 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning Paths through Occlusions in Urban Environments
Dec 29, 2022



This paper presents a novel framework for planning in unknown and occluded urban spaces. We specifically focus on turns and intersections where occlusions significantly impact navigability. Our approach uses an inpainting model to fill in a sparse, occluded, semantic lidar point cloud and plans dynamically feasible paths for a vehicle to traverse through the open and inpainted spaces. We demonstrate our approach using a car's lidar data with real-time occlusions, and show that by inpainting occluded areas, we can plan longer paths, with more turn options compared to without inpainting; in addition, our approach more closely follows paths derived from a planner with no occlusions (called the ground truth) compared to other state of the art approaches.
Adversarial Pretraining of Self-Supervised Deep Networks: Past, Present and Future
Oct 23, 2022



In this paper, we review adversarial pretraining of self-supervised deep networks including both convolutional neural networks and vision transformers. Unlike the adversarial training with access to labeled examples, adversarial pretraining is complicated as it only has access to unlabeled examples. To incorporate adversaries into pretraining models on either input or feature level, we find that existing approaches are largely categorized into two groups: memory-free instance-wise attacks imposing worst-case perturbations on individual examples, and memory-based adversaries shared across examples over iterations. In particular, we review several representative adversarial pretraining models based on Contrastive Learning (CL) and Masked Image Modeling (MIM), respectively, two popular self-supervised pretraining methods in literature. We also review miscellaneous issues about computing overheads, input-/feature-level adversaries, as well as other adversarial pretraining approaches beyond the above two groups. Finally, we discuss emerging trends and future directions about the relations between adversarial and cooperative pretraining, unifying adversarial CL and MIM pretraining, and the trade-off between accuracy and robustness in adversarial pretraining.
Exploring Resolution and Degradation Clues as Self-supervised Signal for Low Quality Object Detection
Aug 05, 2022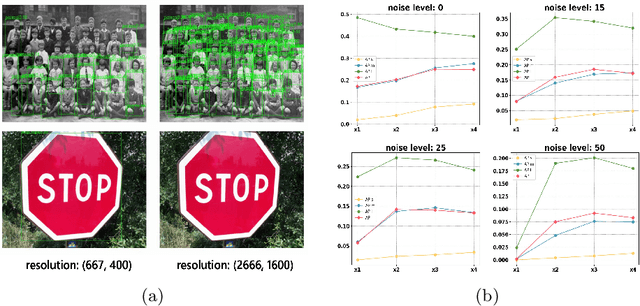
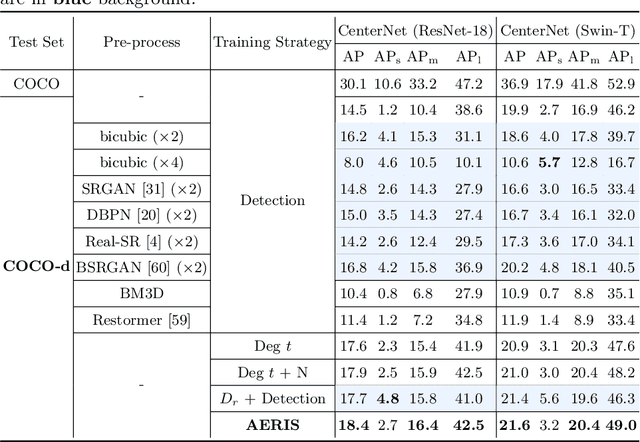
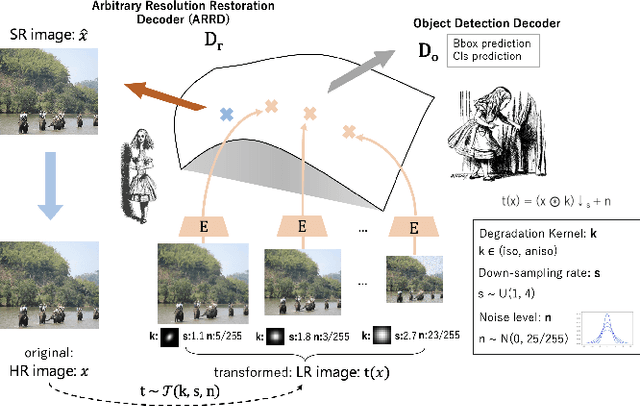
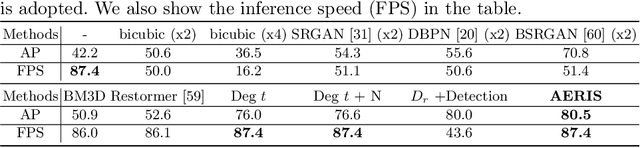
