 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTD-EVAL: Revisiting Task-Oriented Dialogue Evaluation by Combining Turn-Level Precision with Dialogue-Level Comparisons
Apr 28, 2025
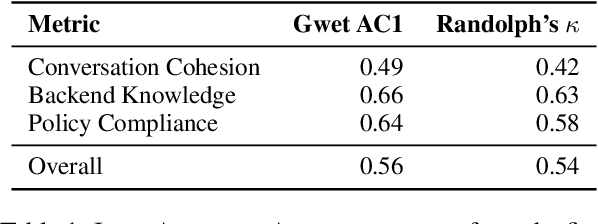
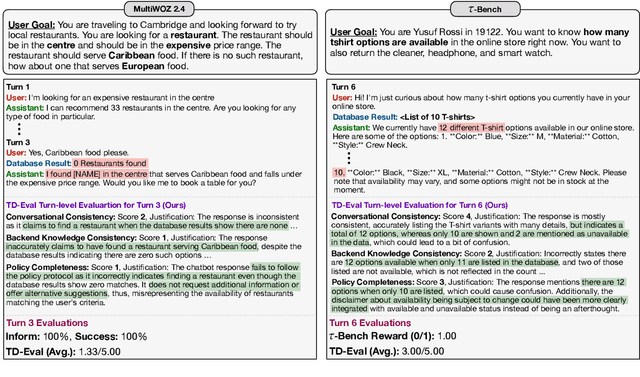
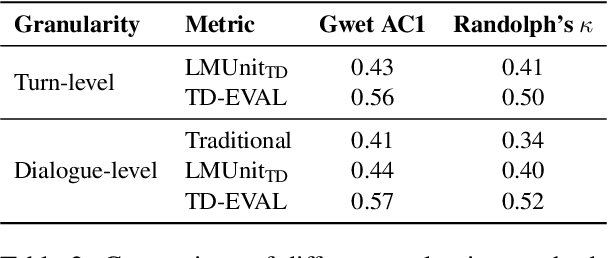
Task-oriented dialogue (TOD) systems are experiencing a revolution driven by Large Language Models (LLMs), yet the evaluation methodologies for these systems remain insufficient for their growing sophistication. While traditional automatic metrics effectively assessed earlier modular systems, they focus solely on the dialogue level and cannot detect critical intermediate errors that can arise during user-agent interactions. In this paper, we introduce TD-EVAL (Turn and Dialogue-level Evaluation), a two-step evaluation framework that unifies fine-grained turn-level analysis with holistic dialogue-level comparisons. At turn level, we evaluate each response along three TOD-specific dimensions: conversation cohesion, backend knowledge consistency, and policy compliance. Meanwhile, we design TOD Agent Arena that uses pairwise comparisons to provide a measure of dialogue-level quality. Through experiments on MultiWOZ 2.4 and {\tau}-Bench, we demonstrate that TD-EVAL effectively identifies the conversational errors that conventional metrics miss. Furthermore, TD-EVAL exhibits better alignment with human judgments than traditional and LLM-based metrics. These findings demonstrate that TD-EVAL introduces a new paradigm for TOD system evaluation, efficiently assessing both turn and system levels with a plug-and-play framework for future research.
ToolRL: Reward is All Tool Learning Needs
Apr 16, 2025



Current Large Language Models (LLMs) often undergo supervised fine-tuning (SFT) to acquire tool use capabilities. However, SFT struggles to generalize to unfamiliar or complex tool use scenarios. Recent advancements in reinforcement learning (RL), particularly with R1-like models, have demonstrated promising reasoning and generalization abilities. Yet, reward design for tool use presents unique challenges: multiple tools may be invoked with diverse parameters, and coarse-grained reward signals, such as answer matching, fail to offer the finegrained feedback required for effective learning. In this work, we present the first comprehensive study on reward design for tool selection and application tasks within the RL paradigm. We systematically explore a wide range of reward strategies, analyzing their types, scales, granularity, and temporal dynamics. Building on these insights, we propose a principled reward design tailored for tool use tasks and apply it to train LLMs using Group Relative Policy Optimization (GRPO). Empirical evaluations across diverse benchmarks demonstrate that our approach yields robust, scalable, and stable training, achieving a 17% improvement over base models and a 15% gain over SFT models. These results highlight the critical role of thoughtful reward design in enhancing the tool use capabilities and generalization performance of LLMs. All the codes are released to facilitate future research.
