 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Hyper RNN for Sequence Modeling
Feb 24, 2020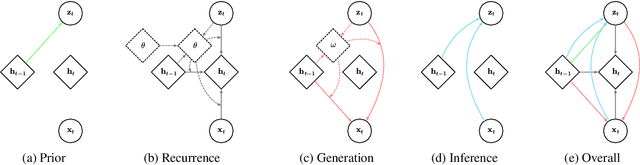

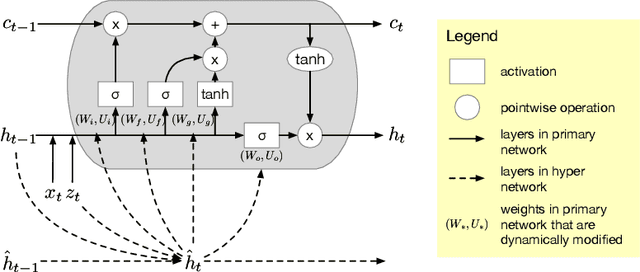
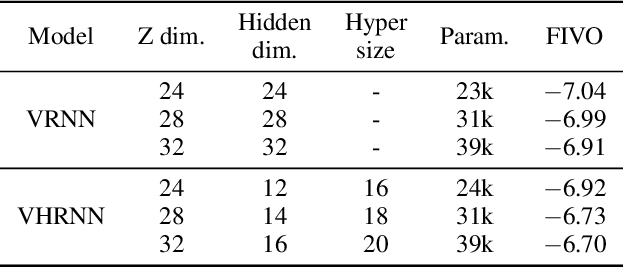
In this work, we propose a novel probabilistic sequence model that excels at capturing high variability in time series data, both across sequences and within an individual sequence. Our method uses temporal latent variables to capture information about the underlying data pattern and dynamically decodes the latent information into modifications of weights of the base decoder and recurrent model. The efficacy of the proposed method is demonstrated on a range of synthetic and real-world sequential data that exhibit large scale variations, regime shifts, and complex dynamics.
Adapting Grad-CAM for Embedding Networks
Jan 17, 2020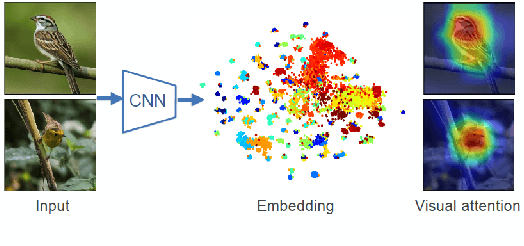

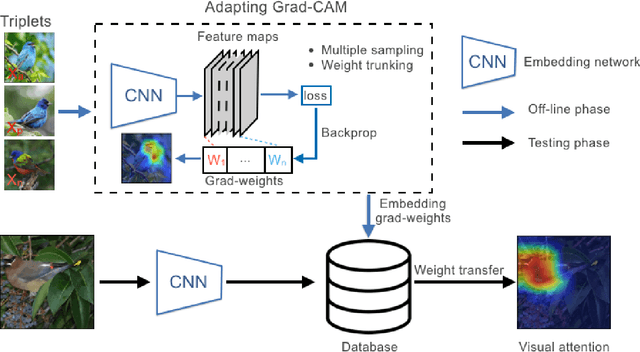
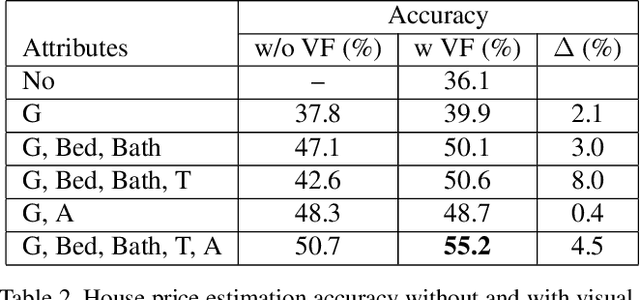
The gradient-weighted class activation mapping (Grad-CAM) method can faithfully highlight important regions in images for deep model prediction in image classification, image captioning and many other tasks. It uses the gradients in back-propagation as weights (grad-weights) to explain network decisions. However, applying Grad-CAM to embedding networks raises significant challenges because embedding networks are trained by millions of dynamically paired examples (e.g. triplets). To overcome these challenges, we propose an adaptation of the Grad-CAM method for embedding networks. First, we aggregate grad-weights from multiple training examples to improve the stability of Grad-CAM. Then, we develop an efficient weight-transfer method to explain decisions for any image without back-propagation. We extensively validate the method on the standard CUB200 dataset in which our method produces more accurate visual attention than the original Grad-CAM method. We also apply the method to a house price estimation application using images. The method produces convincing qualitative results, showcasing the practicality of our approach.
