 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARTScore: Evaluating Generated Text as Text Generation
Jun 22, 2021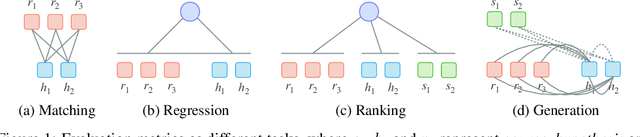

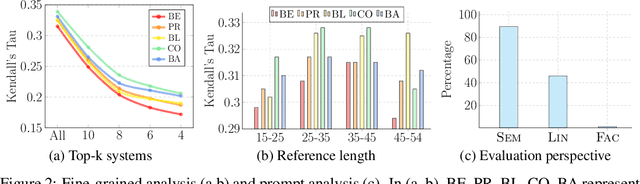
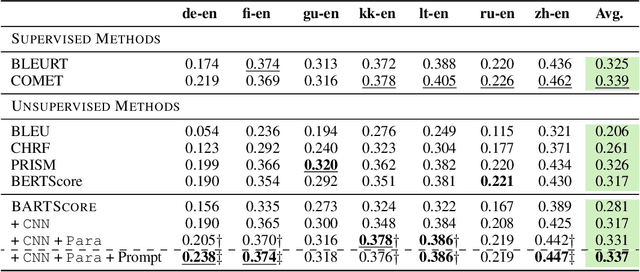
A wide variety of NLP applications, such as machine translation, summarization, and dialog, involve text generation. One major challenge for these applications is how to evaluate whether such generated texts are actually fluent, accurate, or effective. In this work, we conceptualize the evaluation of generated text as a text generation problem, modeled using pre-trained sequence-to-sequence models. The general idea is that models trained to convert the generated text to/from a reference output or the source text will achieve higher scores when the generated text is better. We operationalize this idea using BART, an encoder-decoder based pre-trained model, and propose a metric BARTScore with a number of variants that can be flexibly applied in an unsupervised fashion to evaluation of text from different perspectives (e.g. informativeness, fluency, or factuality). BARTScore is conceptually simple and empirically effective. It can outperform existing top-scoring metrics in 16 of 22 test settings, covering evaluation of 16 datasets (e.g., machine translation, text summarization) and 7 different perspectives (e.g., informativeness, factuality). Code to calculate BARTScore is available at https://github.com/neulab/BARTScore, and we have released an interactive leaderboard for meta-evaluation at http://explainaboard.nlpedia.ai/leaderboard/task-meval/ on the ExplainaBoard platform, which allows us to interactively understand the strengths, weaknesses, and complementarity of each metric.
Phrase-level Active Learning for Neural Machine Translation
Jun 21, 2021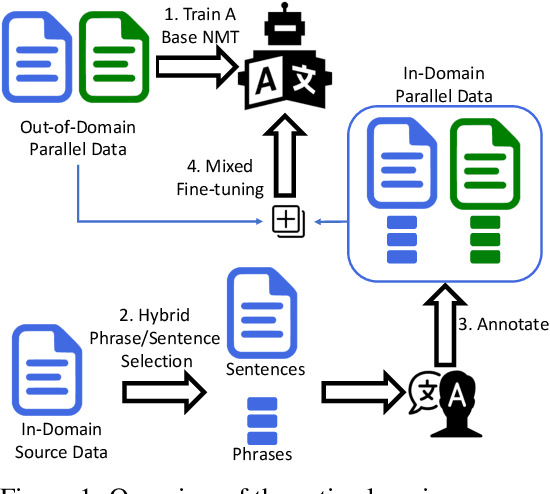
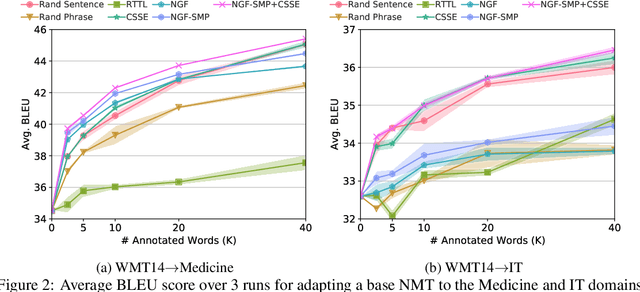

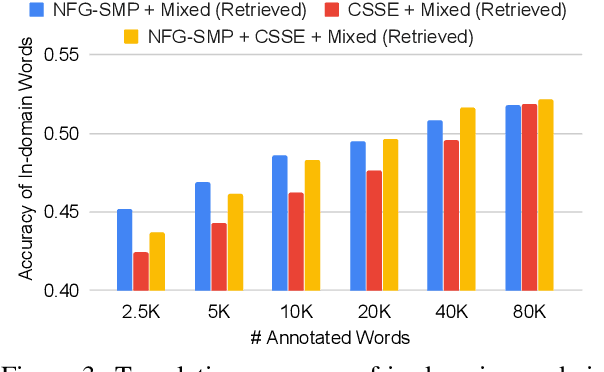
Neural machine translation (NMT) is sensitive to domain shift. In this paper, we address this problem in an active learning setting where we can spend a given budget on translating in-domain data, and gradually fine-tune a pre-trained out-of-domain NMT model on the newly translated data. Existing active learning methods for NMT usually select sentences based on uncertainty scores, but these methods require costly translation of full sentences even when only one or two key phrases within the sentence are informative. To address this