 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold Graph Signal Restoration using Gradient Graph Laplacian Regularizer
Jun 09, 2022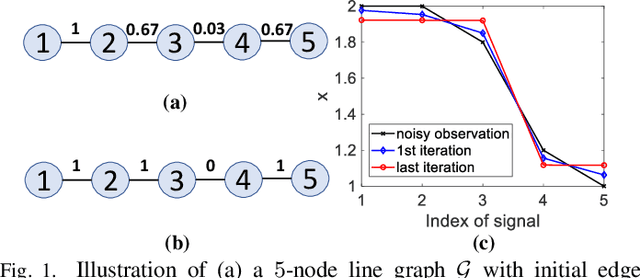
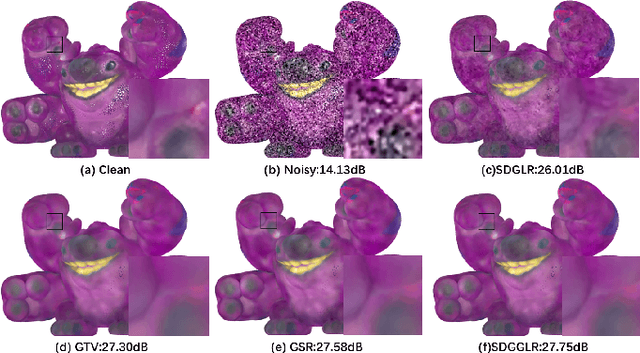
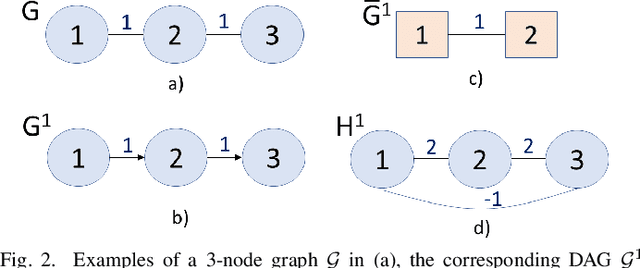
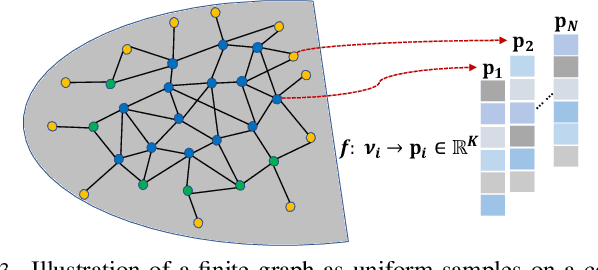
In the graph signal processing (GSP) literature, graph Laplacian regularizer (GLR) was used for signal restoration to promote smooth reconstructions with respect to the underlying graph -- typically signals that are (piecewise) constant. However, for graph signals that are (piecewise) planar, GLR may suffer from the well-known "staircase" effect. In this paper, focusing on manifold graphs -- sets of uniform discrete samples on low-dimensional continuous manifolds -- we generalize GLR to gradient graph Laplacian regularizer (GGLR) that provably promotes piecewise planar (PWP) signal reconstruction. Specifically, for a graph endowed with latent space coordinates (e.g., 2D images, 3D point clouds), we first define a gradient operator, using which we construct a higher-order gradient graph for the computed gradients in each latent dimension. This maps to a gradient-induced nodal graph (GNG) and a Laplacian matrix for a signed graph that is provably positive semi-definite (PSD), thus suitable for quadratic regularization. For manifold graphs without explicit latent coordinates, we propose a fast parameter-free spectral method to first compute latent space coordinates for graph nodes based on generalized eigenvectors. We derive the means-square-error minimizing weight parameter for GGLR efficiently, trading off bias and variance of the signal estimate. Experimental results show that GGLR outperformed previous graph signal priors like GLR and graph total variation (GTV) in a range of graph signal restoration tasks.