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in low quality images. Most of these algorithms assume the degradation is fixed and known a priori. However, in practical, either the real degradation or optimal up-sampling ratio rate is unknown or differs from assumption, leading to a deteriorating performance for both the pre-processing module and the consequent high-level task such as object detection. Here, we propose a novel self-supervised framework to detect objects in degraded low resolution images. We utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. The Auto Encoding Resolution in Self-supervision (AERIS) framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. The generic AERIS framework could be implemented on various mainstream object detection architectures with different backbones. The extensive experiments show that our methods has achieved superior performance compared with existing methods when facing variant degradation situations. Code would be released at https://github.com/cuiziteng/ECCV_AERIS.
AIParsing: Anchor-free Instance-level Human Parsing
Jul 14, 2022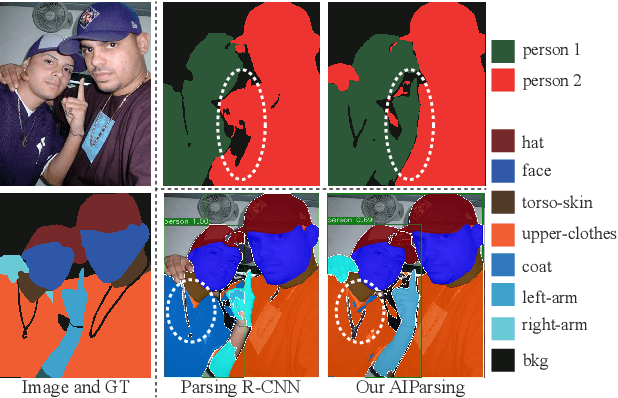
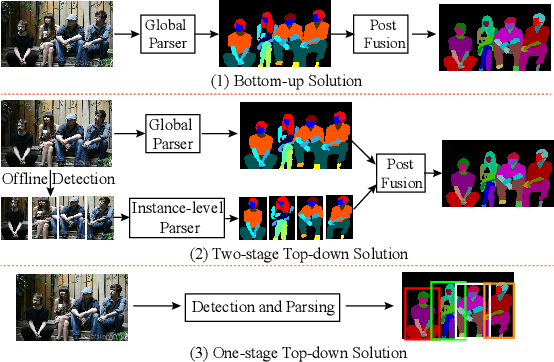
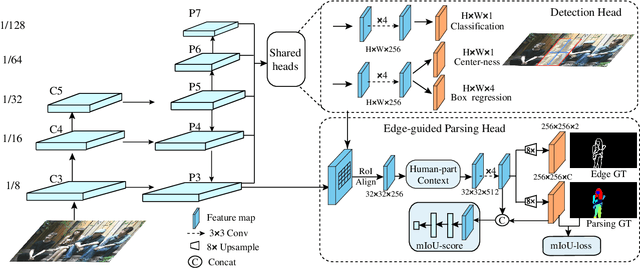

Most state-of-the-art instance-level human parsing models adopt two-stage anchor-based detectors and, therefore, cannot avoid the heuristic anchor box design and the lack of analysis on a pixel level. To address these two issues, we have designed an instance-level human parsing network which is anchor-free and solvable on a pixel level. It consists of two simple sub-networks: an anchor-free detection head for bounding box predictions and an edge-guided parsing head for human segmentation. The anchor-free detector head inherits the pixel-like merits and effectively avoids the sensitivity of hyper-parameters as proved in object detection applications. By introducing the part-aware boundary clue, the edge-guided parsing head is capable to distinguish adjacent human parts from among each other up to 58 parts in a single human instance, even overlapping instances. Meanwhile, a refinement head integrating box-level score and part-level parsing quality is exploited to improve the quality of the parsing results. Experiments on two multiple human parsing datasets (i.e., CIHP and LV-MHP-v2.0) and one video instance-level human parsing dataset (i.e., VIP) show that our method achieves the best global-level and instance-level performance over state-of-the-art one-stage top-down alternatives.