limitation, we re-examine previous work from the phrase-based machine translation (PBMT) era that selected not full sentences, but rather individual phrases. However, while incorporating these phrases into PBMT systems was relatively simple, it is less trivial for NMT systems, which need to be trained on full sequences to capture larger structural properties of sentences unique to the new domain. To overcome these hurdles, we propose to select both full sentences and individual phrases from unlabelled data in the new domain for routing to human translators. In a German-English translation task, our active learning approach achieves consistent improvements over uncertainty-based sentence selection methods, improving up to 1.2 BLEU score over strong active learning baselines.
Examining and Combating Spurious Features under Distribution Shift
Jun 14, 2021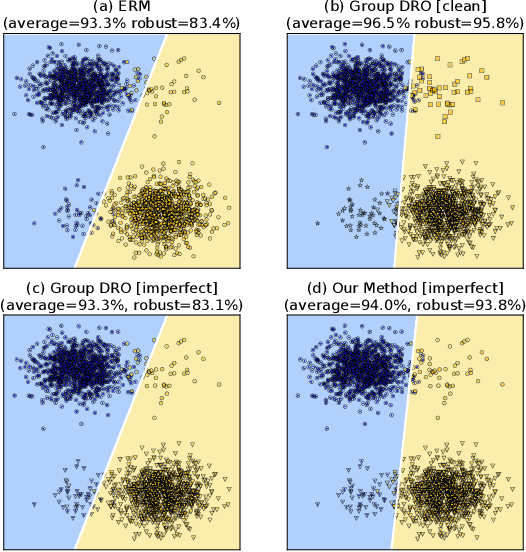

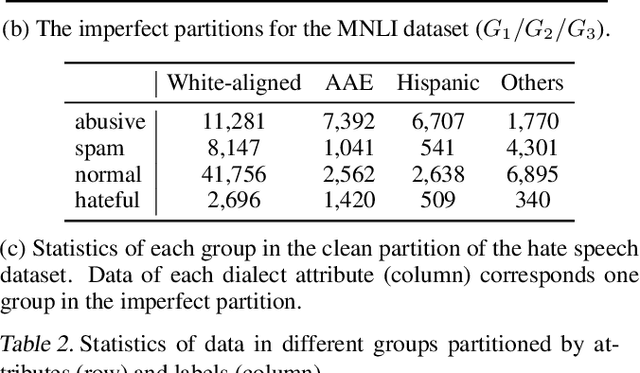
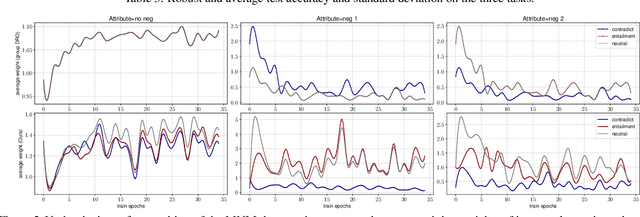
A central goal of machine learning is to learn robust representations that capture the causal relationship between inputs features and output labels. However, minimizing empirical risk over finite or biased datasets often results in models latching on to spurious correlations between the training input/output pairs that are not fundamental to the problem at hand. In this paper, we define and analyze robust and spurious representations using the information-theoretic concept of minimal sufficient statistics. We prove that even when there is only bias of the input distribution (i.e. covariate shift), models can still pick up spurious features from their training data. Group distributionally robust optimization (DRO) provides an effective tool to alleviate covariate shift by minimizing the worst-case training loss over a set of pre-defined groups. Inspired by our analysis, we demonstrate that group DRO can fail when groups do not directly account for various spurious correlations that occur in the data. To address this, we further propose to minimize the worst-case losses over a more flexible set of distributions that are defined on the joint distribution of groups and instances, instead of treating each group as a whole at optimization time. Through extensive experiments on one image and two language tasks, we show that our model is significantly more robust than comparable baselines under various partitions. Our code is available at https://github.com/violet-zct/group-conditional-DRO.