Hybrid Model-based / Data-driven Graph Transform for Image Coding
Mar 02, 2022
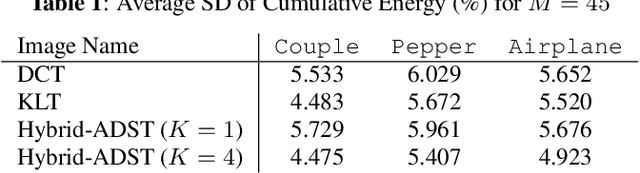
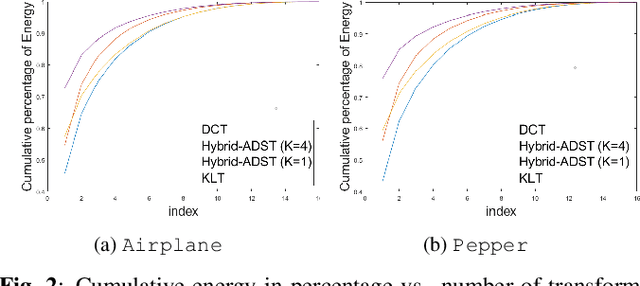

Transform coding to sparsify signal representations remains crucial in an image compression pipeline. While the Karhunen-Lo\`{e}ve transform (KLT) computed from an empirical covariance matrix $\bar{C}$ is theoretically optimal for a stationary process, in practice, collecting sufficient statistics from a non-stationary image to reliably estimate $\bar{C}$ can be difficult. In this paper, to encode an intra-prediction residual block, we pursue a hybrid model-based / data-driven approach: the first $K$ eigenvectors of a transform matrix are derived from a statistical model, e.g., the asymmetric discrete sine transform (ADST), for stability, while the remaining $N-K$ are computed from $\bar{C}$ for performance. The transform computation is posed as a graph learning problem, where we seek a graph Laplacian matrix minimizing a graphical lasso objective inside a convex cone sharing the first $K$ eigenvectors in a Hilbert space of real symmetric matrices. We efficiently solve the problem via augmented Lagrangian relaxation and proximal gradient (PG). Using WebP as a baseline image codec, experimental results show that our hybrid graph transform achieved better energy compaction than default discrete cosine transform (DCT) and better stability than KLT.
Sparse Graph Learning with Eigen-gap for Spectral Filter Training in Graph Convolutional Networks
Feb 28, 2022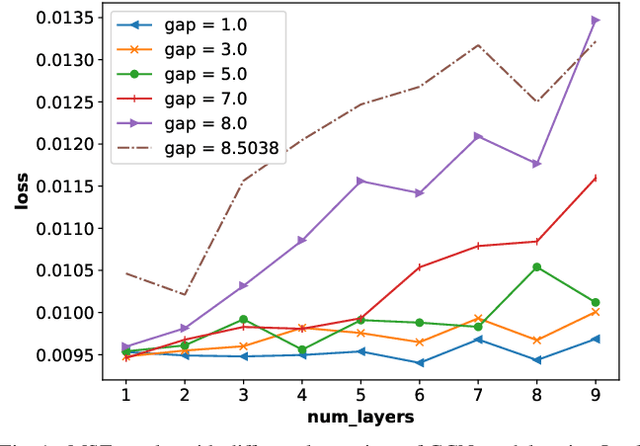
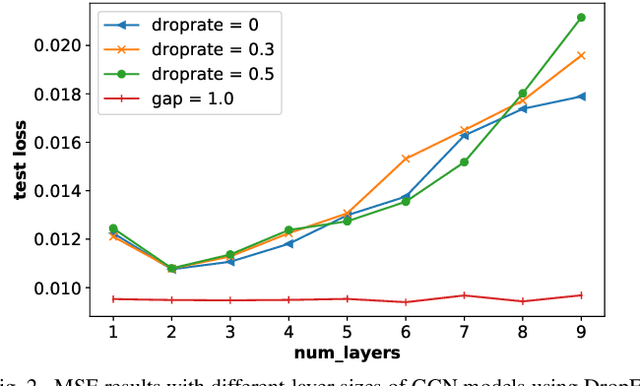
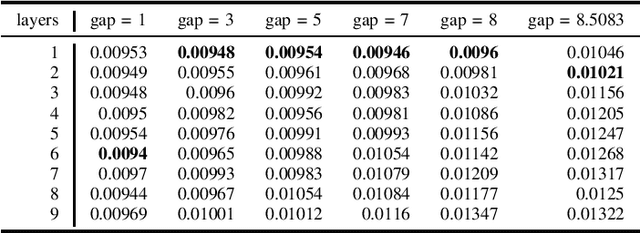
It is now known that the expressive power of graph convolutional neural nets (GCN) does not grow infinitely with the number of layers. Instead, the GCN output approaches a subspace spanned by the first eigenvector of the normalized graph Laplacian matrix with the convergence rate characterized by the "eigen-gap": the difference between the Laplacian's first two distinct eigenvalues. To promote a deeper GCN architecture with sufficient expressiveness, in this paper, given an empirical covariance matrix $\bar{C}$ computed from observable data, we learn