 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Design of Crystal Structures by Point Cloud Representations and Diffusion Model
Jan 31, 2024



Efficiently generating energetically stable crystal structures has long been a challenge in material design, primarily due to the immense arrangement of atoms in a crystal lattice. To facilitate the discovery of stable material, we present a framework for the generation of synthesizable materials, leveraging a point cloud representation to encode intricate structural information. At the heart of this framework lies the introduction of a diffusion model as its foundational pillar. To gauge the efficacy of our approach, we employ it to reconstruct input structures from our training datasets, rigorously validating its high reconstruction performance. Furthermore, we demonstrate the profound potential of Point Cloud-Based Crystal Diffusion (PCCD) by generating entirely new materials, emphasizing their synthesizability. Our research stands as a noteworthy contribution to the advancement of materials design and synthesis through the cutting-edge avenue of generative design instead of the conventional substitution or experience-based discovery.
WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens
Jan 18, 2024World models play a crucial role in understanding and predicting the dynamics of the world, which is essential for video generation. However, existing world models are confined to specific scenarios such as gaming or driving, limiting their ability to capture the complexity of general world dynamic environments. Therefore, we introduce WorldDreamer, a pioneering world model to foster a comprehensive comprehension of general world physics and motions, which significantly enhances the capabilities of video generation. Drawing inspiration from the success of large language models, WorldDreamer frames world modeling as an unsupervised visual sequence modeling challenge. This is achieved by mapping visual inputs to discrete tokens and predicting the masked ones. During this process, we incorporate multi-modal prompts to facilitate interaction within the world model. Our experiments show that WorldDreamer excels in generating videos across different scenarios, including natural scenes and driving environments. WorldDreamer showcases versatility in executing tasks such as text-to-video conversion, image-tovideo synthesis, and video editing. These results underscore WorldDreamer's effectiveness in capturing dynamic elements within diverse general world environments.
DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving
Sep 18, 2023World models, especially in autonomous driving, are trending and drawing extensive attention due to their capacity for comprehending driving environments. The established world model holds immense potential for the generation of high-quality driving videos, and driving policies for safe maneuvering. However, a critical limitation in relevant research lies in its predominant focus on gaming environments or simulated settings, thereby lacking the representation of real-world driving scenarios. Therefore, we introduce DriveDreamer, a pioneering world model entirely derived from real-world driving scenarios. Regarding that modeling the world in intricate driving scenes entails an overwhelming search space, we propose harnessing the powerful diffusion model to construct a comprehensive representation of the complex environment. Furthermore, we introduce a two-stage training pipeline. In the initial phase, DriveDreamer acquires a deep understanding of structured traffic constraints, while the subsequent stage equips it with the ability to anticipate future states. The proposed DriveDreamer is the first world model established from real-world driving scenarios. We instantiate DriveDreamer on the challenging nuScenes benchmark, and extensive experiments verify that DriveDreamer empowers precise, controllable video generation that faithfully captures the structural constraints of real-world traffic scenarios. Additionally, DriveDreamer enables the generation of realistic and reasonable driving policies, opening avenues for interaction and practical applications.
Deep trip generation with graph neural networks for bike sharing system expansion
Mar 20, 2023



