 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGang Niu
A Survey of Label-noise Representation Learning: Past, Present and Future
Nov 09, 2020

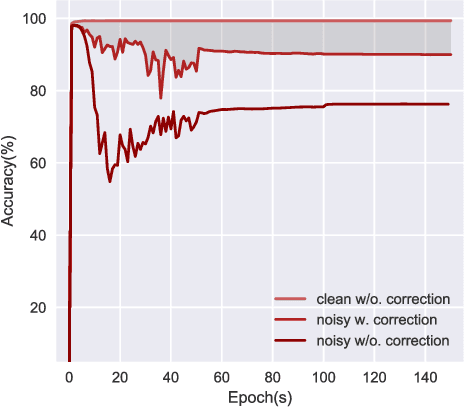
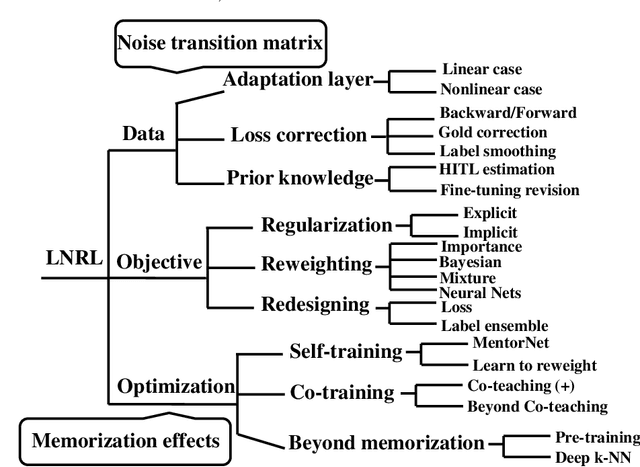
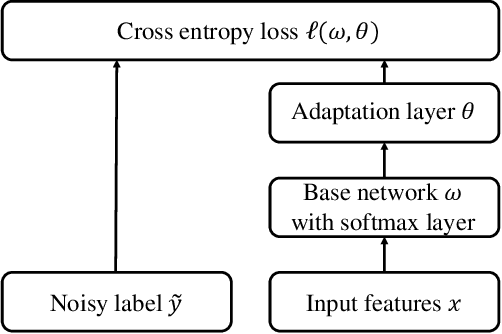
Classical machine learning implicitly assumes that labels of the training data are sampled from a clean distribution, which can be too restrictive for real-world scenarios. However, statistical learning-based methods may not train deep learning models robustly with these noisy labels. Therefore, it is urgent to design Label-Noise Representation Learning (LNRL) methods for robustly training deep models with noisy labels. To fully understand LNRL, we conduct a survey study. We first clarify a formal definition for LNRL from the perspective of machine learning. Then, via the lens of learning theory and empirical study, we figure out why noisy labels affect deep models' performance. Based on the theoretical guidance, we categorize different LNRL methods into three directions. Under this unified taxonomy, we provide a thorough discussion of the pros and cons of different categories. More importantly, we summarize the essential components of robust LNRL, which can spark new directions. Lastly, we propose possible research directions within LNRL, such as new datasets, instance-dependent LNRL, and adversarial LNRL. Finally, we envision potential directions beyond LNRL, such as learning with feature-noise, preference-noise, domain-noise, similarity-noise, graph-noise, and demonstration-noise.
Maximum Mean Discrepancy is Aware of Adversarial Attacks
Oct 22, 2020

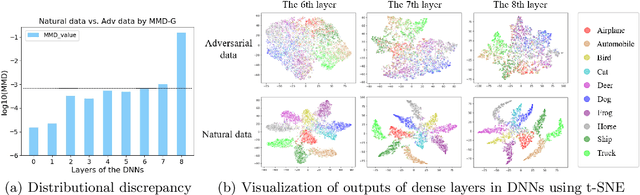

The maximum mean discrepancy (MMD) test, as a representative two-sample test, could in principle detect any distributional discrepancy between two datasets. However, it has been shown that MMD is unaware of adversarial attacks---MMD failed to detect the discrepancy between natural data and adversarial data generated by adversarial attacks. Given this phenomenon, we raise a question: are natural and adversarial data really from different distributions but previous use of MMD on the purpose missed some key factors? The answer is affirmative. We find the previous use missed three factors and accordingly we propose three components: (a) Gaussian kernel has limited representation power, and we replace it with a novel semantic-aware deep kernel; (b) test power of MMD was neglected, and we maximize it in order to optimize our deep kernel; (c) adversarial data may be non-independent, and to this end we apply wild bootstrap for validity of the test power. By taking care of the three factors, we validate that MMD is aware of adversarial attacks, which lights up a novel road for adversarial attack detection based on two-sample tests.
