 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbient Physics: Training Neural PDE Solvers with Partial Observations
Feb 14, 2026In many scientific settings, acquiring complete observations of PDE coefficients and solutions can be expensive, hazardous, or impossible. Recent diffusion-based methods can reconstruct fields given partial observations, but require complete observations for training. We introduce Ambient Physics, a framework for learning the joint distribution of coefficient-solution pairs directly from partial observations, without requiring a single complete observation. The key idea is to randomly mask a subset of already-observed measurements and supervise on them, so the model cannot distinguish "truly unobserved" from "artificially unobserved", and must produce plausible predictions everywhere. Ambient Physics achieves state-of-the-art reconstruction performance. Compared with prior diffusion-based methods, it achieves a 62.51$\%$ reduction in average overall error while using 125$\times$ fewer function evaluations. We also identify a "one-point transition": masking a single already-observed point enables learning from partial observations across architectures and measurement patterns. Ambient Physics thus enables scientific progress in settings where complete observations are unavailable.
Ambient Dataloops: Generative Models for Dataset Refinement
Jan 21, 2026We propose Ambient Dataloops, an iterative framework for refining datasets that makes it easier for diffusion models to learn the underlying data distribution. Modern datasets contain samples of highly varying quality, and training directly on such heterogeneous data often yields suboptimal models. We propose a dataset-model co-evolution process; at each iteration of our method, the dataset becomes progressively higher quality, and the model improves accordingly. To avoid destructive self-consuming loops, at each generation, we treat the synthetically improved samples as noisy, but at a slightly lower noisy level than the previous iteration, and we use Ambient Diffusion techniques for learning under corruption. Empirically, Ambient Dataloops achieve state-of-the-art performance in unconditional and text-conditional image generation and de novo protein design. We further provide a theoretical justification for the proposed framework that captures the benefits of the data looping procedure.
DiffEM: Learning from Corrupted Data with Diffusion Models via Expectation Maximization
Oct 14, 2025Diffusion models have emerged as powerful generative priors for high-dimensional inverse problems, yet learning them when only corrupted or noisy observations are available remains challenging. In this work, we propose a new method for training diffusion models with Expectation-Maximization (EM) from corrupted data. Our proposed method, DiffEM, utilizes conditional diffusion models to reconstruct clean data from observations in the E-step, and then uses the reconstructed data to refine the conditional diffusion model in the M-step. Theoretically, we provide monotonic convergence guarantees for the DiffEM iteration, assuming appropriate statistical conditions. We demonstrate the effectiveness of our approach through experiments on various image reconstruction tasks.
Ambient Diffusion Omni: Training Good Models with Bad Data
Jun 10, 2025We show how to use low-quality, synthetic, and out-of-distribution images to improve the quality of a diffusion model. Typically, diffusion models are trained on curated datasets that emerge from highly filtered data pools from the Web and other sources. We show that there is immense value in the lower-quality images that are often discarded. We present Ambient Diffusion Omni, a simple, principled framework to train diffusion models that can extract signal from all available images during training. Our framework exploits two properties of natural images -- spectral power law decay and locality. We first validate our framework by successfully training diffusion models with images synthetically corrupted by Gaussian blur, JPEG compression, and motion blur. We then use our framework to achieve state-of-the-art ImageNet FID, and we show significant improvements in both image quality and diversity for text-to-image generative modeling. The core insight is that noise dampens the initial skew between the desired high-quality distribution and the mixed distribution we actually observe. We provide rigorous theoretical justification for our approach by analyzing the trade-off between learning from biased data versus limited unbiased data across diffusion times.
Does Generation Require Memorization? Creative Diffusion Models using Ambient Diffusion
Feb 28, 2025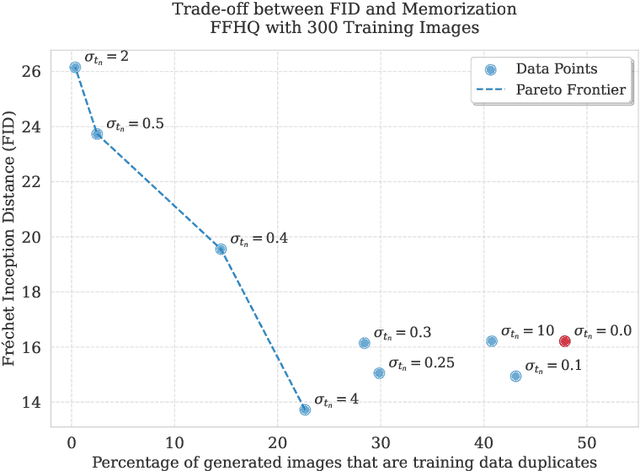
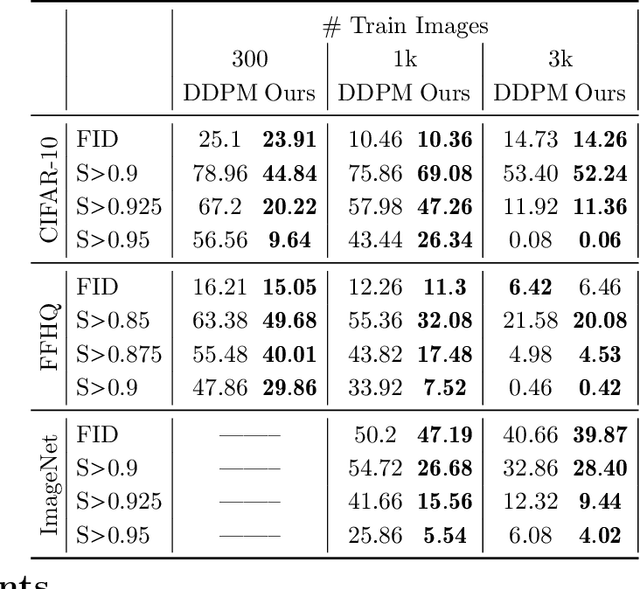