CitationIE: Leveraging the Citation Graph for Scientific Information Extraction
Jun 03, 2021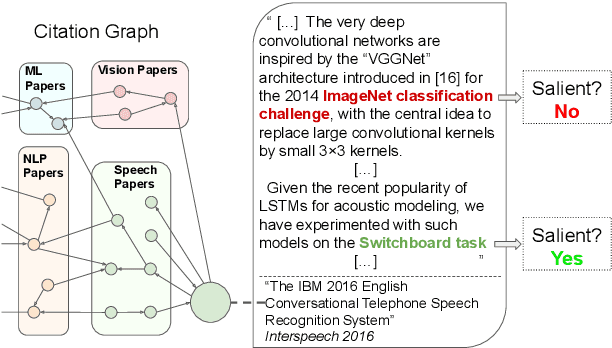
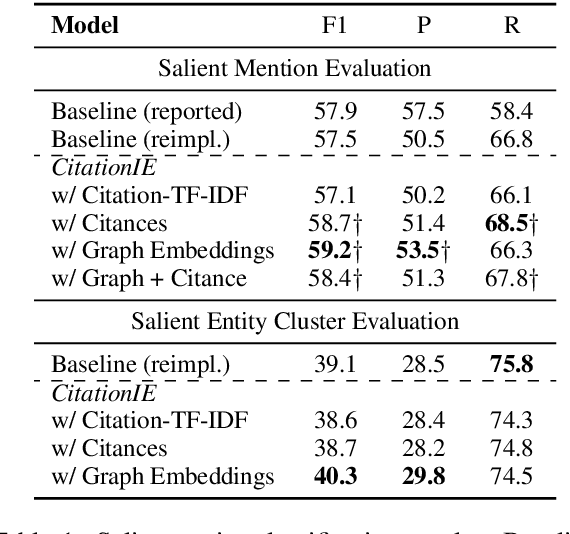
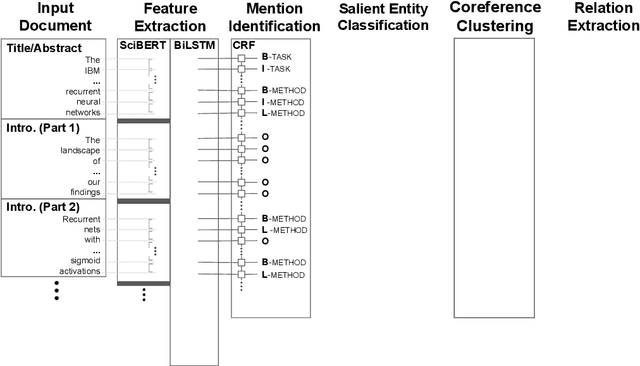
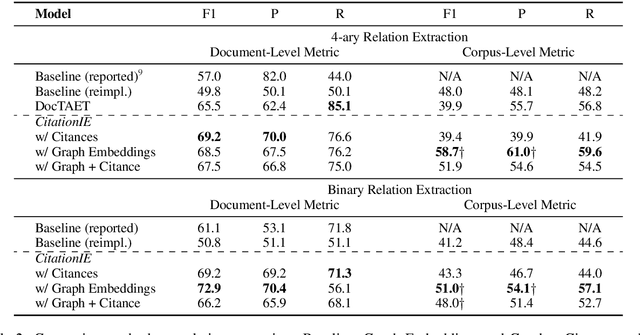
Automatically extracting key information from scientific documents has the potential to help scientists work more efficiently and accelerate the pace of scientific progress. Prior work has considered extracting document-level entity clusters and relations end-to-end from raw scientific text, which can improve literature search and help identify methods and materials for a given problem. Despite the importance of this task, most existing works on scientific information extraction (SciIE) consider extraction solely based on the content of an individual paper, without considering the paper's place in the broader literature. In contrast to prior work, we augment our text representations by leveraging a complementary source of document context: the citation graph of referential links between citing and cited papers. On a test set of English-language scientific documents, we show that simple ways of utilizing the structure and content of the citation graph can each lead to significant gains in different scientific information extraction tasks. When these tasks are combined, we observe a sizable improvement in end-to-end information extraction over the state-of-the-art, suggesting the potential for future work along this direction. We release software tools to facilitate citation-aware SciIE development.
