 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Confusion in Active Learning for Part-Of-Speech Tagging
Nov 02, 2020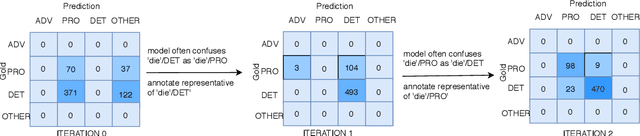

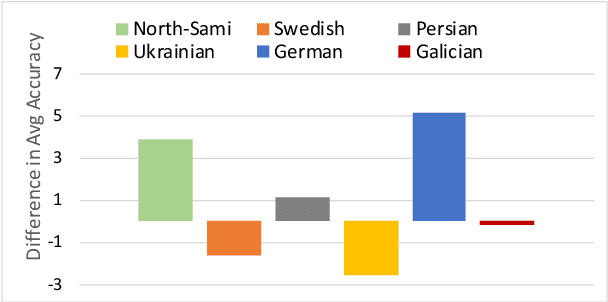

Active learning (AL) uses a data selection algorithm to select useful training samples to minimize annotation cost. This is now an essential tool for building low-resource syntactic analyzers such as part-of-speech (POS) taggers. Existing AL heuristics are generally designed on the principle of selecting uncertain yet representative training instances, where annotating these instances may reduce a large number of errors. However, in an empirical study across six typologically diverse languages (German, Swedish, Galician, North Sami, Persian, and Ukrainian), we found the surprising result that even in an oracle scenario where we know the true uncertainty of predictions, these current heuristics are far from optimal. Based on this analysis, we pose the problem of AL as selecting instances which maximally reduce the confusion between particular pairs of output tags. Extensive experimentation on the aforementioned languages shows that our proposed AL strategy outperforms other AL strategies by a significant margin. We also present auxiliary results demonstrating the importance of proper calibration of models, which we ensure through cross-view training, and analysis demonstrating how our proposed strategy selects examples that more closely follow the oracle data distribution.
X-FACTR: Multilingual Factual Knowledge Retrieval from Pretrained Language Models
Oct 27, 2020

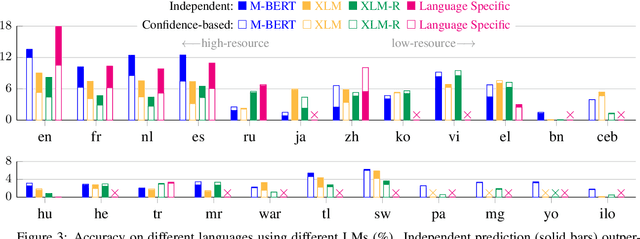
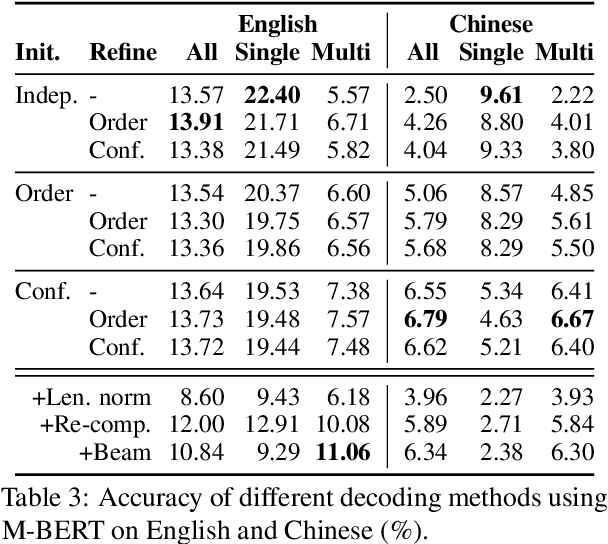
Language models (LMs) have proven surprisingly successful at capturing factual knowledge by completing cloze-style fill-in-the-blank questions such as "Punta Cana is located in _." However, while knowledge is both written and queried in many languages, studies on LMs' factual representation ability have almost invariably been performed on English. To assess factual knowledge retrieval in LMs in different languages, we create a multilingual benchmark of cloze-style probes for 23 typologically diverse languages. To properly handle language variations, we expand probing methods from single- to multi-word entities, and develop several decoding algorithms to generate multi-token predictions. Extensive experimental results provide insights about how well (or poorly) current state-of-the-art LMs perform at this task in languages with more or fewer available resources. We further propose a code-switching-based method to improve the ability of multilingual LMs to access knowledge, and verify its effectiveness on several benchmark languages. Benchmark data and code have been released at https://x-factr.github.io.
