 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Physics-Informed, Behavior-Aware Digital Twin for Robust Multimodal Forecasting of Core Body Temperature in Precision Livestock Farming
Apr 05, 2026Precision livestock farming requires accurate and timely heat stress prediction to ensure animal welfare and optimize farm management. This study presents a physics-informed digital twin (DT) framework combined with an uncertainty-aware, expert-weighted stacked ensemble for multimodal forecasting of Core Body Temperature (CBT) in dairy cattle. Using the high-frequency, heterogeneous MmCows dataset, the DT integrates an ordinary differential equation (ODE)-based thermoregulation model that simulates metabolic heat production and dissipation, a Gaussian process for capturing cow-specific deviations, a Kalman filter for aligning predictions with real-time sensor data, and a behavioral Markov chain that models activity-state transitions under varying environmental conditions. The DT outputs key physiological indicators, such as predicted CBT, heat stress probability, and behavioral state distributions are fused with raw sensor data and enriched through multi-scale temporal analysis and cross-modal feature engineering to form a comprehensive feature set. The predictive methodology is designed in a three-stage stacked ensemble, where stage 1 trains modality-specific LightGBM 'expert' models on distinct feature groups, stage 2 collects their predictions as meta-features, and at stage 3 Optuna-tuned LightGBM meta-model yields the final CBT forecast. Predictive uncertainty is quantified via bootstrapping and validated using Prediction Interval Coverage Probability (PICP). Ablation analysis confirms that incorporating DT-derived features and multimodal fusion substantially enhances performance. The proposed framework achieves a cross-validated R2 of 0.783, F1 score of 84.25% and PICP of 92.38% for 2-hour ahead forecasting, providing a robust, uncertainty-aware, and physically principled system for early heat stress detection and precision livestock management.
Mitigating Hallucinations in Healthcare LLMs with Granular Fact-Checking and Domain-Specific Adaptation
Dec 19, 2025In healthcare, it is essential for any LLM-generated output to be reliable and accurate, particularly in cases involving decision-making and patient safety. However, the outputs are often unreliable in such critical areas due to the risk of hallucinated outputs from the LLMs. To address this issue, we propose a fact-checking module that operates independently of any LLM, along with a domain-specific summarization model designed to minimize hallucination rates. Our model is fine-tuned using Low-Rank Adaptation (LoRa) on the MIMIC III dataset and is paired with the fact-checking module, which uses numerical tests for correctness and logical checks at a granular level through discrete logic in natural language processing (NLP) to validate facts against electronic health records (EHRs). We trained the LLM model on the full MIMIC-III dataset. For evaluation of the fact-checking module, we sampled 104 summaries, extracted them into 3,786 propositions, and used these as facts. The fact-checking module achieves a precision of 0.8904, a recall of 0.8234, and an F1-score of 0.8556. Additionally, the LLM summary model achieves a ROUGE-1 score of 0.5797 and a BERTScore of 0.9120 for summary quality.
DeepAgent: A Dual Stream Multi Agent Fusion for Robust Multimodal Deepfake Detection
Dec 08, 2025The increasing use of synthetic media, particularly deepfakes, is an emerging challenge for digital content verification. Although recent studies use both audio and visual information, most integrate these cues within a single model, which remains vulnerable to modality mismatches, noise, and manipulation. To address this gap, we propose DeepAgent, an advanced multi-agent collaboration framework that simultaneously incorporates both visual and audio modalities for the effective detection of deepfakes. DeepAgent consists of two complementary agents. Agent-1 examines each video with a streamlined AlexNet-based CNN to identify the symbols of deepfake manipulation, while Agent-2 detects audio-visual inconsistencies by combining acoustic features, audio transcriptions from Whisper, and frame-reading sequences of images through EasyOCR. Their decisions are fused through a Random Forest meta-classifier that improves final performance by taking advantage of the different decision boundaries learned by each agent. This study evaluates the proposed framework using three benchmark datasets to demonstrate both component-level and fused performance. Agent-1 achieves a test accuracy of 94.35% on the combined Celeb-DF and FakeAVCeleb datasets. On the FakeAVCeleb dataset, Agent-2 and the final meta-classifier attain accuracies of 93.69% and 81.56%, respectively. In addition, cross-dataset validation on DeepFakeTIMIT confirms the robustness of the meta-classifier, which achieves a final accuracy of 97.49%, and indicates a strong capability across diverse datasets. These findings confirm that hierarchy-based fusion enhances robustness by mitigating the weaknesses of individual modalities and demonstrate the effectiveness of a multi-agent approach in addressing diverse types of manipulations in deepfakes.
