 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGained in Translation: Privileged Pairwise Judges Enhance Multilingual Reasoning
Jan 26, 2026When asked a question in a language less seen in its training data, current reasoning large language models (RLMs) often exhibit dramatically lower performance than when asked the same question in English. In response, we introduce \texttt{SP3F} (Self-Play with Privileged Pairwise Feedback), a two-stage framework for enhancing multilingual reasoning without \textit{any} data in the target language(s). First, we supervise fine-tune (SFT) on translated versions of English question-answer pairs to raise base model correctness. Second, we perform RL with feedback from a pairwise judge in a self-play fashion, with the judge receiving the English reference response as \textit{privileged information}. Thus, even when none of the model's responses are completely correct, the privileged pairwise judge can still tell which response is better. End-to-end, \texttt{SP3F} greatly improves base model performance, even outperforming fully post-trained models on multiple math and non-math tasks with less than of the training data across the single-language, multilingual, and generalization to unseen language settings.
A Smooth Sea Never Made a Skilled $\texttt{SAILOR}$: Robust Imitation via Learning to Search
Jun 05, 2025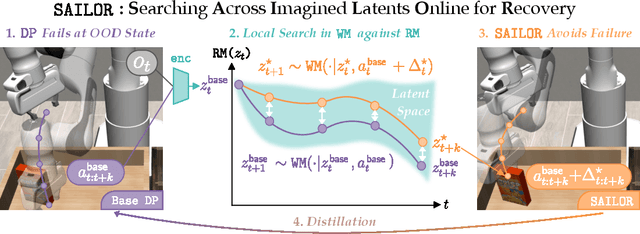
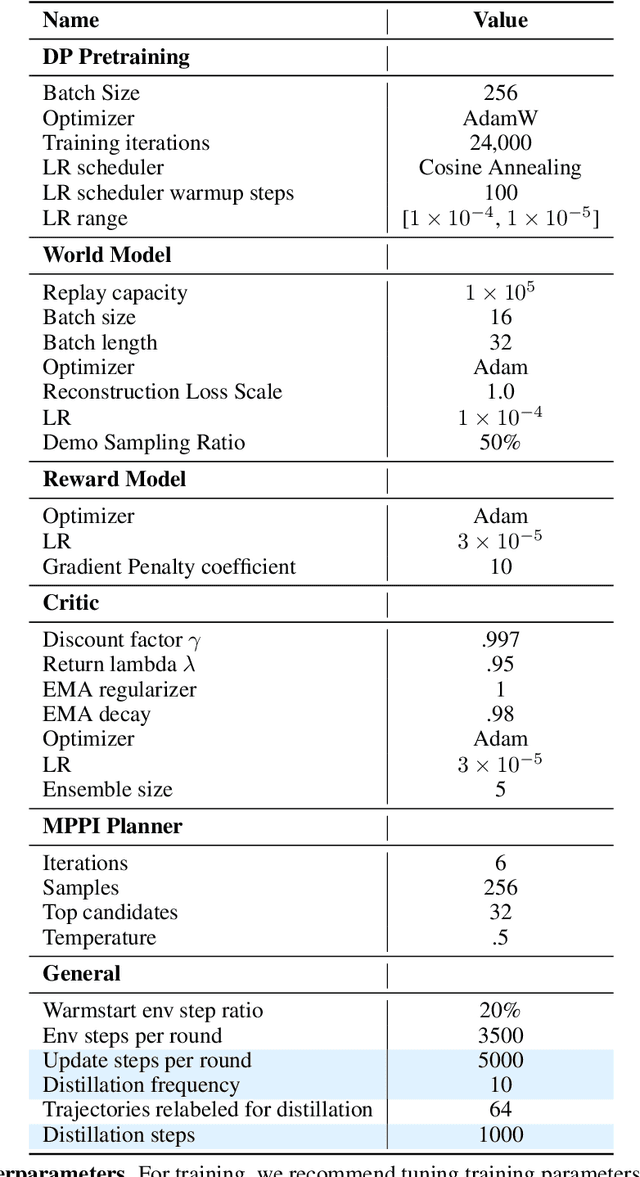
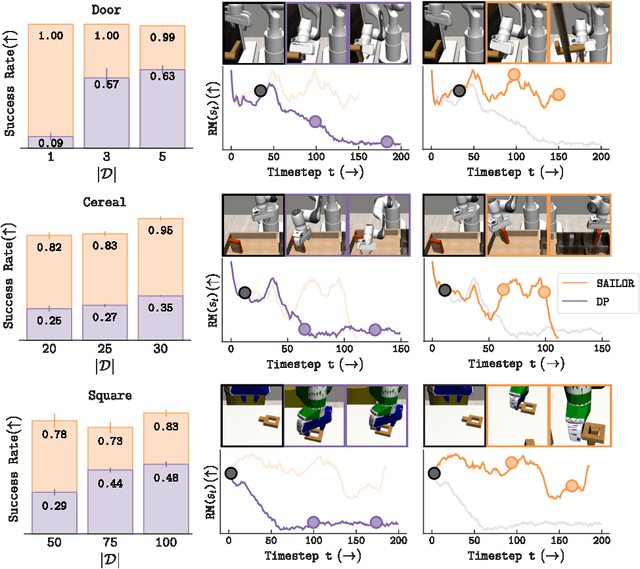
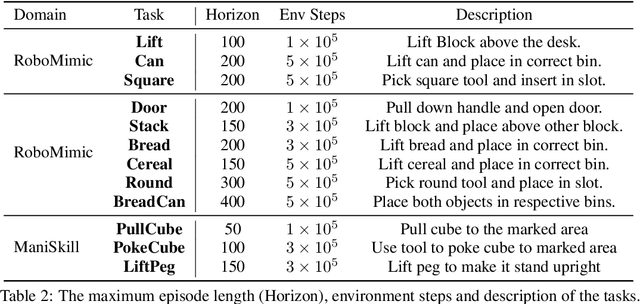
The fundamental limitation of the behavioral cloning (BC) approach to imitation learning is that it only teaches an agent what the expert did at states the expert visited. This means that when a BC agent makes a mistake which takes them out of the support of the demonstrations, they often don't know how to recover from it. In this sense, BC is akin to giving the agent the fish -- giving them dense supervision across a narrow set of states -- rather than teaching them to fish: to be able to reason independently about achieving the expert's