 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERVD: An Efficient and Robust ViT-Based Distillation Framework for Remote Sensing Image Retrieval
Dec 24, 2024



ERVD: An Efficient and Robust ViT-Based Distillation Framework for Remote Sensing Image Retrieval
E-Motion: Future Motion Simulation via Event Sequence Diffusion
Oct 11, 2024Forecasting a typical object's future motion is a critical task for interpreting and interacting with dynamic environments in computer vision. Event-based sensors, which could capture changes in the scene with exceptional temporal granularity, may potentially offer a unique opportunity to predict future motion with a level of detail and precision previously unachievable. Inspired by that, we propose to integrate the strong learning capacity of the video diffusion model with the rich motion information of an event camera as a motion simulation framework. Specifically, we initially employ pre-trained stable video diffusion models to adapt the event sequence dataset. This process facilitates the transfer of extensive knowledge from RGB videos to an event-centric domain. Moreover, we introduce an alignment mechanism that utilizes reinforcement learning techniques to enhance the reverse generation trajectory of the diffusion model, ensuring improved performance and accuracy. Through extensive testing and validation, we demonstrate the effectiveness of our method in various complex scenarios, showcasing its potential to revolutionize motion flow prediction in computer vision applications such as autonomous vehicle guidance, robotic navigation, and interactive media. Our findings suggest a promising direction for future research in enhancing the interpretative power and predictive accuracy of computer vision systems.
Semantic Feature Division Multiple Access for Multi-user Digital Interference Networks
Jul 11, 2024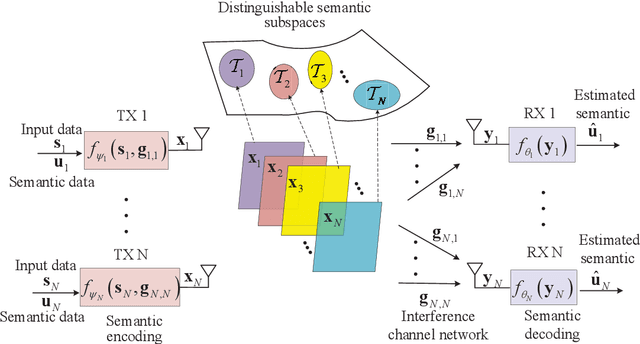


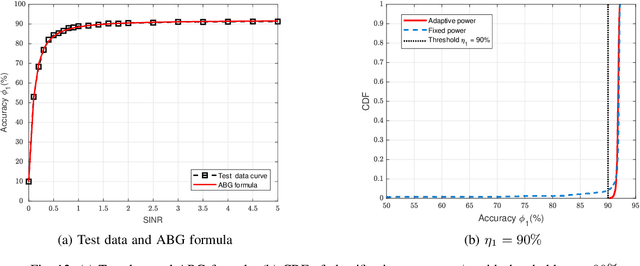
With the ever-increasing user density and quality of service (QoS) demand,5G networks with limited spectrum resources are facing massive access challenges. To address these challenges, in this paper, we propose a novel discrete semantic feature division multiple access (SFDMA) paradigm for multi-user digital interference networks. Specifically, by utilizing deep learning technology, SFDMA extracts multi-user semantic information into discrete representations in distinguishable semantic subspaces, which enables multiple users to transmit simultaneously over the same time-frequency resources. Furthermore, based on a robust information bottleneck, we design a SFDMA based multi-user digital semantic interference network for inference tasks, which can achieve approximate orthogonal transmission. Moreover, we propose a SFDMA based multi-user digital semantic interference network for image reconstruction tasks, where the discrete outputs of the semantic encoders of the users are approximately orthogonal, which significantly reduces multi-user interference. Furthermore, we propose an Alpha-Beta-Gamma (ABG) formula for semantic communications, which is the first theoretical relationship between inference accuracy and transmission power. Then, we derive adaptive power control methods with closed-form expressions for inference tasks. Extensive simulations verify the effectiveness and superiority of the proposed SFDMA.
Back to the Color: Learning Depth to Specific Color Transformation for Unsupervised Depth Estimation
Jun 11, 2024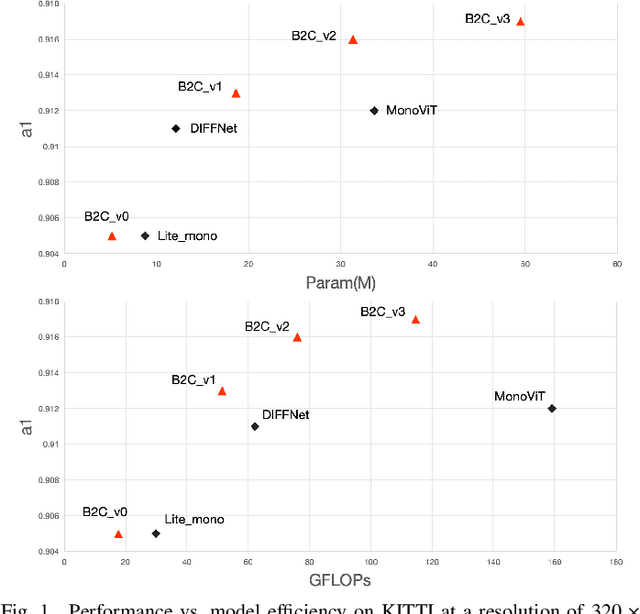