Cross-receptive Focused Inference Network for Lightweight Image Super-Resolution
Jul 06, 2022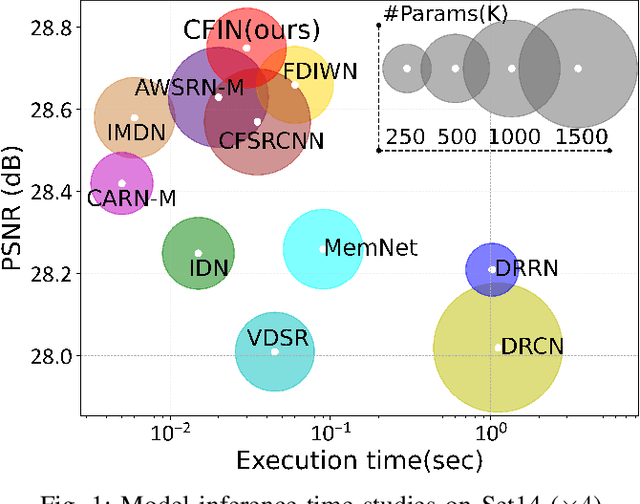
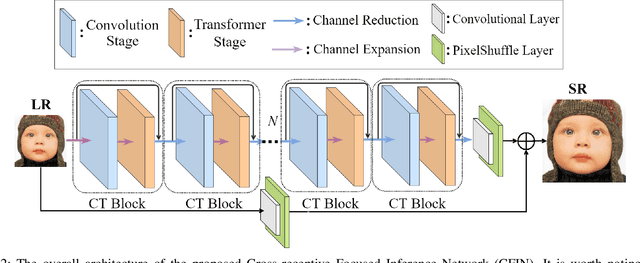
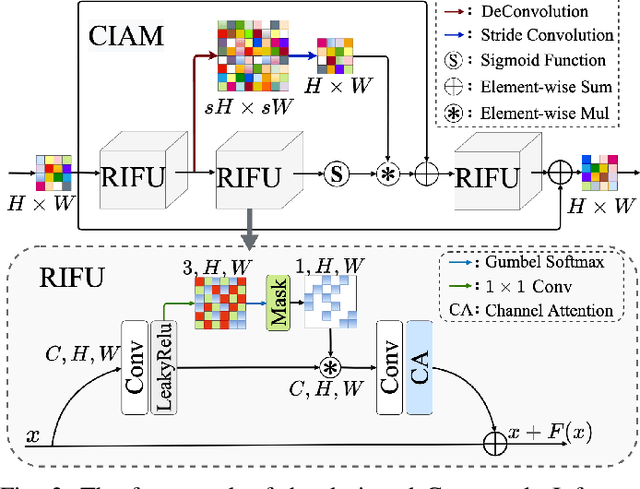
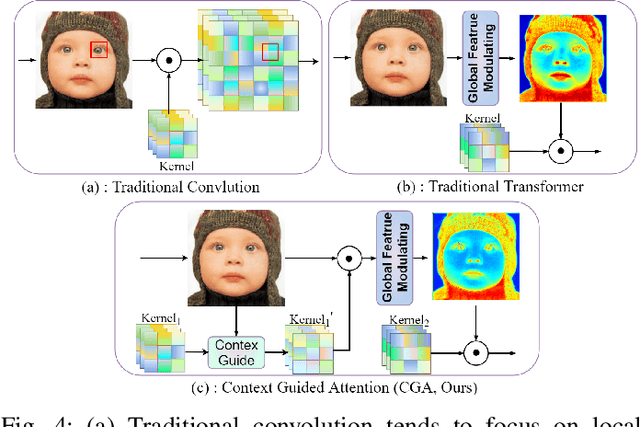
With the development of deep learning, single image super-resolution (SISR) has achieved significant breakthroughs. Recently, methods to enhance the performance of SISR networks based on global feature interactions have been proposed. However, the capabilities of neurons that need to adjust their function in response to the context dynamically are neglected. To address this issue, we propose a lightweight Cross-receptive Focused Inference Network (CFIN), a hybrid network composed of a Convolutional Neural Network (CNN) and a Transformer. Specifically, a novel Cross-receptive Field Guide Transformer (CFGT) is designed to adaptively modify the network weights by using modulated convolution kernels combined with local representative semantic information. In addition, a CNN-based Cross-scale Information Aggregation Module (CIAM) is proposed to make the model better focused on potentially practical information and improve the efficiency of the Transformer stage. Extensive experiments show that our proposed CFIN is a lightweight and efficient SISR model, which can achieve a good balance between computational cost and model performance.
