 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTPA-Net: Generate A Dataset for Text to Physics-based Animation
Nov 25, 2022Recent breakthroughs in Vision-Language (V&L) joint research have achieved remarkable results in various text-driven tasks. High-quality Text-to-video (T2V), a task that has been long considered mission-impossible, was proven feasible with reasonably good results in latest works. However, the resulting videos often have undesired artifacts largely because the system is purely data-driven and agnostic to the physical laws. To tackle this issue and further push T2V towards high-level physical realism, we present an autonomous data generation technique and a dataset, which intend to narrow the gap with a large number of multi-modal, 3D Text-to-Video/Simulation (T2V/S) data. In the dataset, we provide high-resolution 3D physical simulations for both solids and fluids, along with textual descriptions of the physical phenomena. We take advantage of state-of-the-art physical simulation methods (i) Incremental Potential Contact (IPC) and (ii) Material Point Method (MPM) to simulate diverse scenarios, including elastic deformations, material fractures, collisions, turbulence, etc. Additionally, high-quality, multi-view rendering videos are supplied for the benefit of T2V, Neural Radiance Fields (NeRF), and other communities. This work is the first step towards fully automated Text-to-Video/Simulation (T2V/S). Live examples and subsequent work are at https://sites.google.com/view/tpa-net.
Towards Reasoning-Aware Explainable VQA
Nov 09, 2022The domain of joint vision-language understanding, especially in the context of reasoning in Visual Question Answering (VQA) models, has garnered significant attention in the recent past. While most of the existing VQA models focus on improving the accuracy of VQA, the way models arrive at an answer is oftentimes a black box. As a step towards making the VQA task more explainable and interpretable, our method is built upon the SOTA VQA framework by augmenting it with an end-to-end explanation generation module. In this paper, we investigate two network architectures, including Long Short-Term Memory (LSTM) and Transformer decoder, as the explanation generator. Our method generates human-readable textual explanations while maintaining SOTA VQA accuracy on the GQA-REX (77.49%) and VQA-E (71.48%) datasets. Approximately 65.16% of the generated explanations are approved by humans as valid. Roughly 60.5% of the generated explanations are valid and lead to the correct answers.
CH-MARL: A Multimodal Benchmark for Cooperative, Heterogeneous Multi-Agent Reinforcement Learning
Aug 26, 2022
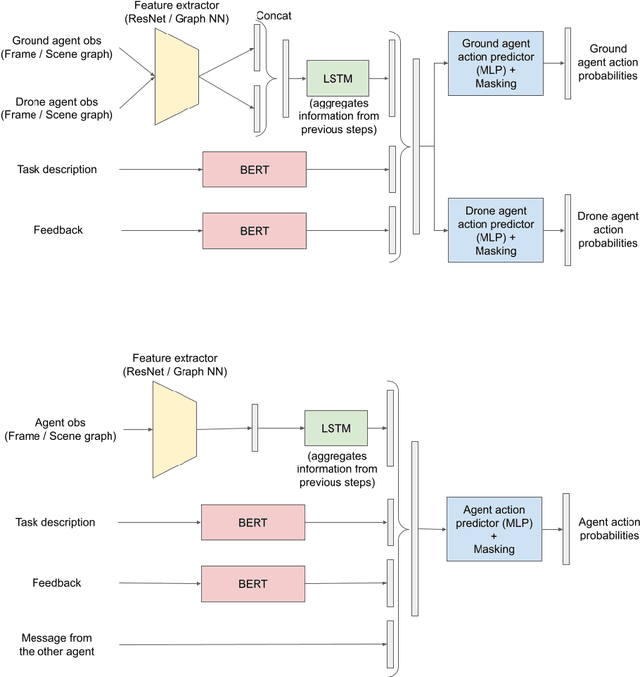


We propose a multimodal (vision-and-language) benchmark for cooperative and heterogeneous multi-agent learning. We introduce a benchmark multimodal dataset with tasks involving collaboration between multiple simulated heterogeneous robots in a rich multi-room home environment. We provide an integrated learning framework, multimodal implementations of state-of-the-art multi-agent reinforcement learning techniques, and a consistent evaluation protocol. Our experiments investigate the impact of different modalities on multi-agent learning performance. We also introduce a simple message passing method between agents. The results suggest that multimodality introduces unique challenges for cooperative multi-agent learning and there is significant room for advancing multi-agent reinforcement learning methods in such settings.
