 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATrans: Context and Affinity Transformer for Few-Shot Segmentation
Apr 27, 2022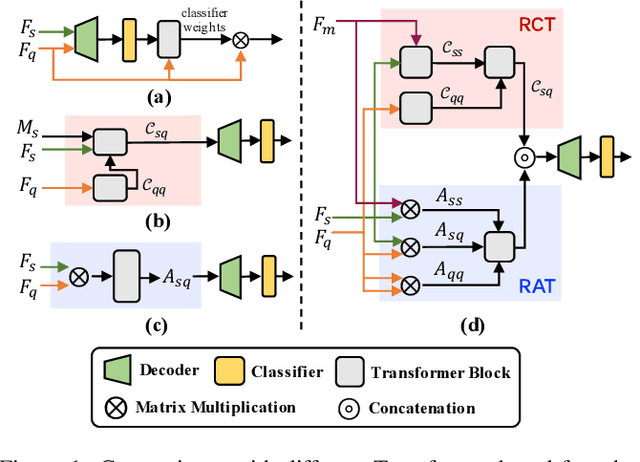
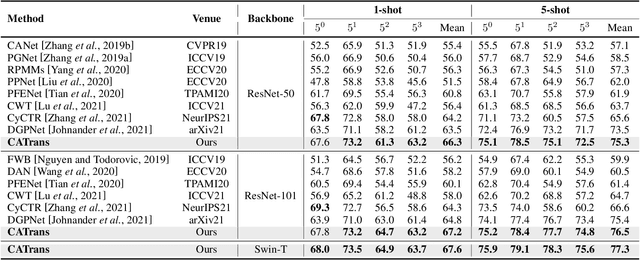
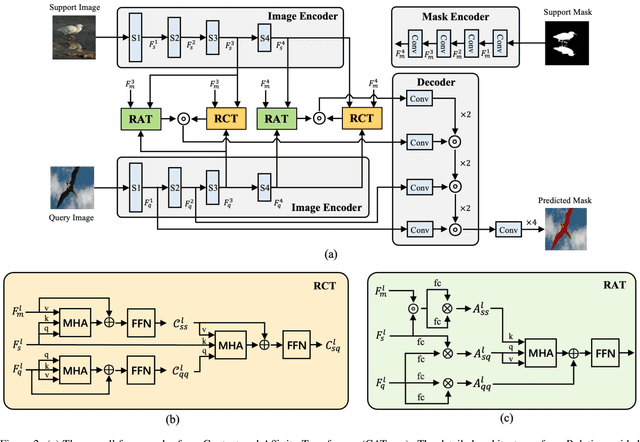

Few-shot segmentation (FSS) aims to segment novel categories given scarce annotated support images. The crux of FSS is how to aggregate dense correlations between support and query images for query segmentation while being robust to the large variations in appearance and context. To this end, previous Transformer-based methods explore global consensus either on context similarity or affinity map between support-query pairs. In this work, we effectively integrate the context and affinity information via the proposed novel Context and Affinity Transformer (CATrans) in a hierarchical architecture. Specifically, the Relation-guided Context Transformer (RCT) propagates context information from support to query images conditioned on more informative support features. Based on the observation that a huge feature distinction between support and query pairs brings barriers for context knowledge transfer, the Relation-guided Affinity Transformer (RAT) measures attention-aware affinity as auxiliary information for FSS, in which the self-affinity is responsible for more reliable cross-affinity. We conduct experiments to demonstrate the effectiveness of the proposed model, outperforming the state-of-the-art methods.
