 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndoscopic navigation in the absence of CT imaging
Jun 08, 2018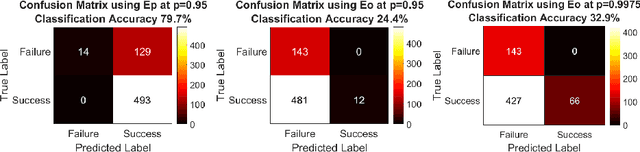
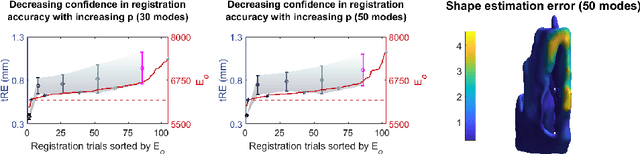
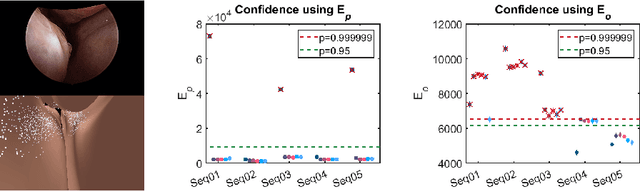
Clinical examinations that involve endoscopic exploration of the nasal cavity and sinuses often do not have a reference image to provide structural context to the clinician. In this paper, we present a system for navigation during clinical endoscopic exploration in the absence of computed tomography (CT) scans by making use of shape statistics from past CT scans. Using a deformable registration algorithm along with dense reconstructions from video, we show that we are able to achieve submillimeter registrations in in-vivo clinical data and are able to assign confidence to these registrations using confidence criteria established using simulated data.
Analyzing and Exploiting NARX Recurrent Neural Networks for Long-Term Dependencies
Apr 20, 2018
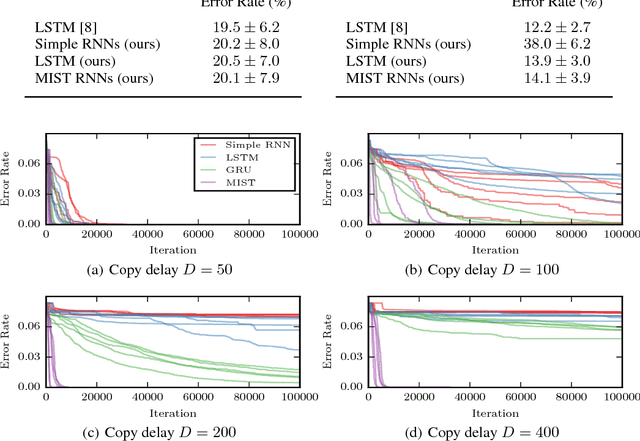


Recurrent neural networks (RNNs) have achieved state-of-the-art performance on many diverse tasks, from machine translation to surgical activity recognition, yet training RNNs to capture long-term dependencies remains difficult. To date, the vast majority of successful RNN architectures alleviate this problem using nearly-additive connections between states, as introduced by long short-term memory (LSTM). We take an orthogonal approach and introduce MIST RNNs, a NARX RNN architecture that allows direct connections from the very distant past. We show that MIST RNNs 1) exhibit superior vanishing-gradient properties in comparison to LSTM and previously-proposed NARX RNNs; 2) are far more efficient than previously-proposed NARX RNN architectures, requiring even fewer computations than LSTM; and 3) improve performance substantially over LSTM and Clockwork RNNs on tasks requiring very long-term dependencies.