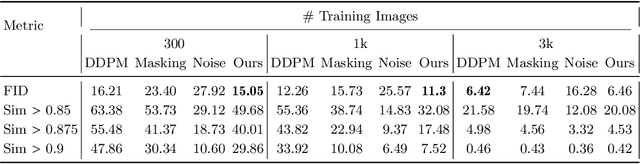
There is strong empirical evidence that the state-of-the-art diffusion modeling paradigm leads to models that memorize the training set, especially when the training set is small. Prior methods to mitigate the memorization problem often lead to a decrease in image quality. Is it possible to obtain strong and creative generative models, i.e., models that achieve high generation quality and low memorization? Despite the current pessimistic landscape of results, we make significant progress in pushing the trade-off between fidelity and memorization. We first provide theoretical evidence that memorization in diffusion models is only necessary for denoising problems at low noise scales (usually used in generating high-frequency details). Using this theoretical insight, we propose a simple, principled method to train the diffusion models using noisy data at large noise scales. We show that our method significantly reduces memorization without decreasing the image quality, for both text-conditional and unconditional models and for a variety of data availability settings.
How much is a noisy image worth? Data Scaling Laws for Ambient Diffusion
Nov 05, 2024



The quality of generative models depends on the quality of the data they are trained on. Creating large-scale, high-quality datasets is often expensive and sometimes impossible, e.g. in certain scientific applications where there is no access to clean data due to physical or instrumentation constraints. Ambient Diffusion and related frameworks train diffusion models with solely corrupted data (which are usually cheaper to acquire) but ambient models significantly underperform models trained on clean data. We study this phenomenon at scale by training more than $80$ models on data with different corruption levels across three datasets ranging from $30,000$ to $\approx 1.3$M samples. We show that it is impossible, at these sample sizes, to match the performance of models trained on clean data when only training on noisy data. Yet, a combination of a small set of clean data (e.g.~$10\%$ of the total dataset) and a large set of highly noisy data suffices to reach the performance of models trained solely on similar-size datasets of clean data, and in particular to achieve near state-of-the-art performance. We provide theoretical evidence for our findings by developing novel sample complexity bounds for learning from Gaussian Mixtures with heterogeneous variances. Our theoretical model suggests that, for large enough datasets, the effective marginal utility of a noisy sample is exponentially worse than that of a clean sample. Providing a small set of clean samples can significantly reduce the sample size requirements for noisy data, as we also observe in our experiments.
Warped Diffusion: Solving Video Inverse Problems with Image Diffusion Models
Oct 21, 2024



Using image models naively for solving inverse video problems often suffers from flickering, texture-sticking, and temporal inconsistency in generated videos. To tackle these problems, in this paper, we view frames as continuous functions in the 2D space, and videos as a sequence of continuous warping transformations between different frames. This perspective allows us to train function space diffusion models only on images and utilize them to solve temporally correlated inverse problems. The function space diffusion models need to be equivariant with respect to the underlying spatial transformations. To ensure temporal consistency, we introduce a simple post-hoc test-time guidance towards (self)-equivariant solutions. Our method allows us to deploy state-of-the-art latent diffusion models such as Stable Diffusion XL to solve video inverse problems. We demonstrate the effectiveness of our method for video inpainting and $8\times$ video super-resolution, outperforming existing techniques based on noise transformations. We provide generated video results: https://giannisdaras.github.io/warped\_diffusion.github.io/.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Ambient Diffusion Posterior Sampling: Solving Inverse Problems with Diffusion Models trained on Corrupted Data
Mar 13, 2024



We provide a framework for solving inverse problems with diffusion models learned from linearly corrupted data. Our method, Ambient Diffusion Posterior Sampling (A-DPS), leverages a generative model pre-trained on one type of corruption (e.g. image inpainting) to perform posterior sampling conditioned on measurements from a potentially different forward process (e.g. image blurring). We test the efficacy of our approach on standard natural image datasets (CelebA, FFHQ, and AFHQ) and we show that A-DPS can sometimes outperform models trained on clean data for several image restoration tasks in both speed and performance. We further extend the Ambient Diffusion framework to train MRI models with access only to Fourier subsampled multi-coil MRI measurements at various acceleration factors (R=2, 4, 6, 8). We again observe that models trained on highly subsampled data are better priors for solving inverse problems in the high acceleration regime than models trained on fully sampled data. We open-source our code and the trained Ambient Diffusion MRI models: https://github.com/utcsilab/ambient-diffusion-mri .
Solving Linear Inverse Problems Provably via Posterior Sampling with Latent Diffusion Models
Jul 02, 2023



We present the first framework to solve linear inverse problems leveraging pre-trained latent diffusion models. Previously proposed algorithms (such as DPS and DDRM) only apply to pixel-space diffusion models. We theoretically analyze our algorithm showing provable sample recovery in a linear model setting. The algorithmic insight obtained from our analysis extends to more general settings often considered in practice. Experimentally, we outperform previously proposed posterior sampling algorithms in a wide variety of problems including random inpainting, block inpainting, denoising, deblurring, destriping, and super-resolution.