Feature Selective Transformer for Semantic Image Segmentation
Apr 01, 2022
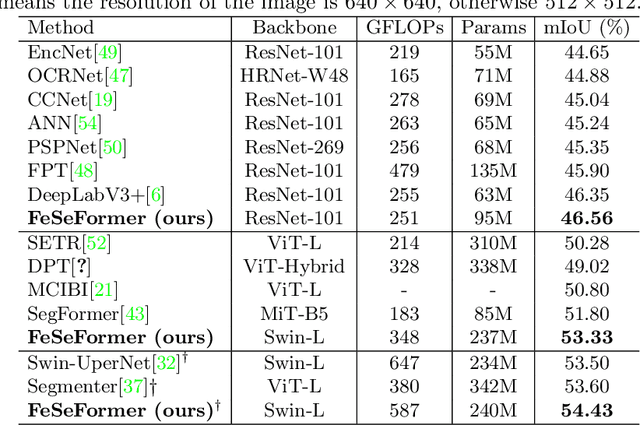
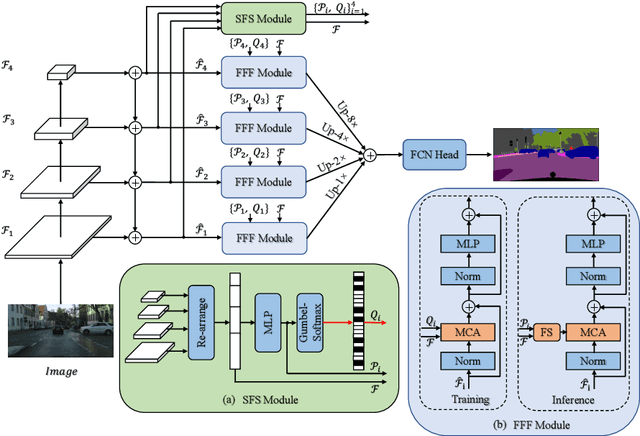
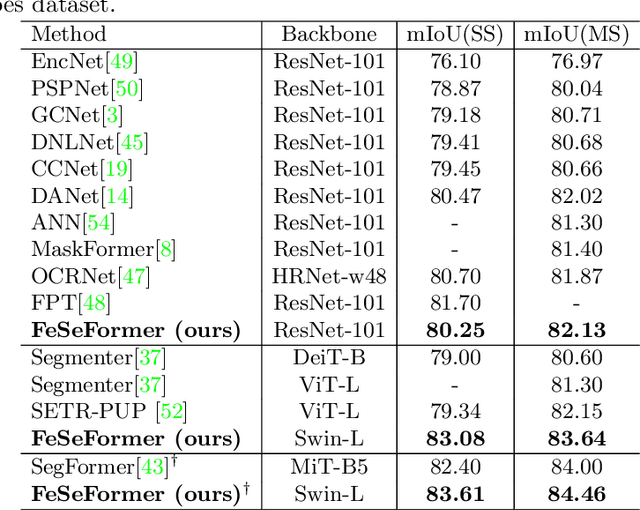
Recently, it has attracted more and more attentions to fuse multi-scale features for semantic image segmentation. Various works were proposed to employ progressive local or global fusion, but the feature fusions are not rich enough for modeling multi-scale context features. In this work, we focus on fusing multi-scale features from Transformer-based backbones for semantic segmentation, and propose a Feature Selective Transformer (FeSeFormer), which aggregates features from all scales (or levels) for each query feature. Specifically, we first propose a Scale-level Feature Selection (SFS) module, which can choose an informative subset from the whole multi-scale feature set for each scale, where those features that are important for the current scale (or level) are selected and the redundant are discarded. Furthermore, we propose a Full-scale Feature Fusion (FFF) module, which can adaptively fuse features of all scales for queries. Based on the proposed SFS and FFF modules, we develop a Feature Selective Transformer (FeSeFormer), and evaluate our FeSeFormer on four challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K, COCO-Stuff 10K, and Cityscapes, outperforming the state-of-the-art.
