 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuandong Xu
An Extended Variational Mode Decomposition Algorithm Developed Speech Emotion Recognition Performance
Dec 18, 2023
Emotion recognition (ER) from speech signals is a robust approach since it cannot be imitated like facial expression or text based sentiment analysis. Valuable information underlying the emotions are significant for human-computer interactions enabling intelligent machines to interact with sensitivity in the real world. Previous ER studies through speech signal processing have focused exclusively on associations between different signal mode decomposition methods and hidden informative features. However, improper decomposition parameter selections lead to informative signal component losses due to mode duplicating and mixing. In contrast, the current study proposes VGG-optiVMD, an empowered variational mode decomposition algorithm, to distinguish meaningful speech features and automatically select the number of decomposed modes and optimum balancing parameter for the data fidelity constraint by assessing their effects on the VGG16 flattening output layer. Various feature vectors were employed to train the VGG16 network on different databases and assess VGG-optiVMD reproducibility and reliability. One, two, and three-dimensional feature vectors were constructed by concatenating Mel-frequency cepstral coefficients, Chromagram, Mel spectrograms, Tonnetz diagrams, and spectral centroids. Results confirmed a synergistic relationship between the fine-tuning of the signal sample rate and decomposition parameters with classification accuracy, achieving state-of-the-art 96.09% accuracy in predicting seven emotions on the Berlin EMO-DB database.
* 12 pages
Churn Prediction via Multimodal Fusion Learning:Integrating Customer Financial Literacy, Voice, and Behavioral Data
Dec 03, 2023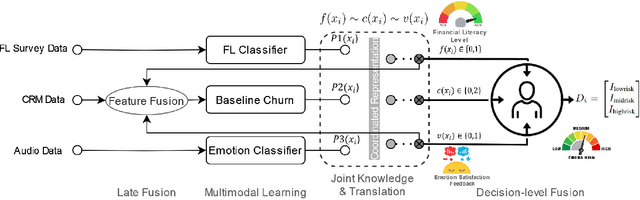
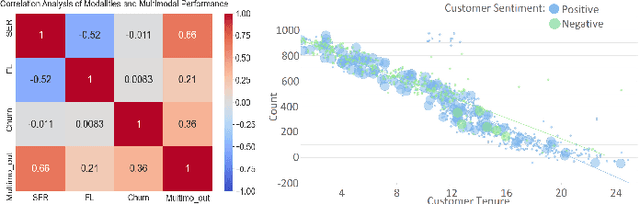
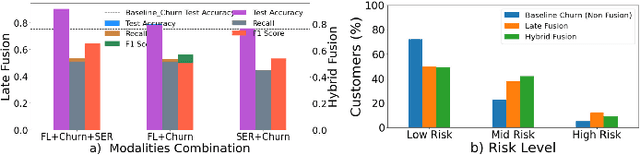
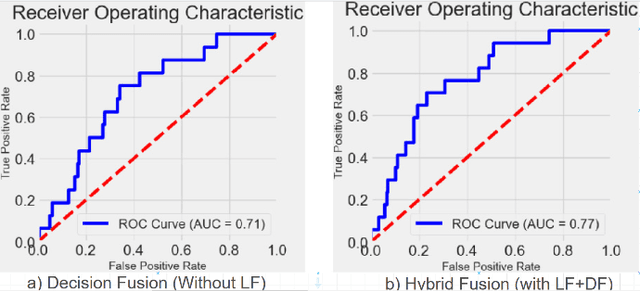
In todays competitive landscape, businesses grapple with customer retention. Churn prediction models, although beneficial, often lack accuracy due to the reliance on a single data source. The intricate nature of human behavior and high dimensional customer data further complicate these efforts. To address these concerns, this paper proposes a multimodal fusion learning model for identifying customer churn risk levels in financial service providers. Our multimodal approach integrates customer sentiments financial literacy (FL) level, and financial behavioral data, enabling more accurate and bias-free churn prediction models. The proposed FL model utilizes a SMOGN COREG supervised model to gauge customer FL levels from their financial data. The baseline churn model applies an ensemble artificial neural network and oversampling techniques to predict churn propensity in high-dimensional financial data. We also incorporate a speech emotion recognition model employing a pre-trained CNN-VGG16 to recognize customer emotions based on pitch, energy, and tone. To integrate these diverse features while retaining unique insights, we introduced late and hybrid fusion techniques that complementary boost coordinated multimodal co learning. Robust metrics were utilized to evaluate the proposed multimodal fusion model and hence the approach validity, including mean average precision and macro-averaged F1 score. Our novel approach demonstrates a marked improvement in churn prediction, achieving a test accuracy of 91.2%, a Mean Average Precision (MAP) score of 66, and a Macro-Averaged F1 score of 54 through the proposed hybrid fusion learning technique compared with late fusion and baseline models. Furthermore, the analysis demonstrates a positive correlation between negative emotions, low FL scores, and high-risk customers.