Visual Robot Task Planning
Mar 30, 2018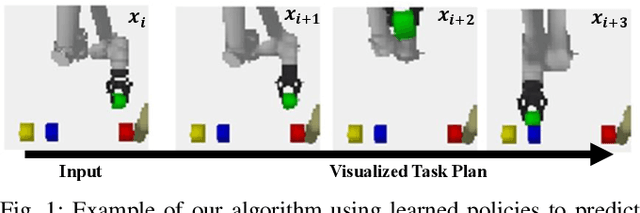

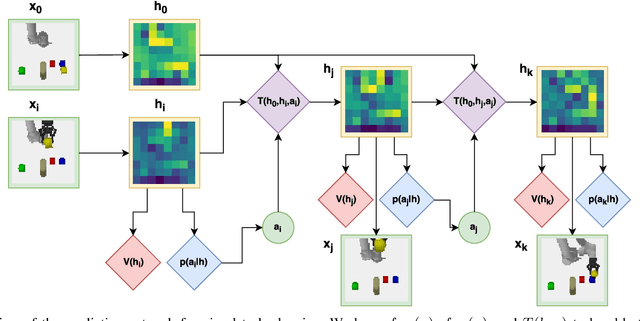
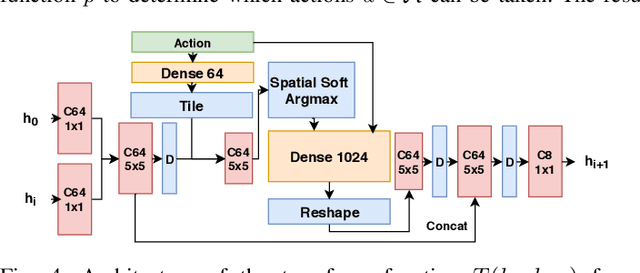
Prospection, the act of predicting the consequences of many possible futures, is intrinsic to human planning and action, and may even be at the root of consciousness. Surprisingly, this idea has been explored comparatively little in robotics. In this work, we propose a neural network architecture and associated planning algorithm that (1) learns a representation of the world useful for generating prospective futures after the application of high-level actions, (2) uses this generative model to simulate the result of sequences of high-level actions in a variety of environments, and (3) uses this same representation to evaluate these actions and perform tree search to find a sequence of high-level actions in a new environment. Models are trained via imitation learning on a variety of domains, including navigation, pick-and-place, and a surgical robotics task. Our approach allows us to visualize intermediate motion goals and learn to plan complex activity from visual information.
Guide Me: Interacting with Deep Networks
Mar 30, 2018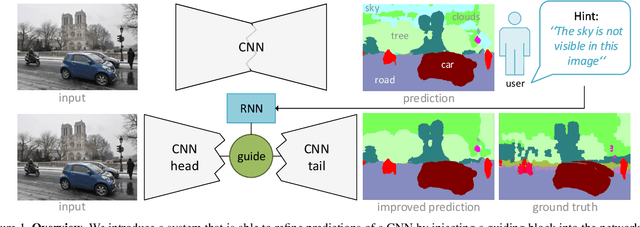
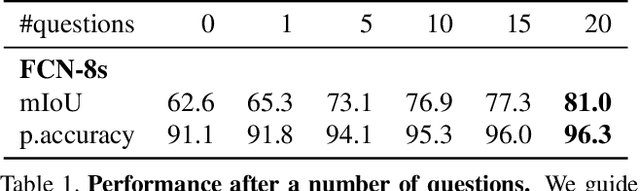
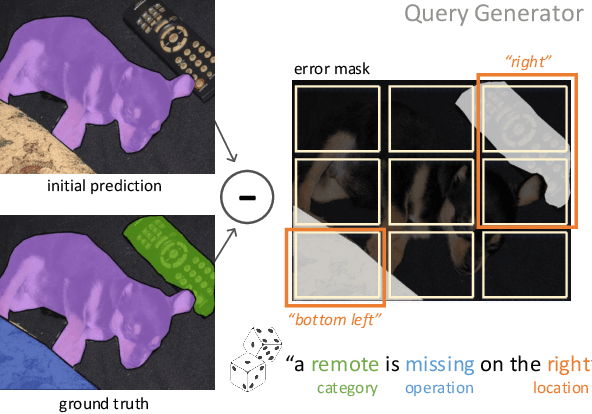
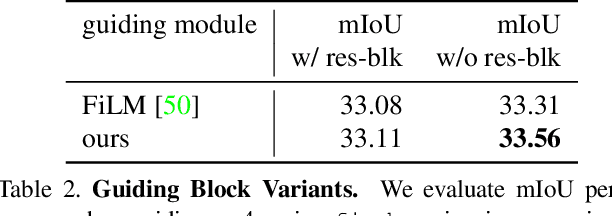
Interaction and collaboration between humans and intelligent machines has become increasingly important as machine learning methods move into real-world applications that involve end users. While much prior work lies at the intersection of natural language and vision, such as image captioning or image generation from text descriptions, less focus has been placed on the use of language to guide or improve the performance