Nested Collaborative Learning for Long-Tailed Visual Recognition
Mar 29, 2022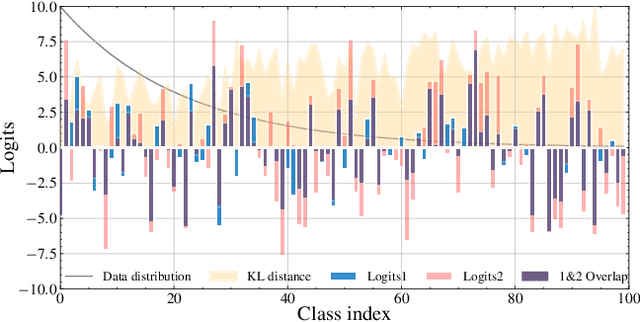
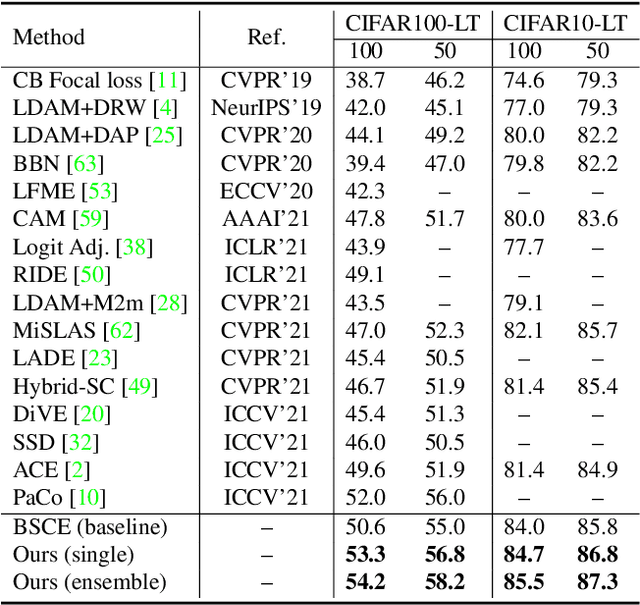
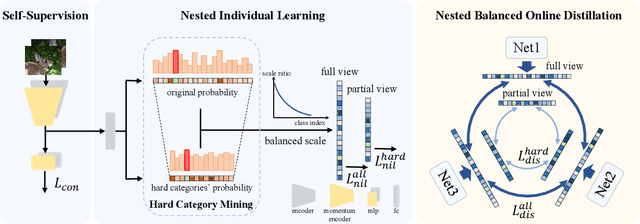
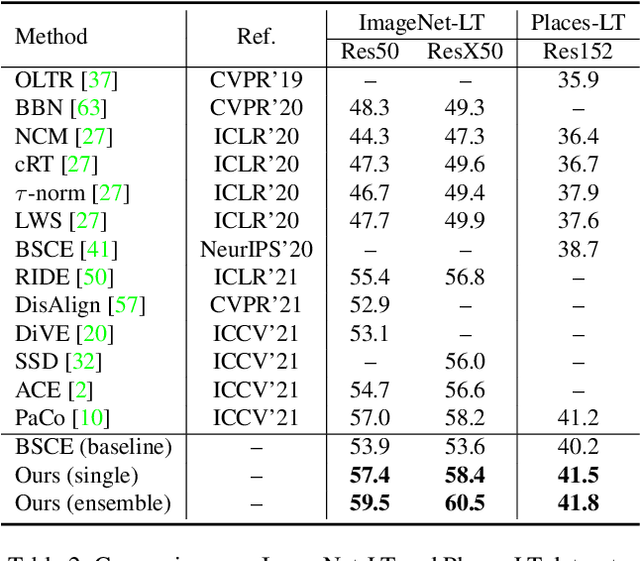
The networks trained on the long-tailed dataset vary remarkably, despite the same training settings, which shows the great uncertainty in long-tailed learning. To alleviate the uncertainty, we propose a Nested Collaborative Learning (NCL), which tackles the problem by collaboratively learning multiple experts together. NCL consists of two core components, namely Nested Individual Learning (NIL) and Nested Balanced Online Distillation (NBOD), which focus on the individual supervised learning for each single expert and the knowledge transferring among multiple experts, respectively. To learn representations more thoroughly, both NIL and NBOD are formulated in a nested way, in which the learning is conducted on not just all categories from a full perspective but some hard categories from a partial perspective. Regarding the learning in the partial perspective, we specifically select the negative categories with high predicted scores as the hard categories by using a proposed Hard Category Mining (HCM). In the NCL, the learning from two perspectives is nested, highly related and complementary, and helps the network to capture not only global and robust features but also meticulous distinguishing ability. Moreover, self-supervision is further utilized for feature enhancement. Extensive experiments manifest the superiority of our method with outperforming the state-of-the-art whether by using a single model or an ensemble.