outcome even when faced with unseen situations at test-time. In response, we explore learning to search (L2S) from expert demonstrations, i.e. learning the components required to, at test time, plan to match expert outcomes, even after making a mistake. These include (1) a world model and (2) a reward model. We carefully ablate the set of algorithmic and design decisions required to combine these and other components for stable and sample/interaction-efficient learning of recovery behavior without additional human corrections. Across a dozen visual manipulation tasks from three benchmarks, our approach $\texttt{SAILOR}$ consistently out-performs state-of-the-art Diffusion Policies trained via BC on the same data. Furthermore, scaling up the amount of demonstrations used for BC by 5-10$\times$ still leaves a performance gap. We find that $\texttt{SAILOR}$ can identify nuanced failures and is robust to reward hacking. Our code is available at https://github.com/arnavkj1995/SAILOR .
Scaling Offline RL via Efficient and Expressive Shortcut Models
May 28, 2025



Diffusion and flow models have emerged as powerful generative approaches capable of modeling diverse and multimodal behavior. However, applying these models to offline reinforcement learning (RL) remains challenging due to the iterative nature of their noise sampling processes, making policy optimization difficult. In this paper, we introduce Scalable Offline Reinforcement Learning (SORL), a new offline RL algorithm that leverages shortcut models - a novel class of generative models - to scale both training and inference. SORL's policy can capture complex data distributions and can be trained simply and efficiently in a one-stage training procedure. At test time, SORL introduces both sequential and parallel inference scaling by using the learned Q-function as a verifier. We demonstrate that SORL achieves strong performance across a range of offline RL tasks and exhibits positive scaling behavior with increased test-time compute. We release the code at nico-espinosadice.github.io/projects/sorl.