Pointwise Binary Classification with Pairwise Confidence Comparisons
Oct 05, 2020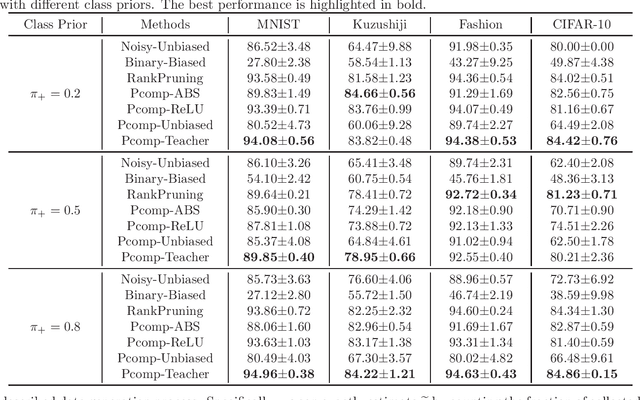

Ordinary (pointwise) binary classification aims to learn a binary classifier from pointwise labeled data. However, such pointwise labels may not be directly accessible due to privacy, confidentiality, or security considerations. In this case, can we still learn an accurate binary classifier? This paper proposes a novel setting, namely pairwise comparison (Pcomp) classification, where we are given only pairs of unlabeled data that we know one is more likely to be positive than the other, instead of pointwise labeled data. Pcomp classification is useful for private or subjective classification tasks. To solve this problem, we present a mathematical formulation for the generation process of pairwise comparison data, based on which we exploit an unbiased risk estimator(URE) to train a binary classifier by empirical risk minimization and establish an estimation error bound. We first prove that a URE can be derived and improve it using correction functions. Then, we start from the noisy-label learning perspective to introduce a progressive URE and improve it by imposing consistency regularization. Finally, experiments validate the effectiveness of our proposed solutions for Pcomp classification.
Geometry-aware Instance-reweighted Adversarial Training
Oct 05, 2020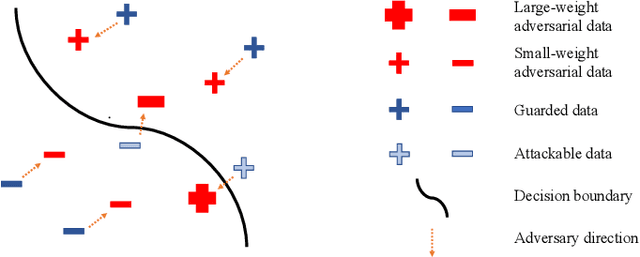

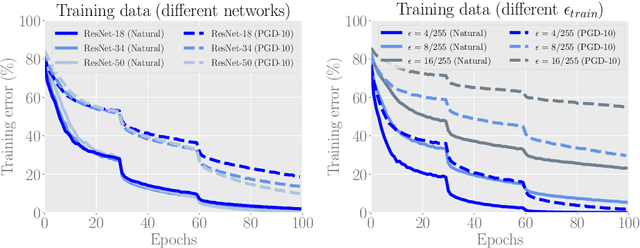

In adversarial machine learning, there was a common belief that robustness and accuracy hurt each other. The belief was challenged by recent studies where we can maintain the robustness and improve the accuracy. However, the other direction, whether we can keep the accuracy while improving the robustness, is conceptually and practically more interesting, since robust accuracy should be lower than standard accuracy for any model. In this paper, we show this direction is also promising. Firstly, we find even over-parameterized deep networks may still have insufficient model capacity, because adversarial training has an overwhelming smoothing effect. Secondly, given limited model capacity, we argue adversarial data should have unequal importance: geometrically speaking, a natural data point closer to/farther from the class boundary is less/more robust, and the corresponding adversarial data point should be assigned with larger/smaller weight. Finally, to implement the idea, we propose geometry-aware instance-reweighted adversarial training, where the weights are based on how difficult it is to attack a natural data point. Experiments show that our proposal boosts the robustness of standard adversarial training; combining two directions, we improve both robustness and accuracy of standard adversarial training.
