 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNice Fold or Hero Call: Learning Budget-Efficient Thinking for Adaptive Reasoning
May 12, 2026Large reasoning models (LRMs) improve problem solving through extended reasoning, but often misallocate test-time compute. Existing efficiency methods reduce cost by compressing reasoning traces or conditioning budget on perceived difficulty, yet largely overlook solvability. As a result, they may spend large budgets on queries beyond the model's capability while compressing hard-but-solvable queries that require deeper reasoning. In this work, we formulate adaptive reasoning as a computational investment under uncertainty, where budget should follow the expected return of reasoning rather than perceived difficulty alone. To instantiate this principle, we propose Budget-Efficient Thinking (BET), a two-stage framework that combines behavioral cold-start with GRPO under an investment-cost-aware reward. By aligning solve-or-fold decisions with rollout-derived solvability, BET learns three behaviors: (1) short solve, answering easy queries concisely; (2) nice fold, abstaining early when continued reasoning has near-zero expected return; and (3) hero call, preserving sufficient compute for hard-but-solvable queries. Across seven benchmarks and three base models, BET reduces reasoning tokens by ~55% on average while achieving overall performance improvements, and transfers zero-shot from mathematical reasoning to scientific QA and logical reasoning with comparable efficiency gains.
IoT-Brain: Grounding LLMs for Semantic-Spatial Sensor Scheduling
Apr 09, 2026Intelligent systems powered by large-scale sensor networks are shifting from predefined monitoring to intent-driven operation, revealing a critical Semantic-to-Physical Mapping Gap. While large language models (LLMs) excel at semantic understanding, existing perception-centric pipelines operate retrospectively, overlooking the fundamental decision of what to sense and when. We formalize this proactive decision as Semantic-Spatial Sensor Scheduling (S3) and demonstrate that direct LLM planning is unreliable due to inherent gaps in representation, reasoning, and optimization. To bridge these gaps, we introduce the Spatial Trajectory Graph (STG), a neuro-symbolic paradigm governed by a verify-before-commit discipline that transforms open-ended planning into a verifiable graph optimization problem. Based on STG, we implement IoT-Brain, a concrete system embodiment, and construct TopoSense-Bench, a campus-scale benchmark with 5,250 natural-language queries across 2,510 cameras. Evaluations show that IoT-Brain boosts task success rate by 37.6% over the strongest search-intensive methods while running nearly 2 times faster and using 6.6 times fewer prompt tokens. In real-world deployment, it approaches the reliability upper bound while reducing 4.1 times network bandwidth, providing a foundational framework for LLMs to interact with the physical world with unprecedented reliability and efficiency.
Reasoning with Autoregressive-Diffusion Collaborative Thoughts
Feb 02, 2026Autoregressive and diffusion models represent two complementary generative paradigms. Autoregressive models excel at sequential planning and constraint composition, yet struggle with tasks that require explicit spatial or physical grounding. Diffusion models, in contrast, capture rich spatial structure through high-dimensional generation, but lack the stepwise logical control needed to satisfy complex, multi-stage constraints or to reliably identify and correct errors. We introduce Collaborative Thoughts, a unified collaborative framework that enables autoregressive and diffusion models to reason and generate jointly through a closed-loop interaction. In Collaborative Thoughts, autoregressive models perform structured planning and constraint management, diffusion models instantiate these constraints as intermediate visual thoughts, and a vision-based critic module evaluates whether the visual thoughts satisfy the intended structural and physical requirements. This feedback is then used to iteratively refine subsequent planning and generation steps, mitigating error propagation across modalities. Importantly, Collaborative Thoughts uses the same collaborative loop regardless of whether the task is autoregressive question answering or diffusion-based visual generation. Through representative examples, we illustrate how Collaborative Thoughts can improve the reliability of spatial reasoning and the controllability of generation.