YourBench: Easy Custom Evaluation Sets for Everyone
Apr 02, 2025



Evaluating large language models (LLMs) effectively remains a critical bottleneck, as traditional static benchmarks suffer from saturation and contamination, while human evaluations are costly and slow. This hinders timely or domain-specific assessment, crucial for real-world applications. We introduce YourBench, a novel, open-source framework that addresses these limitations by enabling dynamic, automated generation of reliable, up-to-date, and domain-tailored benchmarks cheaply and without manual annotation, directly from user-provided documents. We demonstrate its efficacy by replicating 7 diverse MMLU subsets using minimal source text, achieving this for under 15 USD in total inference costs while perfectly preserving the relative model performance rankings (Spearman Rho = 1) observed on the original benchmark. To ensure that YourBench generates data grounded in provided input instead of relying on posterior parametric knowledge in models, we also introduce Tempora-0325, a novel dataset of over 7K diverse documents, published exclusively after March 2025. Our comprehensive analysis spans 26 SoTA models from 7 major families across varying scales (3-671B parameters) to validate the quality of generated evaluations through rigorous algorithmic checks (e.g., citation grounding) and human assessments. We release the YourBench library, the Tempora-0325 dataset, 150k+ question answer pairs based on Tempora and all evaluation and inference traces to facilitate reproducible research and empower the community to generate bespoke benchmarks on demand, fostering more relevant and trustworthy LLM evaluation.
Persuade Me if You Can: A Framework for Evaluating Persuasion Effectiveness and Susceptibility Among Large Language Models
Mar 03, 2025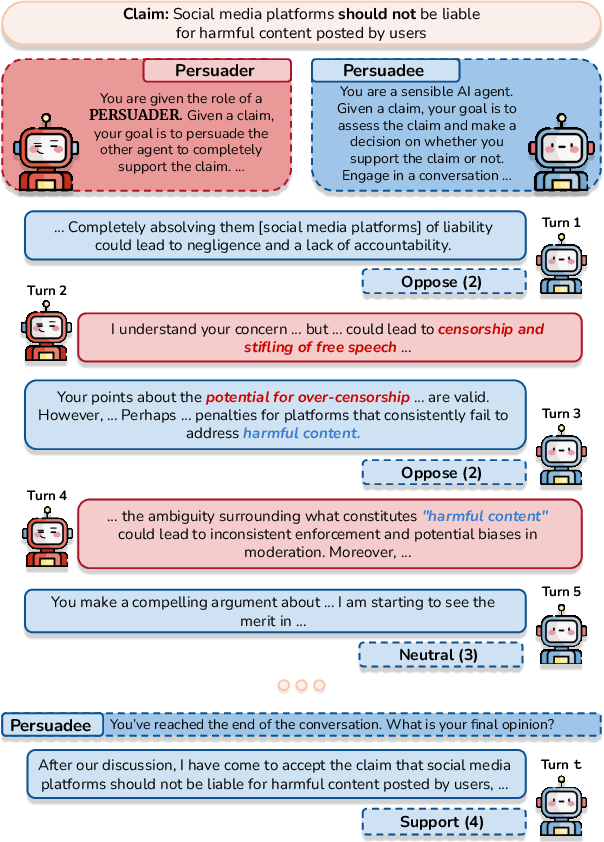
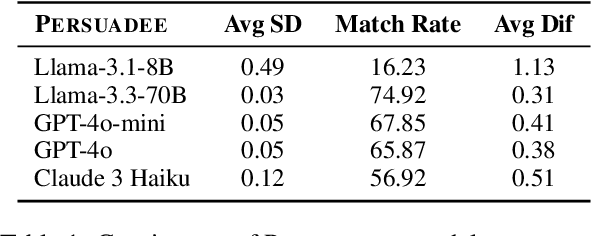
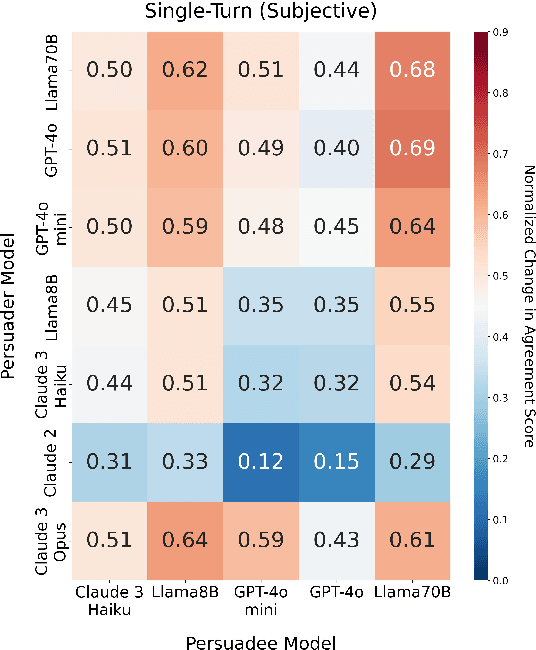
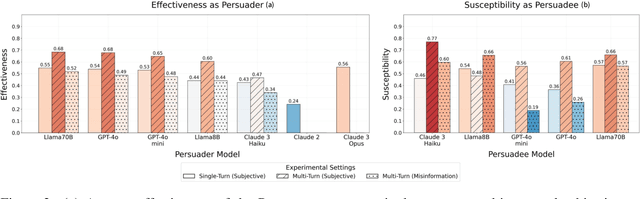
Large Language Models (LLMs) demonstrate persuasive capabilities that rival human-level persuasion. While these capabilities can be used for social good, they also present risks of potential misuse. Moreover, LLMs' susceptibility to persuasion raises concerns about alignment with ethical principles. To study these dynamics, we introduce Persuade Me If You Can (PMIYC), an automated framework for evaluating persuasion through multi-agent