Virtual engines have the capability to generate dense depth maps for various synthetic scenes, making them invaluable for training depth estimation models. However, synthetic colors often exhibit significant discrepancies compared to real-world colors, thereby posing challenges for depth estimation in real-world scenes, particularly in complex and uncertain environments encountered in unsupervised monocular depth estimation tasks. To address this issue, we propose Back2Color, a framework that predicts realistic colors from depth utilizing a model trained on real-world data, thus facilitating the transformation of synthetic colors into real-world counterparts. Additionally, by employing the Syn-Real CutMix method for joint training with both real-world unsupervised and synthetic supervised depth samples, we achieve improved performance in monocular depth estimation for real-world scenes. Moreover, to comprehensively address the impact of non-rigid motions on depth estimation, we propose an auto-learning uncertainty temporal-spatial fusion method (Auto-UTSF), which integrates the benefits of unsupervised learning in both temporal and spatial dimensions. Furthermore, we design a depth estimation network (VADepth) based on the Vision Attention Network. Our Back2Color framework demonstrates state-of-the-art performance, as evidenced by improvements in performance metrics and the production of fine-grained details in our predictions, particularly on challenging datasets such as Cityscapes for unsupervised depth estimation.
AesExpert: Towards Multi-modality Foundation Model for Image Aesthetics Perception
Apr 15, 2024



The highly abstract nature of image aesthetics perception (IAP) poses significant challenge for current multimodal large language models (MLLMs). The lack of human-annotated multi-modality aesthetic data further exacerbates this dilemma, resulting in MLLMs falling short of aesthetics perception capabilities. To address the above challenge, we first introduce a comprehensively annotated Aesthetic Multi-Modality Instruction Tuning (AesMMIT) dataset, which serves as the footstone for building multi-modality aesthetics foundation models. Specifically, to align MLLMs with human aesthetics perception, we construct a corpus-rich aesthetic critique database with 21,904 diverse-sourced images and 88K human natural language feedbacks, which are collected via progressive questions, ranging from coarse-grained aesthetic grades to fine-grained aesthetic descriptions. To ensure that MLLMs can handle diverse queries, we further prompt GPT to refine the aesthetic critiques and assemble the large-scale aesthetic instruction tuning dataset, i.e. AesMMIT, which consists of 409K multi-typed instructions to activate stronger aesthetic capabilities. Based on the AesMMIT database, we fine-tune the open-sourced general foundation models, achieving multi-modality Aesthetic Expert models, dubbed AesExpert. Extensive experiments demonstrate that the proposed AesExpert models deliver significantly better aesthetic perception performances than the state-of-the-art MLLMs, including the most advanced GPT-4V and Gemini-Pro-Vision. Source data will be available at https://github.com/yipoh/AesExpert.
Fast Window-Based Event Denoising with Spatiotemporal Correlation Enhancement
Feb 14, 2024



Previous deep learning-based event denoising methods mostly suffer from poor interpretability and difficulty in real-time processing due to their complex architecture designs. In this paper, we propose window-based event denoising, which simultaneously deals with a stack of events while existing element-based denoising focuses on one event each time. Besides, we give the theoretical analysis based on probability distributions in both temporal and spatial domains to improve interpretability. In temporal domain, we use timestamp deviations between processing events and central event to judge the temporal correlation and filter out temporal-irrelevant events. In spatial domain, we choose maximum a posteriori (MAP) to discriminate real-world event and noise, and use the learned convolutional sparse coding to optimize the objective function. Based on the theoretical analysis, we build Temporal Window (TW) module and Soft Spatial Feature Embedding (SSFE) module to process temporal and spatial information separately, and construct a novel multi-scale window-based event denoising network, named MSDNet. The high denoising accuracy and fast running speed of our MSDNet enables us to achieve real-time denoising in complex scenes. Extensive experimental results verify the effectiveness and robustness of our MSDNet. Our algorithm can remove event noise effectively and efficiently and improve the performance of downstream tasks.
Swin-UMamba: Mamba-based UNet with ImageNet-based pretraining
Feb 05, 2024