GATGPT: A Pre-trained Large Language Model with Graph Attention Network for Spatiotemporal Imputation
Nov 24, 2023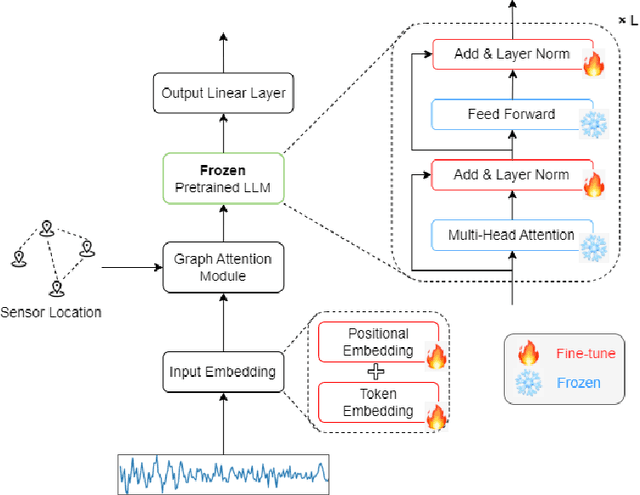
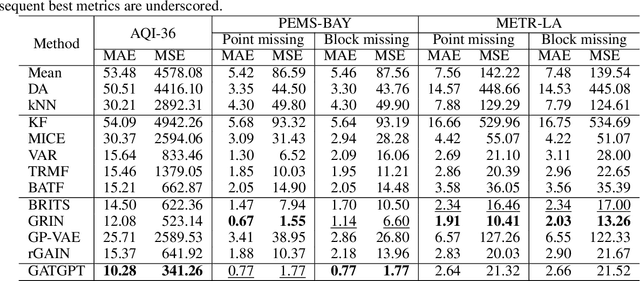
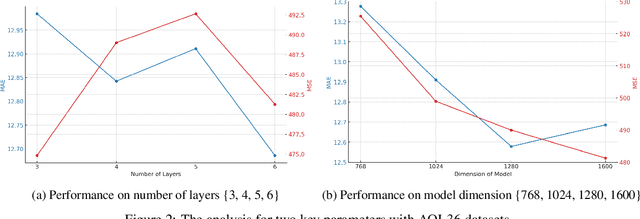
The analysis of spatiotemporal data is increasingly utilized across diverse domains, including transportation, healthcare, and meteorology. In real-world settings, such data often contain missing elements due to issues like sensor malfunctions and data transmission errors. The objective of spatiotemporal imputation is to estimate these missing values by understanding the inherent spatial and temporal relationships in the observed multivariate time series. Traditionally, spatiotemporal imputation has relied on specific, intricate architectures designed for this purpose, which suffer from limited applicability and high computational complexity. In contrast, our approach integrates pre-trained large language models (LLMs) into spatiotemporal imputation, introducing a groundbreaking framework, GATGPT. This framework merges a graph attention mechanism with LLMs. We maintain most of the LLM parameters unchanged to leverage existing knowledge for learning temporal patterns, while fine-tuning the upper layers tailored to various applications. The graph attention component enhances the LLM's ability to understand spatial relationships. Through tests on three distinct real-world datasets, our innovative approach demonstrates comparable results to established deep learning benchmarks.