Coarse-to-Fine Cascaded Networks with Smooth Predicting for Video Facial Expression Recognition
Mar 28, 2022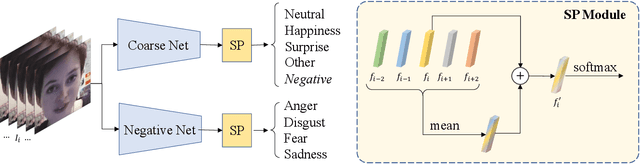
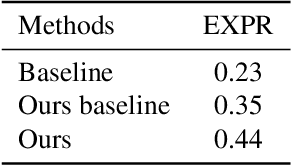

Facial expression recognition plays an important role in human-computer interaction. In this paper, we propose the Coarse-to-Fine Cascaded network with Smooth Predicting (CFC-SP) to improve the performance of facial expression recognition. CFC-SP contains two core components, namely Coarse-to-Fine Cascaded networks (CFC) and Smooth Predicting (SP). For CFC, it first groups several similar emotions to form a rough category, and then employs a network to conduct a coarse but accurate classification. Later, an additional network for these grouped emotions is further used to obtain fine-grained predictions. For SP, it improves the recognition capability of the model by capturing both universal and unique expression features. To be specific, the universal features denote the general characteristic of facial emotions within a period and the unique features denote the specific characteristic at this moment. Experiments on Aff-Wild2 show the effectiveness of the proposed CFSP.
Bi-level Doubly Variational Learning for Energy-based Latent Variable Models
Mar 24, 2022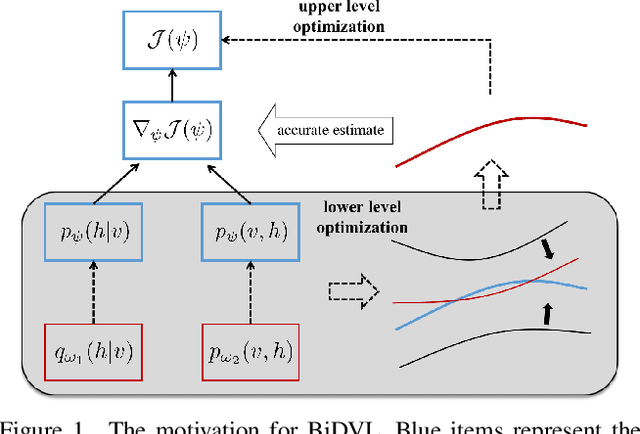

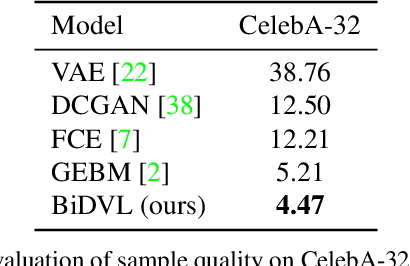

Energy-based latent variable models (EBLVMs) are more expressive than conventional energy-based models. However, its potential on visual tasks are limited by its training process based on maximum likelihood estimate that requires sampling from two intractable distributions. In this paper, we propose Bi-level doubly variational learning (BiDVL), which is based on a new bi-level optimization framework and two tractable variational distributions to facilitate learning EBLVMs. Particularly, we lead a decoupled EBLVM consisting of a marginal energy-based distribution and a structural posterior to handle the difficulties when learning deep EBLVMs on images. By choosing a symmetric KL divergence in the lower level of our framework, a compact BiDVL for visual tasks can be obtained. Our model achieves impressive image generation performance over related works. It also demonstrates the significant capacity of testing image reconstruction and out-of-distribution detection.
