 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Geometry of Reinforcement Learning in Continuous State and Action Spaces
Dec 29, 2022



Advances in reinforcement learning have led to its successful application in complex tasks with continuous state and action spaces. Despite these advances in practice, most theoretical work pertains to finite state and action spaces. We propose building a theoretical understanding of continuous state and action spaces by employing a geometric lens. Central to our work is the idea that the transition dynamics induce a low dimensional manifold of reachable states embedded in the high-dimensional nominal state space. We prove that, under certain conditions, the dimensionality of this manifold is at most the dimensionality of the action space plus one. This is the first result of its kind, linking the geometry of the state space to the dimensionality of the action space. We empirically corroborate this upper bound for four MuJoCo environments. We further demonstrate the applicability of our result by learning a policy in this low dimensional representation. To do so we introduce an algorithm that learns a mapping to a low dimensional representation, as a narrow hidden layer of a deep neural network, in tandem with the policy using DDPG. Our experiments show that a policy learnt this way perform on par or better for four MuJoCo control suite tasks.
Effects of Data Geometry in Early Deep Learning
Dec 29, 2022



Deep neural networks can approximate functions on different types of data, from images to graphs, with varied underlying structure. This underlying structure can be viewed as the geometry of the data manifold. By extending recent advances in the theoretical understanding of neural networks, we study how a randomly initialized neural network with piece-wise linear activation splits the data manifold into regions where the neural network behaves as a linear function. We derive bounds on the density of boundary of linear regions and the distance to these boundaries on the data manifold. This leads to insights into the expressivity of randomly initialized deep neural networks on non-Euclidean data sets. We empirically corroborate our theoretical results using a toy supervised learning problem. Our experiments demonstrate that number of linear regions varies across manifolds and the results hold with changing neural network architectures. We further demonstrate how the complexity of linear regions is different on the low dimensional manifold of images as compared to the Euclidean space, using the MetFaces dataset.
Evaluation Beyond Task Performance: Analyzing Concepts in AlphaZero in Hex
Nov 26, 2022AlphaZero, an approach to reinforcement learning that couples neural networks and Monte Carlo tree search (MCTS), has produced state-of-the-art strategies for traditional board games like chess, Go, shogi, and Hex. While researchers and game commentators have suggested that AlphaZero uses concepts that humans consider important, it is unclear how these concepts are captured in the network. We investigate AlphaZero's internal representations in the game of Hex using two evaluation techniques from natural language processing (NLP): model probing and behavioral tests. In doing so, we introduce new evaluation tools to the RL community and illustrate how evaluations other than task performance can be used to provide a more complete picture of a model's strengths and weaknesses. Our analyses in the game of Hex reveal interesting patterns and generate some testable hypotheses about how such models learn in general. For example, we find that MCTS discovers concepts before the neural network learns to encode them. We also find that concepts related to short-term end-game planning are best encoded in the final layers of the model, whereas concepts related to long-term planning are encoded in the middle layers of the model.