Towards Communication-Efficient Model Updating for On-Device Session-Based Recommendation
Aug 24, 2023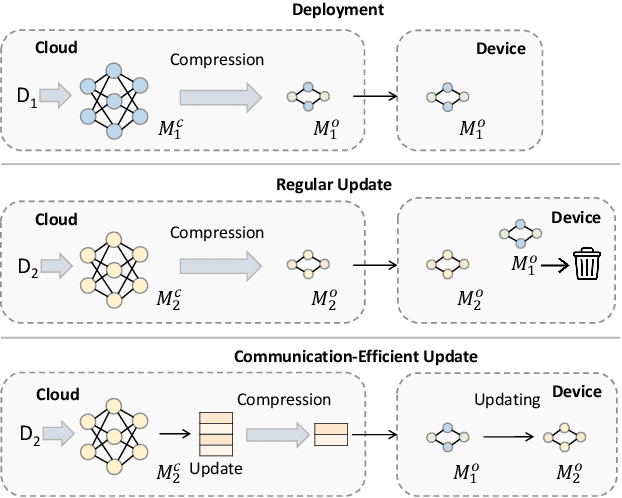

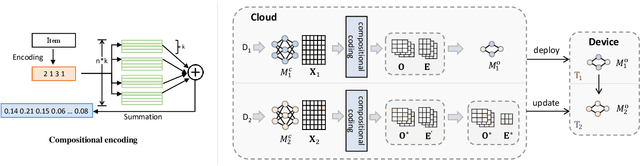
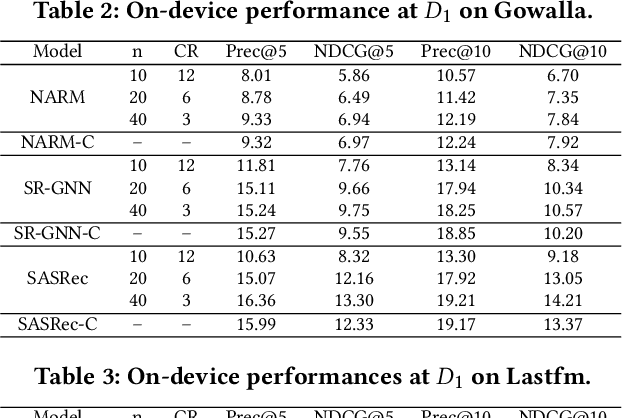
On-device recommender systems recently have garnered increasing attention due to their advantages of providing prompt response and securing privacy. To stay current with evolving user interests, cloud-based recommender systems are periodically updated with new interaction data. However, on-device models struggle to retrain themselves because of limited onboard computing resources. As a solution, we consider the scenario where the model retraining occurs on the server side and then the updated parameters are transferred to edge devices via network communication. While this eliminates the need for local retraining, it incurs a regular transfer of parameters that significantly taxes network bandwidth. To mitigate this issue, we develop an efficient approach based on compositional codes to compress the model update. This approach ensures the on-device model is updated flexibly with minimal additional parameters whilst utilizing previous knowledge. The extensive experiments conducted on multiple session-based recommendation models with distinctive architectures demonstrate that the on-device model can achieve comparable accuracy to the retrained server-side counterpart through transferring an update 60x smaller in size. The codes are available at \url{https://github.com/xiaxin1998/ODUpdate}.