Measuring and Increasing Context Usage in Context-Aware Machine Translation
Jun 02, 2021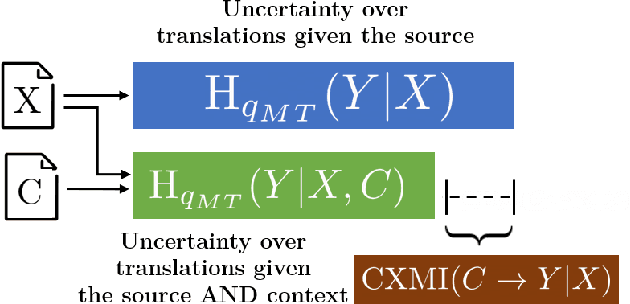

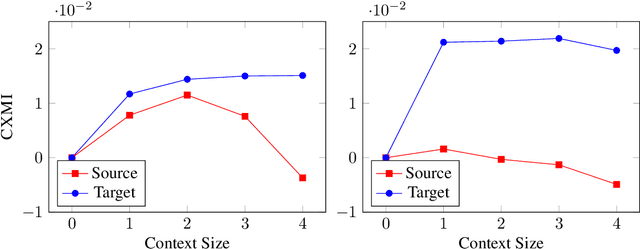
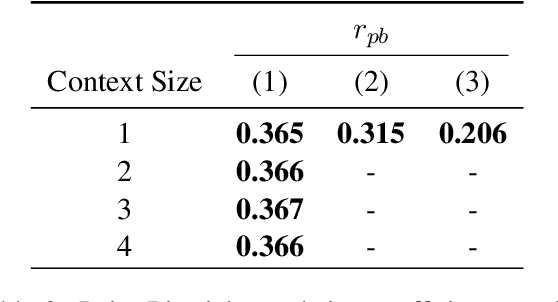
Recent work in neural machine translation has demonstrated both the necessity and feasibility of using inter-sentential context -- context from sentences other than those currently being translated. However, while many current methods present model architectures that theoretically can use this extra context, it is often not clear how much they do actually utilize it at translation time. In this paper, we introduce a new metric, conditional cross-mutual information, to quantify the usage of context by these models. Using this metric, we measure how much document-level machine translation systems use particular varieties of context. We find that target context is referenced more than source context, and that conditioning on a longer context has a diminishing effect on results. We then introduce a new, simple training method, context-aware word dropout, to increase the usage of context by context-aware models. Experiments show that our method increases context usage and that this reflects on the translation quality according to metrics such as BLEU and COMET, as well as performance on anaphoric pronoun resolution and lexical cohesion contrastive datasets.
Do Context-Aware Translation Models Pay the Right Attention?