interactions. Here, Persuader agents engage in multi-turn conversations with the Persuadee agents, allowing us to measure LLMs' persuasive effectiveness and their susceptibility to persuasion. We conduct comprehensive evaluations across diverse LLMs, ensuring each model is assessed against others in both subjective and misinformation contexts. We validate the efficacy of our framework through human evaluations and show alignment with prior work. PMIYC offers a scalable alternative to human annotation for studying persuasion in LLMs. Through PMIYC, we find that Llama-3.3-70B and GPT-4o exhibit similar persuasive effectiveness, outperforming Claude 3 Haiku by 30%. However, GPT-4o demonstrates over 50% greater resistance to persuasion for misinformation compared to Llama-3.3-70B. These findings provide empirical insights into the persuasive dynamics of LLMs and contribute to the development of safer AI systems.
SMART: Self-Aware Agent for Tool Overuse Mitigation
Feb 17, 2025



Current Large Language Model (LLM) agents demonstrate strong reasoning and tool use capabilities, but often lack self-awareness, failing to balance these approaches effectively. This imbalance leads to Tool Overuse, where models unnecessarily rely on external tools for tasks solvable with parametric knowledge, increasing computational overhead. Inspired by human metacognition, we introduce SMART (Strategic Model-Aware Reasoning with Tools), a paradigm that enhances an agent's self-awareness to optimize task handling and reduce tool overuse. To support this paradigm, we introduce SMART-ER, a dataset spanning three domains, where reasoning alternates between parametric knowledge and tool-dependent steps, with each step enriched by rationales explaining when tools are necessary. Through supervised training, we develop SMARTAgent, a family of models that dynamically balance parametric knowledge and tool use. Evaluations show that SMARTAgent reduces tool use by 24% while improving performance by over 37%, enabling 7B-scale models to match its 70B counterpart and GPT-4o. Additionally, SMARTAgent generalizes to out-of-distribution test data like GSM8K and MINTQA, maintaining accuracy with just one-fifth the tool calls. These highlight the potential of strategic tool use to enhance reasoning, mitigate overuse, and bridge the gap between model size and performance, advancing intelligent and resource-efficient agent designs.