DeepFeature: Iterative Context-aware Feature Generation for Wearable Biosignals
Dec 09, 2025Biosignals collected from wearable devices are widely utilized in healthcare applications. Machine learning models used in these applications often rely on features extracted from biosignals due to their effectiveness, lower data dimensionality, and wide compatibility across various model architectures. However, existing feature extraction methods often lack task-specific contextual knowledge, struggle to identify optimal feature extraction settings in high-dimensional feature space, and are prone to code generation and automation errors. In this paper, we propose DeepFeature, the first LLM-empowered, context-aware feature generation framework for wearable biosignals. DeepFeature introduces a multi-source feature generation mechanism that integrates expert knowledge with task settings. It also employs an iterative feature refinement process that uses feature assessment-based feedback for feature re-selection. Additionally, DeepFeature utilizes a robust multi-layer filtering and verification approach for robust feature-to-code translation to ensure that the extraction functions run without crashing. Experimental evaluation results show that DeepFeature achieves an average AUROC improvement of 4.21-9.67% across eight diverse tasks compared to baseline methods. It outperforms state-of-the-art approaches on five tasks while maintaining comparable performance on the remaining tasks.
Venus: An Efficient Edge Memory-and-Retrieval System for VLM-based Online Video Understanding
Dec 08, 2025



Vision-language models (VLMs) have demonstrated impressive multimodal comprehension capabilities and are being deployed in an increasing number of online video understanding applications. While recent efforts extensively explore advancing VLMs' reasoning power in these cases, deployment constraints are overlooked, leading to overwhelming system overhead in real-world deployments. To address that, we propose Venus, an on-device memory-and-retrieval system for efficient online video understanding. Venus proposes an edge-cloud disaggregated architecture that sinks memory construction and keyframe retrieval from cloud to edge, operating in two stages. In the ingestion stage, Venus continuously processes streaming edge videos via scene segmentation and clustering, where the selected keyframes are embedded with a multimodal embedding model to build a hierarchical memory for efficient storage and retrieval. In the querying stage, Venus indexes incoming queries from memory, and employs a threshold-based progressive sampling algorithm for keyframe selection that enhances diversity and adaptively balances system cost and reasoning accuracy. Our extensive evaluation shows that Venus achieves a 15x-131x speedup in total response latency compared to state-of-the-art methods, enabling real-time responses within seconds while maintaining comparable or even superior reasoning accuracy.
An LLM-Empowered Low-Resolution Vision System for On-Device Human Behavior Understanding
May 03, 2025The rapid advancements in Large Vision Language Models (LVLMs) offer the potential to surpass conventional labeling by generating richer, more detailed descriptions of on-device human behavior understanding (HBU) in low-resolution vision systems, such as depth, thermal, and infrared. However, existing large vision language model (LVLM) approaches are unable to understand low-resolution data well as they are primarily designed for high-resolution data, such as RGB images. A quick fixing approach is to caption a large amount of low-resolution data, but it requires a significant amount of labor-intensive annotation efforts. In this paper, we propose a novel, labor-saving system, Llambda, designed to support low-resolution HBU. The core idea is to leverage limited labeled data and a large amount of unlabeled data to guide LLMs in generating informative captions, which can be combined with raw data to effectively fine-tune LVLM models for understanding low-resolution videos in HBU. First, we propose a Contrastive-Oriented Data Labeler, which can capture behavior-relevant information from long, low-resolution videos and generate high-quality pseudo labels for unlabeled data via contrastive learning. Second, we propose a Physical-Knowledge Guided Captioner, which utilizes spatial and temporal consistency checks to mitigate errors in pseudo labels. Therefore, it can improve LLMs' understanding of sequential data and then generate high-quality video captions. Finally, to ensure on-device deployability, we employ LoRA-based efficient fine-tuning to adapt LVLMs for low-resolution data. We evaluate Llambda using a region-scale real-world testbed and three distinct low-resolution datasets, and the experiments show that Llambda outperforms several state-of-the-art LVLM systems up to $40.03\%$ on average Bert-Score.
RemoteRAG: A Privacy-Preserving LLM Cloud RAG Service
Dec 17, 2024



Retrieval-augmented generation (RAG) improves the service quality of large language models by retrieving relevant documents from credible literature and integrating them into the context of the user query. Recently, the rise of the cloud RAG service has made it possible for users to query relevant documents conveniently. However, directly sending queries to the cloud brings potential privacy leakage. In this paper, we are the first to formally define the privacy-preserving cloud RAG service to protect the user query and propose RemoteRAG as a solution regarding privacy, efficiency, and accuracy. For privacy, we introduce $(n,\epsilon)$-DistanceDP to characterize privacy leakage of the user query and the leakage inferred from relevant documents. For efficiency, we limit the search range from the total documents to a small number of selected documents related to a perturbed embedding generated from $(n,\epsilon)$-DistanceDP, so that computation and communication costs required for privacy protection significantly decrease. For accuracy, we ensure that the small range includes target documents related to the user query with detailed theoretical analysis. Experimental results also demonstrate that RemoteRAG can resist existing embedding inversion attack methods while achieving no loss in retrieval under various settings. Moreover, RemoteRAG is efficient, incurring only $0.67$ seconds and $46.66$KB of data transmission ($2.72$ hours and $1.43$ GB with the non-optimized privacy-preserving scheme) when retrieving from a total of $10^6$ documents.