Point Process Flows
Oct 31, 2019
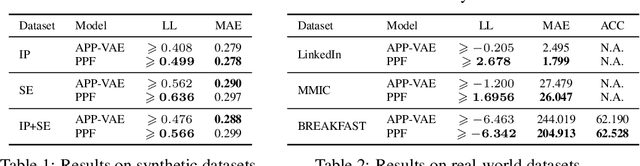
Event sequences can be modeled by temporal point processes (TPPs) to capture their asynchronous and probabilistic nature. We propose an intensity-free framework that directly models the point process distribution by utilizing normalizing flows. This approach is capable of capturing highly complex temporal distributions and does not rely on restrictive parametric forms. Comparisons with state-of-the-art baseline models on both synthetic and challenging real-life datasets show that the proposed framework is effective at modeling the stochasticity of discrete event sequences.
Graph Generation with Variational Recurrent Neural Network
Oct 02, 2019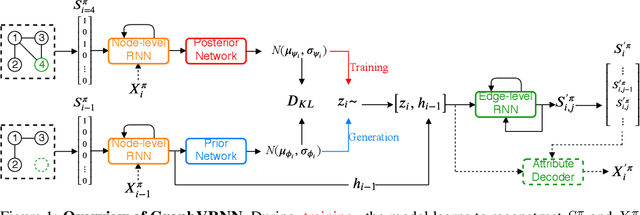
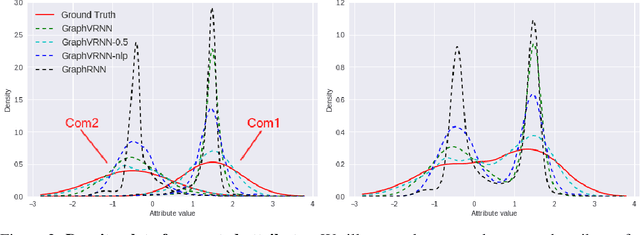
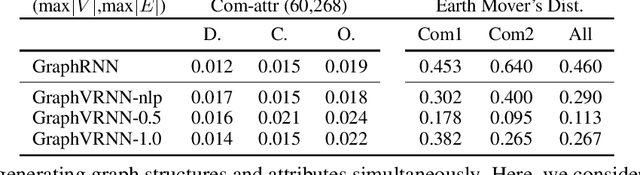

Generating graph structures is a challenging problem due to the diverse representations and complex dependencies among nodes. In this paper, we introduce Graph Variational Recurrent Neural Network (GraphVRNN), a probabilistic autoregressive model for graph generation. Through modeling the latent variables of graph data, GraphVRNN can capture the joint distributions of graph structures and the underlying node attributes. We conduct experiments on the proposed GraphVRNN in both graph structure learning and attribute generation tasks. The evaluation results show that the variational component allows our network to model complicated distributions, as well as generate plausible structures and node attributes.