a sparse graph Laplacian matrix $L$ closest to $\bar{C}^{-1}$ while maintaining a desirable eigen-gap that slows down convergence. Specifically, we first define a sparse graph learning problem with constraints on the first eigenvector (the most common signal) and the eigen-gap. We solve the corresponding dual problem greedily, where a locally optimal eigen-pair is computed one at a time via a fast approximation of a semi-definite programming (SDP) formulation. The computed $L$ with the desired eigen-gap is normalized spectrally and used for supervised training of GCN for a targeted task. Experiments show that our proposal produced deeper GCNs and smaller errors compared to a competing scheme without explicit eigen-gap optimization.
Fast Computation of Generalized Eigenvectors for Manifold Graph Embedding
Dec 15, 2021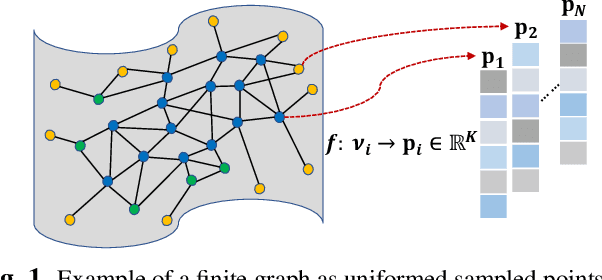

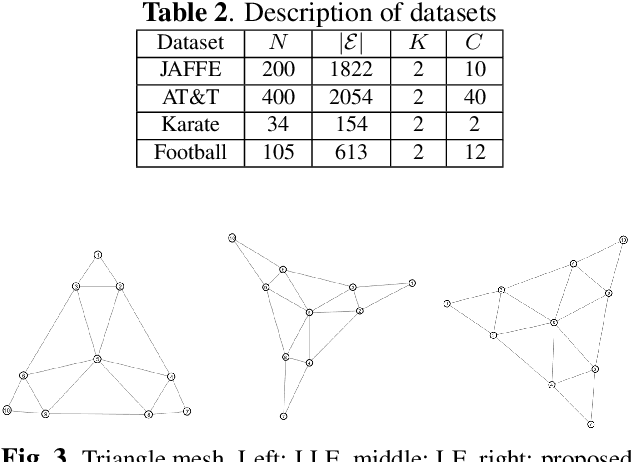
Our goal is to efficiently compute low-dimensional latent coordinates for nodes in an input graph -- known as graph embedding -- for subsequent data processing such as clustering. Focusing on finite graphs that are interpreted as uniformly samples on continuous manifolds (called manifold graphs), we leverage existing fast extreme eigenvector computation algorithms for speedy execution. We first pose a generalized eigenvalue problem for sparse matrix pair $(\A,\B)$, where $\A = \L - \mu \Q + \epsilon \I$ is a sum of graph Laplacian $\L$ and disconnected two-hop difference matrix $\Q$. Eigenvector $\v$ minimizing Rayleigh quotient $\frac{\v^{\top} \A \v}{\v^{\top} \v}$ thus minimizes $1$-hop neighbor distances while maximizing distances between disconnected $2$-hop neighbors, preserving graph structure. Matrix $\B = \text{diag}(\{\b_i\})$ that defines eigenvector orthogonality is then chosen so that boundary / interior nodes in the sampling domain have the same generalized degrees. $K$-dimensional latent vectors for the $N$ graph nodes are the first $K$ generalized eigenvectors for $(\A,\B)$, computed in $\cO(N)$ using LOBPCG, where $K \ll N$. Experiments show that our embedding is among the fastest in the literature, while producing the best clustering performance for manifold graphs.