MLink: Linking Black-Box Models from Multiple Domains for Collaborative Inference
Sep 28, 2022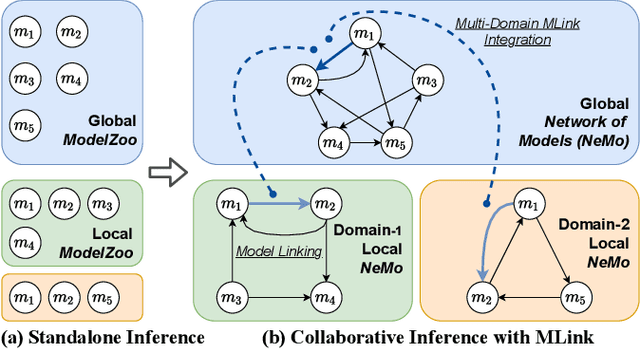
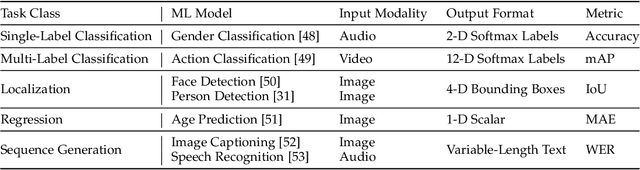
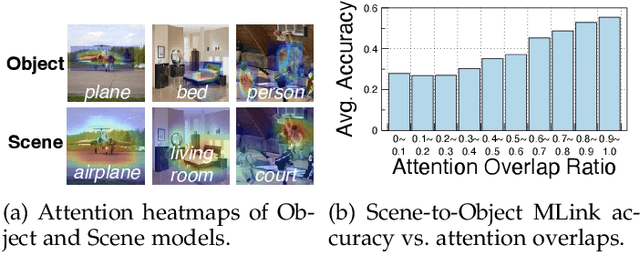
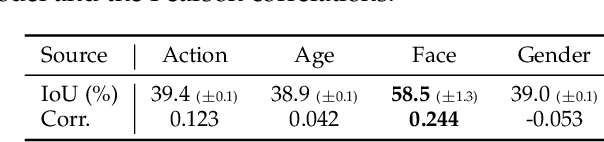
The cost efficiency of model inference is critical to real-world machine learning (ML) applications, especially for delay-sensitive tasks and resource-limited devices. A typical dilemma is: in order to provide complex intelligent services (e.g. smart city), we need inference results of multiple ML models, but the cost budget (e.g. GPU memory) is not enough to run all of them. In this work, we study underlying relationships among black-box ML models and propose a novel learning task: model linking, which aims to bridge the knowledge of different black-box models by learning mappings (dubbed model links) between their output spaces. We propose the design of model links which supports linking heterogeneous black-box ML models. Also, in order to address the distribution discrepancy challenge, we present adaptation and aggregation methods of model links. Based on our proposed model links, we developed a scheduling algorithm, named MLink. Through collaborative multi-model inference enabled by model links, MLink can improve the accuracy of obtained inference results under the cost budget. We evaluated MLink on a multi-modal dataset with seven different ML models and two real-world video analytics systems with six ML models and 3,264 hours of video. Experimental results show that our proposed model links can be effectively built among various black-box models. Under the budget of GPU memory, MLink can save 66.7% inference computations while preserving 94% inference accuracy, which outperforms multi-task learning, deep reinforcement learning-based scheduler and frame filtering baselines.