May 21, 2021

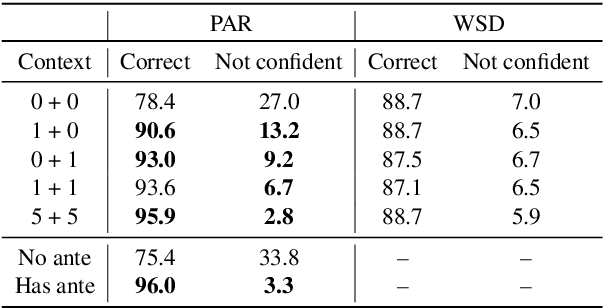
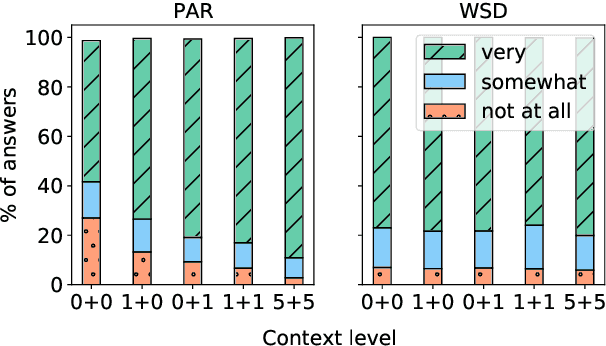
Context-aware machine translation models are designed to leverage contextual information, but often fail to do so. As a result, they inaccurately disambiguate pronouns and polysemous words that require context for resolution. In this paper, we ask several questions: What contexts do human translators use to resolve ambiguous words? Are models paying large amounts of attention to the same context? What if we explicitly train them to do so? To answer these questions, we introduce SCAT (Supporting Context for Ambiguous Translations), a new English-French dataset comprising supporting context words for 14K translations that professional translators found useful for pronoun disambiguation. Using SCAT, we perform an in-depth analysis of the context used to disambiguate, examining positional and lexical characteristics of the supporting words. Furthermore, we measure the degree of alignment between the model's attention scores and the supporting context from SCAT, and apply a guided attention strategy to encourage agreement between the two.
Data Augmentation for Sign Language Gloss Translation
May 16, 2021

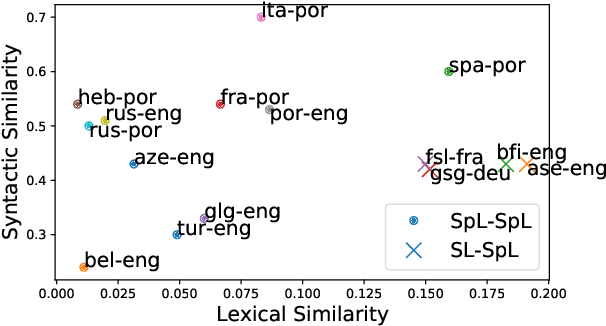
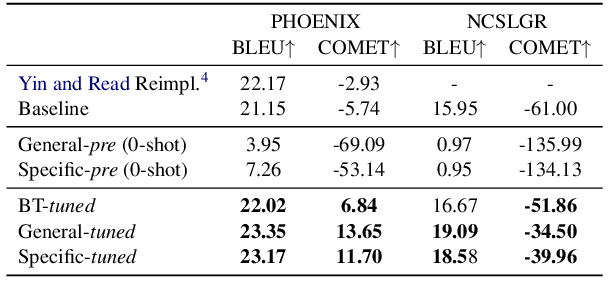
Sign language translation (SLT) is often decomposed into video-to-gloss recognition and gloss-to-text translation, where a gloss is a sequence of transcribed spoken-language words in the order in which they are signed. We focus here on gloss-to-text translation, which we treat as a low-resource neural machine translation (NMT) problem. However, unlike traditional low-resource NMT, gloss-to-text translation differs because gloss-text pairs often have a higher lexical overlap and lower syntactic overlap than pairs of spoken languages. We exploit this lexical overlap and handle syntactic divergence by proposing two rule-based heuristics that generate pseudo-parallel gloss-text pairs from monolingual spoken language text. By pre-training on the thus obtained synthetic data, we improve translation from American Sign Language (ASL) to English and German Sign Language (DGS) to German by up to 3.14 and 2.20 BLEU, respectively.