Graph-Based Depth Denoising & Dequantization for Point Cloud Enhancement
Nov 09, 2021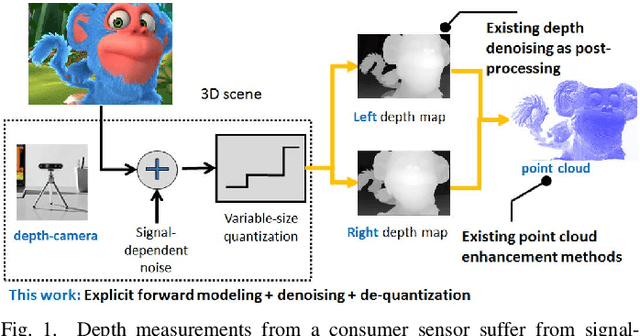
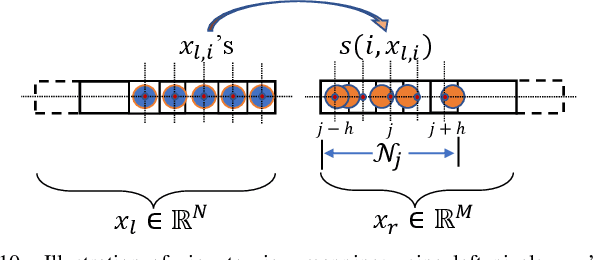
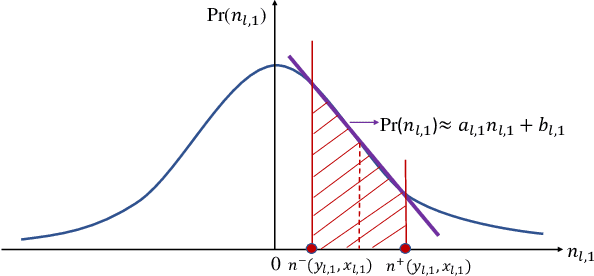
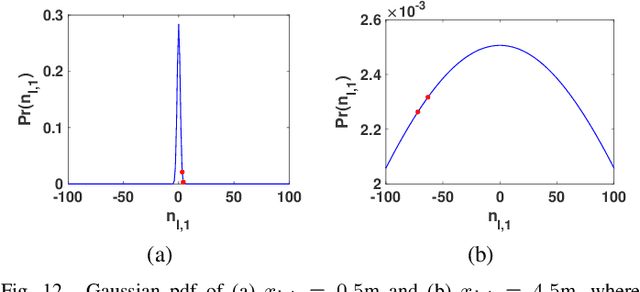
A 3D point cloud is typically constructed from depth measurements acquired by sensors at one or more viewpoints. The measurements suffer from both quantization and noise corruption. To improve quality, previous works denoise a point cloud \textit{a posteriori} after projecting the imperfect depth data onto 3D space. Instead, we enhance depth measurements directly on the sensed images \textit{a priori}, before synthesizing a 3D point cloud. By enhancing near the physical sensing process, we tailor our optimization to our depth formation model before subsequent processing steps that obscure measurement errors. Specifically, we model depth formation as a combined process of signal-dependent noise addition and non-uniform log-based quantization. The designed model is validated (with parameters fitted) using collected empirical data from an actual depth sensor. To enhance each pixel row in a depth image, we first encode intra-view similarities between available row pixels as edge weights via feature graph learning. We next establish inter-view similarities with another rectified depth image via viewpoint mapping and sparse linear interpolation. This leads to a maximum a posteriori (MAP) graph filtering objective that is convex and differentiable. We optimize the objective efficiently using accelerated gradient descent (AGD), where the optimal step size is approximated via Gershgorin circle theorem (GCT). Experiments show that our method significantly outperformed recent point cloud denoising schemes and state-of-the-art image denoising schemes, in two established point cloud quality metrics.