A Multi-level Alignment Training Scheme for Video-and-Language Grounding
Apr 26, 2022



To solve video-and-language grounding tasks, the key is for the network to understand the connection between the two modalities. For a pair of video and language description, their semantic relation is reflected by their encodings' similarity. A good multi-modality encoder should be able to well capture both inputs' semantics and encode them in the shared feature space where embedding distance gets properly translated into their semantic similarity. In this work, we focused on this semantic connection between video and language, and developed a multi-level alignment training scheme to directly shape the encoding process. Global and segment levels of video-language alignment pairs were designed, based on the information similarity ranging from high-level context to fine-grained semantics. The contrastive loss was used to contrast the encodings' similarities between the positive and negative alignment pairs, and to ensure the network is trained in such a way that similar information is encoded closely in the shared feature space while information of different semantics is kept apart. Our multi-level alignment training can be applied to various video-and-language grounding tasks. Together with the task-specific training loss, our framework achieved comparable performance to previous state-of-the-arts on multiple video QA and retrieval datasets.
DialFRED: Dialogue-Enabled Agents for Embodied Instruction Following
Feb 27, 2022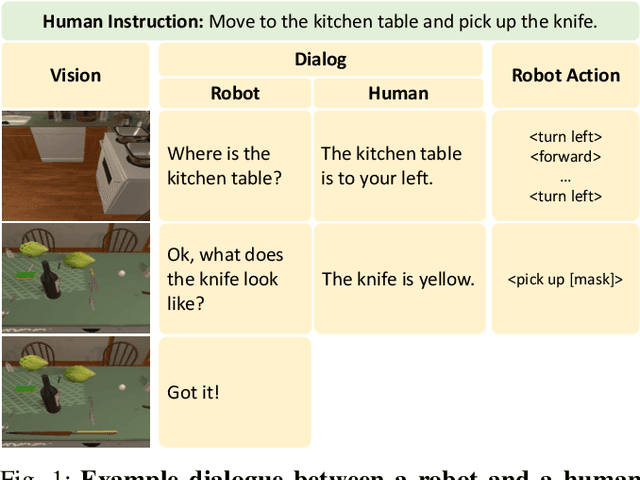


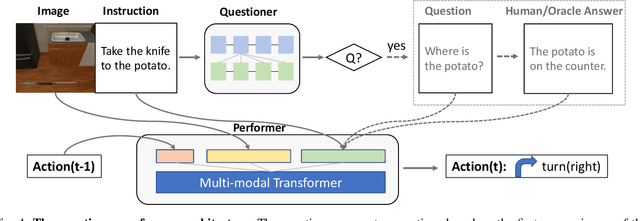
Language-guided Embodied AI benchmarks requiring an agent to navigate an environment and manipulate objects typically allow one-way communication: the human user gives a natural language command to the agent, and the agent can only follow the command passively. We present DialFRED, a dialogue-enabled embodied instruction following benchmark based on the ALFRED benchmark. DialFRED allows an agent to actively ask questions to the human user; the additional information in the user's response is used by the agent to better complete its task. We release a human-annotated dataset with 53K task-relevant questions and answers and an oracle to answer questions. To solve DialFRED, we propose a questioner-performer framework wherein the questioner is pre-trained with the human-annotated data and fine-tuned with reinforcement learning. We make DialFRED publicly available and encourage researchers to propose and evaluate their solutions to building dialog-enabled embodied agents.