End-to-End Human-Gaze-Target Detection with Transformers
Mar 24, 2022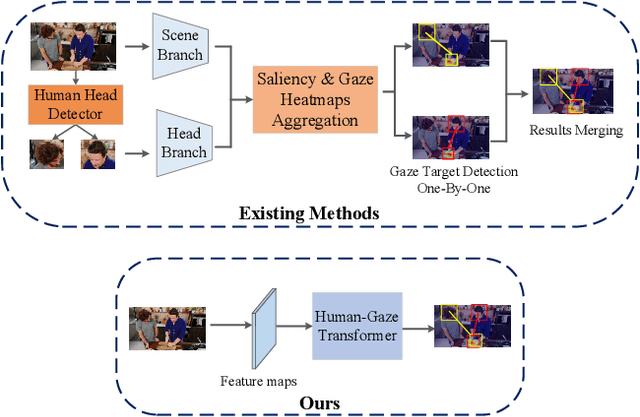
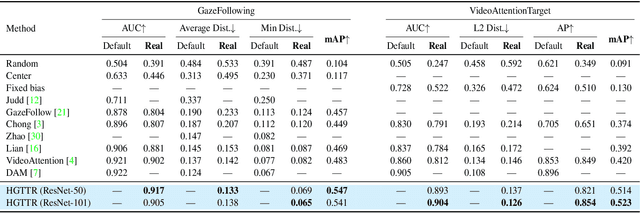
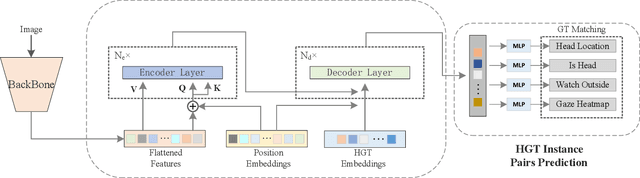
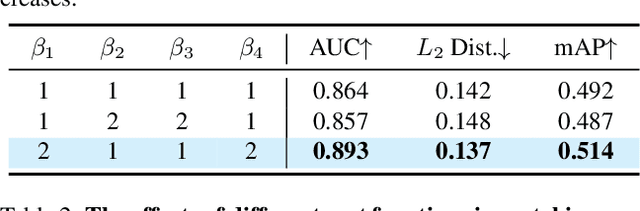
In this paper, we propose an effective and efficient method for Human-Gaze-Target (HGT) detection, i.e., gaze following. Current approaches decouple the HGT detection task into separate branches of salient object detection and human gaze prediction, employing a two-stage framework where human head locations must first be detected and then be fed into the next gaze target prediction sub-network. In contrast, we redefine the HGT detection task as detecting human head locations and their gaze targets, simultaneously. By this way, our method, named Human-Gaze-Target detection TRansformer or HGTTR, streamlines the HGT detection pipeline by eliminating all other additional components. HGTTR reasons about the relations of salient objects and human gaze from the global image context. Moreover, unlike existing two-stage methods that require human head locations as input and can predict only one human's gaze target at a time, HGTTR can directly predict the locations of all people and their gaze targets at one time in an end-to-end manner. The effectiveness and robustness of our proposed method are verified with extensive experiments on the two standard benchmark datasets, GazeFollowing and VideoAttentionTarget. Without bells and whistles, HGTTR outperforms existing state-of-the-art methods by large margins (6.4 mAP gain on GazeFollowing and 10.3 mAP gain on VideoAttentionTarget) with a much simpler architecture.
Iwin: Human-Object Interaction Detection via Transformer with Irregular Windows
Mar 20, 2022
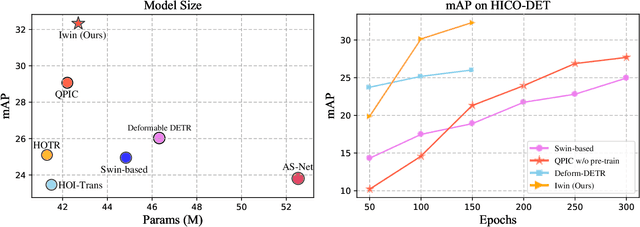
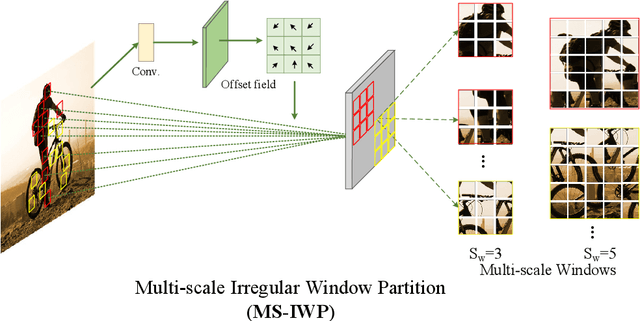
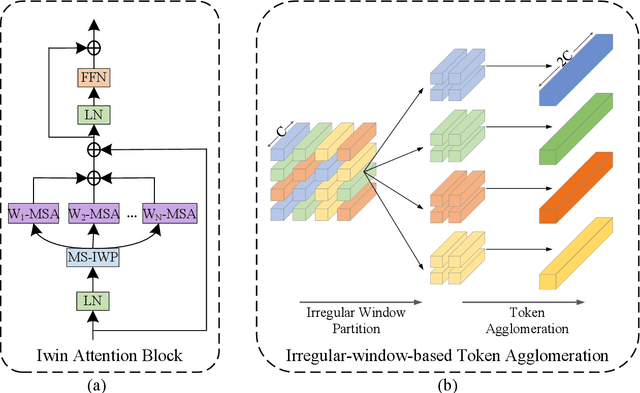