Constrained Dynamic Movement Primitives for Safe Learning of Motor Skills
Sep 28, 2022
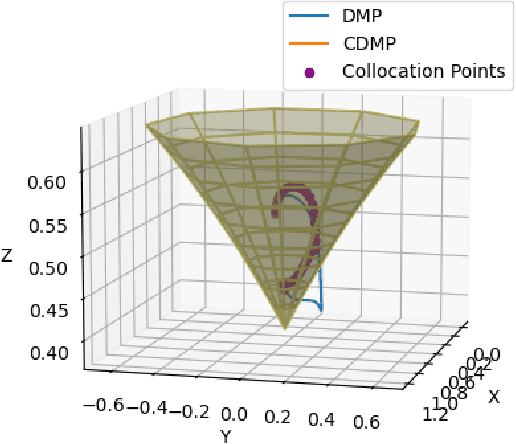
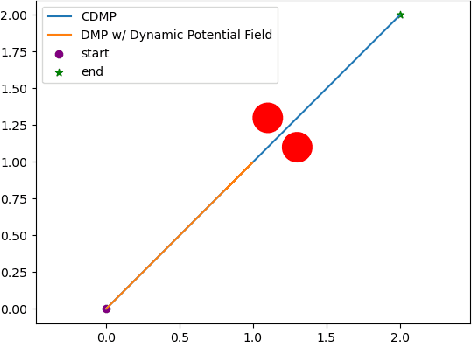
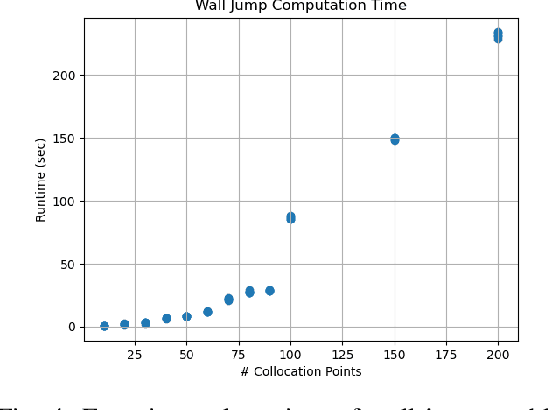
Dynamic movement primitives are widely used for learning skills which can be demonstrated to a robot by a skilled human or controller. While their generalization capabilities and simple formulation make them very appealing to use, they possess no strong guarantees to satisfy operational safety constraints for a task. In this paper, we present constrained dynamic movement primitives (CDMP) which can allow for constraint satisfaction in the robot workspace. We present a formulation of a non-linear optimization to perturb the DMP forcing weights regressed by locally-weighted regression to admit a Zeroing Barrier Function (ZBF), which certifies workspace constraint satisfaction. We demonstrate the proposed CDMP under different constraints on the end-effector movement such as obstacle avoidance and workspace constraints on a physical robot. A video showing the implementation of the proposed algorithm using different manipulators in different environments could be found here https://youtu.be/hJegJJkJfys.
RLang: A Declarative Language for Expression Prior Knowledge for Reinforcement Learning
Aug 16, 2022

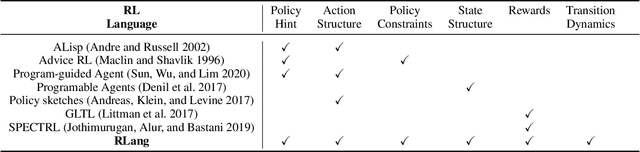
Communicating useful background knowledge to reinforcement learning (RL) agents is an important and effective method for accelerating learning. We introduce RLang, a domain-specific language (DSL) for communicating domain knowledge to an RL agent. Unlike other existing DSLs proposed by the RL community that ground to single elements of a decision-making formalism (e.g., the reward function or policy function), RLang can specify information about every element of a Markov decision process. We define precise syntax and grounding semantics for RLang, and provide a parser implementation that grounds RLang programs to an algorithm-agnostic partial world model and policy that can be exploited by an RL agent. We provide a series of example RLang programs, and demonstrate how different RL methods can exploit the resulting knowledge, including model-free and model-based tabular algorithms, hierarchical approaches, and deep RL algorithms (including both policy gradient and value-based methods).