of a learned visual processing algorithm. In this paper, we explore methods to flexibly guide a trained convolutional neural network through user input to improve its performance during inference. We do so by inserting a layer that acts as a spatio-semantic guide into the network. This guide is trained to modify the network's activations, either directly via an energy minimization scheme or indirectly through a recurrent model that translates human language queries to interaction weights. Learning the verbal interaction is fully automatic and does not require manual text annotations. We evaluate the method on two datasets, showing that guiding a pre-trained network can improve performance, and provide extensive insights into the interaction between the guide and the CNN.
Occupancy Map Prediction Using Generative and Fully Convolutional Networks for Vehicle Navigation
Mar 06, 2018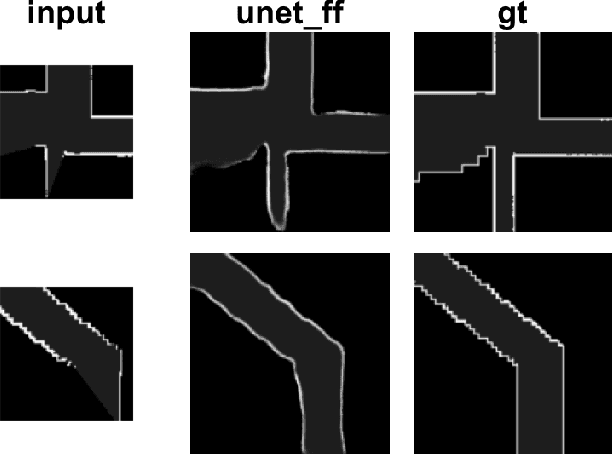
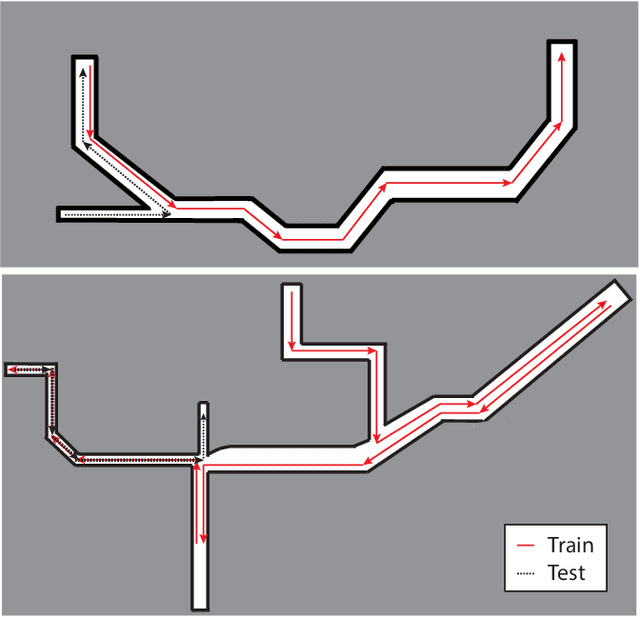

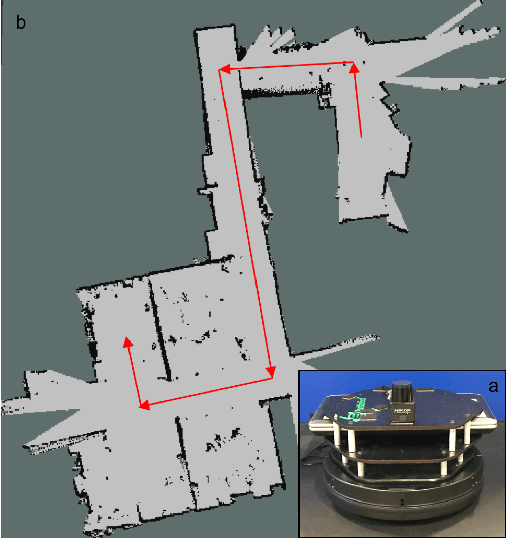
Fast, collision-free motion through unknown environments remains a challenging problem for robotic systems. In these situations, the robot's ability to reason about its future motion is often severely limited by sensor field of view (FOV). By contrast, biological systems routinely make decisions by taking into consideration what might exist beyond their FOV based on prior experience. In this paper, we present an approach for predicting occupancy map representations of sensor data for future robot motions using deep neural networks. We evaluate several deep network architectures, including purely generative and adversarial models. Testing on both simulated and real environments we demonstrated performance both qualitatively and quantitatively, with SSIM similarity measure up to 0.899. We showed that it is possible to make predictions about occupied space beyond the physical robot's FOV from simulated training data. In the future, this method will allow robots to navigate through unknown environments in a faster, safer manner.