This paper presents a new vision Transformer, named Iwin Transformer, which is specifically designed for human-object interaction (HOI) detection, a detailed scene understanding task involving a sequential process of human/object detection and interaction recognition. Iwin Transformer is a hierarchical Transformer which progressively performs token representation learning and token agglomeration within irregular windows. The irregular windows, achieved by augmenting regular grid locations with learned offsets, 1) eliminate redundancy in token representation learning, which leads to efficient human/object detection, and 2) enable the agglomerated tokens to align with humans/objects with different shapes, which facilitates the acquisition of highly-abstracted visual semantics for interaction recognition. The effectiveness and efficiency of Iwin Transformer are verified on the two standard HOI detection benchmark datasets, HICO-DET and V-COCO. Results show our method outperforms existing Transformers-based methods by large margins (3.7 mAP gain on HICO-DET and 2.0 mAP gain on V-COCO) with fewer training epochs ($0.5 \times$).
Confidence Dimension for Deep Learning based on Hoeffding Inequality and Relative Evaluation
Mar 17, 2022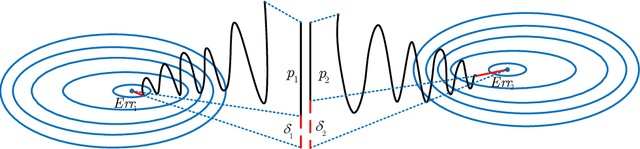
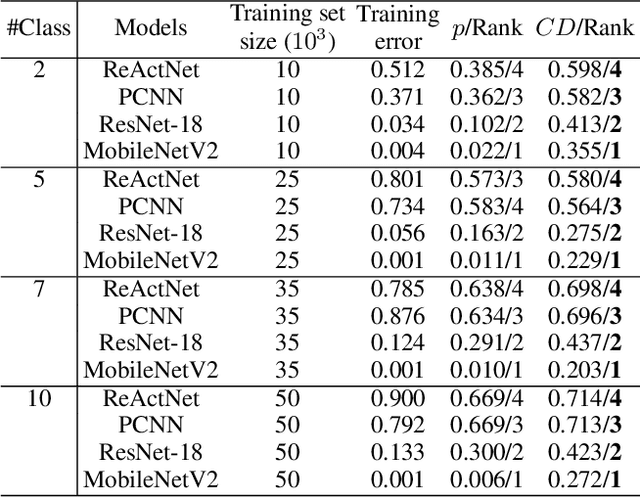
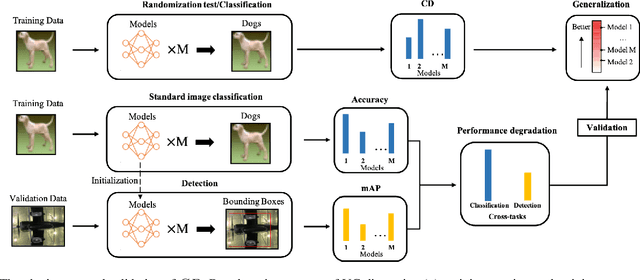
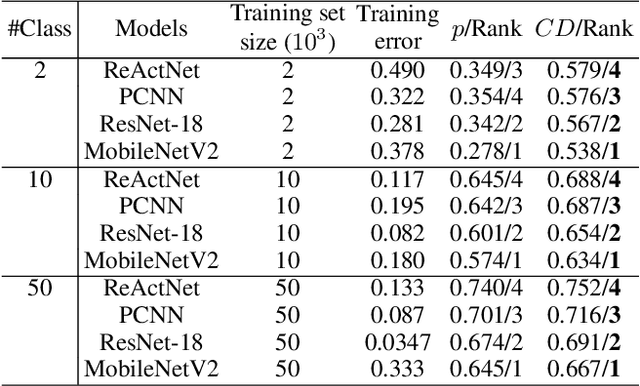
Research on the generalization ability of deep neural networks (DNNs) has recently attracted a great deal of attention. However, due to their complex architectures and large numbers of parameters, measuring the generalization ability of specific DNN models remains an open challenge. In this paper, we propose to use multiple factors to measure and rank the relative generalization of DNNs based on a new concept of confidence dimension (CD). Furthermore, we provide a feasible framework in our CD to theoretically