Relational Graph Learning for Crowd Navigation
Oct 01, 2019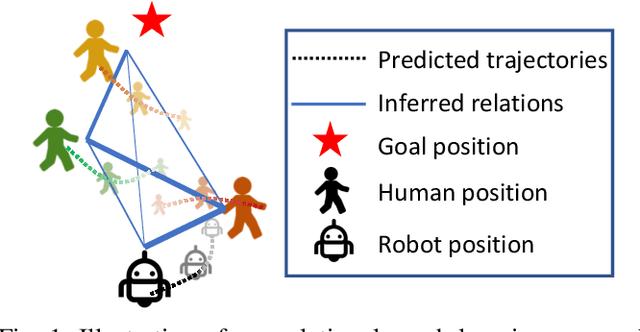
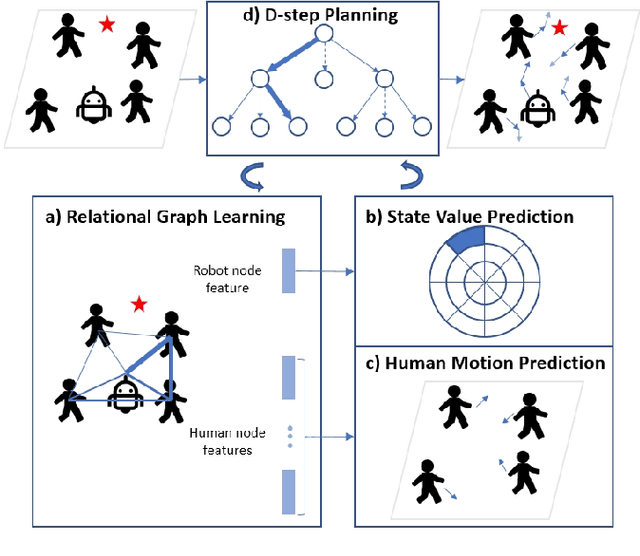
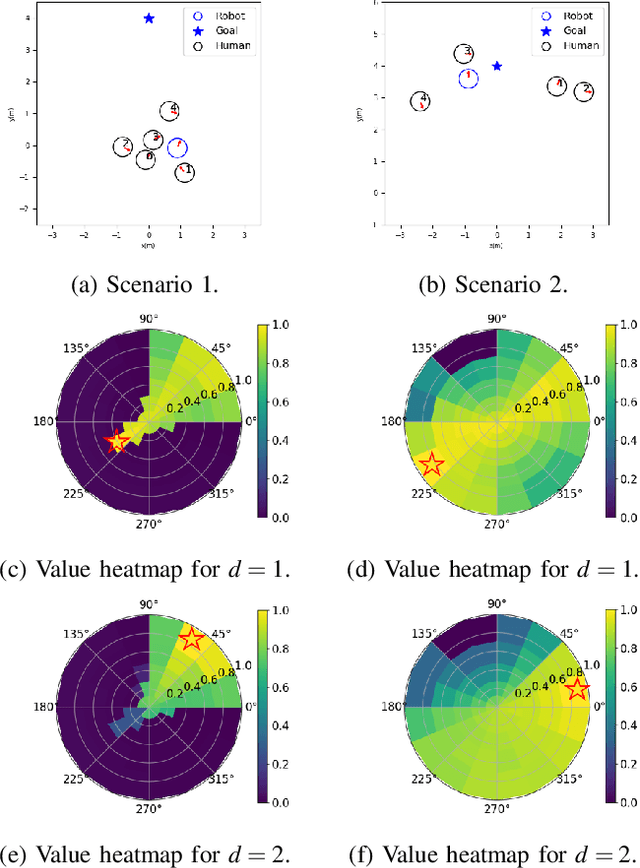

We present a relational graph learning approach for robotic crowd navigation using model-based deep reinforcement learning that plans actions by looking into the future. Our approach reasons about the relations between all agents based on their latent features and uses a Graph Convolutional Network to encode higher-order interactions in each agent's state representation, which is subsequently leveraged for state prediction and value estimation. The ability to predict human motion allows us to perform multi-step lookahead planning, taking into account the temporal evolution of human crowds. We evaluate our approach against a state-of-the-art baseline for crowd navigation and ablations of our model to demonstrate that navigation with our approach is more efficient, results in fewer collisions, and avoids failure cases involving oscillatory and freezing behaviors.
Policy Message Passing: A New Algorithm for Probabilistic Graph Inference
Sep 29, 2019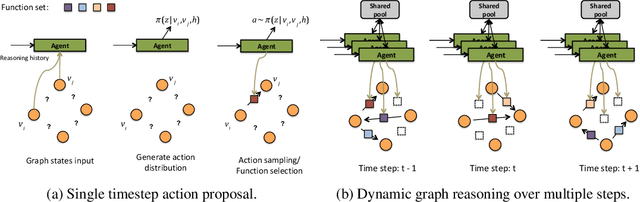
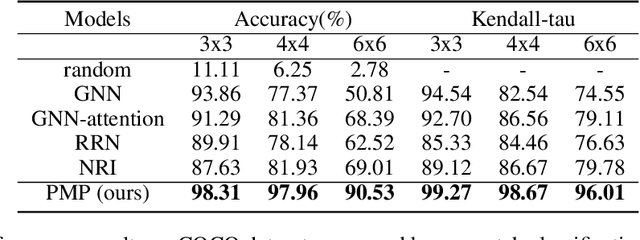

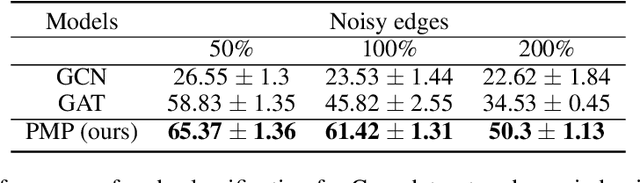
A general graph-structured neural network architecture operates on graphs through two core components: (1) complex enough message functions; (2) a fixed information aggregation process. In this paper, we present the Policy Message Passing algorithm, which takes a probabilistic perspective and reformulates the whole information aggregation as stochastic sequential processes. The algorithm works on a much larger search space, utilizes reasoning history to perform inference, and is robust to noisy edges. We apply our algorithm to multiple complex graph reasoning and prediction tasks and show that our algorithm consistently outperforms state-of-the-art graph-structured models by a significant margin.
