 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCR-RAG: Enhancing Retrieval-Augmented Generation in Web Q&A via Concept-oriented Context Reconstruction
Mar 25, 2026Retrieval-augmented generation (RAG) has shown promising results in enhancing Q&A by incorporating information from the web and other external sources. However, the supporting documents retrieved from the heterogeneous web often originate from multiple sources with diverse writing styles, varying formats, and inconsistent granularity. Fusing such multi-source documents into a coherent and knowledge-intensive context remains a significant challenge, as the presence of irrelevant and redundant information can compromise the factual consistency of the inferred answers. This paper proposes the Concept-oriented Context Reconstruction RAG (CoCR-RAG), a framework that addresses the multi-source information fusion problem in RAG through linguistically grounded concept-level integration. Specifically, we introduce a concept distillation algorithm that extracts essential concepts from Abstract Meaning Representation (AMR), a stable semantic representation that structures the meaning of texts as logical graphs. The distilled concepts from multiple retrieved documents are then fused and reconstructed into a unified, information-intensive context by Large Language Models, which supplement only the necessary sentence elements to highlight the core knowledge. Experiments on the PopQA and EntityQuestions datasets demonstrate that CoCR-RAG significantly outperforms existing context-reconstruction methods across these Web Q&A benchmarks. Furthermore, CoCR-RAG shows robustness across various backbone LLMs, establishing itself as a flexible, plug-and-play component adaptable to different RAG frameworks.
Expert-Guided Extinction of Toxic Tokens for Debiased Generation
May 29, 2024



Large language models (LLMs) can elicit social bias during generations, especially when inference with toxic prompts. Controlling the sensitive attributes in generation encounters challenges in data distribution, generalizability, and efficiency. Specifically, fine-tuning and retrieval demand extensive unbiased corpus, while direct prompting requires meticulously curated instructions for correcting the output in multiple rounds of thoughts but poses challenges on memory and inference latency. In this work, we propose the Expert-Guided Extinction of Toxic Tokens for Debiased Generation (EXPOSED) to eliminate the undesired harmful outputs for LLMs without the aforementioned requirements. EXPOSED constructs a debiasing expert based on the abundant toxic corpus to expose and elicit the potentially dangerous tokens. It then processes the output to the LLMs and constructs a fair distribution by suppressing and attenuating the toxic tokens. EXPOSED is evaluated on fairness benchmarks over three LLM families. Extensive experiments demonstrate that compared with other baselines, the proposed EXPOSED significantly reduces the potential social bias while balancing fairness and generation performance.
Compressing Long Context for Enhancing RAG with AMR-based Concept Distillation
May 06, 2024



Large Language Models (LLMs) have made significant strides in information acquisition. However, their overreliance on potentially flawed parametric knowledge leads to hallucinations and inaccuracies, particularly when handling long-tail, domain-specific queries. Retrieval Augmented Generation (RAG) addresses this limitation by incorporating external, non-parametric knowledge. Nevertheless, the retrieved long-context documents often contain noisy, irrelevant information alongside vital knowledge, negatively diluting LLMs' attention. Inspired by the supportive role of essential concepts in individuals' reading comprehension, we propose a novel concept-based RAG framework with the Abstract Meaning Representation (AMR)-based concept distillation algorithm. The proposed algorithm compresses the cluttered raw retrieved documents into a compact set of crucial concepts distilled from the informative nodes of AMR by referring to reliable linguistic features. The concepts explicitly constrain LLMs to focus solely on vital information in the inference process. We conduct extensive experiments on open-domain question-answering datasets to empirically evaluate the proposed method's effectiveness. The results indicate that the concept-based RAG framework outperforms other baseline methods, particularly as the number of supporting documents increases, while also exhibiting robustness across various backbone LLMs. This emphasizes the distilled concepts are informative for augmenting the RAG process by filtering out interference information. To the best of our knowledge, this is the first work introducing AMR to enhance the RAG, presenting a potential solution to augment inference performance with semantic-based context compression.
BiHRNet: A Binary high-resolution network for Human Pose Estimation
Nov 17, 2023Human Pose Estimation (HPE) plays a crucial role in computer vision applications. However, it is difficult to deploy state-of-the-art models on resouce-limited devices due to the high computational costs of the networks. In this work, a binary human pose estimator named BiHRNet(Binary HRNet) is proposed, whose weights and activations are expressed as $\pm$1. BiHRNet retains the keypoint extraction ability of HRNet, while using fewer computing resources by adapting binary neural network (BNN). In order to reduce the accuracy drop caused by network binarization, two categories of techniques are proposed in this work. For optimizing the training process for binary pose estimator, we propose a new loss function combining KL divergence loss with AWing loss, which makes the binary network obtain more comprehensive output distribution from its real-valued counterpart to reduce information loss caused by binarization. For designing more binarization-friendly structures, we propose a new information reconstruction bottleneck called IR Bottleneck to retain more information in the initial stage of the network. In addition, we also propose a multi-scale basic block called MS-Block for information retention. Our work has less computation cost with few precision drop. Experimental results demonstrate that BiHRNet achieves a PCKh of 87.9 on the MPII dataset, which outperforms all binary pose estimation networks. On the challenging of COCO dataset, the proposed method enables the binary neural network to achieve 70.8 mAP, which is better than most tested lightweight full-precision networks.