Privacy Preserving Visual Question Answering
Feb 15, 2022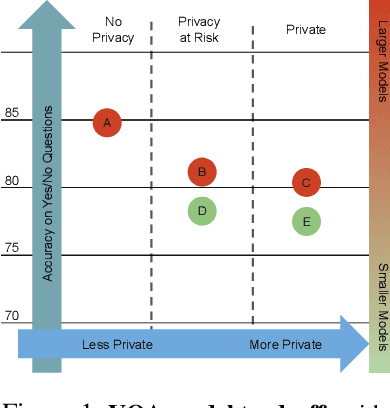

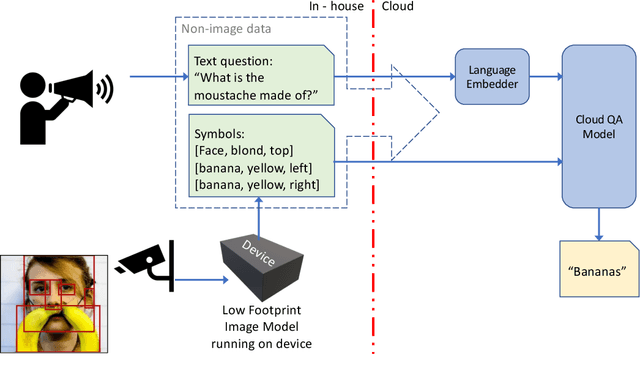

We introduce a novel privacy-preserving methodology for performing Visual Question Answering on the edge. Our method constructs a symbolic representation of the visual scene, using a low-complexity computer vision model that jointly predicts classes, attributes and predicates. This symbolic representation is non-differentiable, which means it cannot be used to recover the original image, thereby keeping the original image private. Our proposed hybrid solution uses a vision model which is more than 25 times smaller than the current state-of-the-art (SOTA) vision models, and 100 times smaller than end-to-end SOTA VQA models. We report detailed error analysis and discuss the trade-offs of using a distilled vision model and a symbolic representation of the visual scene.
Learning to Act with Affordance-Aware Multimodal Neural SLAM
Feb 04, 2022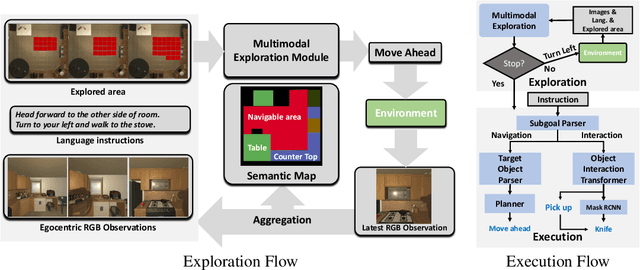

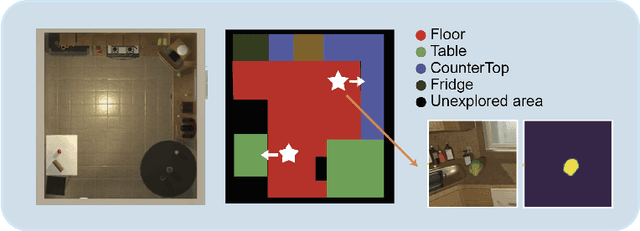
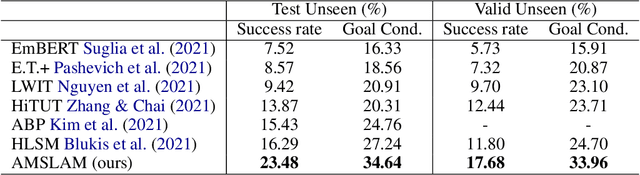
Recent years have witnessed an emerging paradigm shift toward embodied artificial intelligence, in which an agent must learn to solve challenging tasks by interacting with its environment. There are several challenges in solving embodied multimodal tasks, including long-horizon planning, vision-and-language grounding, and efficient exploration. We focus on a critical bottleneck, namely the performance of planning and navigation. To tackle this challenge, we propose a Neural SLAM approach that, for the first time, utilizes several modalities for exploration, predicts an affordance-aware semantic map, and plans over it at the same time. This significantly improves exploration efficiency, leads to robust long-horizon planning, and enables effective vision-and-language grounding. With the proposed Affordance-aware Multimodal Neural SLAM (AMSLAM) approach, we obtain more than $40\%$ improvement over prior published work on the ALFRED benchmark and set a new state-of-the-art generalization performance at a success rate of $23.48\%$ on the test unseen scenes.