Adversarial Deep Structured Nets for Mass Segmentation from Mammograms
Dec 25, 2017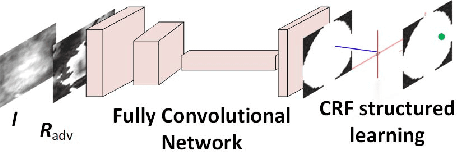
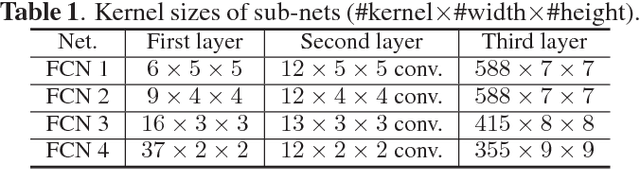

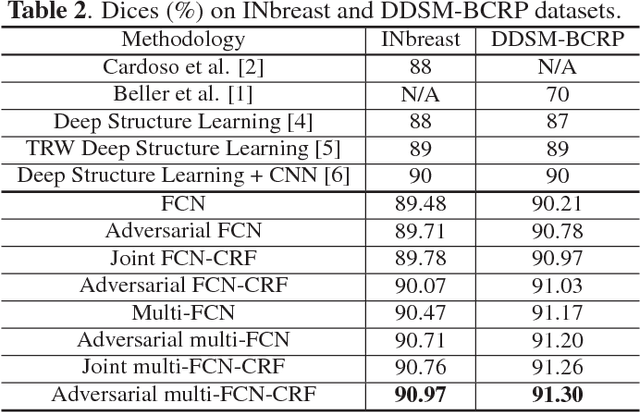
Mass segmentation provides effective morphological features which are important for mass diagnosis. In this work, we propose a novel end-to-end network for mammographic mass segmentation which employs a fully convolutional network (FCN) to model a potential function, followed by a CRF to perform structured learning. Because the mass distribution varies greatly with pixel position, the FCN is combined with a position priori. Further, we employ adversarial training to eliminate over-fitting due to the small sizes of mammogram datasets. Multi-scale FCN is employed to improve the segmentation performance. Experimental results on two public datasets, INbreast and DDSM-BCRP, demonstrate that our end-to-end network achieves better performance than state-of-the-art approaches. \footnote{https://github.com/wentaozhu/adversarial-deep-structural-networks.git}
Learning to Imagine Manipulation Goals for Robot Task Planning
Nov 09, 2017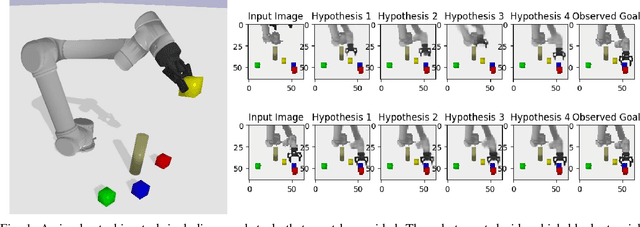
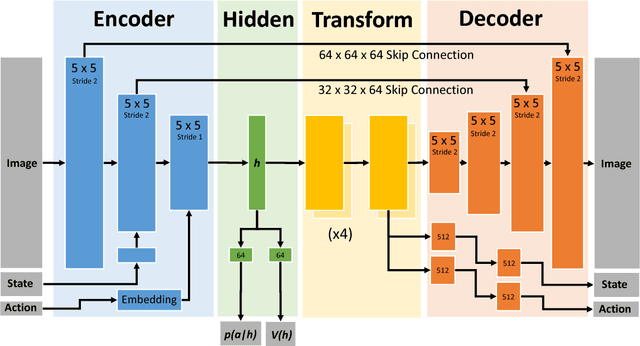

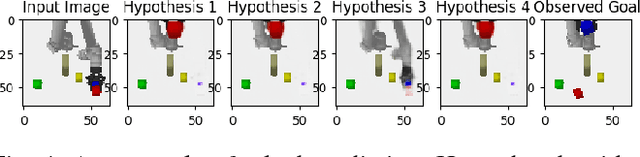