LLaMA-E: Empowering E-commerce Authoring with Multi-Aspect Instruction Following
Aug 09, 2023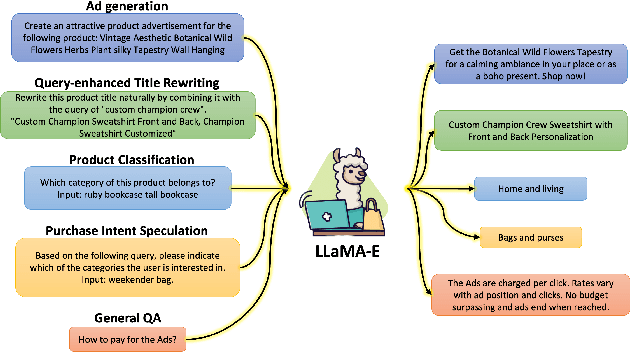

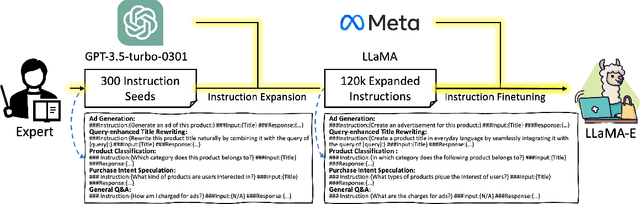
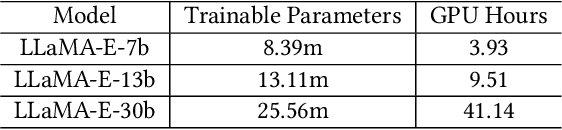
E-commerce authoring involves creating attractive, abundant, and targeted promotional content to drive product sales. The emergence of large language models (LLMs) introduces an innovative paradigm, offering a unified solution to address various authoring tasks within this scenario. However, mainstream LLMs trained on general corpora with common sense knowledge reveal limitations in fitting complex and personalized features unique to e-commerce products and customers. Furthermore, LLMs like GPT-3.5 necessitate remote accessibility, raising concerns about safeguarding voluminous customer privacy data during transmission. This paper proposes the LLaMA-E, the unified and customized instruction-following language models focusing on diverse e-commerce authoring tasks. Specifically, the domain experts create the seed instruction set from the tasks of ads generation, query-enhanced product title rewriting, product classification, purchase intent speculation, and general Q&A. These tasks enable the models to comprehensively understand precise e-commerce authoring knowledge by interleaving features covering typical service aspects of customers, sellers, and platforms. The GPT-3.5 is introduced as a teacher model, which expands the seed instructions to form a training set for the LLaMA-E models with various scales. The experimental results show that the proposed LLaMA-E models achieve state-of-the-art results in quantitative and qualitative evaluations, also exhibiting the advantage in zero-shot scenes. To the best of our knowledge, this study is the first to serve the LLMs to specific e-commerce authoring scenarios.
Counterfactual Explanation for Fairness in Recommendation
Jul 10, 2023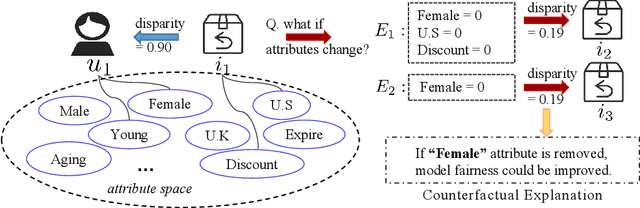
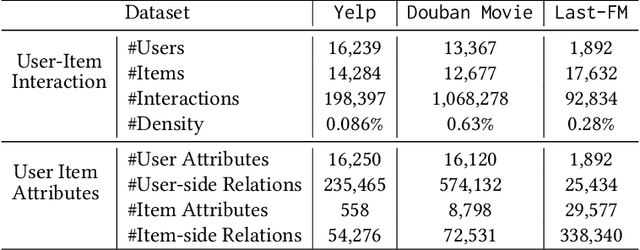
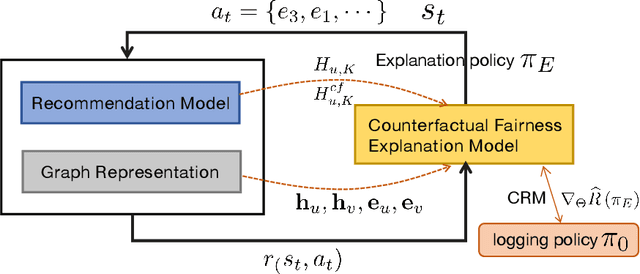
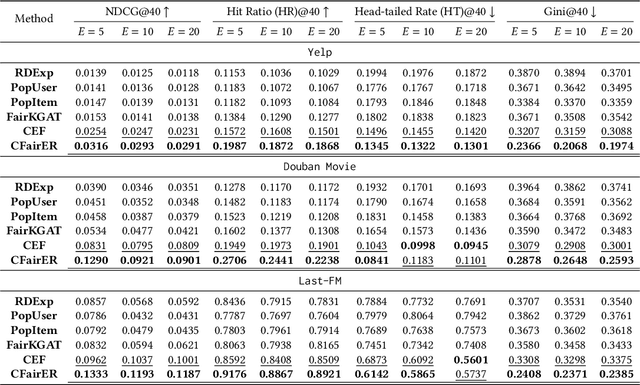
Fairness-aware recommendation eliminates discrimination issues to build trustworthy recommendation systems.Explaining the causes of unfair recommendations is critical, as it promotes fairness diagnostics, and thus secures users' trust in recommendation models. Existing fairness explanation methods suffer high computation burdens due to the large-scale search space and the greedy nature of the