Learning Two-Step Hybrid Policy for Graph-Based Interpretable Reinforcement Learning
Jan 21, 2022
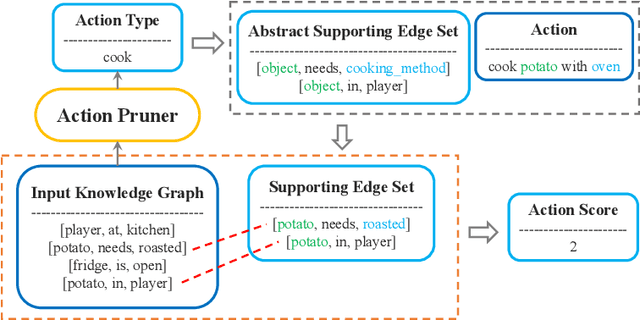
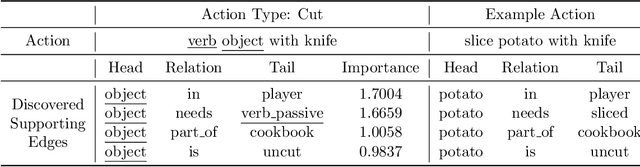
We present a two-step hybrid reinforcement learning (RL) policy that is designed to generate interpretable and robust hierarchical policies on the RL problem with graph-based input. Unlike prior deep reinforcement learning policies parameterized by an end-to-end black-box graph neural network, our approach disentangles the decision-making process into two steps. The first step is a simplified classification problem that maps the graph input to an action group where all actions share a similar semantic meaning. The second step implements a sophisticated rule-miner that conducts explicit one-hop reasoning over the graph and identifies decisive edges in the graph input without the necessity of heavy domain knowledge. This two-step hybrid policy presents human-friendly interpretations and achieves better performance in terms of generalization and robustness. Extensive experimental studies on four levels of complex text-based games have demonstrated the superiority of the proposed method compared to the state-of-the-art.
A Thousand Words Are Worth More Than a Picture: Natural Language-Centric Outside-Knowledge Visual Question Answering
Jan 14, 2022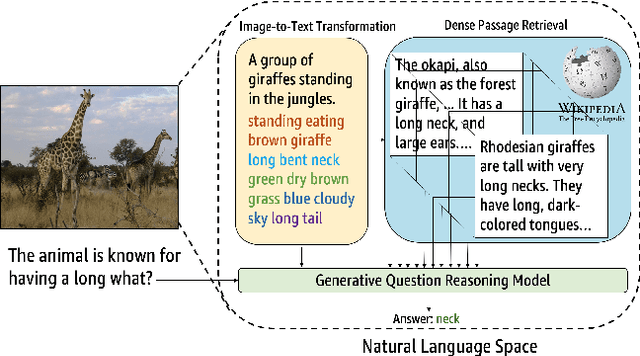
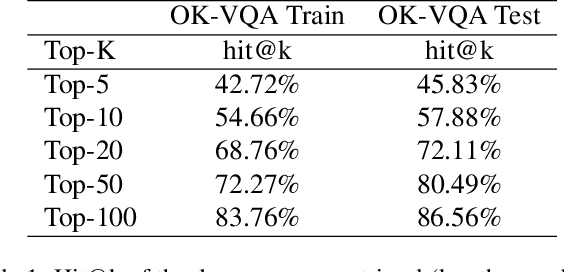
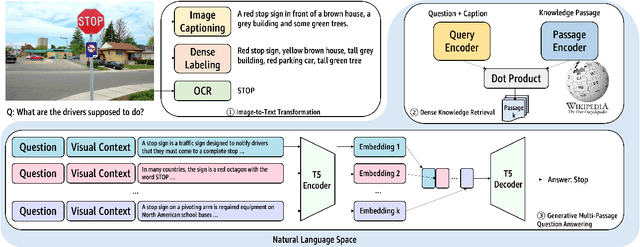
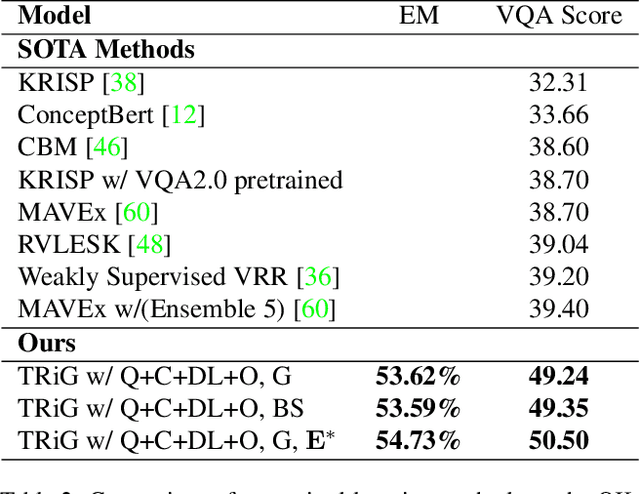
Outside-knowledge visual question answering (OK-VQA) requires the agent to comprehend the image, make use of relevant knowledge from the entire web, and digest all the information to answer the question. Most previous works address the problem by first fusing the image and question in the multi-modal space, which is inflexible for further fusion