Provably Consistent Partial-Label Learning
Jul 17, 2020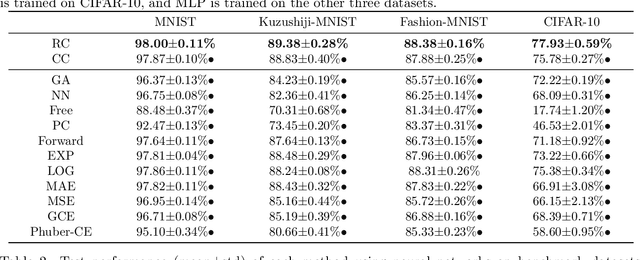
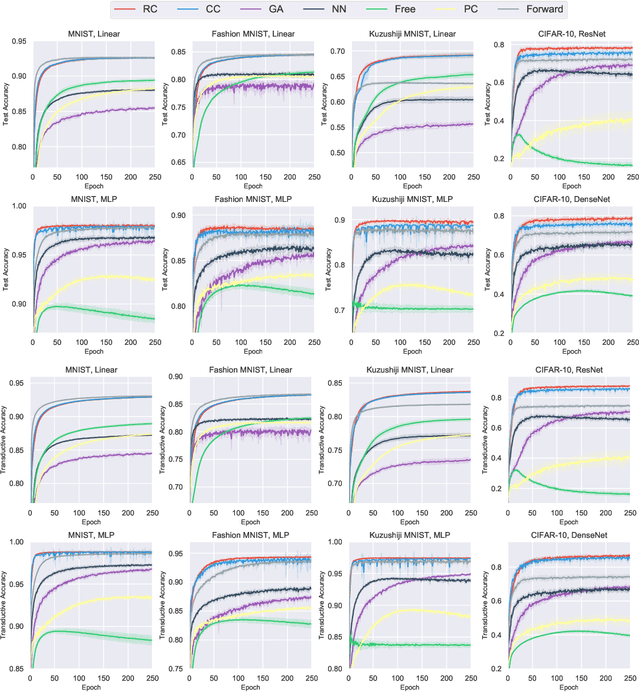
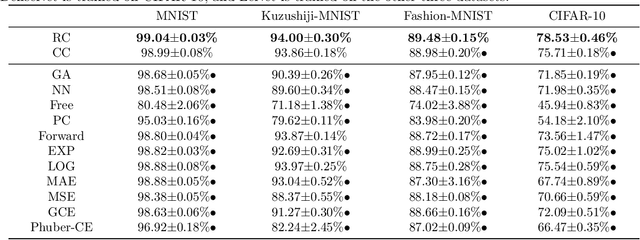
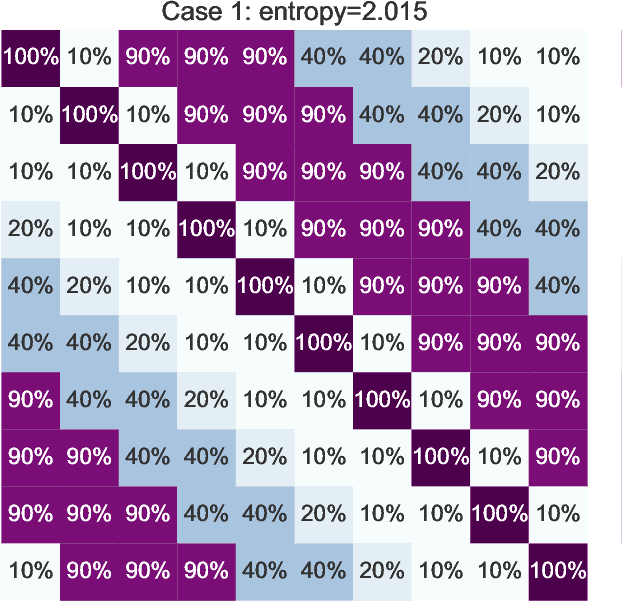
Partial-label learning (PLL) is a multi-class classification problem, where each training example is associated with a set of candidate labels. Even though many practical PLL methods have been proposed in the last two decades, there lacks a theoretical understanding of the consistency of those methods-none of the PLL methods hitherto possesses a generation process of candidate label sets, and then it is still unclear why such a method works on a specific dataset and when it may fail given a different dataset. In this paper, we propose the first generation model of candidate label sets, and develop two novel PLL methods that are guaranteed to be provably consistent, i.e., one is risk-consistent and the other is classifier-consistent. Our methods are advantageous, since they are compatible with any deep network or stochastic optimizer. Furthermore, thanks to the generation model, we would be able to answer the two questions above by testing if the generation model matches given candidate label sets. Experiments on benchmark and real-world datasets validate the effectiveness of the proposed generation model and two PLL methods.
