 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompound Batch Normalization for Long-tailed Image Classification
Dec 02, 2022



Significant progress has been made in learning image classification neural networks under long-tail data distribution using robust training algorithms such as data re-sampling, re-weighting, and margin adjustment. Those methods, however, ignore the impact of data imbalance on feature normalization. The dominance of majority classes (head classes) in estimating statistics and affine parameters causes internal covariate shifts within less-frequent categories to be overlooked. To alleviate this challenge, we propose a compound batch normalization method based on a Gaussian mixture. It can model the feature space more comprehensively and reduce the dominance of head classes. In addition, a moving average-based expectation maximization (EM) algorithm is employed to estimate the statistical parameters of multiple Gaussian distributions. However, the EM algorithm is sensitive to initialization and can easily become stuck in local minima where the multiple Gaussian components continue to focus on majority classes. To tackle this issue, we developed a dual-path learning framework that employs class-aware split feature normalization to diversify the estimated Gaussian distributions, allowing the Gaussian components to fit with training samples of less-frequent classes more comprehensively. Extensive experiments on commonly used datasets demonstrated that the proposed method outperforms existing methods on long-tailed image classification.
Divide and Contrast: Source-free Domain Adaptation via Adaptive Contrastive Learning
Nov 12, 2022



We investigate a practical domain adaptation task, called source-free domain adaptation (SFUDA), where the source-pretrained model is adapted to the target domain without access to the source data. Existing techniques mainly leverage self-supervised pseudo labeling to achieve class-wise global alignment [1] or rely on local structure extraction that encourages feature consistency among neighborhoods [2]. While impressive progress has been made, both lines of methods have their own drawbacks - the "global" approach is sensitive to noisy labels while the "local" counterpart suffers from source bias. In this paper, we present Divide and Contrast (DaC), a new paradigm for SFUDA that strives to connect the good ends of both worlds while bypassing their limitations. Based on the prediction confidence of the source model, DaC divides the target data into source-like and target-specific samples, where either group of samples is treated with tailored goals under an adaptive contrastive learning framework. Specifically, the source-like samples are utilized for learning global class clustering thanks to their relatively clean labels. The more noisy target-specific data are harnessed at the instance level for learning the intrinsic local structures. We further align the source-like domain with the target-specific samples using a memory bank-based Maximum Mean Discrepancy (MMD) loss to reduce the distribution mismatch. Extensive experiments on VisDA, Office-Home, and the more challenging DomainNet have verified the superior performance of DaC over current state-of-the-art approaches. The code is available at https://github.com/ZyeZhang/DaC.git.
OhMG: Zero-shot Open-vocabulary Human Motion Generation
Oct 28, 2022



Generating motion in line with text has attracted increasing attention nowadays. However, open-vocabulary human motion generation still remains touchless and undergoes the lack of diverse labeled data. The good news is that, recent studies of large multi-model foundation models (e.g., CLIP) have demonstrated superior performance on few/zero-shot image-text alignment, largely reducing the need for manually labeled data. In this paper, we take advantage of CLIP for open-vocabulary 3D human motion generation in a zero-shot manner. Specifically, our model is composed of two stages, i.e., text2pose and pose2motion. For text2pose, to address the difficulty of optimization with direct supervision from CLIP, we propose to carve the versatile CLIP model into a slimmer but more specific model for aligning 3D poses and texts, via a novel pipeline distillation strategy. Optimizing with the distilled 3D pose-text model, we manage to concretize the text-pose knowledge of CLIP into a text2pose generator effectively and efficiently. As for pose2motion, drawing inspiration from the advanced language model, we pretrain a transformer-based motion model, which makes up for the lack of motion dynamics of CLIP. After that, by formulating the generated poses from the text2pose stage as prompts, the motion generator can generate motions referring to the poses in a controllable and flexible manner. Our method is validated against advanced baselines and obtains sharp improvements. The code will be released here.