Skill Transfer for Temporally-Extended Task Specifications
Jun 10, 2022
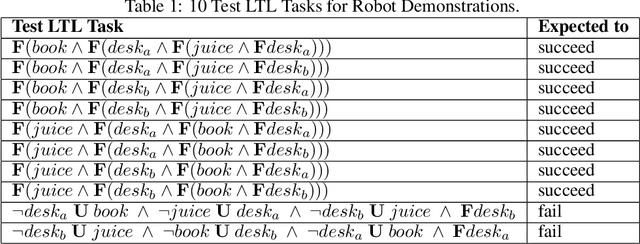
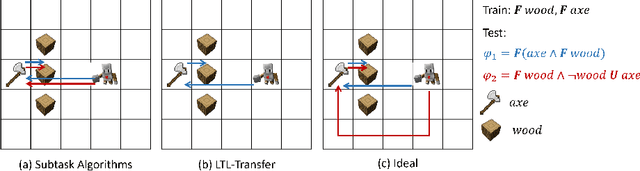
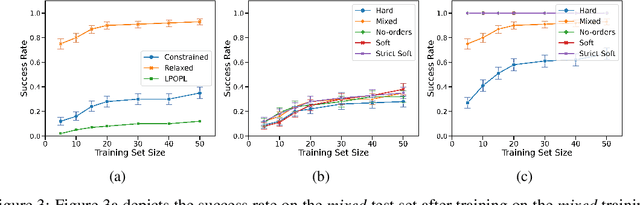
Deploying robots in real-world domains, such as households and flexible manufacturing lines, requires the robots to be taskable on demand. Linear temporal logic (LTL) is a widely-used specification language with a compositional grammar that naturally induces commonalities across tasks. However, the majority of prior research on reinforcement learning with LTL specifications treats every new formula independently. We propose LTL-Transfer, a novel algorithm that enables subpolicy reuse across tasks by segmenting policies for training tasks into portable transition-centric skills capable of satisfying a wide array of unseen LTL specifications while respecting safety-critical constraints. Our experiments in a Minecraft-inspired domain demonstrate the capability of LTL-Transfer to satisfy over 90% of 500 unseen tasks while training on only 50 task specifications and never violating a safety constraint. We also deployed LTL-Transfer on a quadruped mobile manipulator in a household environment to show its ability to transfer to many fetch and delivery tasks in a zero-shot fashion.
Meta-Learning Transferable Parameterized Skills
Jun 07, 2022
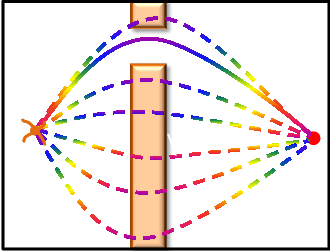
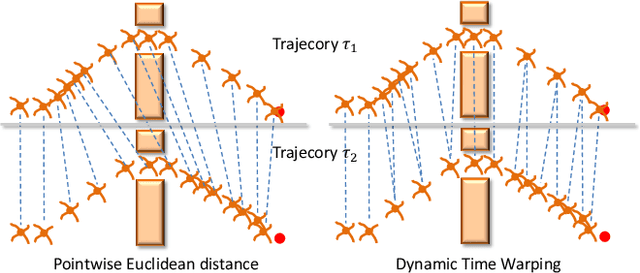
We propose a novel parameterized skill-learning algorithm that aims to learn transferable parameterized skills and synthesize them into a new action space that supports efficient learning in long-horizon tasks. We first propose novel learning objectives -- trajectory-centric diversity and smoothness -- that allow an agent to meta-learn reusable parameterized skills. Our agent can use these learned skills to construct a temporally-extended parameterized-action Markov decision process, for which we propose a hierarchical actor-critic algorithm that aims to efficiently learn a high-level control policy with the learned skills. We empirically demonstrate that the proposed algorithms enable an agent to solve a complicated long-horizon obstacle-course environment.
