Open Catalyst Challenge, which is a competition track on NeurIPS 2021 workshop, and aims to model the catalyst-adsorbate reaction system with advanced AI models. All codes could be found at https://github.com/Microsoft/Graphormer.