explanation search process. Besides, they perform score-based optimizations with continuous values, which are not applicable to discrete attributes such as gender and race. In this work, we adopt the novel paradigm of counterfactual explanation from causal inference to explore how minimal alterations in explanations change model fairness, to abandon the greedy search for explanations. We use real-world attributes from Heterogeneous Information Networks (HINs) to empower counterfactual reasoning on discrete attributes. We propose a novel Counterfactual Explanation for Fairness (CFairER) that generates attribute-level counterfactual explanations from HINs for recommendation fairness. Our CFairER conducts off-policy reinforcement learning to seek high-quality counterfactual explanations, with an attentive action pruning reducing the search space of candidate counterfactuals. The counterfactual explanations help to provide rational and proximate explanations for model fairness, while the attentive action pruning narrows the search space of attributes. Extensive experiments demonstrate our proposed model can generate faithful explanations while maintaining favorable recommendation performance.
Causal Neural Graph Collaborative Filtering
Jul 10, 2023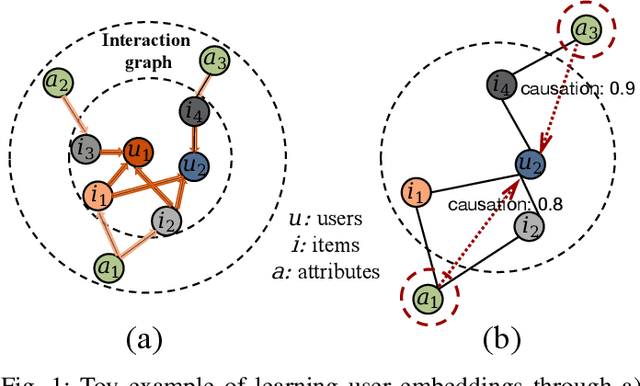
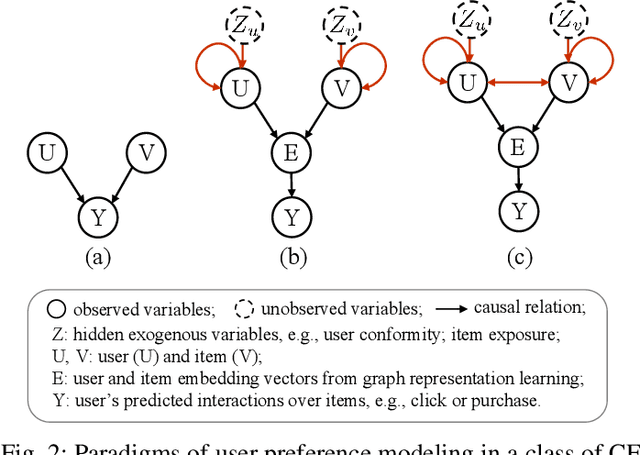
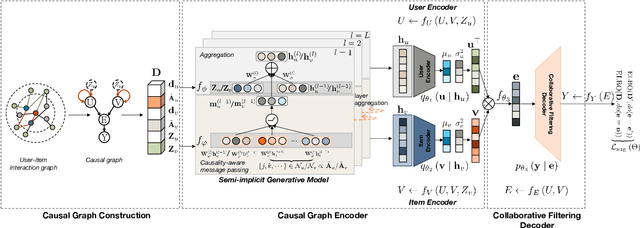

Graph collaborative filtering (GCF) has gained considerable attention in recommendation systems by leveraging graph learning techniques to enhance collaborative filtering (CF) models. One classical approach in GCF is to learn user and item embeddings by modeling complex graph relations and utilizing these embeddings for CF models. However, the quality of the embeddings significantly impacts the recommendation performance of GCF models. In this paper, we argue that existing graph learning methods are insufficient in generating satisfactory embeddings for CF models. This is because they aggregate neighboring node messages directly, which can result in incorrect estimations of user-item correlations. To overcome this limitation, we propose a novel approach that incorporates causal modeling to explicitly encode the causal effects of neighboring nodes on the target node. This approach enables us to identify spurious correlations and uncover the root causes of user preferences. We introduce Causal Neural Graph Collaborative Filtering (CNGCF), the first causality-aware graph learning framework