From Language to Action: A Review of Large Language Models as Autonomous Agents and Tool Users
Aug 24, 2025The pursuit of human-level artificial intelligence (AI) has significantly advanced the development of autonomous agents and Large Language Models (LLMs). LLMs are now widely utilized as decision-making agents for their ability to interpret instructions, manage sequential tasks, and adapt through feedback. This review examines recent developments in employing LLMs as autonomous agents and tool users and comprises seven research questions. We only used the papers published between 2023 and 2025 in conferences of the A* and A rank and Q1 journals. A structured analysis of the LLM agents' architectural design principles, dividing their applications into single-agent and multi-agent systems, and strategies for integrating external tools is presented. In addition, the cognitive mechanisms of LLM, including reasoning, planning, and memory, and the impact of prompting methods and fine-tuning procedures on agent performance are also investigated. Furthermore, we evaluated current benchmarks and assessment protocols and have provided an analysis of 68 publicly available datasets to assess the performance of LLM-based agents in various tasks. In conducting this review, we have identified critical findings on verifiable reasoning of LLMs, the capacity for self-improvement, and the personalization of LLM-based agents. Finally, we have discussed ten future research directions to overcome these gaps.
Analysis of child development facts and myths using text mining techniques and classification models
Aug 23, 2024



The rapid dissemination of misinformation on the internet complicates the decision-making process for individuals seeking reliable information, particularly parents researching child development topics. This misinformation can lead to adverse consequences, such as inappropriate treatment of children based on myths. While previous research has utilized text-mining techniques to predict child abuse cases, there has been a gap in the analysis of child development myths and facts. This study addresses this gap by applying text mining techniques and classification models to distinguish between myths and facts about child development, leveraging newly gathered data from publicly available websites. The research methodology involved several stages. First, text mining techniques were employed to pre-process the data, ensuring enhanced accuracy. Subsequently, the structured data was analysed using six robust Machine Learning (ML) classifiers and one Deep Learning (DL) model, with two feature extraction techniques applied to assess their performance across three different training-testing splits. To ensure the reliability of the results, cross-validation was performed using both k-fold and leave-one-out methods. Among the classification models tested, Logistic Regression (LR) demonstrated the highest accuracy, achieving a 90% accuracy with the Bag-of-Words (BoW) feature extraction technique. LR stands out for its exceptional speed and efficiency, maintaining low testing time per statement (0.97 microseconds). These findings suggest that LR, when combined with BoW, is effective in accurately classifying child development information, thus providing a valuable tool for combating misinformation and assisting parents in making informed decisions.