Prospection is an important part of how humans come up with new task plans, but has not been explored in depth in robotics. Predicting multiple task-level is a challenging problem that involves capturing both task semantics and continuous variability over the state of the world. Ideally, we would combine the ability of machine learning to leverage big data for learning the semantics of a task, while using techniques from task planning to reliably generalize to new environment. In this work, we propose a method for learning a model encoding just such a representation for task planning. We learn a neural net that encodes the $k$ most likely outcomes from high level actions from a given world. Our approach creates comprehensible task plans that allow us to predict changes to the environment many time steps into the future. We demonstrate this approach via application to a stacking task in a cluttered environment, where the robot must select between different colored blocks while avoiding obstacles, in order to perform a task. We also show results on a simple navigation task. Our algorithm generates realistic image and pose predictions at multiple points in a given task.
Temporal and Physical Reasoning for Perception-Based Robotic Manipulation
Oct 11, 2017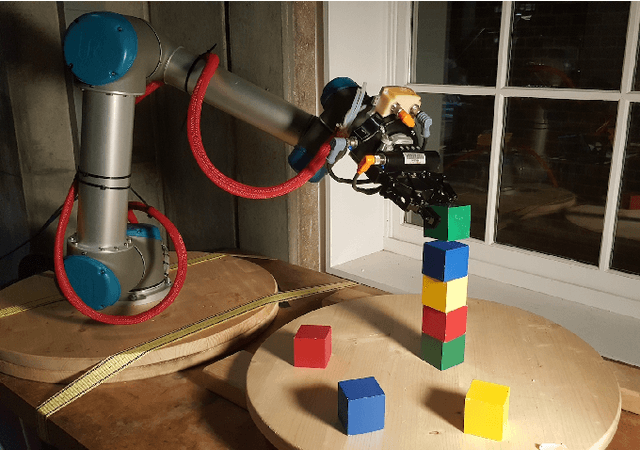

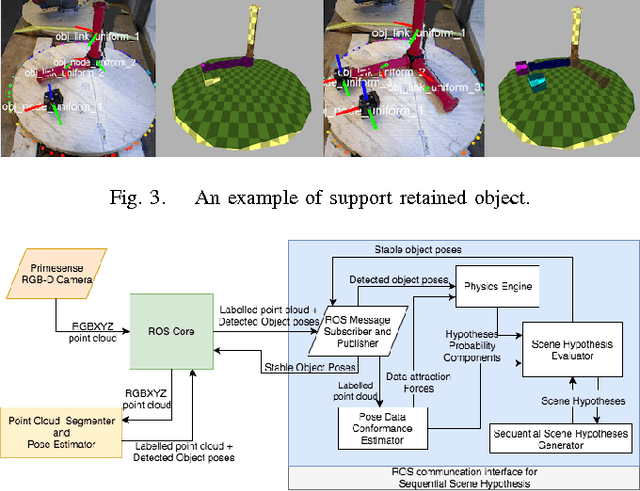

Accurate knowledge of object poses is crucial to successful robotic manipulation tasks, and yet most current approaches only work in laboratory settings. Noisy sensors and cluttered scenes interfere with accurate pose recognition, which is problematic especially when performing complex tasks involving object interactions. This is because most pose estimation algorithms focus only on estimating objects from a single frame, which means they lack continuity between frames. Further, they often do not consider resulting physical properties of the predicted scene such as intersecting objects or objects in unstable positions. In this work, we enhance the accuracy and stability of estimated poses