Efficient Imitation Under Misspecification
Mar 17, 2025



Interactive imitation learning (IL) is a powerful paradigm for learning to make sequences of decisions from an expert demonstrating how to perform a task. Prior work in efficient imitation learning has focused on the realizable setting, where the expert's policy lies within the learner's policy class (i.e. the learner can perfectly imitate the expert in all states). However, in practice, perfect imitation of the expert is often impossible due to differences in state information and action space expressiveness (e.g. morphological differences between robots and humans.) In this paper, we consider the more general misspecified setting, where no assumptions are made about the expert policy's realizability. We introduce a novel structural condition, reward-agnostic policy completeness, and prove that it is sufficient for interactive IL algorithms to efficiently avoid the quadratically compounding errors that stymie offline approaches like behavioral cloning. We address an additional practical constraint-the case of limited expert data-and propose a principled method for using additional offline data to further improve the sample-efficiency of interactive IL algorithms. Finally, we empirically investigate the optimal reset distribution in efficient IL under misspecification with a suite of continuous control tasks.
All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning
Mar 03, 2025



From a first-principles perspective, it may seem odd that the strongest results in foundation model fine-tuning (FT) are achieved via a relatively complex, two-stage training procedure. Specifically, one first trains a reward model (RM) on some dataset (e.g. human preferences) before using it to provide online feedback as part of a downstream reinforcement learning (RL) procedure, rather than directly optimizing the policy parameters on the dataset via offline maximum likelihood estimation. In fact, from an information-theoretic perspective, we can only lose information via passing through a reward model and cannot create any new information via on-policy sampling. To explain this discrepancy, we scrutinize several hypotheses on the value of RL in FT through both theoretical and empirical lenses. Of the hypotheses considered, we find the most support for the explanation that on problems with a generation-verification gap, the combination of the ease of learning the relatively simple RM (verifier) from the preference data, coupled with the ability of the downstream RL procedure to then filter its search space to the subset of policies (generators) that are optimal for relatively simple verifiers is what leads to the superior performance of online FT.
From Foresight to Forethought: VLM-In-the-Loop Policy Steering via Latent Alignment
Feb 03, 2025



While generative robot policies have demonstrated significant potential in learning complex, multimodal behaviors from demonstrations, they still exhibit diverse failures at deployment-time. Policy steering offers an elegant solution to reducing the chance of failure by using an external verifier to select from low-level actions proposed by an imperfect generative policy. Here, one might hope to use a Vision Language Model (VLM) as a verifier, leveraging its open-world reasoning capabilities. However, off-the-shelf VLMs struggle to understand the consequences of low-level robot actions as they are represented fundamentally differently than the text and images the VLM was trained on. In response, we propose FOREWARN, a novel framework to unlock the potential of VLMs as open-vocabulary verifiers for runtime policy steering. Our key idea is to decouple the VLM's burden of predicting action outcomes (foresight) from evaluation (forethought). For foresight, we leverage a latent world model to imagine future latent states given diverse low-level action plans. For forethought, we align the VLM with these predicted latent states to reason about the consequences of actions in its native representation--natural language--and effectively filter proposed plans. We validate our framework across diverse robotic manipulation tasks, demonstrating its ability to bridge representational gaps and provide robust, generalizable policy steering.
Your Learned Constraint is Secretly a Backward Reachable Tube
Jan 26, 2025Inverse Constraint Learning (ICL) is the problem of inferring constraints from safe (i.e., constraint-satisfying) demonstrations. The hope is that these inferred constraints can then be used downstream to search for safe policies for new tasks and, potentially, under different dynamics. Our paper explores the question of what mathematical entity ICL recovers. Somewhat surprisingly, we show that both in theory and in practice, ICL recovers the set of states where failure is inevitable, rather than the set of states where failure has already happened. In the language of safe control, this means we recover a backwards reachable tube (BRT) rather than a failure set. In contrast to the failure set, the BRT depends on the dynamics of the data collection system. We discuss the implications of the dynamics-conditionedness of the recovered constraint on both the sample-efficiency of policy search and the transferability of learned constraints.