Unbiased Risk Estimators Can Mislead: A Case Study of Learning with Complementary Labels
Jul 07, 2020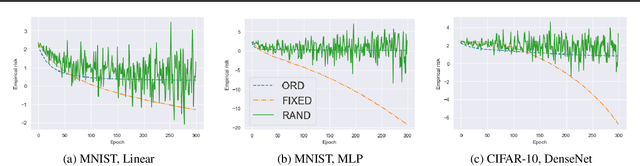
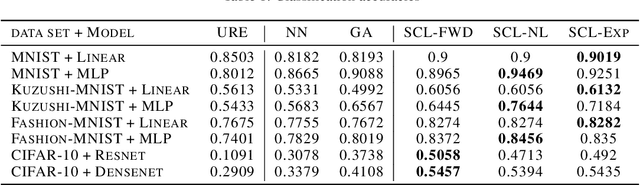
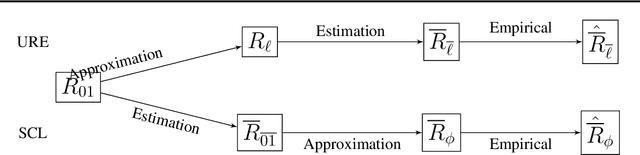
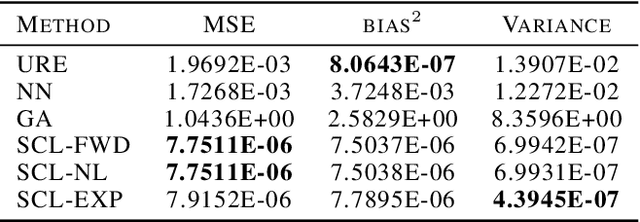
In weakly supervised learning, unbiased risk estimator(URE) is a powerful tool for training classifiers when training and test data are drawn from different distributions. Nevertheless, UREs lead to overfitting in many problem settings when the models are complex like deep networks. In this paper, we investigate reasons for such overfitting by studying a weakly supervised problem called learning with complementary labels. We argue the quality of gradient estimation matters more in risk minimization. Theoretically, we show that a URE gives an unbiased gradient estimator(UGE). Practically, however, UGEs may suffer from huge variance, which causes empirical gradients to be usually far away from true gradients during minimization. To this end, we propose a novel surrogate complementary loss(SCL) framework that trades zero bias with reduced variance and makes empirical gradients more aligned with true gradients in the direction. Thanks to this characteristic, SCL successfully mitigates the overfitting issue and improves URE-based methods.