View-Disentangled Transformer for Brain Lesion Detection
Sep 20, 2022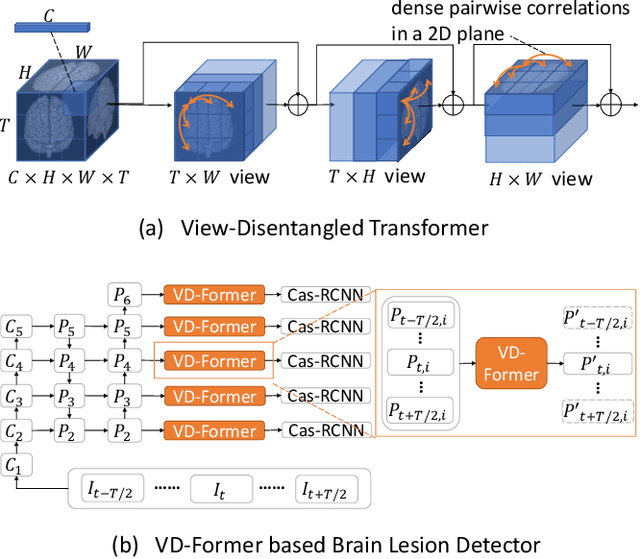
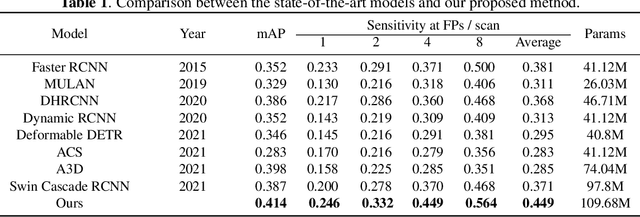
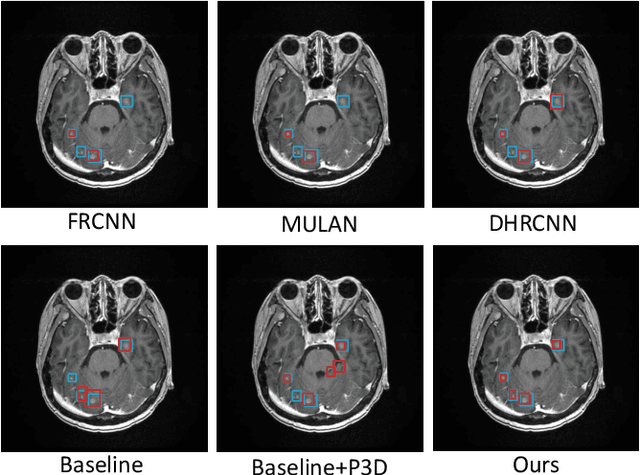
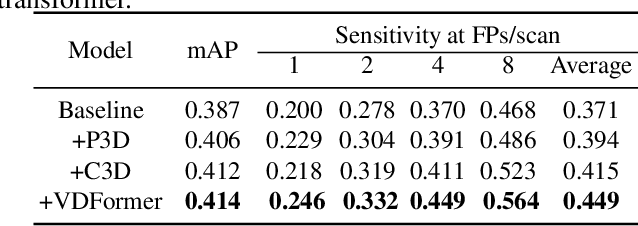
Deep neural networks (DNNs) have been widely adopted in brain lesion detection and segmentation. However, locating small lesions in 2D MRI slices is challenging, and requires to balance between the granularity of 3D context aggregation and the computational complexity. In this paper, we propose a novel view-disentangled transformer to enhance the extraction of MRI features for more accurate tumour detection. First, the proposed transformer harvests long-range correlation among different positions in a 3D brain scan. Second, the transformer models a stack of slice features as multiple 2D views and enhance these features view-by-view, which approximately achieves the 3D correlation computing in an efficient way. Third, we deploy the proposed transformer module in a transformer backbone, which can effectively detect the 2D regions surrounding brain lesions. The experimental results show that our proposed view-disentangled transformer performs well for brain lesion detection on a challenging brain MRI dataset.
Attentive Symmetric Autoencoder for Brain MRI Segmentation
Sep 19, 2022Self-supervised learning methods based on image patch reconstruction have witnessed great success in training auto-encoders, whose pre-trained weights can be transferred to fine-tune other downstream tasks of image understanding. However, existing methods seldom study the various importance of reconstructed patches and the symmetry of anatomical structures, when they are applied to 3D medical images. In this paper we propose a novel Attentive Symmetric Auto-encoder (ASA) based on Vision Transformer (ViT) for 3D brain MRI segmentation tasks. We conjecture that forcing the auto-encoder to recover informative image regions can harvest more discriminative representations, than to recover smooth image patches. Then we adopt a gradient based metric to estimate the importance of each image patch. In the pre-training stage, the proposed auto-encoder pays more attention to reconstruct the informative patches according to the gradient metrics. Moreover, we resort to the prior of brain structures and develop a Symmetric Position Encoding (SPE) method to better exploit the correlations between long-range but spatially symmetric regions to obtain effective features. Experimental results show that our proposed attentive symmetric auto-encoder outperforms the state-of-the-art self-supervised learning methods and medical image segmentation models on three brain MRI segmentation benchmarks.