for CF. CNGCF integrates causal modeling into the graph representation learning process, explicitly coupling causal effects between node pairs into the core message-passing process of graph learning. As a result, CNGCF yields causality-aware embeddings that promote robust recommendations. Our extensive experiments demonstrate that CNGCF provides precise recommendations that align with user preferences. Therefore, our proposed framework can address the limitations of existing GCF models and offer a more effective solution for recommendation systems.
Improved Churn Causal Analysis Through Restrained High-Dimensional Feature Space Effects in Financial Institutions
Apr 23, 2023Customer churn describes terminating a relationship with a business or reducing customer engagement over a specific period. Customer acquisition cost can be five to six times that of customer retention, hence investing in customers with churn risk is wise. Causal analysis of the churn model can predict whether a customer will churn in the foreseeable future and identify effects and possible causes for churn. In general, this study presents a conceptual framework to discover the confounding features that correlate with independent variables and are causally related to those dependent variables that impact churn. We combine different algorithms including the SMOTE, ensemble ANN, and Bayesian networks to address churn prediction problems on a massive and high-dimensional finance data that is usually generated in financial institutions due to employing interval-based features used in Customer Relationship Management systems. The effects of the curse and blessing of dimensionality assessed by utilising the Recursive Feature Elimination method to overcome the high dimension feature space problem. Moreover, a causal discovery performed to find possible interpretation methods to describe cause probabilities that lead to customer churn. Evaluation metrics on validation data confirm the random forest and our ensemble ANN model, with %86 accuracy, outperformed other approaches. Causal analysis results confirm that some independent causal variables representing the level of super guarantee contribution, account growth, and account balance amount were identified as confounding variables that cause customer churn with a high degree of belief. This article provides a real-world customer churn analysis from current status inference to future directions in local superannuation funds.