Bike sharing is emerging globally as an active, convenient, and sustainable mode of transportation. To plan successful bike-sharing systems (BSSs), many cities start from a small-scale pilot and gradually expand the system to cover more areas. For station-based BSSs, this means planning new stations based on existing ones over time, which requires prediction of the number of trips generated by these new stations across the whole system. Previous studies typically rely on relatively simple regression or machine learning models, which are limited in capturing complex spatial relationships. Despite the growing literature in deep learning methods for travel demand prediction, they are mostly developed for short-term prediction based on time series data, assuming no structural changes to the system. In this study, we focus on the trip generation problem for BSS expansion, and propose a graph neural network (GNN) approach to predicting the station-level demand based on multi-source urban built environment data. Specifically, it constructs multiple localized graphs centered on each target station and uses attention mechanisms to learn the correlation weights between stations. We further illustrate that the proposed approach can be regarded as a generalized spatial regression model, indicating the commonalities between spatial regression and GNNs. The model is evaluated based on realistic experiments using multi-year BSS data from New York City, and the results validate the superior performance of our approach compared to existing methods. We also demonstrate the interpretability of the model for uncovering the effects of built environment features and spatial interactions between stations, which can provide strategic guidance for BSS station location selection and capacity planning.
Detachable Novel Views Synthesis of Dynamic Scenes Using Distribution-Driven Neural Radiance Fields
Jan 01, 2023Representing and synthesizing novel views in real-world dynamic scenes from casual monocular videos is a long-standing problem. Existing solutions typically approach dynamic scenes by applying geometry techniques or utilizing temporal information between several adjacent frames without considering the underlying background distribution in the entire scene or the transmittance over the ray dimension, limiting their performance on static and occlusion areas. Our approach $\textbf{D}$istribution-$\textbf{D}$riven neural radiance fields offers high-quality view synthesis and a 3D solution to $\textbf{D}$etach the background from the entire $\textbf{D}$ynamic scene, which is called $\text{D}^4$NeRF. Specifically, it employs a neural representation to capture the scene distribution in the static background and a 6D-input NeRF to represent dynamic objects, respectively. Each ray sample is given an additional occlusion weight to indicate the transmittance lying in the static and dynamic components. We evaluate $\text{D}^4$NeRF on public dynamic scenes and our urban driving scenes acquired from an autonomous-driving dataset. Extensive experiments demonstrate that our approach outperforms previous methods in rendering texture details and motion areas while also producing a clean static background. Our code will be released at https://github.com/Luciferbobo/D4NeRF.
Are We Ready for Vision-Centric Driving Streaming Perception? The ASAP Benchmark
Dec 17, 2022



In recent years, vision-centric perception has flourished in various autonomous driving tasks, including 3D detection, semantic map construction, motion forecasting, and depth estimation. Nevertheless, the latency of vision-centric approaches is too high for practical deployment (e.g., most camera-based 3D detectors have a runtime greater than 300ms). To bridge the gap between ideal research and real-world applications, it is necessary to quantify the trade-off between performance and efficiency. Traditionally, autonomous-driving perception benchmarks perform the offline evaluation, neglecting the inference time delay. To mitigate the problem, we propose the Autonomous-driving StreAming Perception (ASAP) benchmark, which is the first benchmark to evaluate the online performance of vision-centric perception in autonomous driving. On the basis of the 2Hz annotated nuScenes dataset, we first propose an annotation-extending pipeline to generate high-frame-rate labels for the 12Hz raw images. Referring to the practical deployment, the Streaming Perception Under constRained-computation (SPUR) evaluation protocol is further constructed, where the 12Hz inputs are utilized for streaming evaluation under the constraints of different computational resources. In the ASAP benchmark, comprehensive experiment results reveal that the model rank alters under different constraints, suggesting that the model latency and computation budget should be considered as design choices to optimize the practical deployment. To facilitate further research, we establish baselines for camera-based streaming 3D detection, which consistently enhance the streaming performance across various hardware. ASAP project page: https://github.com/JeffWang987/ASAP.
BEVPoolv2: A Cutting-edge Implementation of BEVDet Toward Deployment
Nov 30, 2022



We release a new codebase version of the BEVDet, dubbed branch dev2.0. With dev2.0, we propose BEVPoolv2 upgrade the view transformation process from the perspective of engineering optimization, making it free from a huge burden in both calculation and storage aspects. It achieves this by omitting the calculation and preprocessing of the large frustum feature. As a result, it can be processed within 0.82 ms even with a large input resolution of 640x1600, which is 15.1 times the previous fastest implementation. Besides, it is also less cache consumptive when compared with the previous implementation, naturally as it no longer needs to store the large frustum feature. Last but not least, this also makes the deployment to the other backend handy. We offer an example of deployment to the TensorRT backend in branch dev2.0 and show how fast the BEVDet paradigm can be processed on it. Other than BEVPoolv2, we also select and integrate some substantial progress that was proposed in the past year. As an example configuration, BEVDet4D-R50-Depth-CBGS scores 52.3 NDS on the NuScenes validation set and can be processed at a speed of 16.4 FPS with the PyTorch backend. The code has been released to facilitate the study on https://github.com/HuangJunJie2017/BEVDet/tree/dev2.0.
Cross-Mode Knowledge Adaptation for Bike Sharing Demand Prediction using Domain-Adversarial Graph Neural Networks
Nov 16, 2022