On Learning Text Style Transfer with Direct Rewards
Oct 24, 2020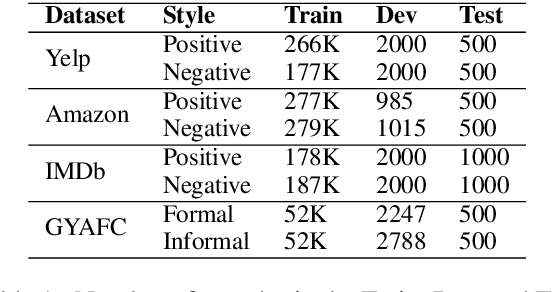
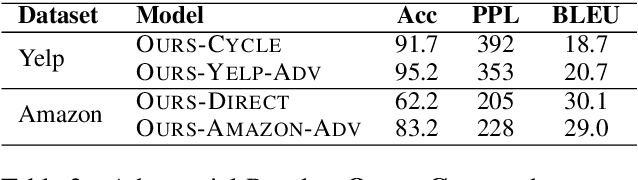
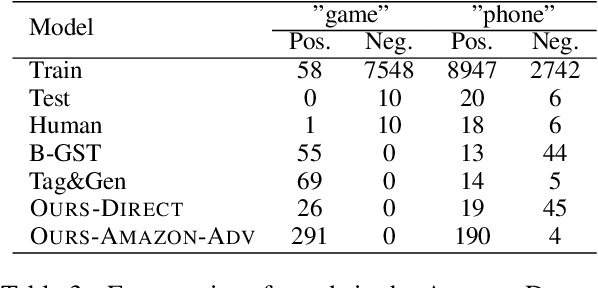

In most cases, the lack of parallel corpora makes it impossible to directly train supervised models for text style transfer task. In this paper, we explore training algorithms that instead optimize reward functions that explicitly consider different aspects of the style-transferred outputs. In particular, we leverage semantic similarity metrics originally used for fine-tuning neural machine translation models to explicitly assess the preservation of content between system outputs and input texts. We also investigate the potential weaknesses of the existing automatic metrics and propose efficient strategies of using these metrics for training. The experimental results show that our model provides significant gains in both automatic and human evaluation over strong baselines, indicating the effectiveness of our proposed methods and training strategies.
NeuSpell: A Neural Spelling Correction Toolkit
Oct 21, 2020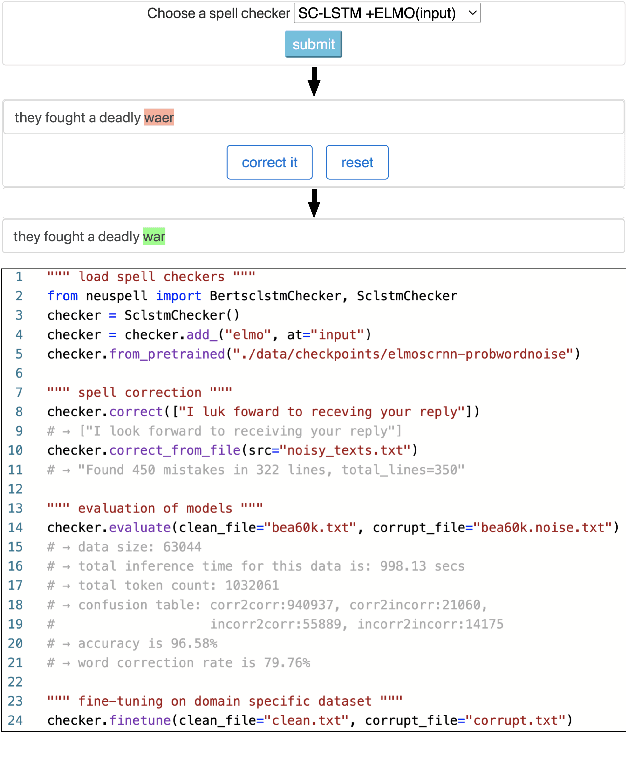
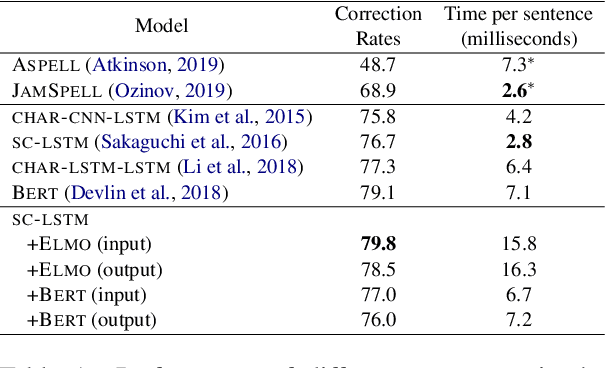
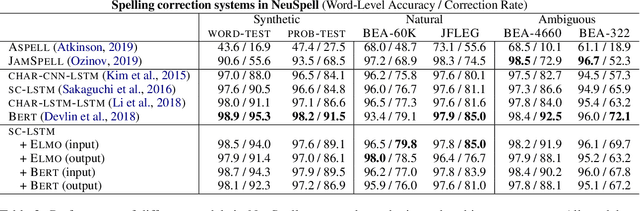
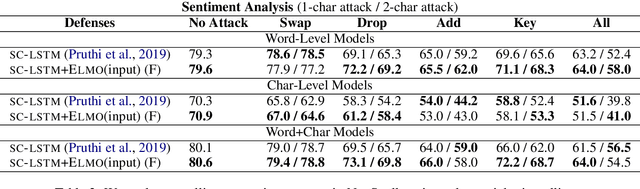
We introduce NeuSpell, an open-source toolkit for spelling correction in English. Our toolkit comprises ten different models, and benchmarks them on naturally occurring misspellings from multiple sources. We find that many systems do not adequately leverage the context around the misspelt token. To remedy this, (i) we train neural models using spelling errors in context, synthetically constructed by reverse engineering isolated misspellings; and (ii) use contextual representations. By training on our synthetic examples, correction rates