Multitask AET with Orthogonal Tangent Regularity for Dark Object Detection
May 06, 2022

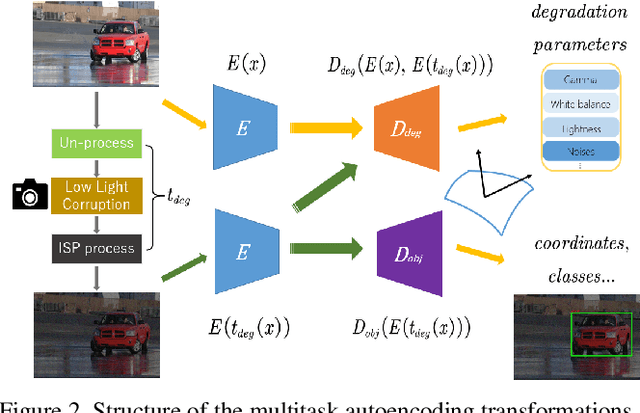

Dark environment becomes a challenge for computer vision algorithms owing to insufficient photons and undesirable noise. To enhance object detection in a dark environment, we propose a novel multitask auto encoding transformation (MAET) model which is able to explore the intrinsic pattern behind illumination translation. In a self-supervision manner, the MAET learns the intrinsic visual structure by encoding and decoding the realistic illumination-degrading transformation considering the physical noise model and image signal processing (ISP). Based on this representation, we achieve the object detection task by decoding the bounding box coordinates and classes. To avoid the over-entanglement of two tasks, our MAET disentangles the object and degrading features by imposing an orthogonal tangent regularity. This forms a parametric manifold along which multitask predictions can be geometrically formulated by maximizing the orthogonality between the tangents along the outputs of respective tasks. Our framework can be implemented based on the mainstream object detection architecture and directly trained end-to-end using normal target detection datasets, such as VOC and COCO. We have achieved the state-of-the-art performance using synthetic and real-world datasets. Code is available at https://github.com/cuiziteng/MAET.