For bike sharing systems, demand prediction is crucial to ensure the timely re-balancing of available bikes according to predicted demand. Existing methods for bike sharing demand prediction are mostly based on its own historical demand variation, essentially regarding it as a closed system and neglecting the interaction between different transportation modes. This is particularly important for bike sharing because it is often used to complement travel through other modes (e.g., public transit). Despite some recent progress, no existing method is capable of leveraging spatiotemporal information from multiple modes and explicitly considers the distribution discrepancy between them, which can easily lead to negative transfer. To address these challenges, this study proposes a domain-adversarial multi-relational graph neural network (DA-MRGNN) for bike sharing demand prediction with multimodal historical data as input. A temporal adversarial adaptation network is introduced to extract shareable features from demand patterns of different modes. To capture correlations between spatial units across modes, we adapt a multi-relational graph neural network (MRGNN) considering both cross-mode similarity and difference. In addition, an explainable GNN technique is developed to understand how our proposed model makes predictions. Extensive experiments are conducted using real-world bike sharing, subway and ride-hailing data from New York City. The results demonstrate the superior performance of our proposed approach compared to existing methods and the effectiveness of different model components.
Hybrid CNN -Interpreter: Interpret local and global contexts for CNN-based Models
Oct 31, 2022



Convolutional neural network (CNN) models have seen advanced improvements in performance in various domains, but lack of interpretability is a major barrier to assurance and regulation during operation for acceptance and deployment of AI-assisted applications. There have been many works on input interpretability focusing on analyzing the input-output relations, but the internal logic of models has not been clarified in the current mainstream interpretability methods. In this study, we propose a novel hybrid CNN-interpreter through: (1) An original forward propagation mechanism to examine the layer-specific prediction results for local interpretability. (2) A new global interpretability that indicates the feature correlation and filter importance effects. By combining the local and global interpretabilities, hybrid CNN-interpreter enables us to have a solid understanding and monitoring of model context during the whole learning process with detailed and consistent representations. Finally, the proposed interpretabilities have been demonstrated to adapt to various CNN-based model structures.
A Simple Baseline for Multi-Camera 3D Object Detection
Aug 22, 2022
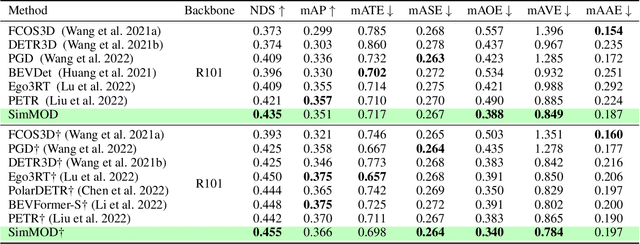
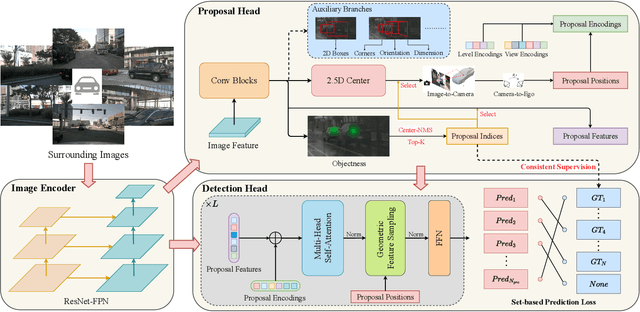
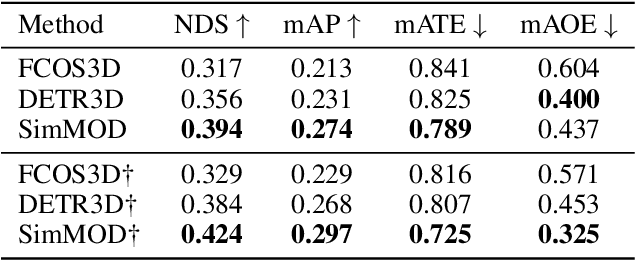
3D object detection with surrounding cameras has been a promising direction for autonomous driving. In this paper, we present SimMOD, a Simple baseline for Multi-camera Object Detection, to solve the problem. To incorporate multi-view information as well as build upon previous efforts on monocular 3D object detection, the framework is built on sample-wise object proposals and designed to work in a two-stage manner. First, we extract multi-scale features and generate the perspective object proposals on each monocular image. Second, the multi-view proposals are aggregated and then iteratively refined with multi-view and multi-scale visual features in the DETR3D-style. The refined proposals are end-to-end decoded into the detection results. To further boost the performance, we incorporate the auxiliary branches alongside the proposal generation to enhance the feature learning. Also, we design the methods of target filtering and teacher forcing to promote the consistency of two-stage training. We conduct extensive experiments on the 3D object detection benchmark of nuScenes to demonstrate the effectiveness of SimMOD and achieve new state-of-the-art performance. Code will be available at https://github.com/zhangyp15/SimMOD.