Diffusing States and Matching Scores: A New Framework for Imitation Learning
Oct 17, 2024Adversarial Imitation Learning is traditionally framed as a two-player zero-sum game between a learner and an adversarially chosen cost function, and can therefore be thought of as the sequential generalization of a Generative Adversarial Network (GAN). A prominent example of this framework is Generative Adversarial Imitation Learning (GAIL). However, in recent years, diffusion models have emerged as a non-adversarial alternative to GANs that merely require training a score function via regression, yet produce generations of a higher quality. In response, we investigate how to lift insights from diffusion modeling to the sequential setting. We propose diffusing states and performing score-matching along diffused states to measure the discrepancy between the expert's and learner's states. Thus, our approach only requires training score functions to predict noises via standard regression, making it significantly easier and more stable to train than adversarial methods. Theoretically, we prove first- and second-order instance-dependent bounds with linear scaling in the horizon, proving that our approach avoids the compounding errors that stymie offline approaches to imitation learning. Empirically, we show our approach outperforms GAN-style imitation learning baselines across various continuous control problems, including complex tasks like controlling humanoids to walk, sit, and crawl.
Regressing the Relative Future: Efficient Policy Optimization for Multi-turn RLHF
Oct 06, 2024



Large Language Models (LLMs) have achieved remarkable success at tasks like summarization that involve a single turn of interaction. However, they can still struggle with multi-turn tasks like dialogue that require long-term planning. Previous works on multi-turn dialogue extend single-turn reinforcement learning from human feedback (RLHF) methods to the multi-turn setting by treating all prior dialogue turns as a long context. Such approaches suffer from covariate shift: the conversations in the training set have previous turns generated by some reference policy, which means that low training error may not necessarily correspond to good performance when the learner is actually in the conversation loop. In response, we introduce REgressing the RELative FUture (REFUEL), an efficient policy optimization approach designed to address multi-turn RLHF in LLMs. REFUEL employs a single model to estimate $Q$-values and trains on self-generated data, addressing the covariate shift issue. REFUEL frames the multi-turn RLHF problem as a sequence of regression tasks on iteratively collected datasets, enabling ease of implementation. Theoretically, we prove that REFUEL can match the performance of any policy covered by the training set. Empirically, we evaluate our algorithm by using Llama-3.1-70B-it to simulate a user in conversation with our model. REFUEL consistently outperforms state-of-the-art methods such as DPO and REBEL across various settings. Furthermore, despite having only 8 billion parameters, Llama-3-8B-it fine-tuned with REFUEL outperforms Llama-3.1-70B-it on long multi-turn dialogues. Implementation of REFUEL can be found at https://github.com/ZhaolinGao/REFUEL/, and models trained by REFUEL can be found at https://huggingface.co/Cornell-AGI.
EvIL: Evolution Strategies for Generalisable Imitation Learning
Jun 15, 2024



Often times in imitation learning (IL), the environment we collect expert demonstrations in and the environment we want to deploy our learned policy in aren't exactly the same (e.g. demonstrations collected in simulation but deployment in the real world). Compared to policy-centric approaches to IL like behavioural cloning, reward-centric approaches like inverse reinforcement learning (IRL) often better replicate expert behaviour in new environments. This transfer is usually performed by optimising the recovered reward under the dynamics of the target environment. However, (a) we find that modern deep IL algorithms frequently recover rewards which induce policies far weaker than the expert, even in the same environment the demonstrations were collected in. Furthermore, (b) these rewards are often quite poorly shaped, necessitating extensive environment interaction to optimise effectively. We provide simple and scalable fixes to both of these concerns. For (a), we find that reward model ensembles combined with a slightly different training objective significantly improves re-training and transfer performance. For (b), we propose a novel evolution-strategies based method EvIL to optimise for a reward-shaping term that speeds up re-training in the target environment, closing a gap left open by the classical theory of IRL. On a suite of continuous control tasks, we are able to re-train policies in target (and source) environments more interaction-efficiently than prior work.