Paraphrastic Representations at Scale
Apr 30, 2021


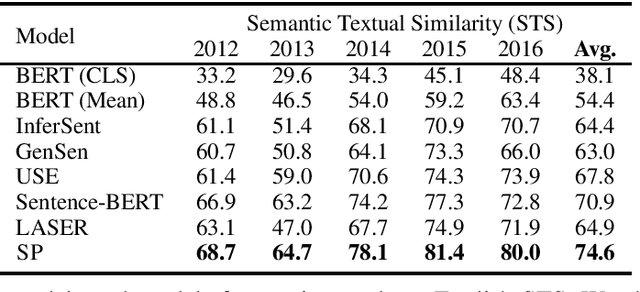
We present a system that allows users to train their own state-of-the-art paraphrastic sentence representations in a variety of languages. We also release trained models for English, Arabic, German, French, Spanish, Russian, Turkish, and Chinese. We train these models on large amounts of data, achieving significantly improved performance from the original papers proposing the methods on a suite of monolingual semantic similarity, cross-lingual semantic similarity, and bitext mining tasks. Moreover, the resulting models surpass all prior work on unsupervised semantic textual similarity, significantly outperforming even BERT-based models like Sentence-BERT (Reimers and Gurevych, 2019). Additionally, our models are orders of magnitude faster than prior work and can be used on CPU with little difference in inference speed (even improved speed over GPU when using more CPU cores), making these models an attractive choice for users without access to GPUs or for use on embedded devices. Finally, we add significantly increased functionality to the code bases for training paraphrastic sentence models, easing their use for both inference and for training them for any desired language with parallel data. We also include code to automatically download and preprocess training data.
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
Apr 18, 2021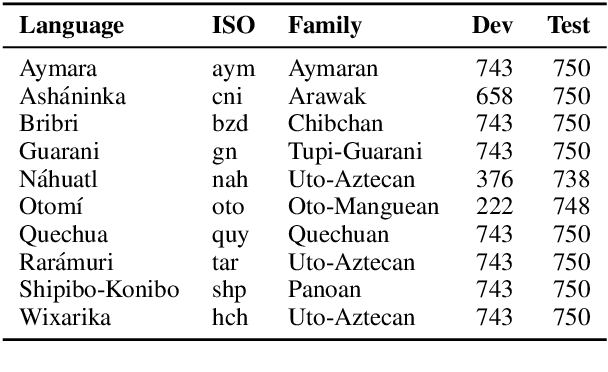
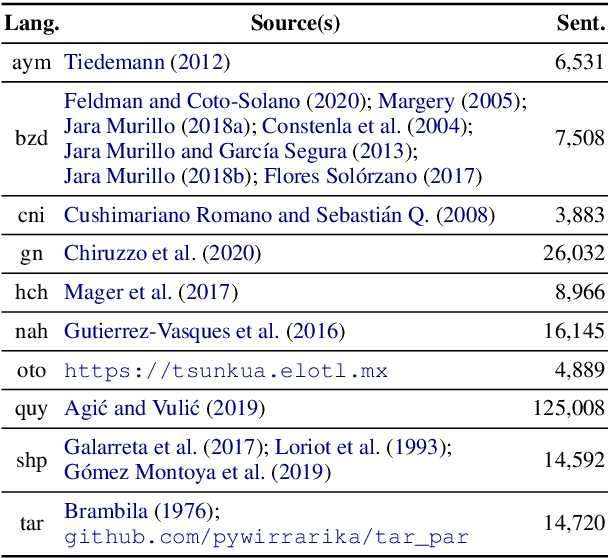
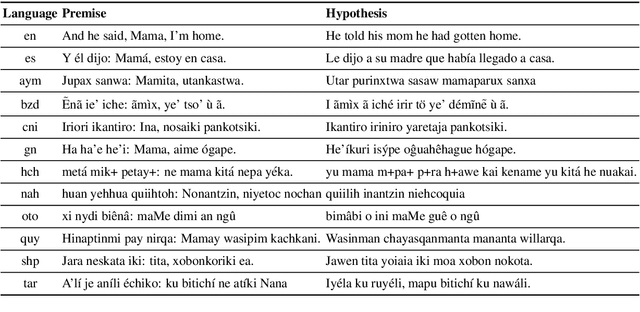

Pretrained multilingual models are able to perform cross-lingual transfer in a zero-shot setting, even for languages unseen during pretraining. However, prior work evaluating performance on unseen languages has largely been limited to low-level, syntactic tasks, and it remains unclear if zero-shot learning of high-level, semantic tasks is possible for unseen languages. To explore this question, we present AmericasNLI, an extension of XNLI (Conneau et al., 2018) to 10 indigenous languages of the Americas. We conduct experiments with XLM-R, testing multiple zero-shot and translation-based approaches. Additionally, we explore model adaptation via continued pretraining and provide an analysis of the dataset by considering hypothesis-only models. We find that XLM-R's zero-shot performance is poor for all 10 languages, with an average performance of 38.62%. Continued pretraining offers improvements, with an average accuracy of 44.05%. Surprisingly, training on poorly translated data by far outperforms all other methods with an accuracy of 48.72%.