CTCNet: A CNN-Transformer Cooperation Network for Face Image Super-Resolution
Apr 19, 2022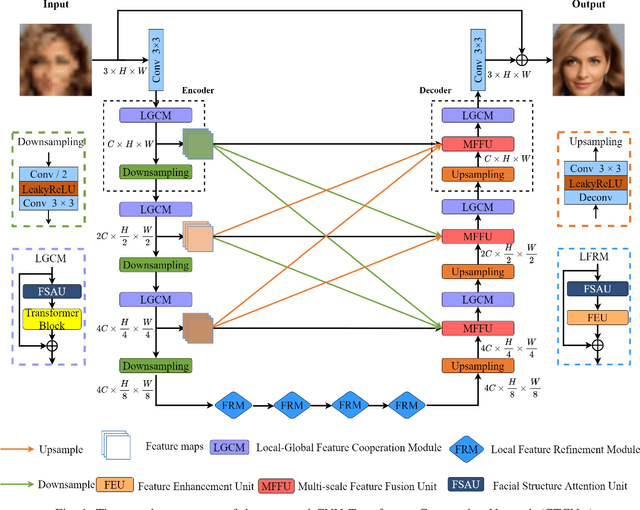

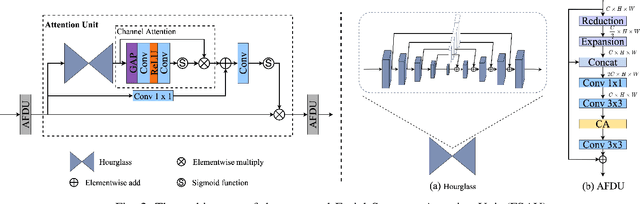
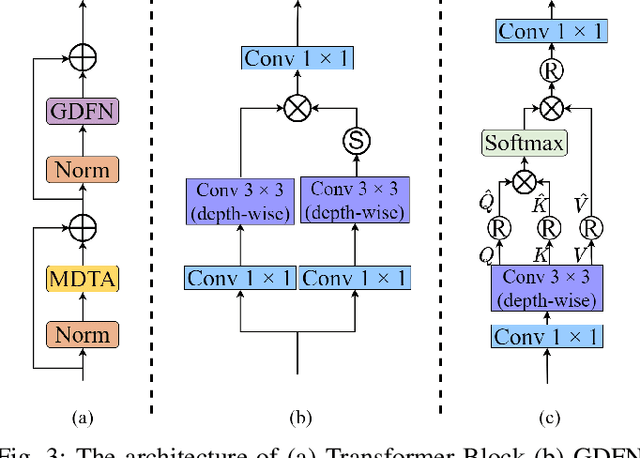
Recently, deep convolution neural networks (CNNs) steered face super-resolution methods have achieved great progress in restoring degraded facial details by jointly training with facial priors. However, these methods have some obvious limitations. On the one hand, multi-task joint learning requires additional marking on the dataset, and the introduced prior network will significantly increase the computational cost of the model. On the other hand, the limited receptive field of CNN will reduce the fidelity and naturalness of the reconstructed facial images, resulting in suboptimal reconstructed images. In this work, we propose an efficient CNN-Transformer Cooperation Network (CTCNet) for face super-resolution tasks, which uses the multi-scale connected encoder-decoder architecture as the backbone. Specifically, we first devise a novel Local-Global Feature Cooperation Module (LGCM), which is composed of a Facial Structure Attention Unit (FSAU) and a Transformer block, to promote the consistency of local facial detail and global facial structure restoration simultaneously. Then, we design an efficient Local Feature Refinement Module (LFRM) to enhance the local facial structure information. Finally, to further improve the restoration of fine facial details, we present a Multi-scale Feature Fusion Unit (MFFU) to adaptively fuse the features from different stages in the encoder procedure. Comprehensive evaluations on various datasets have assessed that the proposed CTCNet can outperform other state-of-the-art methods significantly.