COPHY: Counterfactual Learning of Physical Dynamics
Sep 26, 2019



Understanding causes and effects in mechanical systems is an essential component of reasoning in the physical world. This work poses a new problem of counterfactual learning of object mechanics from visual input. We develop the COPHY benchmark to assess the capacity of the state-of-the-art models for causal physical reasoning in a synthetic 3D environment and propose a model for learning the physical dynamics in a counterfactual setting. Having observed a mechanical experiment that involves, for example, a falling tower of blocks, a set of bouncing balls or colliding objects, we learn to predict how its outcome is affected by an arbitrary intervention on its initial conditions, such as displacing one of the objects in the scene. The alternative future is predicted given the altered past and a latent representation of the confounders learned by the model in an end-to-end fashion with no supervision. We compare against feedforward video prediction baselines and show how observing alternative experiences allows the network to capture latent physical properties of the environment, which results in significantly more accurate predictions at the level of super human performance.
Lifelong GAN: Continual Learning for Conditional Image Generation
Aug 22, 2019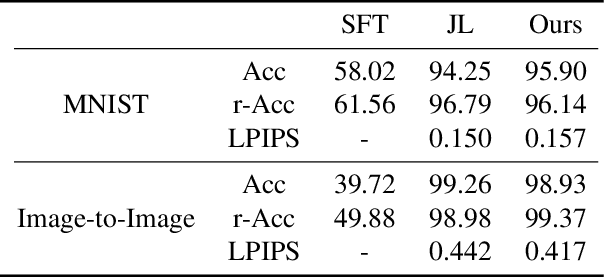
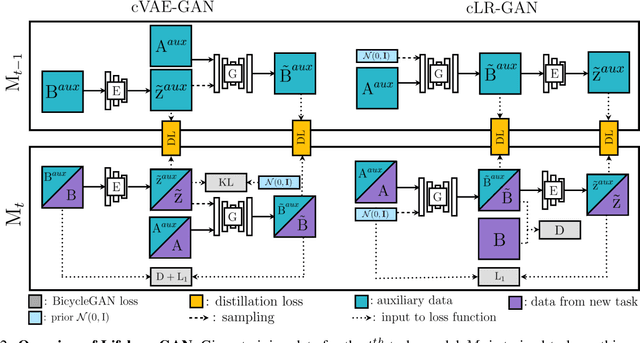
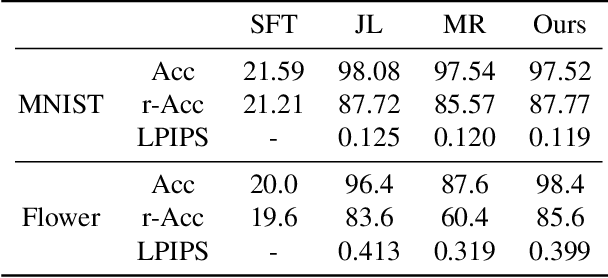

Lifelong learning is challenging for deep neural networks due to their susceptibility to catastrophic forgetting. Catastrophic forgetting occurs when a trained network is not able to maintain its ability to accomplish previously learned tasks when it is trained to perform new tasks. We study the problem of lifelong learning for generative models, extending a trained network to new conditional generation tasks without forgetting previous tasks, while assuming access to the training data for the current task only. In contrast to state-of-the-art memory replay based approaches which are limited to label-conditioned image generation tasks, a more generic framework for continual learning of generative models under different conditional image generation settings is proposed in this paper. Lifelong GAN employs knowledge distillation to transfer learned knowledge from previous networks to the new network. This makes it possible to perform image-conditioned generation tasks in a lifelong learning setting. We validate Lifelong GAN for both image-conditioned and label-conditioned generation tasks, and provide qualitative and quantitative results to show the generality and effectiveness of our method.