* Human-Centric Intelligent Systems 2022. arXiv admin note: substantial text overlap with arXiv:2304.10604
Causal Analysis of Customer Churn Using Deep Learning
Apr 20, 2023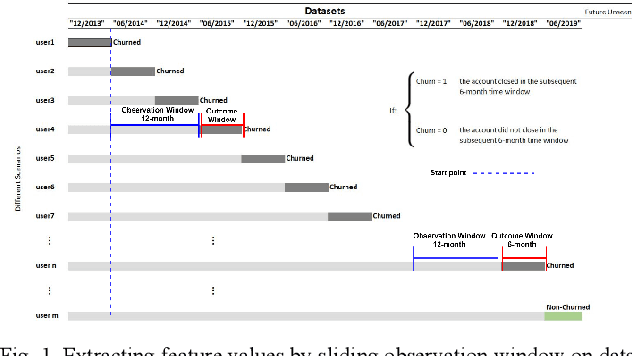
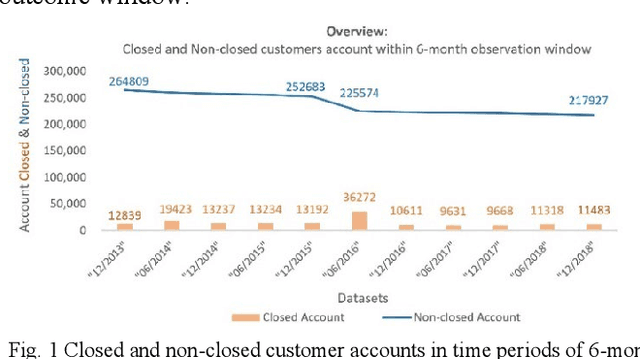
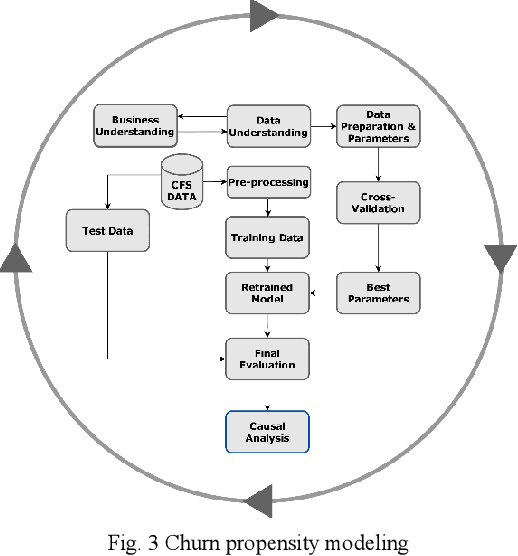
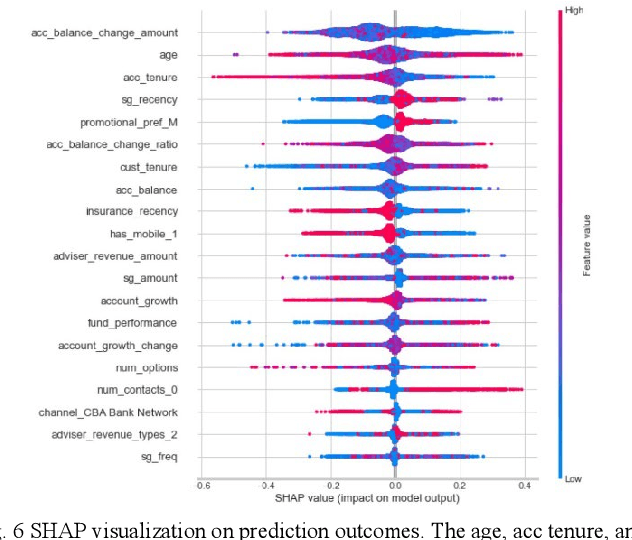
Customer churn describes terminating a relationship with a business or reducing customer engagement over a specific period. Two main business marketing strategies play vital roles to increase market share dollar-value: gaining new and preserving existing customers. Customer acquisition cost can be five to six times that for customer retention, hence investing in customers with churn risk is smart. Causal analysis of the churn model can predict whether a customer will churn in the foreseeable future and assist enterprises to identify effects and possible causes for churn and subsequently use that knowledge to apply tailored incentives. This paper proposes a framework using a deep feedforward neural network for classification accompanied by a sequential pattern mining method on high-dimensional sparse data. We also propose a causal Bayesian network to predict cause probabilities that lead to customer churn. Evaluation metrics on test data confirm the XGBoost and our deep learning model outperformed previous techniques. Experimental analysis confirms that some independent causal variables representing the level of super guarantee contribution, account growth, and customer tenure were identified as confounding factors for customer churn with a high degree of belief. This paper provides a real-world customer churn analysis from current status inference to future directions in local superannuation funds.