LLaMA-E: Empowering E-commerce Authoring with Multi-Aspect Instruction Following
Aug 09, 2023E-commerce authoring involves creating attractive, abundant, and targeted promotional content to drive product sales. The emergence of large language models (LLMs) introduces an innovative paradigm, offering a unified solution to address various authoring tasks within this scenario. However, mainstream LLMs trained on general corpora with common sense knowledge reveal limitations in fitting complex and personalized features unique to e-commerce products and customers. Furthermore, LLMs like GPT-3.5 necessitate remote accessibility, raising concerns about safeguarding voluminous customer privacy data during transmission. This paper proposes the LLaMA-E, the unified and customized instruction-following language models focusing on diverse e-commerce authoring tasks. Specifically, the domain experts create the seed instruction set from the tasks of ads generation, query-enhanced product title rewriting, product classification, purchase intent speculation, and general Q&A. These tasks enable the models to comprehensively understand precise e-commerce authoring knowledge by interleaving features covering typical service aspects of customers, sellers, and platforms. The GPT-3.5 is introduced as a teacher model, which expands the seed instructions to form a training set for the LLaMA-E models with various scales. The experimental results show that the proposed LLaMA-E models achieve state-of-the-art results in quantitative and qualitative evaluations, also exhibiting the advantage in zero-shot scenes. To the best of our knowledge, this study is the first to serve the LLMs to specific e-commerce authoring scenarios.
Explainable Sentence-Level Sentiment Analysis for Amazon Product Reviews
Nov 11, 2021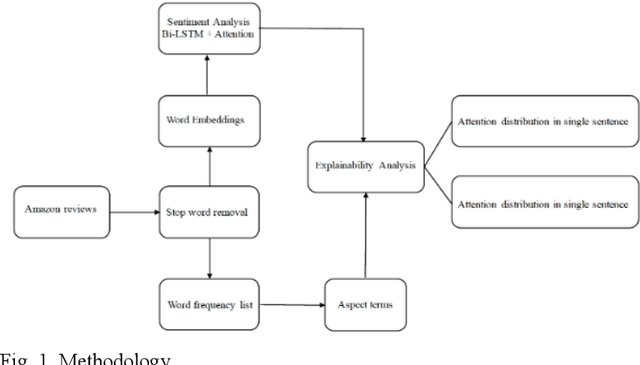
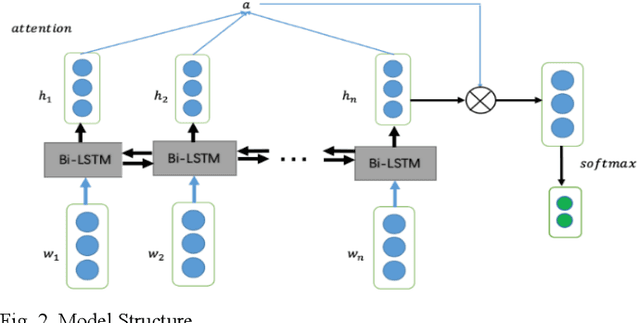
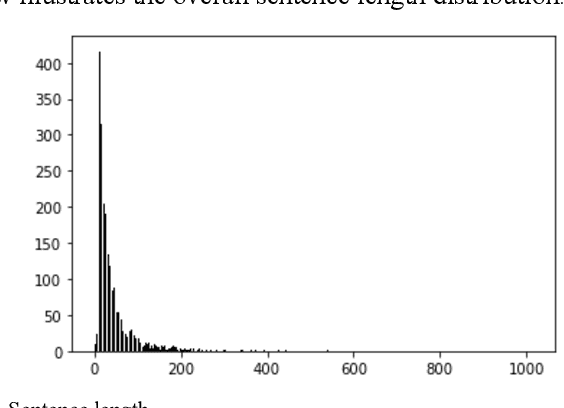
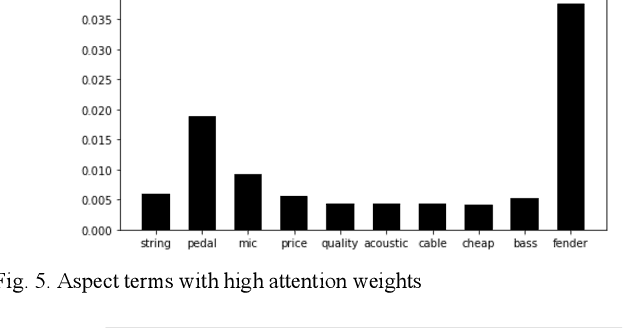
In this paper, we conduct a sentence level sentiment analysis on the product reviews from Amazon and thorough analysis on the model interpretability. For the sentiment analysis task, we use the BiLSTM model with attention mechanism. For the study of interpretability, we consider the attention weights distribution of single sentence and the attention weights of main aspect terms. The model has an accuracy of up to 0.96. And we find that the aspect terms have the same or even more attention weights than the sentimental words in sentences.