LayoutVAE: Stochastic Scene Layout Generation From a Label Set
Aug 13, 2019
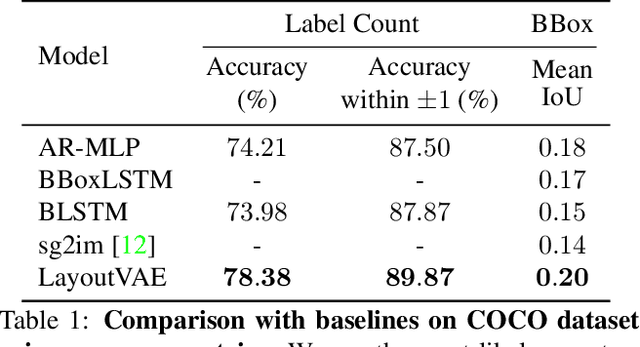
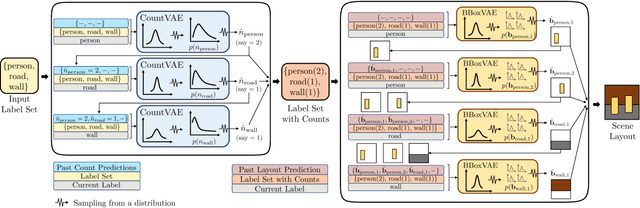
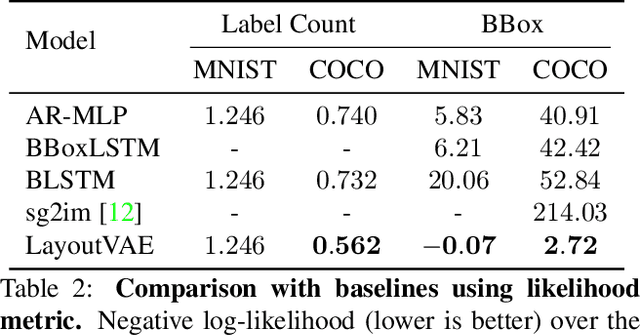
Recently there is an increasing interest in scene generation within the research community. However, models used for generating scene layouts from textual description largely ignore plausible visual variations within the structure dictated by the text. We propose LayoutVAE, a variational autoencoder based framework for generating stochastic scene layouts. LayoutVAE is a versatile modeling framework that allows for generating full image layouts given a label set, or per label layouts for an existing image given a new label. In addition, it is also capable of detecting unusual layouts, potentially providing a way to evaluate layout generation problem. Extensive experiments on MNIST-Layouts and challenging COCO 2017 Panoptic dataset verifies the effectiveness of our proposed framework.
Continuous Graph Flow for Flexible Density Estimation
Aug 07, 2019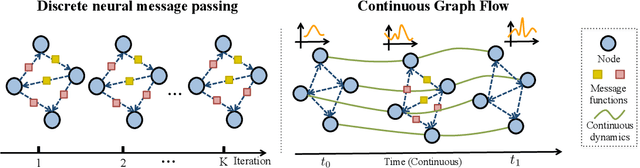
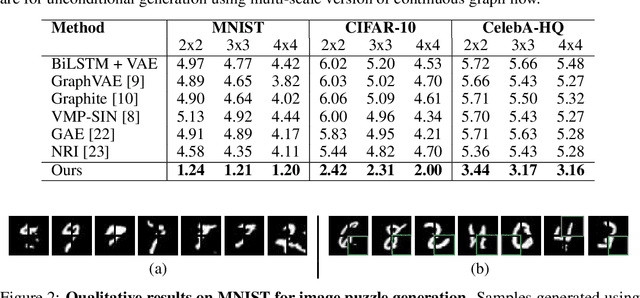

In this paper, we propose Continuous Graph Flow, a generative continuous flow based method that aims to model distributions of graph-structured complex data. The model is formulated as an ordinary differential equation system with shared and reusable functions that operate over the graph structure. This leads to a new type of neural graph message passing scheme that performs continuous message passing over time. This class of models offer several advantages: (1) modeling complex graphical distributions without rigid assumptions on the distributions; (2) not limited to modeling data of fixed dimensions and can generalize probability evaluation and data generation over unseen subset of variables; (3) the underlying continuous graph message passing process is reversible and memory-efficient. We demonstrate the effectiveness of our model on two generation tasks, namely, image puzzle generation, and layout generation from scene graphs. Compared to unstructured and structured latent-space VAE models, we show that our proposed model achieves significant performance improvement (up to 400% in negative log-likelihood).