InFi: End-to-End Learning to Filter Input for Resource-Efficiency in Mobile-Centric Inference
Sep 28, 2022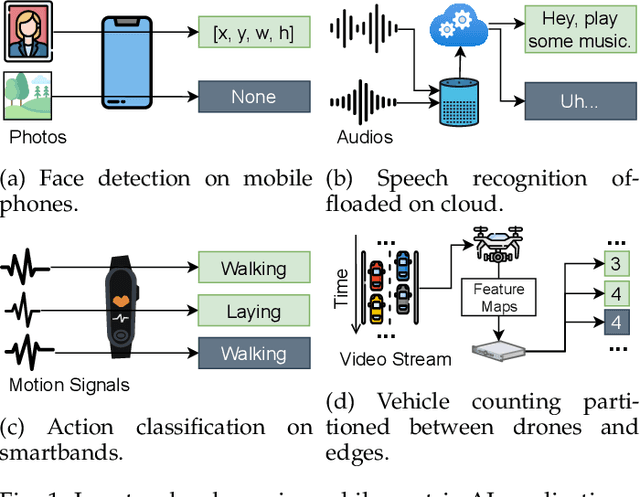
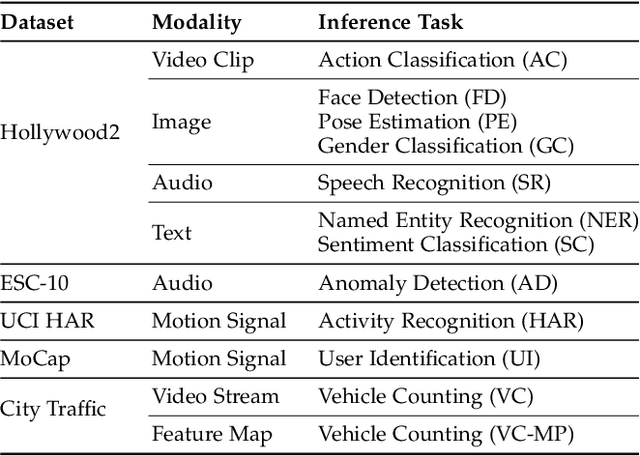
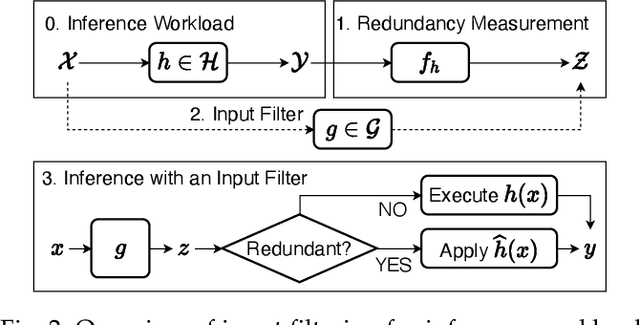
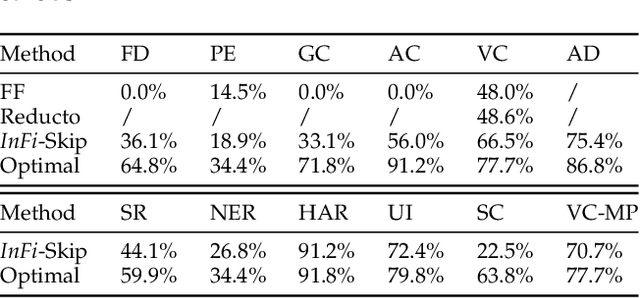
Mobile-centric AI applications have high requirements for resource-efficiency of model inference. Input filtering is a promising approach to eliminate the redundancy so as to reduce the cost of inference. Previous efforts have tailored effective solutions for many applications, but left two essential questions unanswered: (1) theoretical filterability of an inference workload to guide the application of input filtering techniques, thereby avoiding the trial-and-error cost for resource-constrained mobile applications; (2) robust discriminability of feature embedding to allow input filtering to be widely effective for diverse inference tasks and input content. To answer them, we first formalize the input filtering problem and theoretically compare the hypothesis complexity of inference models and input filters to understand the optimization potential. Then we propose the first end-to-end learnable input filtering framework that covers most state-of-the-art methods and surpasses them in feature embedding with robust discriminability. We design and implement InFi that supports six input modalities and multiple mobile-centric deployments. Comprehensive evaluations confirm our theoretical results and show that InFi outperforms strong baselines in applicability, accuracy, and efficiency. InFi achieve 8.5x throughput and save 95% bandwidth, while keeping over 90% accuracy, for a video analytics application on mobile platforms.