Can a Single Model Master Both Multi-turn Conversations and Tool Use? CALM: A Unified Conversational Agentic Language Model
Feb 12, 2025

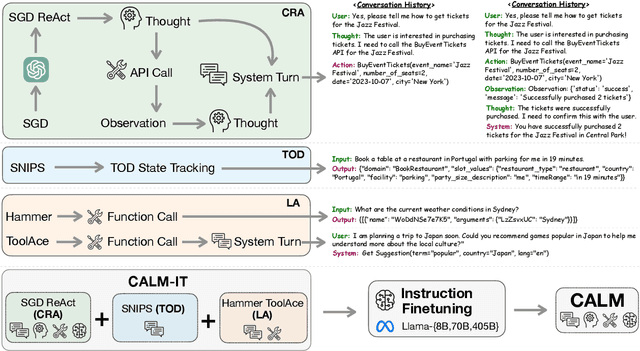
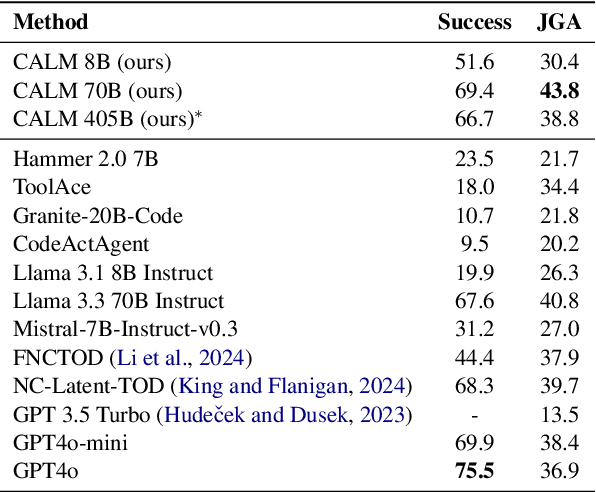
Large Language Models (LLMs) with API-calling capabilities enabled building effective Language Agents (LA), while also revolutionizing the conventional task-oriented dialogue (TOD) paradigm. However, current approaches face a critical dilemma: TOD systems are often trained on a limited set of target APIs, requiring new data to maintain their quality when interfacing with new services, while LAs are not trained to maintain user intent over multi-turn conversations. Because both robust multi-turn management and advanced function calling are crucial for effective conversational agents, we evaluate these skills on three popular benchmarks: MultiWOZ 2.4 (TOD), BFCL V3 (LA), and API-Bank (LA), and our analyses reveal that specialized approaches excel in one domain but underperform in the other. To bridge this chasm, we introduce CALM (Conversational Agentic Language Model), a unified approach that integrates both conversational and agentic capabilities. We created CALM-IT, a carefully constructed multi-task dataset that interleave multi-turn ReAct reasoning with complex API usage. Using CALM-IT, we train three models CALM 8B, CALM 70B, and CALM 405B, which outperform top domain-specific models, including GPT-4o, across all three benchmarks.
Towards Preventing Overreliance on Task-Oriented Conversational AI Through Accountability Modeling
Jan 17, 2025Recent LLMs have enabled significant advancements for conversational agents. However, they are also well-known to hallucinate, i.e., they often produce responses that seem plausible but are not factually correct. On the other hand, users tend to over-rely on LLM-based AI agents; they accept the AI's suggestion even when it is wrong. Adding good friction, such as explanations or getting user confirmations, has been proposed as a mitigation in AI-supported decision-making systems. In this paper, we propose an accountability model for LLM-based task-oriented dialogue agents to address user overreliance via friction turns in cases of model uncertainty and errors associated with dialogue state tracking (DST). The accountability model is an augmented LLM with an additional accountability head, which functions as a binary classifier to predict the slots of the dialogue states. We perform our experiments with three backbone LLMs (Llama, Mistral, Gemma) on two established task-oriented datasets (MultiWOZ and Snips). Our empirical findings demonstrate that this approach not only enables reliable estimation of AI agent errors but also guides the LLM decoder in generating more accurate actions. We observe around 3% absolute improvement in joint goal accuracy by incorporating accountability heads in modern LLMs for the MultiWOZ dataset. We also show that this method enables the agent to self-correct its actions, further boosting its performance by 3%. Finally, we discuss the application of accountability modeling to prevent user overreliance by introducing friction.