Churn Prediction via Multimodal Fusion Learning:Integrating Customer Financial Literacy, Voice, and Behavioral Data
Dec 03, 2023



In todays competitive landscape, businesses grapple with customer retention. Churn prediction models, although beneficial, often lack accuracy due to the reliance on a single data source. The intricate nature of human behavior and high dimensional customer data further complicate these efforts. To address these concerns, this paper proposes a multimodal fusion learning model for identifying customer churn risk levels in financial service providers. Our multimodal approach integrates customer sentiments financial literacy (FL) level, and financial behavioral data, enabling more accurate and bias-free churn prediction models. The proposed FL model utilizes a SMOGN COREG supervised model to gauge customer FL levels from their financial data. The baseline churn model applies an ensemble artificial neural network and oversampling techniques to predict churn propensity in high-dimensional financial data. We also incorporate a speech emotion recognition model employing a pre-trained CNN-VGG16 to recognize customer emotions based on pitch, energy, and tone. To integrate these diverse features while retaining unique insights, we introduced late and hybrid fusion techniques that complementary boost coordinated multimodal co learning. Robust metrics were utilized to evaluate the proposed multimodal fusion model and hence the approach validity, including mean average precision and macro-averaged F1 score. Our novel approach demonstrates a marked improvement in churn prediction, achieving a test accuracy of 91.2%, a Mean Average Precision (MAP) score of 66, and a Macro-Averaged F1 score of 54 through the proposed hybrid fusion learning technique compared with late fusion and baseline models. Furthermore, the analysis demonstrates a positive correlation between negative emotions, low FL scores, and high-risk customers.
AutoCl : A Visual Interactive System for Automatic Deep Learning Classifier Recommendation Based on Models Performance
Feb 24, 2022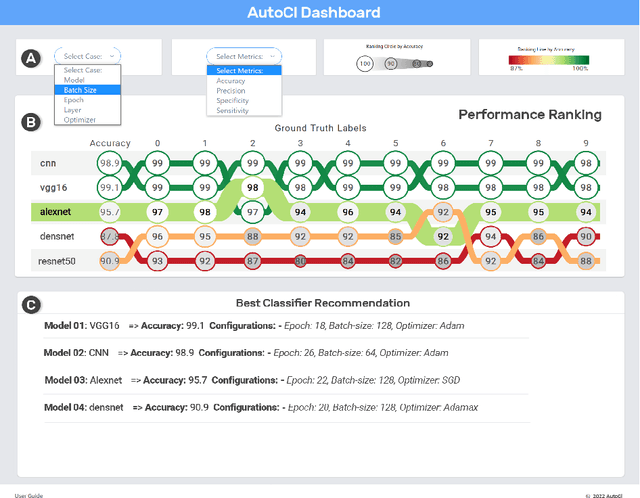
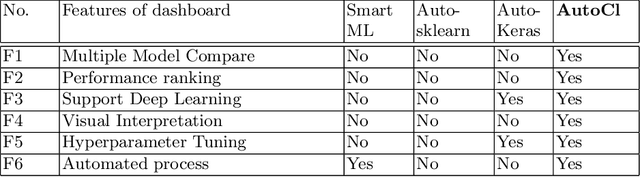
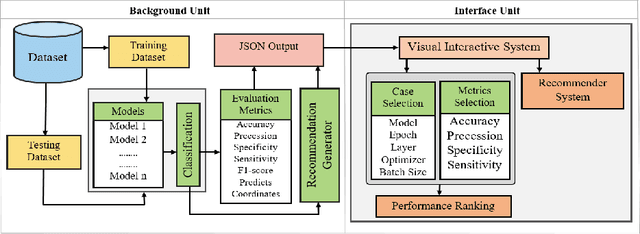
Nowadays, deep learning (DL) models being increasingly applied to various fields, people without technical expertise and domain knowledge struggle to find an appropriate model for their task. In this paper, we introduce AutoCl a visual interactive recommender system aimed at helping non-experts to adopt an appropriate DL classifier. Our system enables users to compare the performance and behavior of multiple classifiers trained with various hyperparameter setups as well as automatically recommends a best classifier with appropriate hyperparameter. We compare features of AutoCl against several recent AutoML systems and show that it helps non-experts better in choosing DL classifier. Finally, we demonstrate use cases for image classification using publicly available dataset to show the capability of our system.
* This research paper has accepted and presented in The 28th International Workshop on Frontiers of Computer Vision (IW-FCV). IW-FCV held fully virtual on February 21-22, 2022. See https://sites.google.com/view/iwfcv2022 for details