Accurate medical image segmentation demands the integration of multi-scale information, spanning from local features to global dependencies. However, it is challenging for existing methods to model long-range global information, where convolutional neural networks (CNNs) are constrained by their local receptive fields, and vision transformers (ViTs) suffer from high quadratic complexity of their attention mechanism. Recently, Mamba-based models have gained great attention for their impressive ability in long sequence modeling. Several studies have demonstrated that these models can outperform popular vision models in various tasks, offering higher accuracy, lower memory consumption, and less computational burden. However, existing Mamba-based models are mostly trained from scratch and do not explore the power of pretraining, which has been proven to be quite effective for data-efficient medical image analysis. This paper introduces a novel Mamba-based model, Swin-UMamba, designed specifically for medical image segmentation tasks, leveraging the advantages of ImageNet-based pretraining. Our experimental results reveal the vital role of ImageNet-based training in enhancing the performance of Mamba-based models. Swin-UMamba demonstrates superior performance with a large margin compared to CNNs, ViTs, and latest Mamba-based models. Notably, on AbdomenMRI, Encoscopy, and Microscopy datasets, Swin-UMamba outperforms its closest counterpart U-Mamba by an average score of 3.58%. The code and models of Swin-UMamba are publicly available at: https://github.com/JiarunLiu/Swin-UMamba
PACE: A Pragmatic Agent for Enhancing Communication Efficiency Using Large Language Models
Jan 30, 2024Current communication technologies face limitations in terms of theoretical capacity, spectrum availability, and power resources. Pragmatic communication, leveraging terminal intelligence for selective data transmission, offers resource conservation. Existing research lacks universal intention resolution tools, limiting applicability to specific tasks. This paper proposes an image pragmatic communication framework based on a Pragmatic Agent for Communication Efficiency (PACE) using Large Language Models (LLM). In this framework, PACE sequentially performs semantic perception, intention resolution, and intention-oriented coding. To ensure the effective utilization of LLM in communication, a knowledge base is designed to supplement the necessary knowledge, dedicated prompts are introduced to facilitate understanding of pragmatic communication scenarios and task requirements, and a chain of thought is designed to assist in making reasonable trade-offs between transmission efficiency and cost. For experimental validation, this paper constructs an image pragmatic communication dataset along with corresponding evaluation standards. Simulation results indicate that the proposed method outperforms traditional and non-LLM-based pragmatic communication in terms of transmission efficiency.
Self-supervised Learning of LiDAR 3D Point Clouds via 2D-3D Neural Calibration
Jan 23, 2024



This paper introduces a novel self-supervised learning framework for enhancing 3D perception in autonomous driving scenes. Specifically, our approach, named NCLR, focuses on 2D-3D neural calibration, a novel pretext task that estimates the rigid transformation aligning camera and LiDAR coordinate systems. First, we propose the learnable transformation alignment to bridge the domain gap between image and point cloud data, converting features into a unified representation space for effective comparison and matching. Second, we identify the overlapping area between the image and point cloud with the fused features. Third, we establish dense 2D-3D correspondences to estimate the rigid transformation. The framework not only learns fine-grained matching from points to pixels but also achieves alignment of the image and point cloud at a holistic level, understanding their relative pose. We demonstrate NCLR's efficacy by applying the pre-trained backbone to downstream tasks, such as LiDAR-based 3D semantic segmentation, object detection, and panoptic segmentation. Comprehensive experiments on various datasets illustrate the superiority of NCLR over existing self-supervised methods. The results confirm that joint learning from different modalities significantly enhances the network's understanding abilities and effectiveness of learned representation. Code will be available at \url{https://github.com/Eaphan/NCLR}.
Segment Any Events via Weighted Adaptation of Pivotal Tokens
Dec 24, 2023In this paper, we delve into the nuanced challenge of tailoring the Segment Anything Models (SAMs) for integration with event data, with the overarching objective of attaining robust and universal object segmentation within the event-centric domain. One pivotal issue at the heart of this endeavor is the precise alignment and calibration of embeddings derived from event-centric data such that they harmoniously coincide with those originating from RGB imagery. Capitalizing on the vast repositories of datasets with paired events and RGB images, our proposition is to harness and extrapolate the profound knowledge encapsulated within the pre-trained SAM framework. As a cornerstone to achieving this, we introduce a multi-scale feature distillation methodology. This methodology rigorously optimizes the alignment of token embeddings originating from event data with their RGB image counterparts, thereby preserving and enhancing the robustness of the overall architecture. Considering the distinct significance that token embeddings from intermediate layers hold for higher-level embeddings, our strategy is centered on accurately calibrating the pivotal token embeddings. This targeted calibration is aimed at effectively managing the discrepancies in high-level embeddings originating from both the event and image domains. Extensive experiments on different datasets demonstrate the effectiveness of the proposed distillation method. Code in http://github.com/happychenpipi/EventSAM.