MetaXL: Meta Representation Transformation for Low-resource Cross-lingual Learning
Apr 16, 2021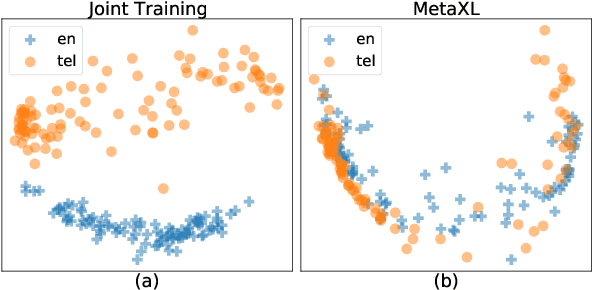
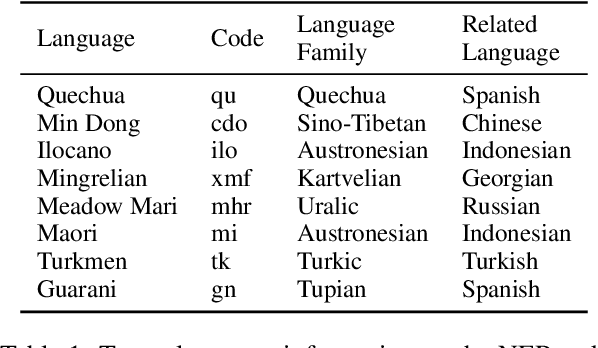
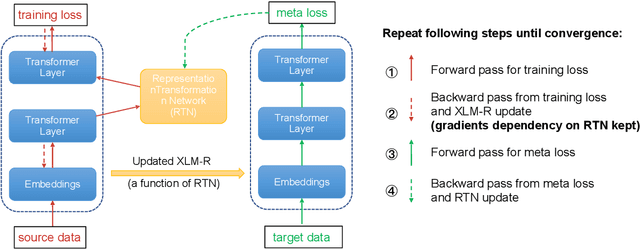
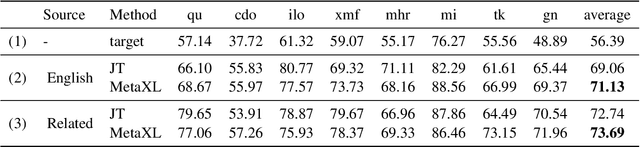
The combination of multilingual pre-trained representations and cross-lingual transfer learning is one of the most effective methods for building functional NLP systems for low-resource languages. However, for extremely low-resource languages without large-scale monolingual corpora for pre-training or sufficient annotated data for fine-tuning, transfer learning remains an under-studied and challenging task. Moreover, recent work shows that multilingual representations are surprisingly disjoint across languages, bringing additional challenges for transfer onto extremely low-resource languages. In this paper, we propose MetaXL, a meta-learning based framework that learns to transform representations judiciously from auxiliary languages to a target one and brings their representation spaces closer for effective transfer. Extensive experiments on real-world low-resource languages - without access to large-scale monolingual corpora or large amounts of labeled data - for tasks like cross-lingual sentiment analysis and named entity recognition show the effectiveness of our approach. Code for MetaXL is publicly available at github.com/microsoft/MetaXL.