for a whole scene by enforcing these physical constraints over time through the integration of a physics simulation. This allows us to accurately determine relationships between objects for a construction task. Scene parsing performance was evaluated on both simulated and real- world data. We apply our method to a real-world block stacking task, where the robot must build a tall tower of colored blocks.
Learning in an Uncertain World: Representing Ambiguity Through Multiple Hypotheses
Aug 22, 2017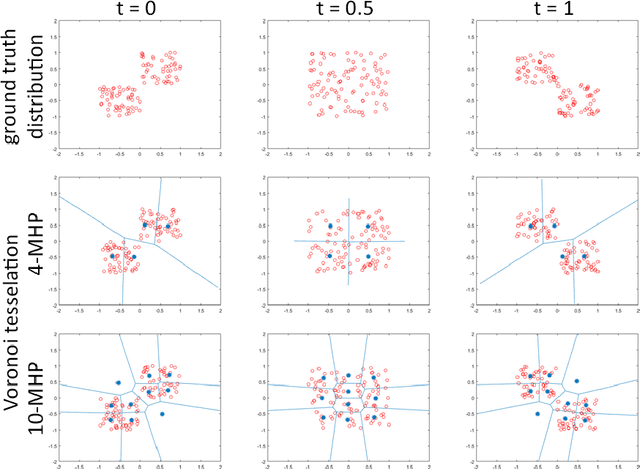
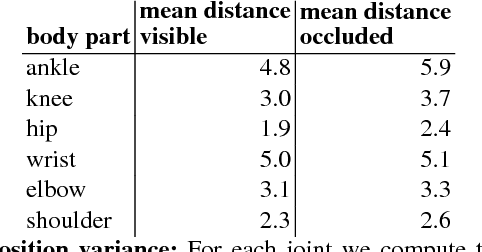

Many prediction tasks contain uncertainty. In some cases, uncertainty is inherent in the task itself. In future prediction, for example, many distinct outcomes are equally valid. In other cases, uncertainty arises from the way data is labeled. For example, in object detection, many objects of interest often go unlabeled, and in human pose estimation, occluded joints are often labeled with ambiguous values. In this work we focus on a principled approach for handling such scenarios. In particular, we propose a framework for reformulating existing single-prediction models as multiple hypothesis prediction (MHP) models and an associated meta loss and optimization procedure to train them. To demonstrate our approach, we consider four diverse applications: human pose estimation, future prediction, image classification and segmentation. We find that MHP models outperform their single-hypothesis counterparts in all cases, and that MHP models simultaneously expose valuable insights into the variability of predictions.
Advances in Artificial Intelligence Require Progress Across all of Computer Science
Jul 13, 2017Advances in Artificial Intelligence require progress across all of computer science.