improve by 9% (absolute) compared to the case when models are trained on randomly sampled character perturbations. Using richer contextual representations boosts the correction rate by another 3%. Our toolkit enables practitioners to use our proposed and existing spelling correction systems, both via a unified command line, as well as a web interface. Among many potential applications, we demonstrate the utility of our spell-checkers in combating adversarial misspellings. The toolkit can be accessed at neuspell.github.io. Code and pretrained models are available at http://github.com/neuspell/neuspell.
GSum: A General Framework for Guided Neural Abstractive Summarization
Oct 15, 2020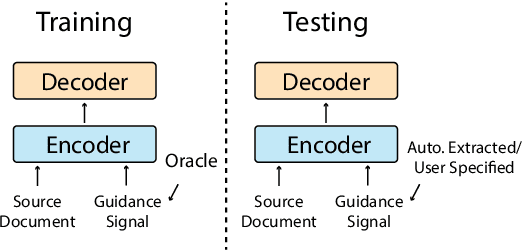
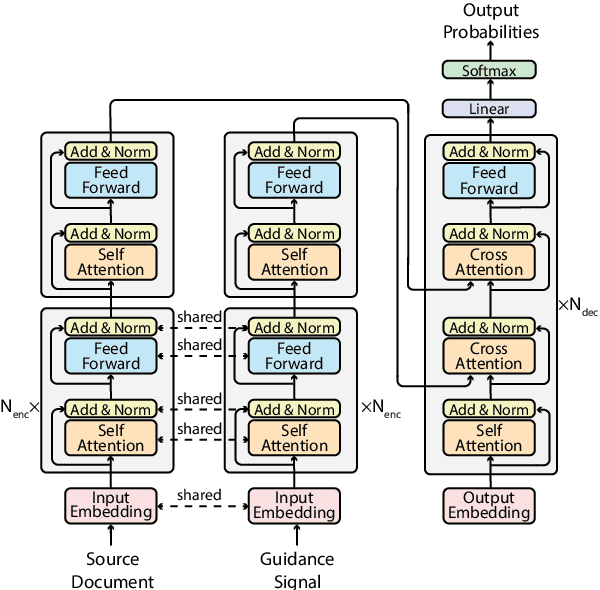
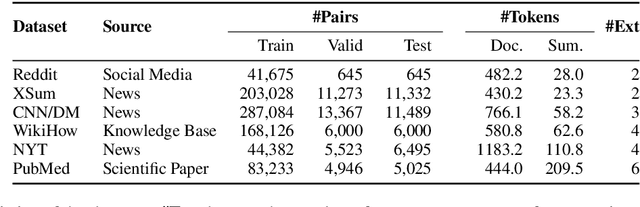
Neural abstractive summarization models are flexible and can produce coherent summaries, but they are sometimes unfaithful and can be difficult to control. While previous studies attempt to provide different types of guidance to control the output and increase faithfulness, it is not clear how these strategies compare and contrast to each other. In this paper, we propose a general and extensible guided summarization framework (GSum) that can effectively take different kinds of external guidance as input, and we perform experiments across several different varieties. Experiments demonstrate that this model is effective, achieving state-of-the-art performance according to ROUGE on 4 popular summarization datasets when using highlighted sentences as guidance. In addition, we show that our guided model can generate more faithful summaries and demonstrate how different types of guidance generate qualitatively different summaries, lending a degree of controllability to the learned models.