Align, Reason and Learn: Enhancing Medical Vision-and-Language Pre-training with Knowledge
Sep 15, 2022
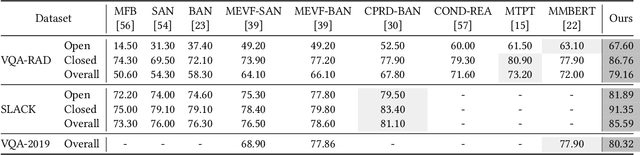
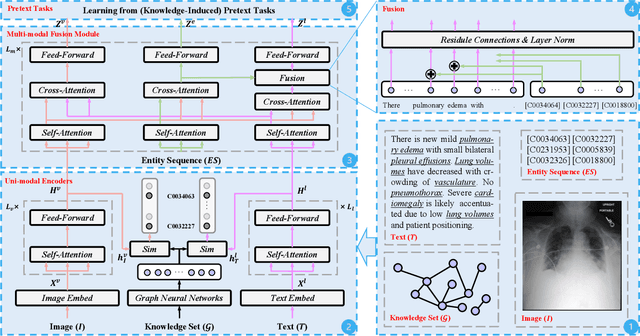
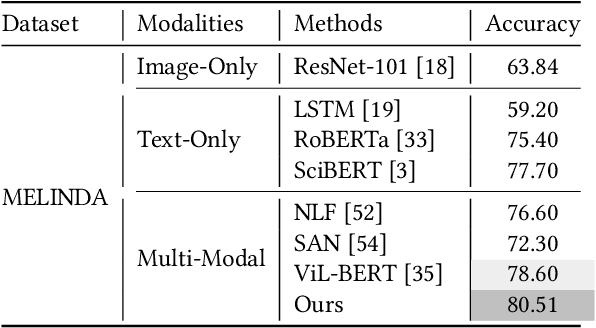
Medical vision-and-language pre-training (Med-VLP) has received considerable attention owing to its applicability to extracting generic vision-and-language representations from medical images and texts. Most existing methods mainly contain three elements: uni-modal encoders (i.e., a vision encoder and a language encoder), a multi-modal fusion module, and pretext tasks, with few studies considering the importance of medical domain expert knowledge and explicitly exploiting such knowledge to facilitate Med-VLP. Although there exist knowledge-enhanced vision-and-language pre-training (VLP) methods in the general domain, most require off-the-shelf toolkits (e.g., object detectors and scene graph parsers), which are unavailable in the medical domain. In this paper, we propose a systematic and effective approach to enhance Med-VLP by structured medical knowledge from three perspectives. First, considering knowledge can be regarded as the intermediate medium between vision and language, we align the representations of the vision encoder and the language encoder through knowledge. Second, we inject knowledge into the multi-modal fusion model to enable the model to perform reasoning using knowledge as the supplementation of the input image and text. Third, we guide the model to put emphasis on the most critical information in images and texts by designing knowledge-induced pretext tasks. To perform a comprehensive evaluation and facilitate further research, we construct a medical vision-and-language benchmark including three tasks. Experimental results illustrate the effectiveness of our approach, where state-of-the-art performance is achieved on all downstream tasks. Further analyses explore the effects of different components of our approach and various settings of pre-training.
Multi-Modal Masked Autoencoders for Medical Vision-and-Language Pre-Training
Sep 15, 2022Medical vision-and-language pre-training provides a feasible solution to extract effective vision-and-language representations from medical images and texts. However, few studies have been dedicated to this field to facilitate medical vision-and-language understanding. In this paper, we propose a self-supervised learning paradigm with multi-modal masked autoencoders (M$^3$AE), which learn cross-modal domain knowledge by reconstructing missing pixels and tokens from randomly masked images and texts. There are three key designs to make this simple approach work. First, considering the different information densities of vision and language, we adopt different masking ratios for the input image and text, where a considerably larger masking ratio is used for images. Second, we use visual and textual features from different layers to perform the reconstruction to deal with different levels of abstraction in visual and language. Third, we develop different designs for vision and language decoders (i.e., a Transformer for vision and a multi-layer perceptron for language). To perform a comprehensive evaluation and facilitate further research, we construct a medical vision-and-language benchmark including three tasks. Experimental results demonstrate the effectiveness of our approach, where state-of-the-art results are achieved on all downstream tasks. Besides, we conduct further analysis to better verify the effectiveness of different components of our approach and various settings of pre-training. The source code is available at~\url{https://github.com/zhjohnchan/M3AE}.