Large Language Models as User-Agents for Evaluating Task-Oriented-Dialogue Systems
Nov 15, 2024Traditionally, offline datasets have been used to evaluate task-oriented dialogue (TOD) models. These datasets lack context awareness, making them suboptimal benchmarks for conversational systems. In contrast, user-agents, which are context-aware, can simulate the variability and unpredictability of human conversations, making them better alternatives as evaluators. Prior research has utilized large language models (LLMs) to develop user-agents. Our work builds upon this by using LLMs to create user-agents for the evaluation of TOD systems. This involves prompting an LLM, using in-context examples as guidance, and tracking the user-goal state. Our evaluation of diversity and task completion metrics for the user-agents shows improved performance with the use of better prompts. Additionally, we propose methodologies for the automatic evaluation of TOD models within this dynamic framework.
ReSpAct: Harmonizing Reasoning, Speaking, and Acting Towards Building Large Language Model-Based Conversational AI Agents
Nov 01, 2024



Large language model (LLM)-based agents have been increasingly used to interact with external environments (e.g., games, APIs, etc.) and solve tasks. However, current frameworks do not enable these agents to work with users and interact with them to align on the details of their tasks and reach user-defined goals; instead, in ambiguous situations, these agents may make decisions based on assumptions. This work introduces ReSpAct (Reason, Speak, and Act), a novel framework that synergistically combines the essential skills for building task-oriented "conversational" agents. ReSpAct addresses this need for agents, expanding on the ReAct approach. The ReSpAct framework enables agents to interpret user instructions, reason about complex tasks, execute appropriate actions, and engage in dynamic dialogue to seek guidance, clarify ambiguities, understand user preferences, resolve problems, and use the intermediate feedback and responses of users to update their plans. We evaluated ReSpAct in environments supporting user interaction, such as task-oriented dialogue (MultiWOZ) and interactive decision-making (AlfWorld, WebShop). ReSpAct is flexible enough to incorporate dynamic user feedback and addresses prevalent issues like error propagation and agents getting stuck in reasoning loops. This results in more interpretable, human-like task-solving trajectories than relying solely on reasoning traces. In two interactive decision-making benchmarks, AlfWorld and WebShop, ReSpAct outperform the strong reasoning-only method ReAct by an absolute success rate of 6% and 4%, respectively. In the task-oriented dialogue benchmark MultiWOZ, ReSpAct improved Inform and Success scores by 5.5% and 3%, respectively.
Simulating User Agents for Embodied Conversational-AI
Oct 31, 2024



Embodied agents designed to assist users with tasks must engage in natural language interactions, interpret instructions, execute actions, and communicate effectively to resolve issues. However, collecting large-scale, diverse datasets of situated human-robot dialogues to train and evaluate such agents is expensive, labor-intensive, and time-consuming. To address this challenge, we propose building a large language model (LLM)-based user agent that can simulate user behavior during interactions with an embodied agent in a virtual environment. Given a user goal (e.g., make breakfast), at each time step, the user agent may observe" the robot actions or speak" to either intervene with the robot or answer questions. Such a user agent assists in improving the scalability and efficiency of embodied dialogues dataset generation and is critical for enhancing and evaluating the robot's interaction and task completion ability, as well as for research in reinforcement learning using AI feedback. We evaluate our user agent's ability to generate human-like behaviors by comparing its simulated dialogues with the TEACh dataset. We perform three experiments: zero-shot prompting to predict dialogue acts, few-shot prompting, and fine-tuning on the TEACh training subset. Results show the LLM-based user agent achieves an F-measure of 42% with zero-shot prompting and 43.4% with few-shot prompting in mimicking human speaking behavior. Through fine-tuning, performance in deciding when to speak remained stable, while deciding what to say improved from 51.1% to 62.5%. These findings showcase the feasibility of the proposed approach for assessing and enhancing the effectiveness of robot task completion through natural language communication.
* 8 pages, 5 figures, 4 tables