Explicit Alignment Objectives for Multilingual Bidirectional Encoders
Oct 15, 2020
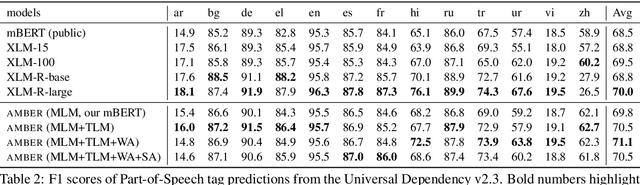
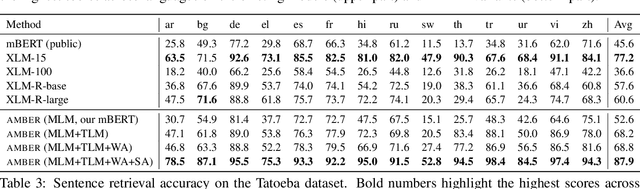
Pre-trained cross-lingual encoders such as mBERT (Devlin et al., 2019) and XLMR (Conneau et al., 2020) have proven to be impressively effective at enabling transfer-learning of NLP systems from high-resource languages to low-resource languages. This success comes despite the fact that there is no explicit objective to align the contextual embeddings of words/sentences with similar meanings across languages together in the same space. In this paper, we present a new method for learning multilingual encoders, AMBER (Aligned Multilingual Bidirectional EncodeR). AMBER is trained on additional parallel data using two explicit alignment objectives that align the multilingual representations at different granularities. We conduct experiments on zero-shot cross-lingual transfer learning for different tasks including sequence tagging, sentence retrieval and sentence classification. Experimental results show that AMBER obtains gains of up to 1.1 average F1 score on sequence tagging and up to 27.3 average accuracy on retrieval over the XLMR-large model which has 4.6x the parameters of AMBER.
Re-evaluating Evaluation in Text Summarization
Oct 14, 2020
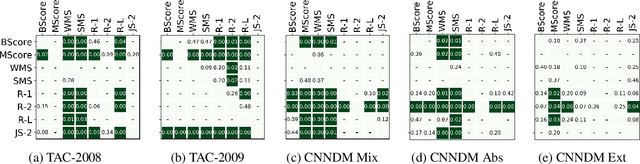

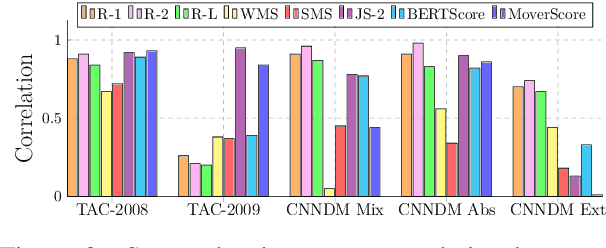
Automated evaluation metrics as a stand-in for manual evaluation are an essential part of the development of text-generation tasks such as text summarization. However, while the field has progressed, our standard metrics have not -- for nearly 20 years ROUGE has been the standard evaluation in most summarization papers. In this paper, we make an attempt to re-evaluate the evaluation method for text summarization: assessing the reliability of automatic metrics using top-scoring system outputs, both abstractive and extractive, on recently popular datasets for both system-level and summary-level evaluation settings. We find that conclusions about evaluation metrics on older datasets do not necessarily hold on modern datasets and systems.