with a vast amount of external knowledge. In this paper, we call for a paradigm shift for the OK-VQA task, which transforms the image into plain text, so that we can enable knowledge passage retrieval, and generative question-answering in the natural language space. This paradigm takes advantage of the sheer volume of gigantic knowledge bases and the richness of pre-trained language models. A Transform-Retrieve-Generate framework (TRiG) framework is proposed, which can be plug-and-played with alternative image-to-text models and textual knowledge bases. Experimental results show that our TRiG framework outperforms all state-of-the-art supervised methods by at least 11.1% absolute margin.
Best of Both Worlds: A Hybrid Approach for Multi-Hop Explanation with Declarative Facts
Dec 17, 2021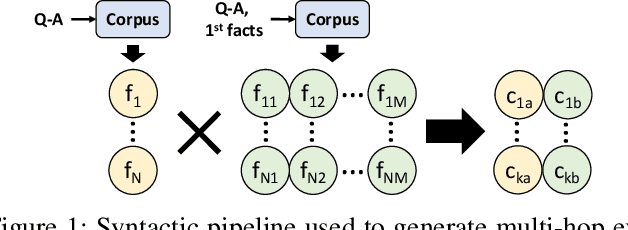
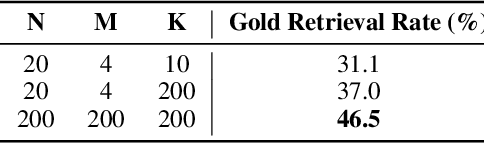
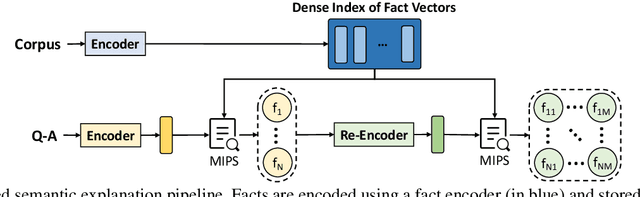
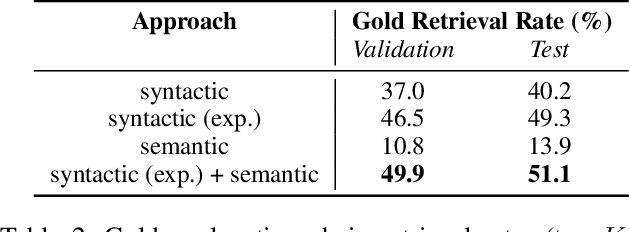
Language-enabled AI systems can answer complex, multi-hop questions to high accuracy, but supporting answers with evidence is a more challenging task which is important for the transparency and trustworthiness to users. Prior work in this area typically makes a trade-off between efficiency and accuracy; state-of-the-art deep neural network systems are too cumbersome to be useful in large-scale applications, while the fastest systems lack reliability. In this work, we integrate fast syntactic methods with powerful semantic methods for multi-hop explanation generation based on declarative facts. Our best system, which learns a lightweight operation to simulate multi-hop reasoning over pieces of evidence and fine-tunes language models to re-rank generated explanation chains, outperforms a purely syntactic baseline from prior work by up to 7% in gold explanation retrieval rate.