CaCo: Both Positive and Negative Samples are Directly Learnable via Cooperative-adversarial Contrastive Learning
Mar 27, 2022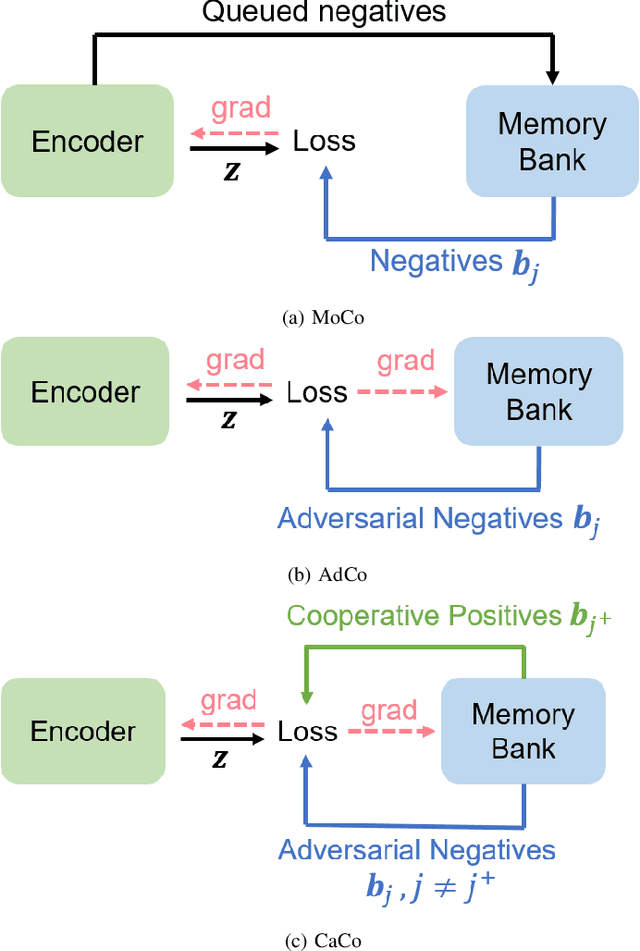
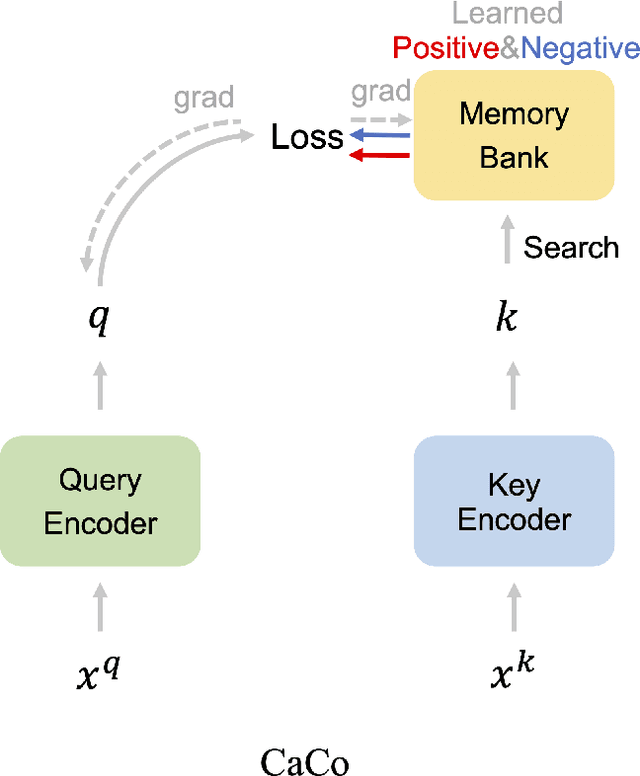

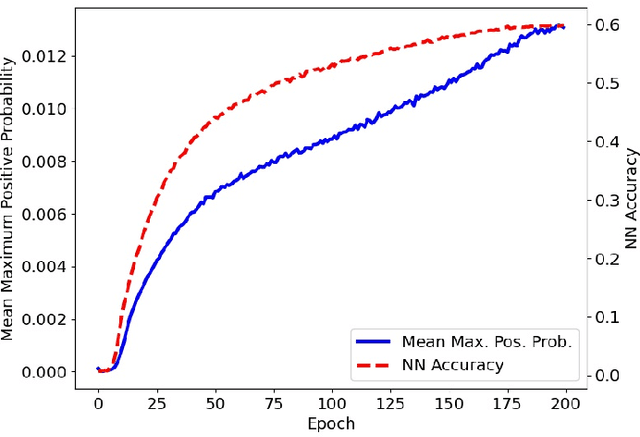
As a representative self-supervised method, contrastive learning has achieved great successes in unsupervised training of representations. It trains an encoder by distinguishing positive samples from negative ones given query anchors. These positive and negative samples play critical roles in defining the objective to learn the discriminative encoder, avoiding it from learning trivial features. While existing methods heuristically choose these samples, we present a principled method where both positive and negative samples are directly learnable end-to-end with the encoder. We show that the positive and negative samples can be cooperatively and adversarially learned by minimizing and maximizing the contrastive loss, respectively. This yields cooperative positives and adversarial negatives with respect to the encoder, which are updated to continuously track the learned representation of the query anchors over mini-batches. The proposed method achieves 71.3% and 75.3% in top-1 accuracy respectively over 200 and 800 epochs of pre-training ResNet-50 backbone on ImageNet1K without tricks such as multi-crop or stronger augmentations. With Multi-Crop, it can be further boosted into 75.7%. The source code and pre-trained model are released in https://github.com/maple-research-lab/caco.