Cross-Modal Causal Relational Reasoning for Event-Level Visual Question Answering
Aug 15, 2022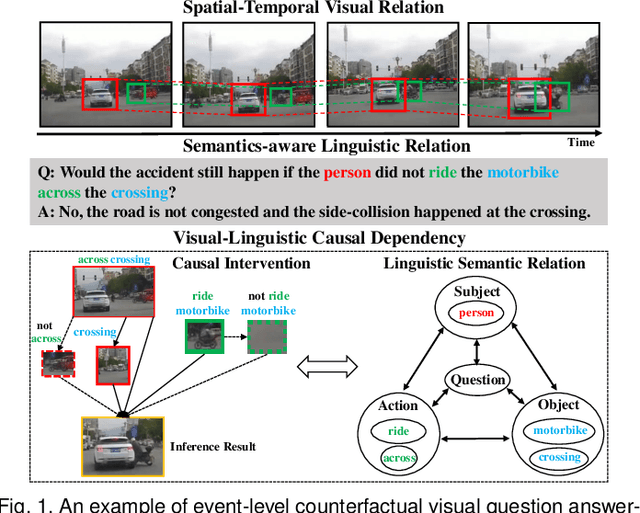
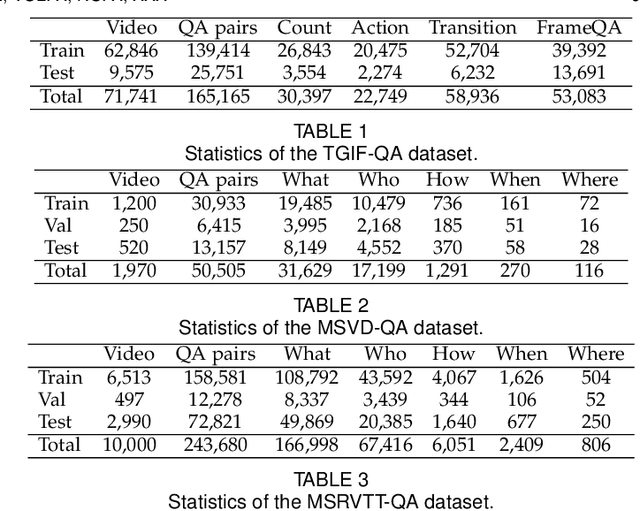
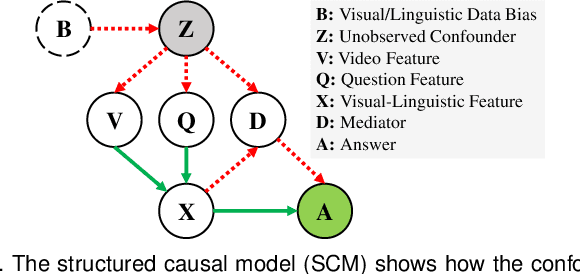
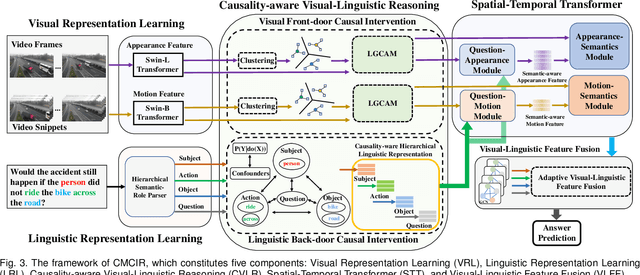
Existing visual question answering methods tend to capture the spurious correlations from visual and linguistic modalities, and fail to discover the true casual mechanism that facilitates reasoning truthfully based on the dominant visual evidence and the correct question intention. Additionally, the existing methods usually ignore the complex event-level understanding in multi-modal settings that requires a strong cognitive capability of causal inference to jointly model cross-modal event temporality, causality, and dynamics. In this work, we focus on event-level visual question answering from a new perspective, i.e., cross-modal causal relational reasoning, by introducing causal intervention methods to mitigate the spurious correlations and discover the true causal structures for the integration of visual and linguistic modalities. Specifically, we propose a novel event-level visual question answering framework named Cross-Modal Causal RelatIonal Reasoning (CMCIR), to achieve robust casuality-aware visual-linguistic question answering. To uncover the causal structures for visual and linguistic modalities, the novel Causality-aware Visual-Linguistic Reasoning (CVLR) module is proposed to collaboratively disentangle the visual and linguistic spurious correlations via elaborately designed front-door and back-door causal intervention modules. To discover the fine-grained interactions between linguistic semantics and spatial-temporal representations, we build a novel Spatial-Temporal Transformer (STT) that builds the multi-modal co-occurrence interactions between visual and linguistic content. Extensive experiments on large-scale event-level urban dataset SUTD-TrafficQA and three benchmark real-world datasets TGIF-QA, MSVD-QA, and MSRVTT-QA demonstrate the effectiveness of our CMCIR for discovering visual-linguistic causal structures.