Comprehensive and Efficient Data Labeling via Adaptive Model Scheduling
Feb 08, 2020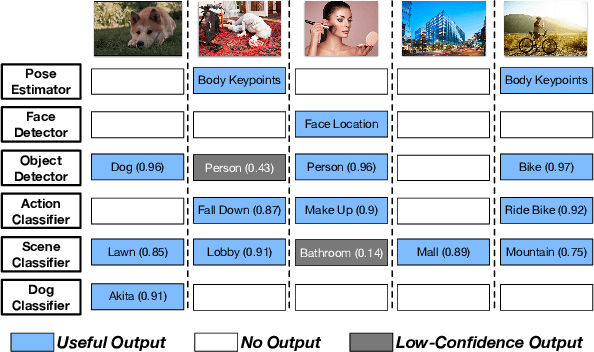
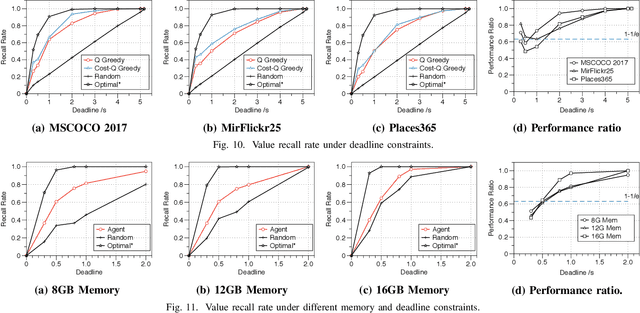
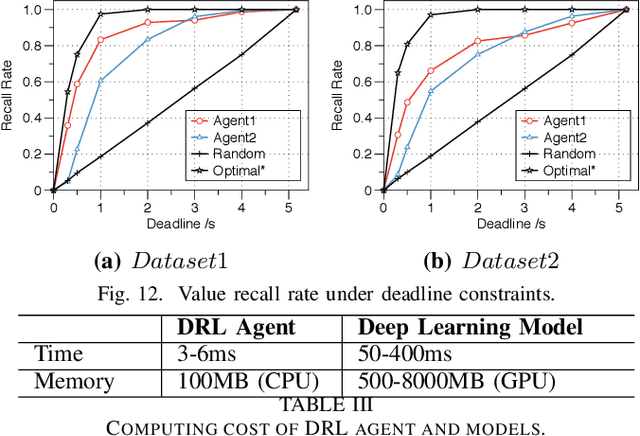
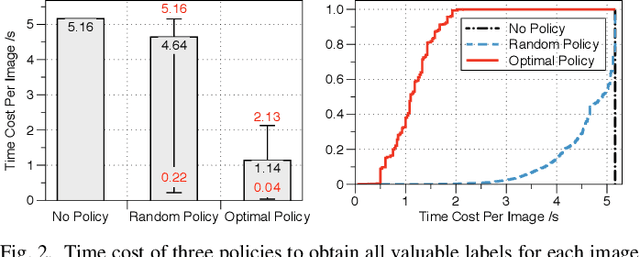
Labeling data (e.g., labeling the people, objects, actions and scene in images) comprehensively and efficiently is a widely needed but challenging task. Numerous models were proposed to label various data and many approaches were designed to enhance the ability of deep learning models or accelerate them. Unfortunately, a single machine-learning model is not powerful enough to extract various semantic information from data. Given certain applications, such as image retrieval platforms and photo album management apps, it is often required to execute a collection of models to obtain sufficient labels. With limited computing resources and stringent delay, given a data stream and a collection of applicable resource-hungry deep-learning models, we design a novel approach to adaptively schedule a subset of these models to execute on each data item, aiming to maximize the value of the model output (e.g., the number of high-confidence labels). Achieving this lofty goal is nontrivial since a model's output on any data item is content-dependent and unknown until we execute it. To tackle this, we propose an Adaptive Model Scheduling framework, consisting of 1) a deep reinforcement learning-based approach to predict the value of unexecuted models by mining semantic relationship among diverse models, and 2) two heuristic algorithms to adaptively schedule the model execution order under a deadline or deadline-memory constraints respectively. The proposed framework doesn't require any prior knowledge of the data, which works as a powerful complement to existing model optimization technologies. We conduct extensive evaluations on five diverse image datasets and 30 popular image labeling models to demonstrate the effectiveness of our design: our design could save around 53\% execution time without loss of any valuable labels.