Parts-dependent Label Noise: Towards Instance-dependent Label Noise
Jun 14, 2020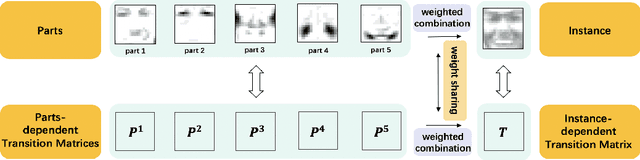
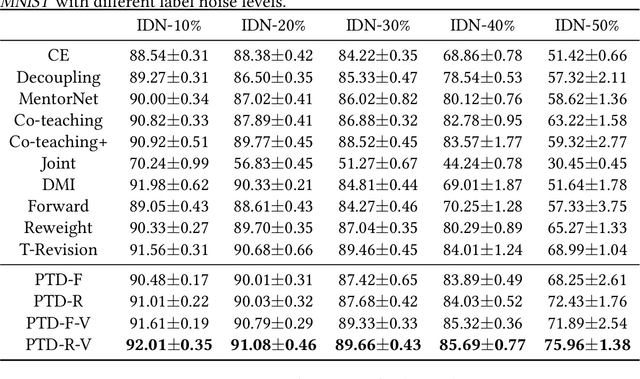
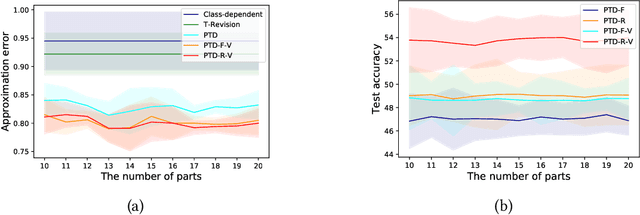
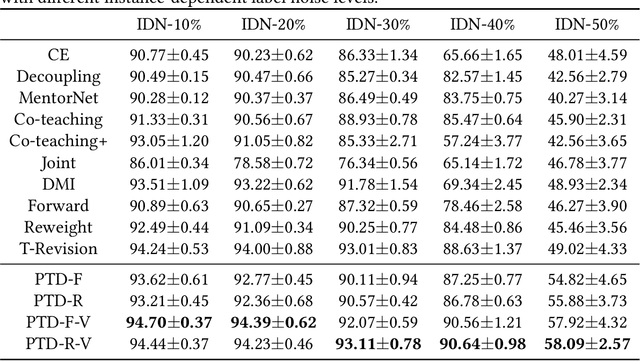
Learning with the \textit{instance-dependent} label noise is challenging, because it is hard to model such real-world noise. Note that there are psychological and physiological evidences showing that we humans perceive instances by decomposing them into parts. Annotators are therefore more likely to annotate instances based on the parts rather than the whole instances. Motivated by this human cognition, in this paper, we approximate the instance-dependent label noise by exploiting \textit{parts-dependent} label noise. Specifically, since instances can be approximately reconstructed by a combination of parts, we approximate the instance-dependent \textit{transition matrix} for an instance by a combination of the transition matrices for the parts of the instance. The transition matrices for parts can be learned by exploiting anchor points (i.e., data points that belong to a specific class almost surely). Empirical evaluations on synthetic and real-world datasets demonstrate our method is superior to the state-of-the-art approaches for learning from the instance-dependent label noise.
Class2Simi: A New Perspective on Learning with Label Noise
Jun 14, 2020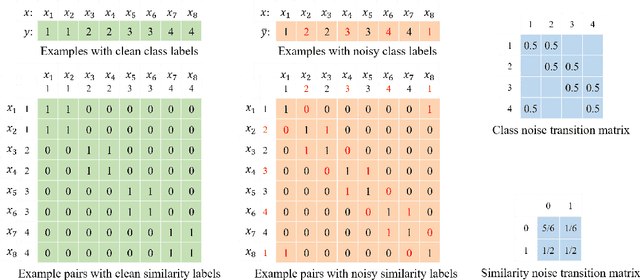


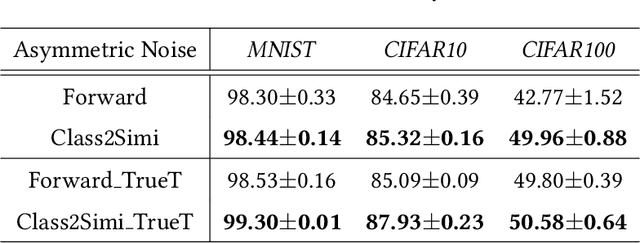
Label noise is ubiquitous in the era of big data. Deep learning algorithms can easily fit the noise and thus cannot generalize well without properly modeling the noise. In this paper, we propose a new perspective on dealing with label noise called Class2Simi. Specifically, we transform the training examples with noisy class labels into pairs of examples with noisy similarity labels and propose a deep learning framework to learn robust classifiers directly with the noisy similarity labels. Note that a class label shows the class that an instance belongs to; while a similarity label indicates whether or not two instances belong to the same class. It is worthwhile to perform the transformation: We prove that the noise rate for the noisy similarity labels is lower than that of the noisy class labels, because similarity labels themselves are robust to noise. For example, given two instances, even if both of their class labels are incorrect, their similarity label could be correct. Due to the lower noise rate, Class2Simi achieves remarkably better classification accuracy than its baselines that directly deals with the noisy class labels.