Neighborhood Collective Estimation for Noisy Label Identification and Correction
Aug 05, 2022Learning with noisy labels (LNL) aims at designing strategies to improve model performance and generalization by mitigating the effects of model overfitting to noisy labels. The key success of LNL lies in identifying as many clean samples as possible from massive noisy data, while rectifying the wrongly assigned noisy labels. Recent advances employ the predicted label distributions of individual samples to perform noise verification and noisy label correction, easily giving rise to confirmation bias. To mitigate this issue, we propose Neighborhood Collective Estimation, in which the predictive reliability of a candidate sample is re-estimated by contrasting it against its feature-space nearest neighbors. Specifically, our method is divided into two steps: 1) Neighborhood Collective Noise Verification to separate all training samples into a clean or noisy subset, 2) Neighborhood Collective Label Correction to relabel noisy samples, and then auxiliary techniques are used to assist further model optimization. Extensive experiments on four commonly used benchmark datasets, i.e., CIFAR-10, CIFAR-100, Clothing-1M and Webvision-1.0, demonstrate that our proposed method considerably outperforms state-of-the-art methods.
Robust Real-World Image Super-Resolution against Adversarial Attacks
Jul 31, 2022
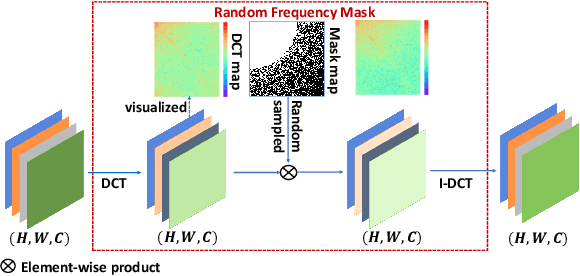
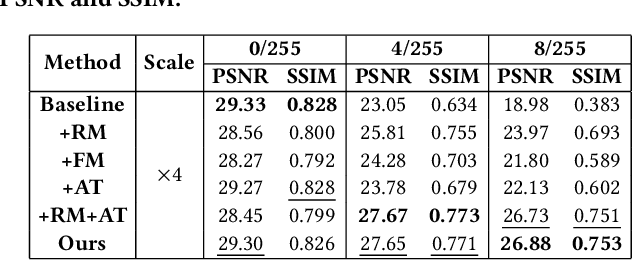
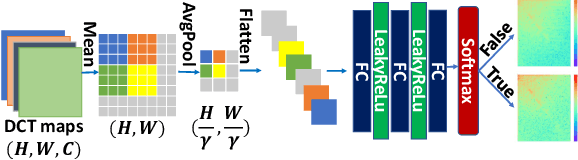
Recently deep neural networks (DNNs) have achieved significant success in real-world image super-resolution (SR). However, adversarial image samples with quasi-imperceptible noises could threaten deep learning SR models. In this paper, we propose a robust deep learning framework for real-world SR that randomly erases potential adversarial noises in the frequency domain of input images or features. The rationale is that on the SR task clean images or features have a different pattern from the attacked ones in the frequency domain. Observing that existing adversarial attacks usually add high-frequency noises to input images, we introduce a novel random frequency mask module that blocks out high-frequency components possibly containing the harmful perturbations in a stochastic manner. Since the frequency masking may not only destroys the adversarial perturbations but also affects the sharp details in a clean image, we further develop an adversarial sample classifier based on the frequency domain of images to determine if applying the proposed mask module. Based on the above ideas, we devise a novel real-world image SR framework that combines the proposed frequency mask modules and the proposed adversarial classifier with an existing super-resolution backbone network. Experiments show that our proposed method is more insensitive to adversarial attacks and presents more stable SR results than existing models and defenses.
* ACM-MM 2021, Code: https://github.com/lhaof/Robust-SR-against-Adversarial-Attacks