calculate the upper bound of generalization based on the conventional Vapnik-Chervonenk dimension (VC-dimension) and Hoeffding's inequality. Experimental results on image classification and object detection demonstrate that our CD can reflect the relative generalization ability for different DNNs. In addition to full-precision DNNs, we also analyze the generalization ability of binary neural networks (BNNs), whose generalization ability remains an unsolved problem. Our CD yields a consistent and reliable measure and ranking for both full-precision DNNs and BNNs on all the tasks.
Defending Black-box Skeleton-based Human Activity Classifiers
Mar 09, 2022
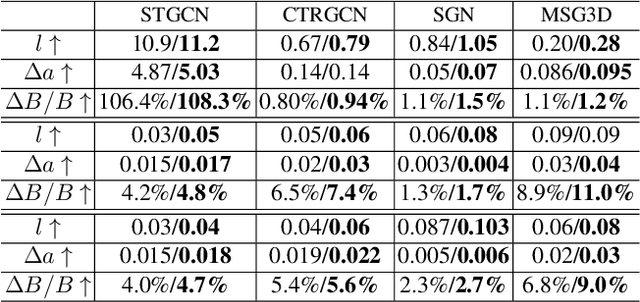
Deep learning has been regarded as the `go to' solution for many tasks today, but its intrinsic vulnerability to malicious attacks has become a major concern. The vulnerability is affected by a variety of factors including models, tasks, data, and attackers. Consequently, methods such as Adversarial Training and Randomized Smoothing have been proposed to tackle the problem in a wide range of applications. In this paper, we investigate skeleton-based Human Activity Recognition, which is an important type of time-series data but under-explored in defense against attacks. Our method is featured by (1) a new Bayesian Energy-based formulation of robust discriminative classifiers, (2) a new parameterization of the adversarial sample manifold of actions, and (3) a new post-train Bayesian treatment on both the adversarial samples and the classifier. We name our framework Bayesian Energy-based Adversarial Training or BEAT. BEAT is straightforward but elegant, which turns vulnerable black-box classifiers into robust ones without sacrificing accuracy. It demonstrates surprising and universal effectiveness across a wide range of action classifiers and datasets, under various attacks.