Fast Graph Sampling for Short Video Summarization using Gershgorin Disc Alignment
Oct 25, 2021
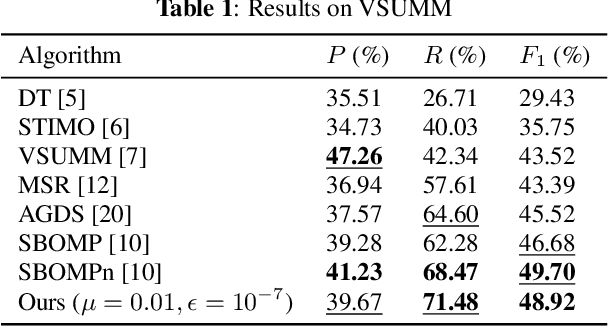

We study the problem of efficiently summarizing a short video into several keyframes, leveraging recent progress in fast graph sampling. Specifically, we first construct a similarity path graph (SPG) $\mathcal{G}$, represented by graph Laplacian matrix $\mathbf{L}$, where the similarities between adjacent frames are encoded as positive edge weights. We show that maximizing the smallest eigenvalue $\lambda_{\min}(\mathbf{B})$ of a coefficient matrix $\mathbf{B} = \text{diag}(\mathbf{a}) + \mu \mathbf{L}$, where $\mathbf{a}$ is the binary keyframe selection vector, is equivalent to minimizing a worst-case signal reconstruction error. We prove that, after partitioning $\mathcal{G}$ into $Q$ sub-graphs $\{\mathcal{G}^q\}^Q_{q=1}$, the smallest Gershgorin circle theorem (GCT) lower bound of $Q$ corresponding coefficient matrices -- $\min_q \lambda^-_{\min}(\mathbf{B}^q)$ -- is a lower bound for $\lambda_{\min}(\mathbf{B})$. This inspires a fast graph sampling algorithm to iteratively partition $\mathcal{G}$ into $Q$ sub-graphs using $Q$ samples (keyframes), while maximizing $\lambda^-_{\min}(\mathbf{B}^q)$ for each sub-graph $\mathcal{G}^q$. Experimental results show that our algorithm achieves comparable video summarization performance as state-of-the-art methods, at a substantially reduced complexity.
Fast sensor placement by enlarging principle submatrix for large-scale linear inverse problems
Oct 07, 2021
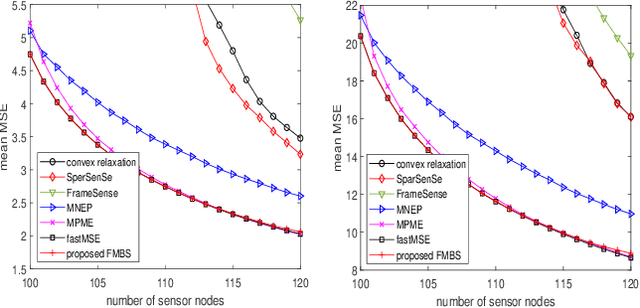
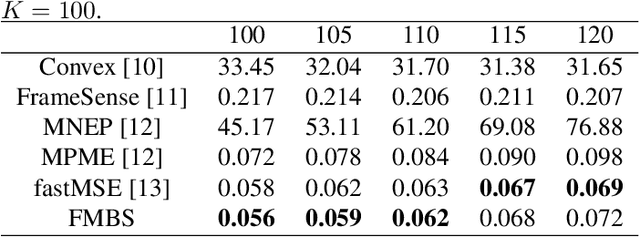
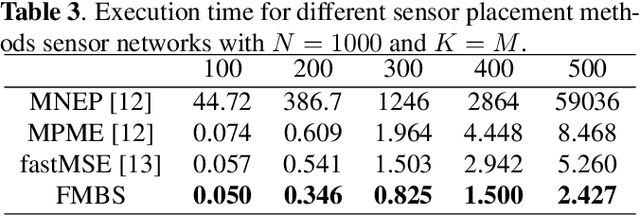
Sensor placement for linear inverse problems is the selection of locations to assign sensors so that the entire physical signal can be well recovered from partial observations. In this paper, we propose a fast sampling algorithm to place sensors. Specifically, assuming that the field signal $\mathbf{f}$ is represented by a linear model $\mathbf{f}=\pmb{\phi}\mathbf{g}$, it can be estimated from partial noisy samples via an unbiased least-squares (LS) method, whose expected mean square error (MSE) depends on chosen samples. First, we formulate an approximate MSE problem, and then prove it is equivalent to a problem related to a principle submatrix of $\pmb{\phi}\pmb{\phi}^\top$ indexed by sample set. To solve the formulated problem, we devise a fast greedy algorithm with simple matrix-vector multiplications, leveraging a matrix inverse formula. To further reduce complexity, we reuse results in the previous greedy step for warm start, so that candidates can be evaluated via lightweight vector-vector multiplications. Extensive experiments show that our proposed sensor placement method achieved the lowest sensor sampling time and the best performance compared to state-of-the-art schemes.