Automatic Extraction of Rules Governing Morphological Agreement
Oct 06, 2020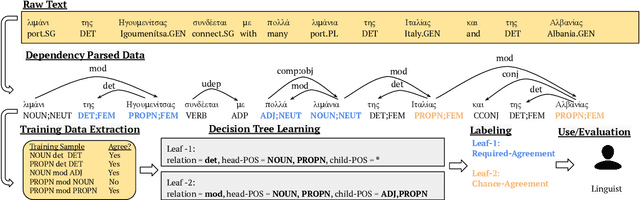
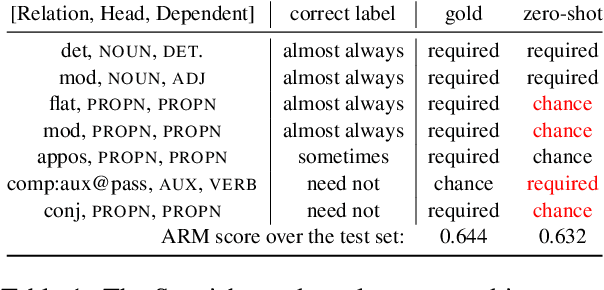
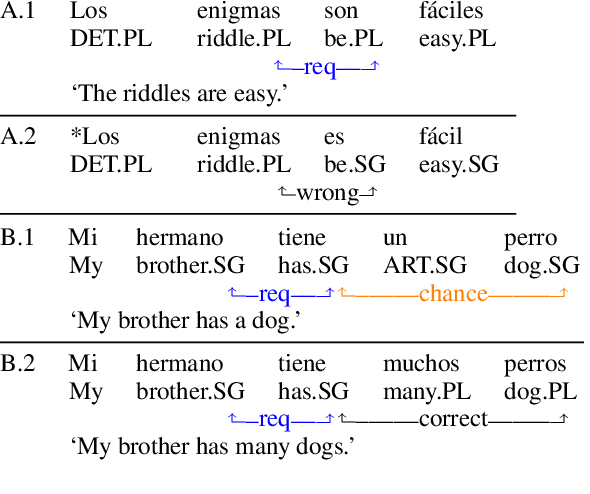
Creating a descriptive grammar of a language is an indispensable step for language documentation and preservation. However, at the same time it is a tedious, time-consuming task. In this paper, we take steps towards automating this process by devising an automated framework for extracting a first-pass grammatical specification from raw text in a concise, human- and machine-readable format. We focus on extracting rules describing agreement, a morphosyntactic phenomenon at the core of the grammars of many of the world's languages. We apply our framework to all languages included in the Universal Dependencies project, with promising results. Using cross-lingual transfer, even with no expert annotations in the language of interest, our framework extracts a grammatical specification which is nearly equivalent to those created with large amounts of gold-standard annotated data. We confirm this finding with human expert evaluations of the rules that our framework produces, which have an average accuracy of 78%. We release an interface demonstrating the extracted rules at https://neulab.github.io/lase/.
Improving Target-side Lexical Transfer in Multilingual Neural Machine Translation
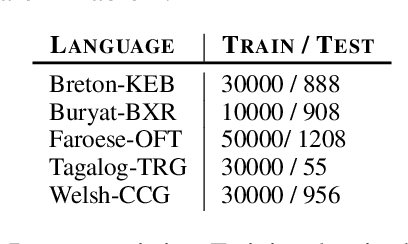
Oct 04, 2020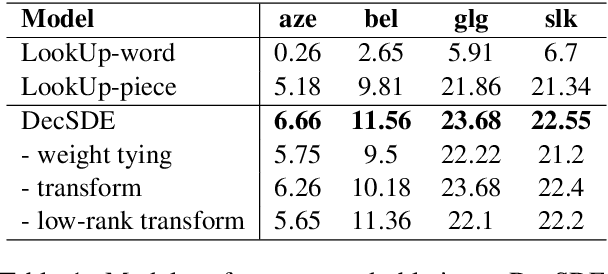
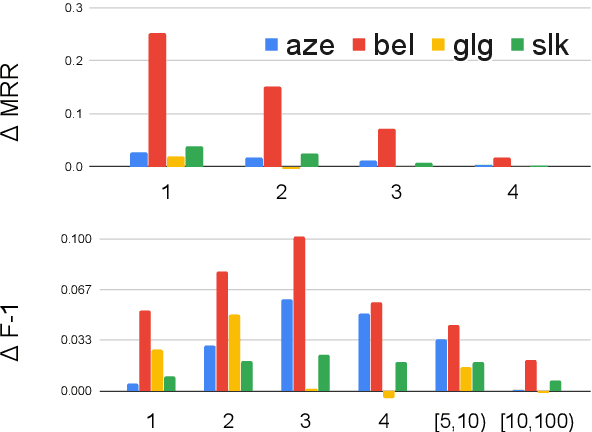
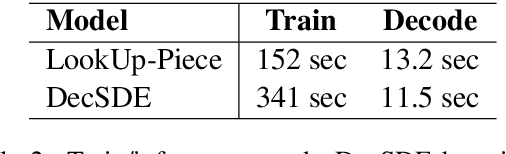
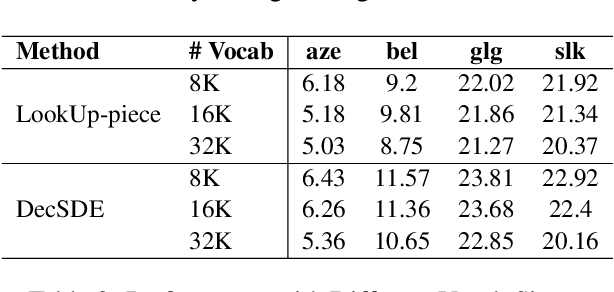