Characterizing the Action-Generalization Gap in Deep Q-Learning
May 11, 2022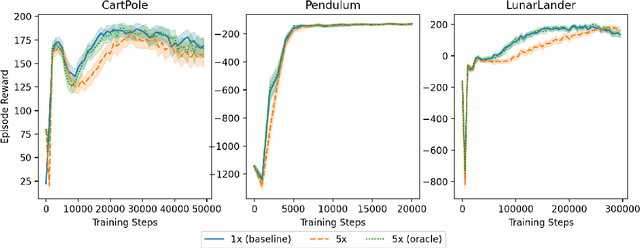
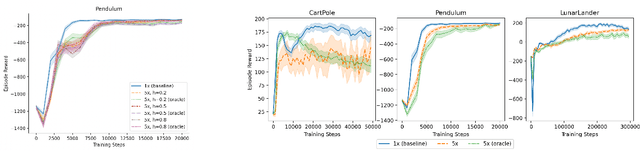
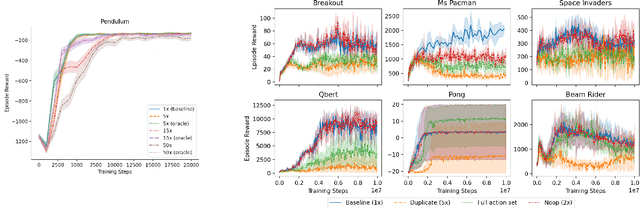
We study the action generalization ability of deep Q-learning in discrete action spaces. Generalization is crucial for efficient reinforcement learning (RL) because it allows agents to use knowledge learned from past experiences on new tasks. But while function approximation provides deep RL agents with a natural way to generalize over state inputs, the same generalization mechanism does not apply to discrete action outputs. And yet, surprisingly, our experiments indicate that Deep Q-Networks (DQN), which use exactly this type of function approximator, are still able to achieve modest action generalization. Our main contribution is twofold: first, we propose a method of evaluating action generalization using expert knowledge of action similarity, and empirically confirm that action generalization leads to faster learning; second, we characterize the action-generalization gap (the difference in learning performance between DQN and the expert) in different domains. We find that DQN can indeed generalize over actions in several simple domains, but that its ability to do so decreases as the action space grows larger.
Learning Abstract and Transferable Representations for Planning
May 04, 2022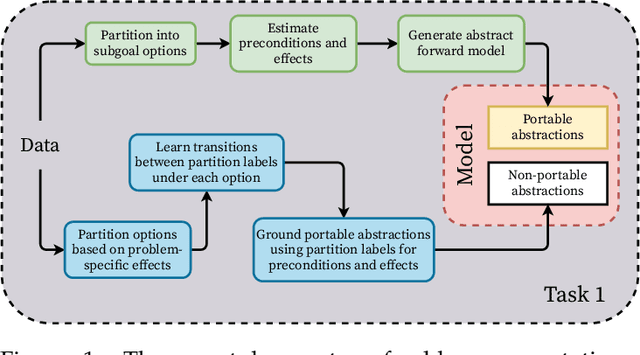
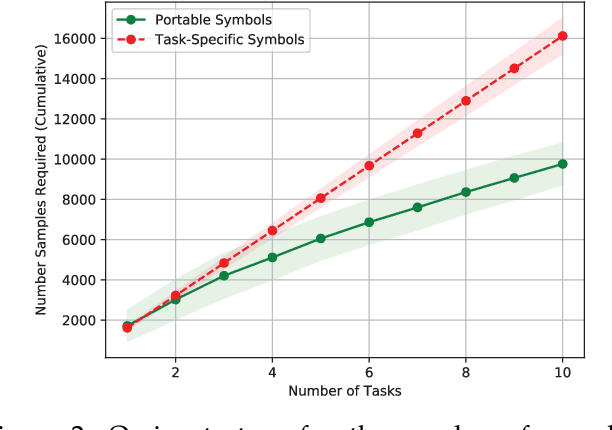
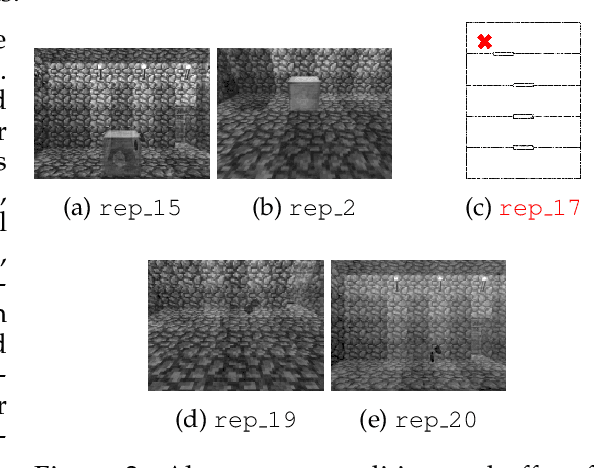
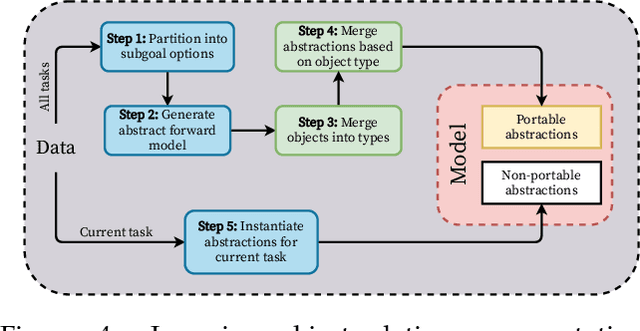
We are concerned with the question of how an agent can acquire its own representations from sensory data. We restrict our focus to learning representations for long-term planning, a class of problems that state-of-the-art learning methods are unable to solve. We propose a framework for autonomously learning state abstractions of an agent's environment, given a set of skills. Importantly, these abstractions are task-independent, and so can be reused to solve new tasks. We demonstrate how an agent can use an existing set of options to acquire representations from ego- and object-centric observations. These abstractions can immediately