Unfolding Projection-free SDP Relaxation of Binary Graph Classifier via GDPA Linearization
Sep 10, 2021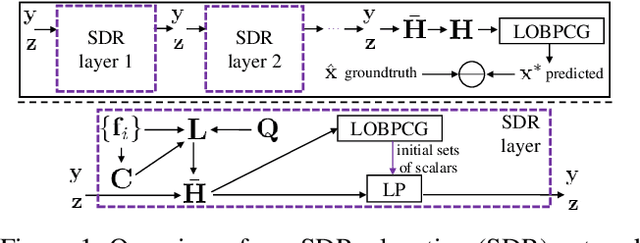
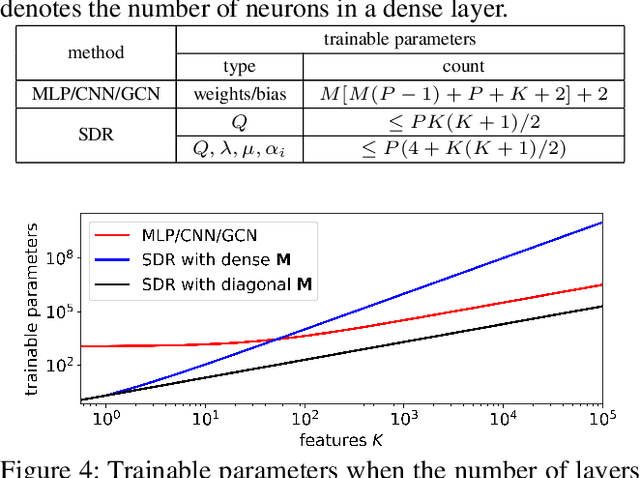
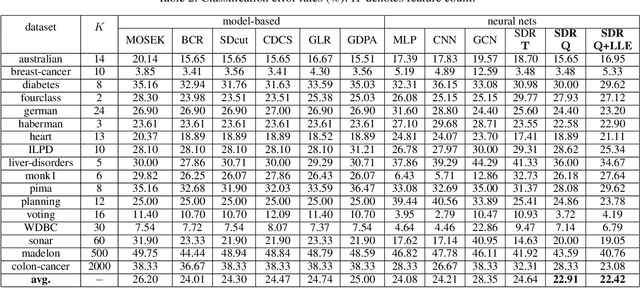
Algorithm unfolding creates an interpretable and parsimonious neural network architecture by implementing each iteration of a model-based algorithm as a neural layer. However, unfolding a proximal splitting algorithm with a positive semi-definite (PSD) cone projection operator per iteration is expensive, due to the required full matrix eigen-decomposition. In this paper, leveraging a recent linear algebraic theorem called Gershgorin disc perfect alignment (GDPA), we unroll a projection-free algorithm for semi-definite programming relaxation (SDR) of a binary graph classifier, where the PSD cone constraint is replaced by a set of "tightest possible" linear constraints per iteration. As a result, each iteration only requires computing a linear program (LP) and one extreme eigenvector. Inside the unrolled network, we optimize parameters via stochastic gradient descent (SGD) that determine graph edge weights in two ways: i) a metric matrix that computes feature distances, and ii) a sparse weight matrix computed via local linear embedding (LLE). Experimental results show that our unrolled network outperformed pure model-based graph classifiers, and achieved comparable performance to pure data-driven networks but using far fewer parameters.