To improve the performance of Neural Machine Translation~(NMT) for low-resource languages~(LRL), one effective strategy is to leverage parallel data from a related high-resource language~(HRL). However, multilingual data has been found more beneficial for NMT models that translate from the LRL to a target language than the ones that translate into the LRLs. In this paper, we aim to improve the effectiveness of multilingual transfer for NMT models that translate \emph{into} the LRL, by designing a better decoder word embedding. Extending upon a general-purpose multilingual encoding method Soft Decoupled Encoding~\citep{SDE}, we propose DecSDE, an efficient character n-gram based embedding specifically designed for the NMT decoder. Our experiments show that DecSDE leads to consistent gains of up to 1.8 BLEU on translation from English to four different languages.
The Return of Lexical Dependencies: Neural Lexicalized PCFGs
Jul 29, 2020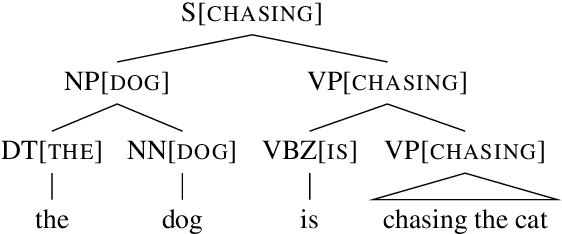

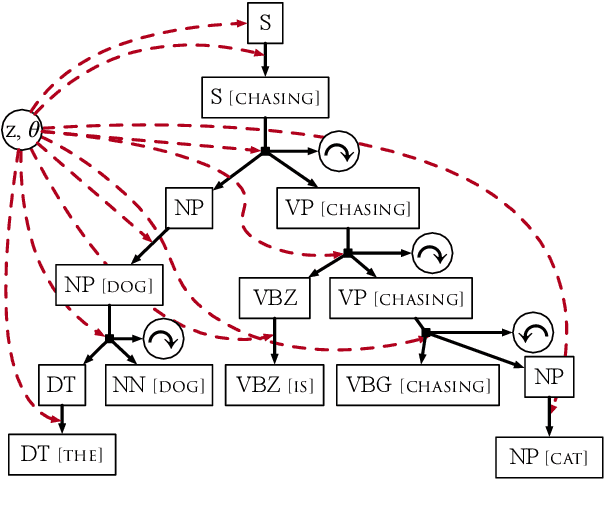
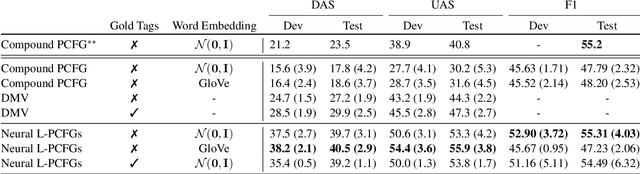
In this paper we demonstrate that $\textit{context free grammar (CFG) based methods for grammar induction benefit from modeling lexical dependencies}$. This contrasts to the most popular current methods for grammar induction, which focus on discovering $\textit{either}$ constituents $\textit{or}$ dependencies. Previous approaches to marry these two disparate syntactic formalisms (e.g. lexicalized PCFGs) have been plagued by sparsity, making them unsuitable for unsupervised grammar induction. However, in this work, we present novel neural models of lexicalized PCFGs which allow us to overcome sparsity problems and effectively induce both constituents and dependencies within a single model. Experiments demonstrate that this unified framework results in stronger results on both representations than achieved when modeling either formalism alone. Code is available at https://github.com/neulab/neural-lpcfg.