* 6 pages
Model-Agnostic Decentralized Collaborative Learning for On-Device POI Recommendation
Apr 08, 2023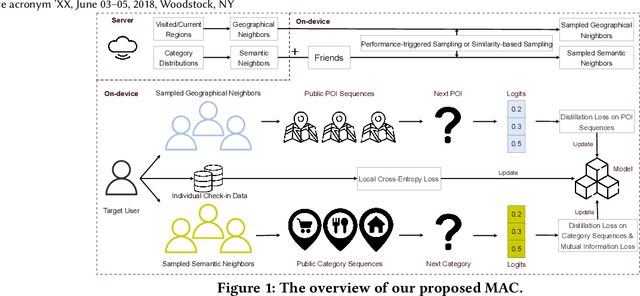
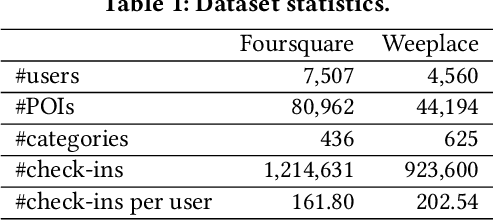
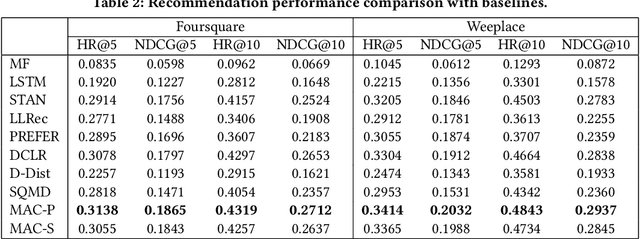
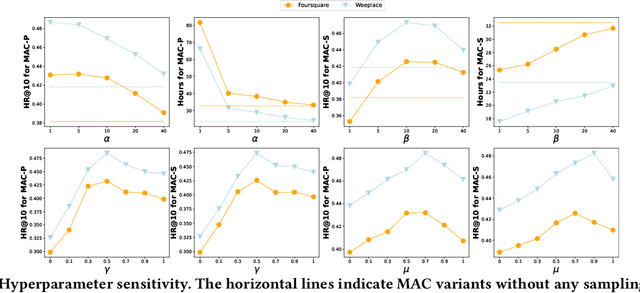
As an indispensable personalized service in Location-based Social Networks (LBSNs), the next Point-of-Interest (POI) recommendation aims to help people discover attractive and interesting places. Currently, most POI recommenders are based on the conventional centralized paradigm that heavily relies on the cloud to train the recommendation models with large volumes of collected users' sensitive check-in data. Although a few recent works have explored on-device frameworks for resilient and privacy-preserving POI recommendations, they invariably hold the assumption of model homogeneity for parameters/gradients aggregation and collaboration. However, users' mobile devices in the real world have various hardware configurations (e.g., compute resources), leading to heterogeneous on-device models with different architectures and sizes. In light of this, We propose a novel on-device POI recommendation framework, namely Model-Agnostic Collaborative learning for on-device POI recommendation (MAC), allowing users to customize their own model structures (e.g., dimension \& number of hidden layers). To counteract the sparsity of on-device user data, we propose to pre-select neighbors for collaboration based on physical distances, category-level preferences, and social networks. To assimilate knowledge from the above-selected neighbors in an efficient and secure way, we adopt the knowledge distillation framework with mutual information maximization. Instead of sharing sensitive models/gradients, clients in MAC only share their soft decisions on a preloaded reference dataset. To filter out low-quality neighbors, we propose two sampling strategies, performance-triggered sampling and similarity-based sampling, to speed up the training process and obtain optimal recommenders. In addition, we design two novel approaches to generate more effective reference datasets while protecting users' privacy.