Projection-free Graph-based Classifier Learning using Gershgorin Disc Perfect Alignment
Jun 03, 2021
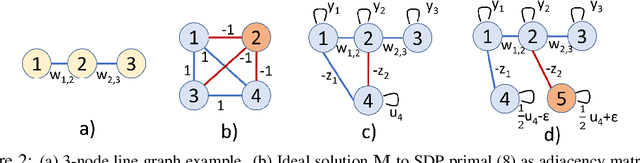
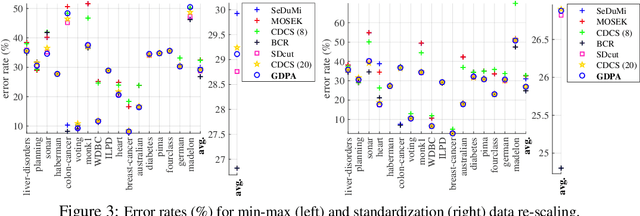
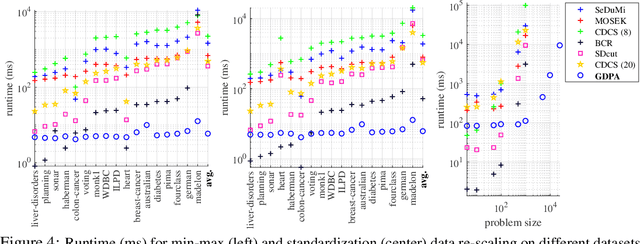
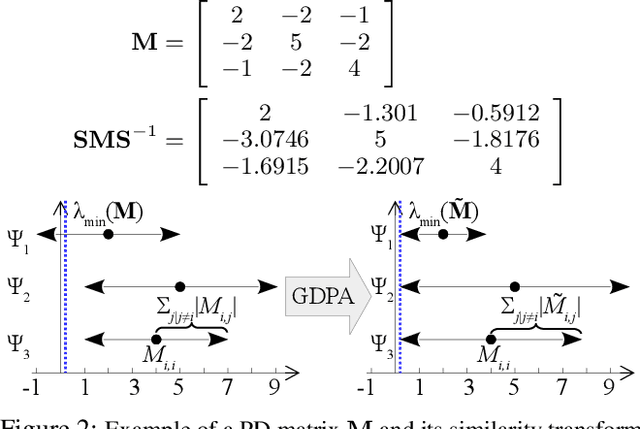
In semi-supervised graph-based binary classifier learning, a subset of known labels $\hat{x}_i$ are used to infer unknown labels, assuming that the label signal $x$ is smooth with respect to a similarity graph specified by a Laplacian matrix. When restricting labels $x_i$ to binary values, the problem is NP-hard. While a conventional semi-definite programming (SDP) relaxation can be solved in polynomial time using, for example, the alternating direction method of multipliers (ADMM), the complexity of iteratively projecting a candidate matrix $M$ onto the positive semi-definite (PSD) cone ($M \succeq 0$) remains high. In this paper, leveraging a recent linear algebraic theory called Gershgorin disc perfect alignment (GDPA), we propose a fast projection-free method by solving a sequence of linear programs (LP) instead. Specifically, we first recast the SDP relaxation to its SDP dual, where a feasible solution $H \succeq 0$ can be interpreted as a Laplacian matrix corresponding to a balanced signed graph sans the last node. To achieve graph balance, we split the last node into two that respectively contain the original positive and negative edges, resulting in a new Laplacian $\bar{H}$. We repose the SDP dual for solution $\bar{H}$, then replace the PSD cone constraint $\bar{H} \succeq 0$ with linear constraints derived from GDPA -- sufficient conditions to ensure $\bar{H}$ is PSD -- so that the optimization becomes an LP per iteration. Finally, we extract predicted labels from our converged LP solution $\bar{H}$. Experiments show that our algorithm enjoyed a $40\times$ speedup on average over the next fastest scheme while retaining comparable label prediction performance.