Dynamic Group Transformer: A General Vision Transformer Backbone with Dynamic Group Attention
Mar 09, 2022
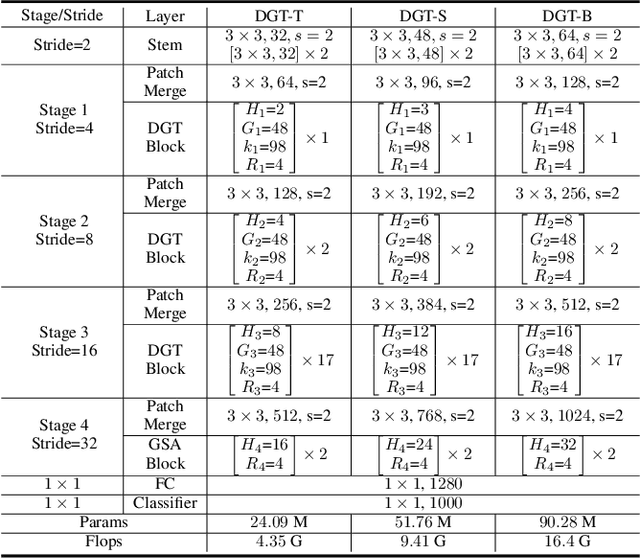
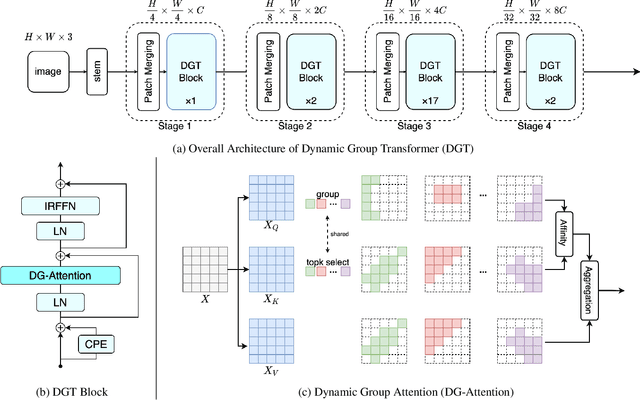
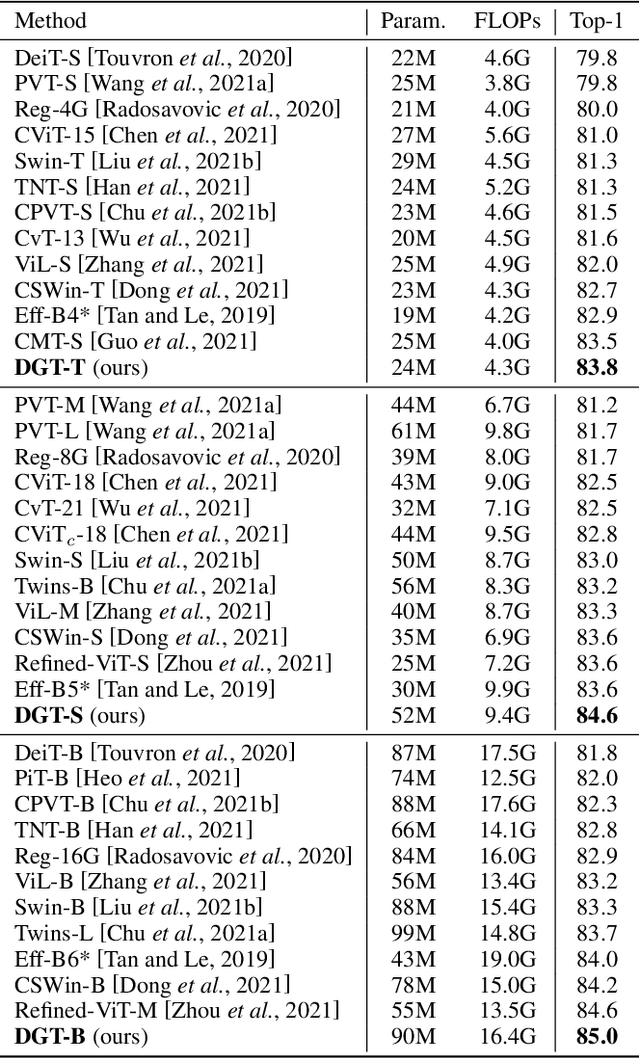
Recently, Transformers have shown promising performance in various vision tasks. To reduce the quadratic computation complexity caused by each query attending to all keys/values, various methods have constrained the range of attention within local regions, where each query only attends to keys/values within a hand-crafted window. However, these hand-crafted window partition mechanisms are data-agnostic and ignore their input content, so it is likely that one query maybe attends to irrelevant keys/values. To address this issue, we propose a Dynamic Group Attention (DG-Attention), which dynamically divides all queries into multiple groups and selects the most relevant keys/values for each group. Our DG-Attention can flexibly model more relevant dependencies without any spatial constraint that is used in hand-crafted window based attention. Built on the DG-Attention, we develop a general vision transformer backbone named Dynamic Group Transformer (DGT). Extensive experiments show that our models can outperform the state-of-the-art methods on multiple common vision tasks, including image classification, semantic segmentation, object detection, and instance segmentation.