Dual T: Reducing Estimation Error for Transition Matrix in Label-noise Learning
Jun 14, 2020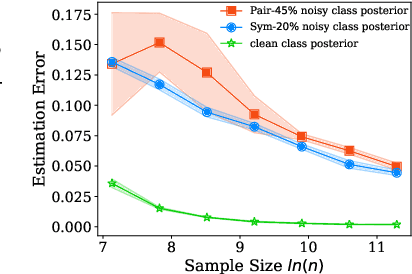
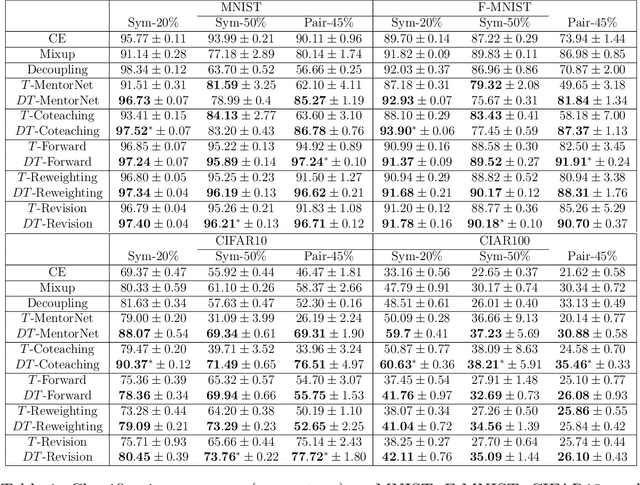
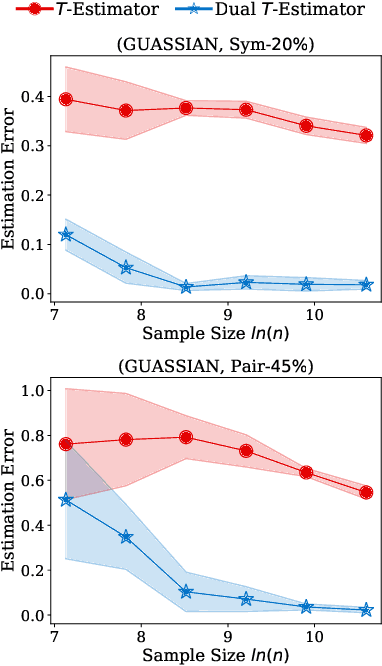

The \textit{transition matrix}, denoting the transition relationship from clean labels to noisy labels, is essential to build \textit{statistically consistent} classifiers in label-noise learning. Existing methods for estimating the transition matrix rely heavily on estimating the noisy class posterior. However, the estimation error for \textit{noisy class posterior} could be large due to the randomness of label noise. The estimation error would lead the transition matrix to be poorly estimated. Therefore, in this paper, we aim to solve this problem by exploiting the divide-and-conquer paradigm. Specifically, we introduce an \textit{intermediate class} to avoid directly estimating the noisy class posterior. By this intermediate class, the original transition matrix can then be factorized into the product of two easy-to-estimate transition matrices. We term the proposed method the \textit{dual $T$-estimator}. Both theoretical analyses and empirical results illustrate the effectiveness of the dual $T$-estimator for estimating transition matrices, leading to better classification performances.