Dual-Flattening Transformers through Decomposed Row and Column Queries for Semantic Segmentation
Jan 22, 2022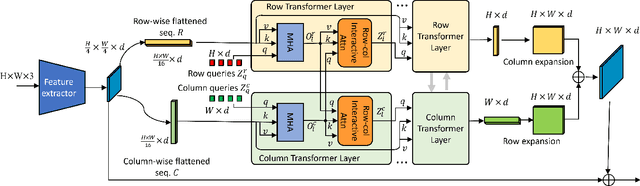

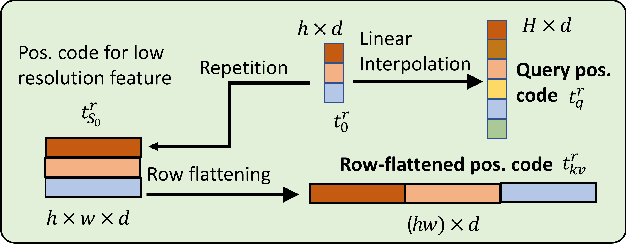
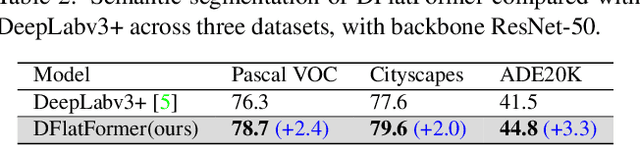
It is critical to obtain high resolution features with long range dependency for dense prediction tasks such as semantic segmentation. To generate high-resolution output of size $H\times W$ from a low-resolution feature map of size $h\times w$ ($hw\ll HW$), a naive dense transformer incurs an intractable complexity of $\mathcal{O}(hwHW)$, limiting its application on high-resolution dense prediction. We propose a Dual-Flattening Transformer (DFlatFormer) to enable high-resolution output by reducing complexity to $\mathcal{O}(hw(H+W))$ that is multiple orders of magnitude smaller than the naive dense transformer. Decomposed queries are presented to retrieve row and column attentions tractably through separate transformers, and their outputs are combined to form a dense feature map at high resolution. To this end, the input sequence fed from an encoder is row-wise and column-wise flattened to align with decomposed queries by preserving their row and column structures, respectively. Row and column transformers also interact with each other to capture their mutual attentions with the spatial crossings between rows and columns. We also propose to perform attentions through efficient grouping and pooling to further reduce the model complexity. Extensive experiments on ADE20K and Cityscapes datasets demonstrate the superiority of the proposed dual-flattening transformer architecture with higher mIoUs.