Point Cloud Sampling via Graph Balancing and Gershgorin Disc Alignment
Mar 10, 2021
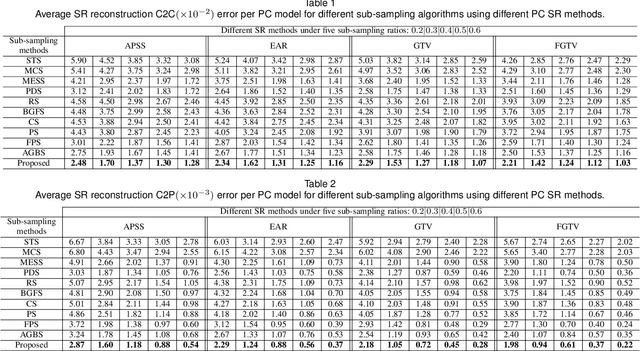
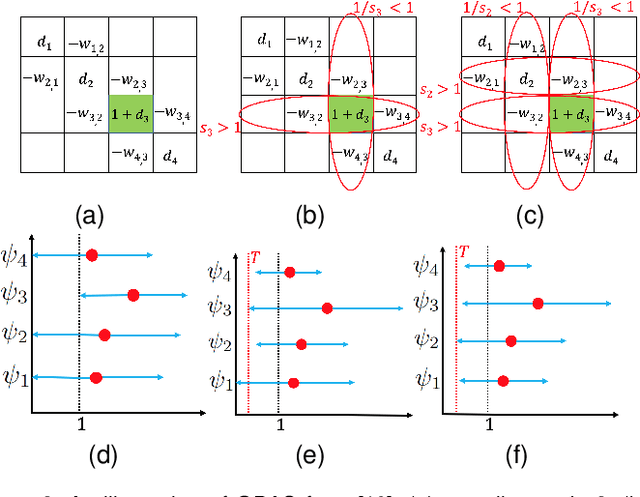
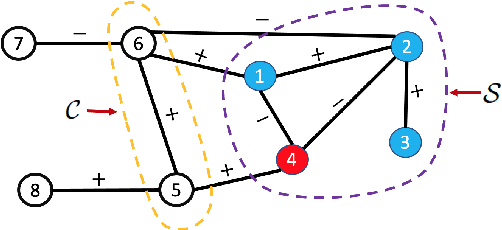
3D point cloud (PC) -- a collection of discrete geometric samples of a physical object's surface -- is typically large in size, which entails expensive subsequent operations like viewpoint image rendering and object recognition. Leveraging on recent advances in graph sampling, we propose a fast PC sub-sampling algorithm that reduces its size while preserving the overall object shape. Specifically, to articulate a sampling objective, we first assume a super-resolution (SR) method based on feature graph Laplacian regularization (FGLR) that reconstructs the original high-resolution PC, given 3D points chosen by a sampling matrix $\H$. We prove that minimizing a worst-case SR reconstruction error is equivalent to maximizing the smallest eigenvalue $\lambda_{\min}$ of a matrix $\H^{\top} \H + \mu \cL$, where $\cL$ is a symmetric, positive semi-definite matrix computed from the neighborhood graph connecting the 3D points. Instead, for fast computation we maximize a lower bound $\lambda^-_{\min}(\H^{\top} \H + \mu \cL)$ via selection of $\H$ in three steps. Interpreting $\cL$ as a generalized graph Laplacian matrix corresponding to an unbalanced signed graph $\cG$, we first approximate $\cG$ with a balanced graph $\cG_B$ with the corresponding generalized graph Laplacian matrix $\cL_B$. Second, leveraging on a recent theorem called Gershgorin disc perfect alignment (GDPA), we perform a similarity transform $\cL_p = \S \cL_B \S^{-1}$ so that Gershgorin disc left-ends of $\cL_p$ are all aligned at the same value $\lambda_{\min}(\cL_B)$. Finally, we perform PC sub-sampling on $\cG_B$ using a graph sampling algorithm to maximize $\lambda^-_{\min}(\H^{\top} \H + \mu \cL_p)$ in roughly linear time. Experimental results show that 3D points chosen by our algorithm outperformed competing schemes both numerically and visually in SR reconstruction quality.