be reused by the same agent in new environments. We show how to combine these portable representations with problem-specific ones to generate a sound description of a specific task that can be used for abstract planning. Finally, we show how to autonomously construct a multi-level hierarchy consisting of increasingly abstract representations. Since these hierarchies are transferable, higher-order concepts can be reused in new tasks, relieving the agent from relearning them and improving sample efficiency. Our results demonstrate that our approach allows an agent to transfer previous knowledge to new tasks, improving sample efficiency as the number of tasks increases.
Adaptive Online Value Function Approximation with Wavelets
Apr 22, 2022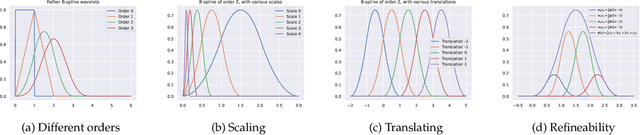
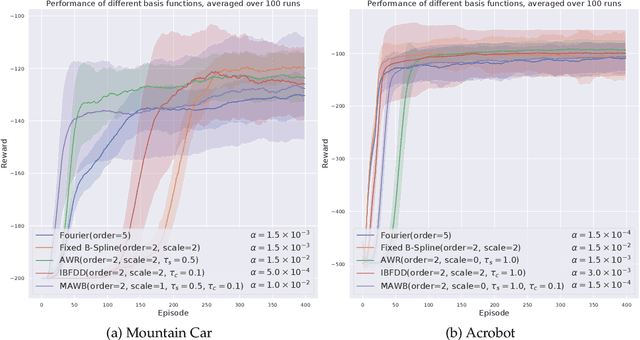
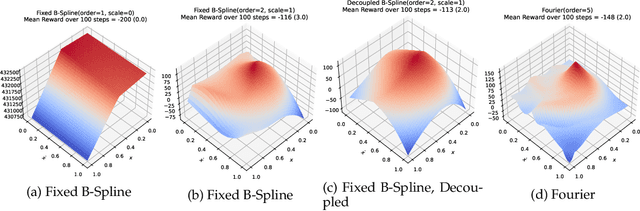
Using function approximation to represent a value function is necessary for continuous and high-dimensional state spaces. Linear function approximation has desirable theoretical guarantees and often requires less compute and samples than neural networks, but most approaches suffer from an exponential growth in the number of functions as the dimensionality of the state space increases. In this work, we introduce the wavelet basis for reinforcement learning. Wavelets can effectively be used as a fixed basis and additionally provide the ability to adaptively refine the basis set as learning progresses, making it feasible to start with a minimal basis set. This adaptive method can either increase the granularity of the approximation at a point in state space, or add in interactions between different dimensions as necessary. We prove that wavelets are both necessary and sufficient if we wish to construct a function approximator that can be adaptively refined without loss of precision. We further demonstrate that a fixed wavelet basis set performs comparably against the high-performing Fourier basis on Mountain Car and Acrobot, and that the adaptive methods provide a convenient approach to addressing an oversized initial basis set, while demonstrating performance comparable to, or greater than, the fixed wavelet basis.