RestoreDet: Degradation Equivariant Representation for Object Detection in Low Resolution Images
Jan 07, 2022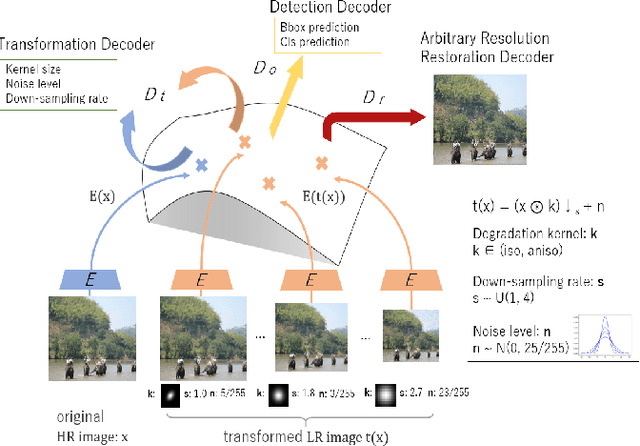
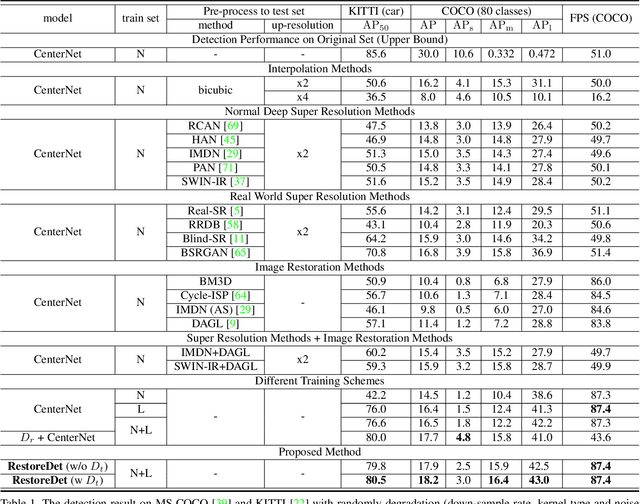
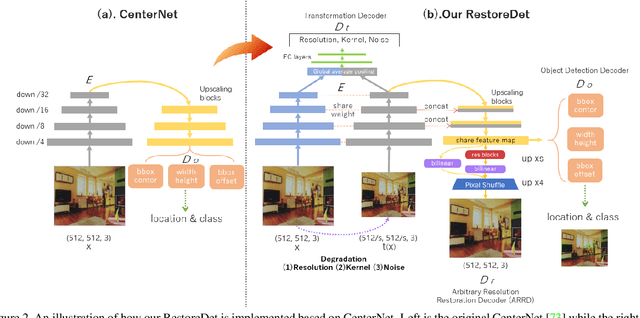
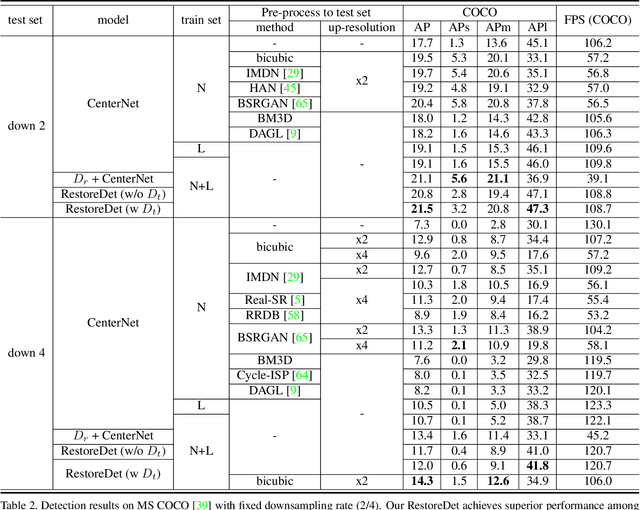
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in degraded images. However, most of these algorithms assume the degradation is fixed and known a priori. When the real degradation is unknown or differs from assumption, both the pre-processing module and the consequent high-level task such as object detection would fail. Here, we propose a novel framework, RestoreDet, to detect objects in degraded low resolution images. RestoreDet utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. Specifically, we learn this intrinsic visual structure by encoding and decoding the degradation transformation from a pair of original and randomly degraded images. The framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. RestoreDet is a generic framework that could be implemented on any mainstream object detection architectures. The extensive experiment shows that our framework based on CenterNet has achieved superior performance compared with existing methods when facing variant degradation situations. Our code would be released soon.